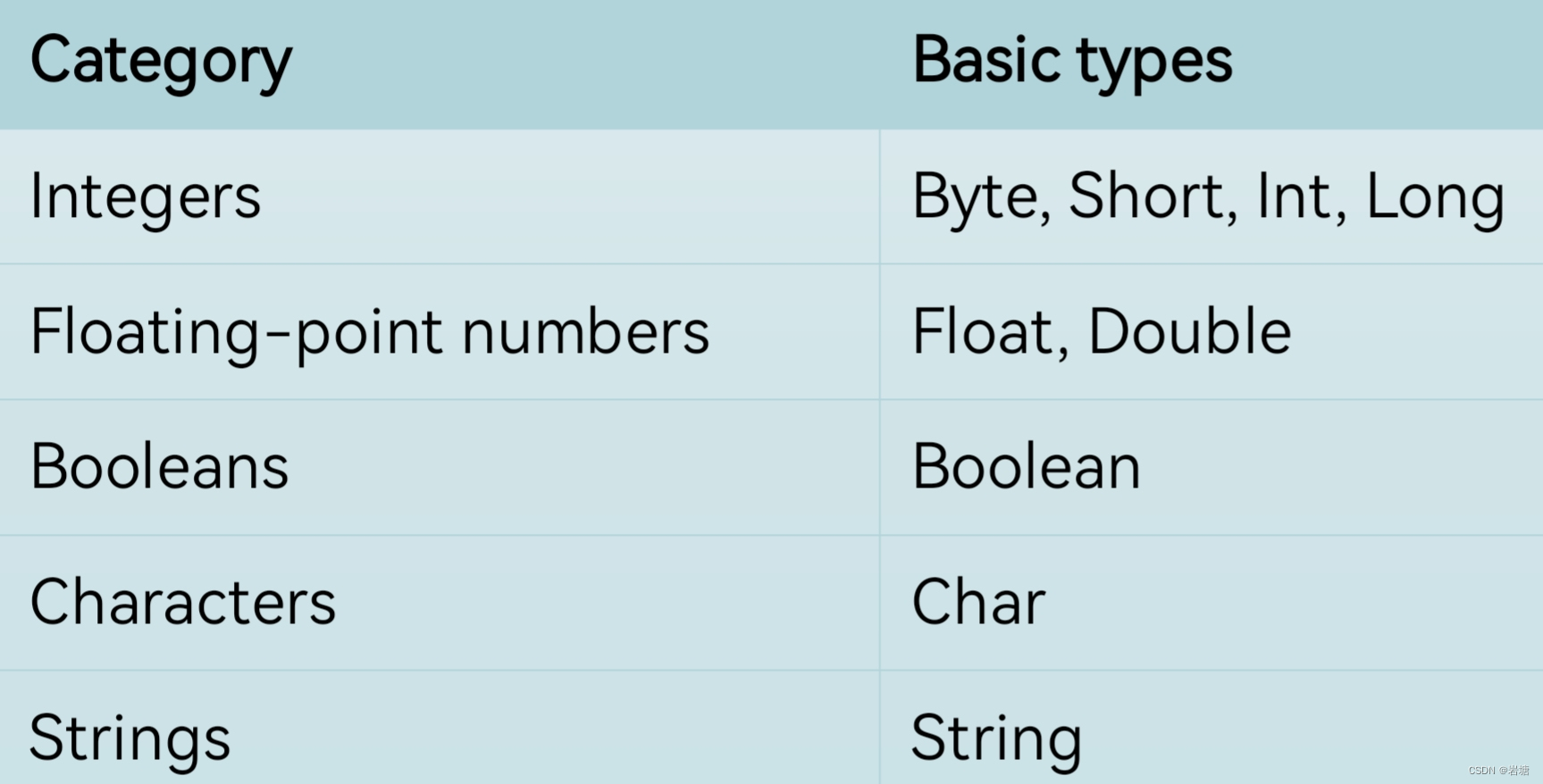
CPU 性能工具。
首先,平均负载的案例。我们先用 uptime, 查看了系统的平均负载;而在平均负载升高后,又用 mpstat 和 pidstat ,分别观察了每个 CPU 和每个进程 CPU 的使用情况,进而找出了导致平均负载升高的进程,也就是我们的压测工具 stress。
第二个,上下文切换的案例。我们先用 vmstat ,查看了系统的上下文切换次数和中断次数;然后通过 pidstat ,观察了进程的自愿上下文切换和非自愿上下文切换情况;最后通过 pidstat ,观察了线程的上下文切换情况,找出了上下文切换次数增多的根源,也就是我们的基准测试工具 sysbench。
第三个,进程 CPU 使用率升高的案例。我们先用 top ,查看了系统和进程的 CPU 使用情况,发现 CPU 使用率升高的进程是 php-fpm;再用 perf top ,观察 php-fpm 的调用链,最终找出 CPU 升高的根源,也就是库函数 sqrt() 。
第四个,系统的 CPU 使用率升高的案例。我们先用 top 观察到了系统 CPU 升高,但通过 top 和 pidstat ,却找不出高 CPU 使用率的进程。于是,我们重新审视 top 的输出,又从 CPU 使用率不高但处于 Running 状态的进程入手,找出了可疑之处,最终通过 perf record 和 perf report ,发现原来是短时进程在捣鬼。
另外,对于短时进程,我还介绍了一个专门的工具 execsnoop,它可以实时监控进程调用的外部命令。
