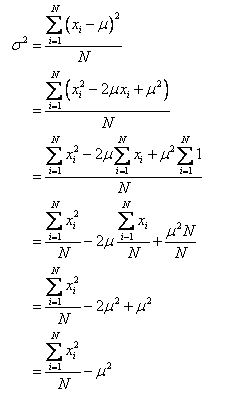一直很欣赏武侠小说宗师还珠楼主李寿民的扛鼎之作《蜀山剑侠传》,可惜由于种种原因,《蜀山剑侠传》并未写完。这着实令还珠迷们扼腕,也有不少人继写了《蜀山剑侠传》,但是良莠夹杂,其中有一位退休公务员写的《续蜀山剑侠传》相对来说是按照还珠楼主的思路续写的,并且在网上连载了,于是想把它从网上down下来保存为txt文件。顺便练习一下Python编程。
首先要获取目录信息,主要是目录名称和网址。通过分析连载网站的网页源代码,编写Python代码如下:
# -*- coding:UTF-8 -*-
import urllib.request, sys
import redef openUrl(url):try:page = urllib.request.urlopen(url, data=None, timeout=5)except urllib.error.HTTPError as e:print(e.code)print(e.reason)return ''except urllib.error.URLError as e:print(e.reason)return ''else: html = page.read().decode('utf-8')return htmldef getList(html, tag):i = html.find(tag)if i == -1:print ('没有找到' + tag)return ''else:con = html[i+len(tag):]#print ("前30个字符:" + con[:30])tag = 'ul'tag_pat = r'(?<=<'+ tag + '>).*?(?=</' + tag + '>)' tag_ex = re.compile(tag_pat, re.M|re.S) con = re.findall(tag_ex, con)#con = html.split('正文')#print (con[0])return con[0]def printList(list, host):#获取textres = r'(.*?)'t = re.findall(res, list, re.S|re.M)#获取hrefres_url = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"h = re.findall(res_url, list, re.I|re.S|re.M)for i in range(len(t)):print (str(i+1) + '\t' + t[i] + '\t' + host + h[i])def main():url = 'http://www.mengxi.net/book/263745/index.html'i = url.index('/', 7)host = url[0 : i]print ('打开' + url)html = openUrl(url)if len(html) > 0:tag = '正文'list = getList(html, tag)printList(list, host)main()程序运行结果如下: