题目
假设你在Uber工作。rides表包含了关于Uber用户在美国各地的行程信息。
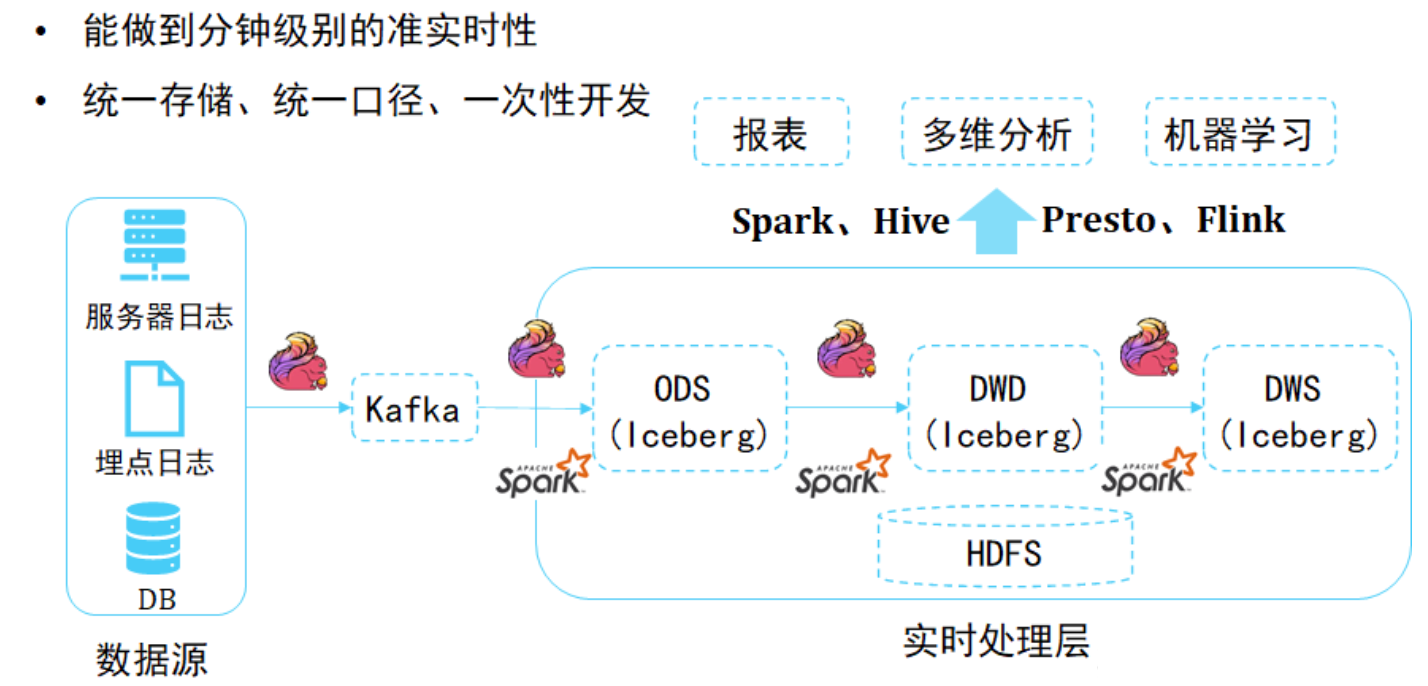
编写一个查询,以获取纽约(NY)每位通勤者的平均通勤时间(以分钟为单位),以及纽约所有通勤者的平均通勤时间(以分钟为单位)。
示例:
输入:
rides表
| 列名 | 类型 |
|---|---|
id | INTEGER |
commuter_id | INTEGER |
start_dt | DATETIME |
end_dt | DATETIME |
city | VARCHAR |
输出:
| 列名 | 类型 |
|---|---|
commuter_id | INTEGER |
avg_commuter_time | FLOAT |
avg_time | FLOAT |
结果显示如下:
commuter_id | avg_commuter_time | avg_time |
|---|---|---|
| 11 | 27 | 45 |
| 22 | 97 | 45 |
| 33 | 11 | 45 |
答案
解题思路
一般思路是,先计算纽约的平均通勤时间,然后再计算个人的,最后把结果汇总在一起。
其实,直接用窗口函数可以直接得出结果。
答案代码
下面是直接用一个窗口函数,完成对每个ID的平均值计算。
SELECT DISTINCTcommuter_id,FLOOR(AVG(TIMESTAMPDIFF(MINUTE,start_dt,end_dt)) OVER (PARTITION BY commuter_id)) avg_commuter_time,FLOOR(AVG(TIMESTAMPDIFF(MINUTE,start_dt,end_dt)) OVER ()) avg_time
FROM rides
WHERE city = 'NY'
FLOOR(): 用于向下取整,将平均值舍入到最接近的整数。TIMESTAMPDIFF(): 用于计算两个时间戳之间的差值,单位为分钟。AVG( ) OVER (PARTITION BY commuter_id): 用于对每个commuter_id进行分组,并计算每个分组的平均值。AVG() OVER ():OVER ()`表示在整个数据集上进行计算
计算时间差的函数
TIMESTAMPDIFF()
TIMESTAMPDIFF(unit, start_datetime, end_datetime) 是一个用于计算两个日期时间之间差异的 MySQL 函数。它接受三个参数:时间单位、起始日期时间和结束日期时间。
在我们的答案中就用了TIMESTAMPDIFF(MINUTE, start_dt, end_dt)
TIMESTAMPDIFF` 函数的时间单位参数可以是以下之一:
MICROSECOND: 微秒SECOND: 秒MINUTE: 分钟HOUR: 小时DAY: 天WEEK: 周MONTH: 月QUARTER: 季度YEAR: 年
DATEDIFF()
DATEDIFF(date1, date2): 这个函数返回两个日期之间的天数差异。它接受两个日期参数,并返回 date2 减去 date1 的天数差异。
TIMESTAMPDIFF() 可以用来计算date 格式吗?
TIMESTAMPDIFF() 函数通常用于计算两个日期时间之间的差异,因此它的参数通常是 DATETIME 或 TIMESTAMP 类型的数据。虽然可以接受 DATE 类型的数据作为参数,但是在处理时会将 DATE 类型的数据隐式转换为 DATETIME 类型,并将时间部分视为零值。
举个例子,如果你要计算两个日期之间的差异:
SELECT TIMESTAMPDIFF(DAY, '2022-01-01', '2022-01-05');
这将返回 4,表示 ‘2022-01-01’ 到 ‘2022-01-05’ 之间相隔 4 天。
虽然 TIMESTAMPDIFF() 可以处理 DATE 类型的参数,但是如果只是想计算日期之间的天数差异,使用 DATEDIFF() 更为简单和直观。