第五个,不可中断进程和僵尸进程的案例。我们先用 top 观察到了 iowait 升高的问题,并发现了大量的不可中断进程和僵尸进程;接着我们用 dstat 发现是这是由磁盘读导致的,于是又通过 pidstat 找出了相关的进程。但我们用 strace 查看进程系统调用却失败了,最终还是用 perf 分析进程调用链,才发现根源在于磁盘直接 I/O 。
最后一个,软中断的案例。我们通过 top 观察到,系统的软中断 CPU 使用率升高;接着查看 /proc/softirqs, 找到了几种变化速率较快的软中断;然后通过 sar 命令,发现是网络小包的问题,最后再用 tcpdump ,找出网络帧的类型和来源,确定是一个 SYN FLOOD 攻击导致的。
到这里,估计你已经晕了吧,原来短短几个案例,我们已经用过十几种 CPU 性能工具了,而且每种工具的适用场景还不同呢!这么多的工具要怎么区分呢?在实际的性能分析中,又该怎么选择呢?
我的经验是,从两个不同的维度来理解它们,做到活学活用。
活学活用,把性能指标和性能工具联系起来
第一个维度,从 CPU 的性能指标出发。也就是说,当你要查看某个性能指标时,要清楚知道哪些工具可以做到。
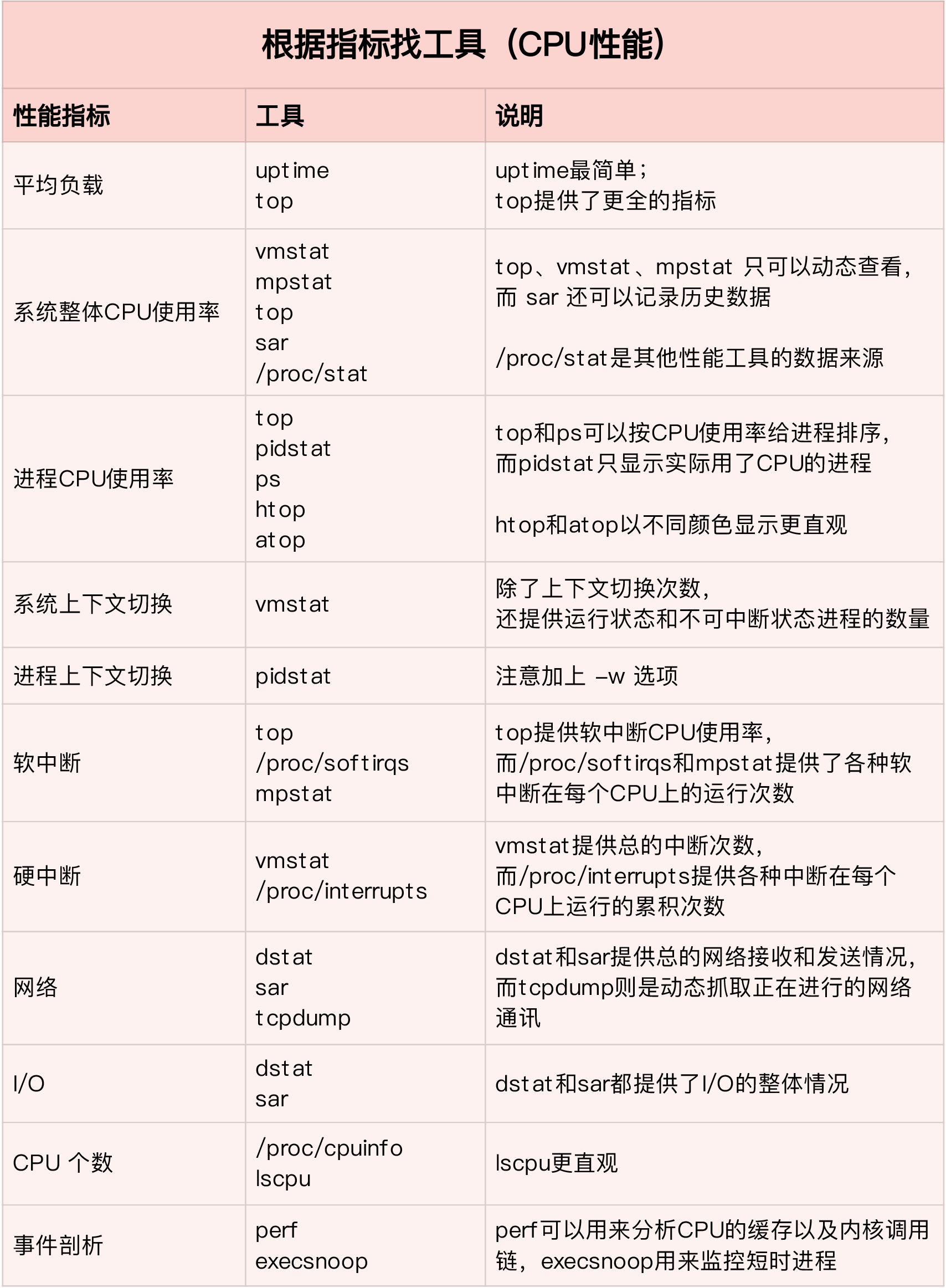
下面,我们再来看第二个维度。
第二个维度,从工具出发。也就是当你已经安装了某个工具后,要知道这个工具能提供哪些指标。
平均负载的案例
uptime的使用

uptime的输出信息理解:
前面的几列比较熟悉,它们分别是当前时间、系统运行时间以及正在登录用户数。
最后三个数字呢,依次则是过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average)。
对于平均负载的理解
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数(进程状态:pass),也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
平均负载为多少时合理?
平均负载最理想的情况是等于 CPU 个数。所以在评判平均负载时,首先你要知道系统有几个 CPU,这可以通过 top 命令(输入数字“1”)或者从文件 /proc/cpuinfo 中读取(#grep ‘model name’ /proc/cpuinfo | wc -l)
举例
既然平均的是活跃进程数,那么最理想的,就是每个 CPU 上都刚好运行着一个进程,这样每个 CPU 都得到了充分利用。比如当平均负载为 2 时,意味着什么呢?
在只有 2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。
在 4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。
而在只有 1 个 CPU 的系统中,则意味着有一半的进程竞争不到 CPU。
平均负载有三个数值,到底该参考哪一个呢?
实际上,都要看。三个不同时间间隔的平均值,其实给我们提供了,分析系统负载趋势的数据来源,让我们能更全面、更立体地理解目前的负载状况。
同样的,前面说到的 CPU 的三个负载时间段也是这个道理。
如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
但如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。
反过来,如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化了。
在实际生产环境中,平均负载多高时,需要我们重点关注呢?
在我看来,当平均负载高于 CPU 数量 70% 的时候,你就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。
但 70% 这个数字并不是绝对的,最推荐的方法,还是把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势。当发现负载有明显升高趋势时,比如说负载翻倍了,你再去做分析和调查。
平均负载与 CPU 使用率
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
三个场景下的观测方法
用 mpstat 和 pidstat ,分别观察了每个 CPU 和每个进程 CPU 的使用情况,进而找出了导致平均负载升高的进程;
通过stree工具模拟三个场景;
工具介绍:
mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
场景一:CPU 密集型进程
首先,我们在第一个终端运行 stress 命令,模拟一个 CPU 使用率 100% 的场景:
首先,我们在第一个终端运行 stress 命令,模拟一个 CPU 使用率 100% 的场景:
接着,在第二个终端运行 uptime 查看平均负载的变化情况:
# -d 参数表示高亮显示变化的区域
$ watch -d uptime
..., load average: 1.00, 0.75, 0.39
最后,在第三个终端运行 mpstat 查看 CPU 使用率的变化情况:
# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据
$ mpstat -P ALL 5
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:30:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:30:11 all 50.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 49.95
13:30:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
13:30:11 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00从终端二中可以看到,1 分钟的平均负载会慢慢增加到 1.00,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。
那么,到底是哪个进程导致了 CPU 使用率为 100% 呢?你可以使用 pidstat 来查询:
# 间隔 5 秒后输出一组数据
$ pidstat -u 5 1
13:37:07 UID PID %usr %system %guest %wait %CPU CPU Command
13:37:12 0 2962 100.00 0.00 0.00 0.00 100.00 1 stress
场景二:I/O 密集型进程
首先还是运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync:
stress -i 1 --timeout 600
场景三:大量进程的场景
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。
比如,我们还是使用 stress,但这次模拟的是 8 个进程:
stress -c 8 --timeout 600
上下文切换的案例-怎么查看 CPU 使用率
知道了 CPU 使用率的含义后,我们再来看看要怎么查看 CPU 使用率。说到查看 CPU 使用率的工具,我猜你第一反应肯定是 top 和 ps。的确,top 和 ps 是最常用的性能分析工具:
top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。
ps 则只显示了每个进程的资源使用情况。
# 默认每 3 秒刷新一次
$ top
top - 11:58:59 up 9 days, 22:47, 1 user, load average: 0.03, 0.02, 0.00
Tasks: 123 total, 1 running, 72 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8169348 total, 5606884 free, 334640 used, 2227824 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7497908 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND1 root 20 0 78088 9288 6696 S 0.0 0.1 0:16.83 systemd2 root 20 0 0 0 0 S 0.0 0.0 0:00.05 kthreadd4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H
...熟悉进程状态
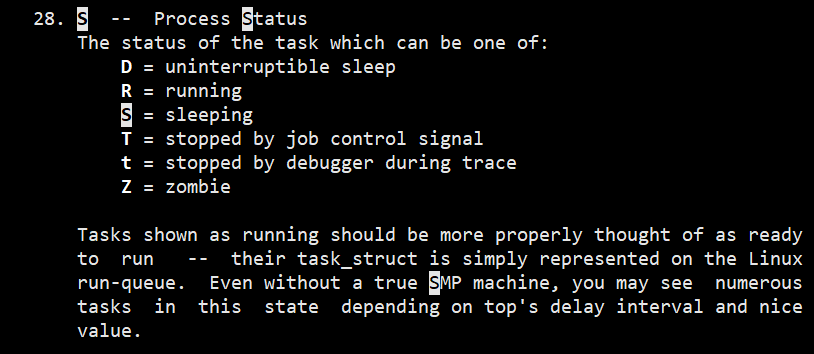
可以查看进程的状态,这些状态包括运行(R)、空闲(I)、不可中断睡眠(D)、可中断睡眠(S)、僵尸(Z)以及暂停(T)等。
不可中断状态,表示进程正在跟硬件交互,为了保护进程数据和硬件的一致性,系统不允许其他进程或中断打断这个进程。进程长时间处于不可中断状态,通常表示系统有 I/O 性能问题。
僵尸进程表示进程已经退出,但它的父进程还没有回收子进程占用的资源。短暂的僵尸状态我们通常不必理会,但进程长时间处于僵尸状态,就应该注意了,可能有应用程序没有正常处理子进程的退出。
这个输出结果中,第三行 %Cpu 就是系统的 CPU 使用率,具体每一列的含义上一节都讲过,只是把 CPU 时间变换成了 CPU 使用率,我就不再重复讲了。不过需要注意,top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。
继续往下看,空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的 CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境中,它还包括了运行虚拟机占用的 CPU。
所以,到这里我们可以发现, top 并没有细分进程的用户态 CPU 和内核态 CPU。那要**怎么查看每个进程的详细情况呢?**你应该还记得上一节用到的 pidstat 吧,它正是一个专门分析每个进程 CPU 使用情况的工具。
用户态 CPU 使用率 (%usr);
内核态 CPU 使用率(%system);
运行虚拟机 CPU 使用率(%guest);
等待 CPU 使用率(%wait);
以及总的 CPU 使用率(%CPU)。
最后的 Average 部分,还计算了 5 组数据的平均值。
# 每隔 1 秒输出一组数据,共输出 5 组
$ pidstat 1 5
15:56:02 UID PID %usr %system %guest %wait %CPU CPU Command
15:56:03 0 15006 0.00 0.99 0.00 0.00 0.99 1 dockerd...Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 15006 0.00 0.99 0.00 0.00 0.99 - dockerdvmstat查看上下文切换次数的使用示例
用 vmstat 看一下空闲系统的上下文切换次数
# 间隔 1 秒后输出 1 组数据
$ vmstat 1 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st0 0 0 6984064 92668 830896 0 0 2 19 19 35 1 0 99 0 0这里你可以看到,现在的上下文切换次数 cs 是 35,而中断次数 in 是 19,r 和 b 都是 0。因为这会儿我并没有运行其他任务,所以它们就是空闲系统的上下文切换次数。
# 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束)
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st6 0 0 6487428 118240 1292772 0 0 0 0 9019 1398830 16 84 0 0 08 0 0 6487428 118240 1292772 0 0 0 0 10191 1392312 16 84 0 0 0你应该可以发现,cs 列的上下文切换次数从之前的 35 骤然上升到了 139 万。同时,注意观察其他几个指标:
r 列:**就绪队列的长度**已经到了 8,远远超过了系统 CPU 的个数 2,所以肯定会有大量的 CPU 竞争。us(user)和 sy(system)列:这两列的 CPU 使用率加起来上升到了 100%,其中系统 CPU 使用率,也就是 sy 列高达 84%,说明 CPU 主要是被内核占用了。in 列:中断次数也上升到了 1 万左右(10191),说明中断处理也是个潜在的问题。
综合这几个指标,我们可以知道,系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高。
到底是什么进程导致了这些问题呢?
# 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束)
# -w 参数表示输出进程切换指标,而 -u 参数则表示输出 CPU 使用指标
$ pidstat -w -u 1
08:06:33 UID PID %usr %system %guest %wait %CPU CPU Command
08:06:34 0 10488 30.00 100.00 0.00 0.00 100.00 0 sysbench
08:06:34 0 26326 0.00 1.00 0.00 0.00 1.00 0 kworker/u4:208:06:33 UID PID cswch/s nvcswch/s Command
08:06:34 0 8 11.00 0.00 rcu_sched
08:06:34 0 16 1.00 0.00 ksoftirqd/1
08:06:34 0 471 1.00 0.00 hv_balloon
08:06:34 0 1230 1.00 0.00 iscsid
08:06:34 0 4089 1.00 0.00 kworker/1:5
08:06:34 0 4333 1.00 0.00 kworker/0:3
08:06:34 0 10499 1.00 224.00 pidstat
08:06:34 0 26326 236.00 0.00 kworker/u4:2
08:06:34 1000 26784 223.00 0.00 sshd
{cswch/s和nvcswch/s字段的含义通过查看帮助 man pidstat了解}
non voluntary context switches the task–非自愿上下文切换任务–nvcs
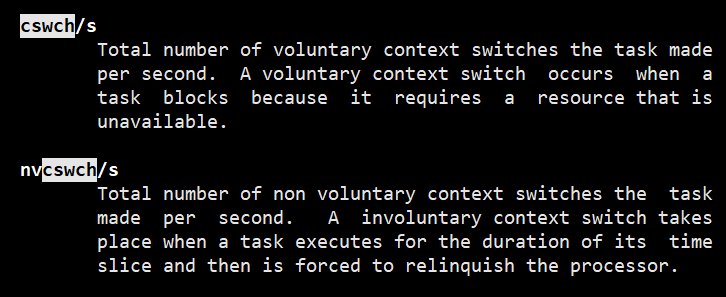
从 pidstat 的输出你可以发现,CPU 使用率的升高果然是 sysbench 导致的,它的 CPU 使用率已经达到了 100%。但上下文切换则是来自其他进程,包括非自愿上下文切换频率最高的 pidstat ,以及自愿上下文切换频率最高的内核线程 kworker 和 sshd。
不过,细心的你肯定也发现了一个怪异的事儿:pidstat 输出的上下文切换次数(cswch/s–自愿上下文切换,nvcswch/s–非自愿上下文切换),加起来也就几百,比 vmstat 的 139 万明显小了太多。这是怎么回事呢?难道是工具本身出了错吗?
别着急,在怀疑工具之前,我们再来回想一下,前面讲到的几种上下文切换场景。其中有一点提到, Linux 调度的基本单位实际上是线程,而我们的场景 sysbench 模拟的也是线程的调度问题,那么,是不是 pidstat 忽略了线程的数据呢?
通过运行 man pidstat ,你会发现,pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标。
所以,我们可以在第三个终端里, Ctrl+C 停止刚才的 pidstat 命令,再加上 -t 参数,重试一下看看:
# 每隔 1 秒输出一组数据(需要 Ctrl+C 才结束)
# -wt 参数表示输出线程的上下文切换指标
$ pidstat -wt 1
08:14:05 UID TGID TID cswch/s nvcswch/s Command
...
08:14:05 0 10551 - 6.00 0.00 sysbench
08:14:05 0 - 10551 6.00 0.00 |__sysbench
08:14:05 0 - 10552 18911.00 103740.00 |__sysbench
08:14:05 0 - 10553 18915.00 100955.00 |__sysbench
08:14:05 0 - 10554 18827.00 103954.00 |__sysbench
...现在你就能看到了,虽然 sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。看来,上下文切换罪魁祸首,还是过多的 sysbench 线程。
中断次数也上升到了 1 万,但到底是什么类型的中断上升了,现在还不清楚。我们接下来继续抽丝剥茧找源头。
怎样才能知道中断发生的类型呢?
既然是中断,我们都知道,它只发生在内核态,而 pidstat 只是一个进程的性能分析工具,并不提供任何关于中断的详细信息,怎样才能知道中断发生的类型呢?
没错,那就是从 /proc/interrupts 这个只读文件中读取。/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况。
# -d 参数表示高亮显示变化的区域
$ watch -d cat /proc/interruptsCPU0 CPU1
...
RES: 2450431 5279697 Rescheduling interrupts
...
观察一段时间,你可以发现,变化速度最快的是重调度中断(RES),这个中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同 CPU 的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)。
所以,这里的中断升高还是因为过多任务的调度问题,跟前面上下文切换次数的分析结果是一致的。
每秒上下文切换多少次才算正常呢?(根据上下文切换的类型,再做具体分析)
这个数值其实取决于系统本身的 CPU 性能。在我看来,如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。
这时,你还需要根据上下文切换的类型,再做具体分析。比方说:
自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题;非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈;中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
CPU 使用率过高怎么办?
通过 top、ps、pidstat 等工具,你能够轻松找到 CPU 使用率较高(比如 100% )的进程。接下来,你可能又想知道,占用 CPU 的到底是代码里的哪个函数呢?找到它,你才能更高效、更针对性地进行优化。
我猜你第一个想到的,应该是 GDB(The GNU Project Debugger), 这个功能强大的程序调试利器。的确,GDB 在调试程序错误方面很强大。但是,我又要来“挑刺”了。请你记住,GDB 并不适合在性能分析的早期应用。
为什么呢?因为 GDB 调试程序的过程会中断程序运行,这在线上环境往往是不允许的。所以,GDB 只适合用在性能分析的后期,当你找到了出问题的大致函数后,线下再借助它来进一步调试函数内部的问题。
那么**哪种工具适合在第一时间分析进程的 CPU 问题呢?**我的推荐是 perf。perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
使用 perf 分析 CPU 性能问题,
我来说两种最常见、也是我最喜欢的用法。
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
$ perf top
Samples: 833 of event 'cpu-clock', Event count (approx.): 97742399
Overhead Shared Object Symbol7.28% perf [.] 0x00000000001f78a44.72% [kernel] [k] vsnprintf4.32% [kernel] [k] module_get_kallsym3.65% [kernel] [k] _raw_spin_unlock_irqrestore
...
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了 833 个 CPU 时钟事件,而总事件数则为 97742399。
另外,采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了 833 个 CPU 时钟事件,而总事件数则为 97742399。
另外,采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
第一列 Overhead ,是该符号的性能事件在所有采样中的**比例**,用百分比来表示。
第二列 Shared ,是**该函数或指令所在的动态共享对象**(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
第三列 Object ,是**动态共享对象的类型**。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
最后一列 Symbol 是符号名,也就是**函数名**。当函数名未知时,用十六进制的地址来表示。
还是以上面的输出为例,我们可以看到,占用 CPU 时钟最多的是 perf 工具自身,不过它的比例也只有 7.28%,说明系统并没有 CPU 性能问题。 perf top 的使用你应该很清楚了吧。
接着再来看第二种常见用法,也就是 perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
$ perf record # 按 Ctrl+C 终止采样
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.452 MB perf.data (6093 samples) ]$ perf report # 展示类似于 perf top 的报告
在实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。