欢迎来到博主的专栏——C语言数据结构
博主ID:代码小豪
文章目录
- 冒泡排序
- 冒泡排序的代码及原理
- 快速排序
- 快速排序的代码和原理
- 快速排序的其他排序方法
- 非递归的快速排序
冒泡排序
相信冒泡排序是绝大多数计科学子接触的第一个排序算法。作为最简单、最容易理解的排序算法,冒泡排序虽然效率不高,但是冒泡排序的思路给了其他排序算法一些启发。
冒泡排序的思路如下:
(1)从第一个数据开始,向后继元素比较大小、若满足条件(大于或小于),则交换数据的位置,然后从后一个位置开始继续比较。
(2)当N-1与N进行数据比较后、完成一趟冒牌排序,然后从头开始继续进行冒牌排序
(3)完成N-1趟排序后、冒牌排序结束。


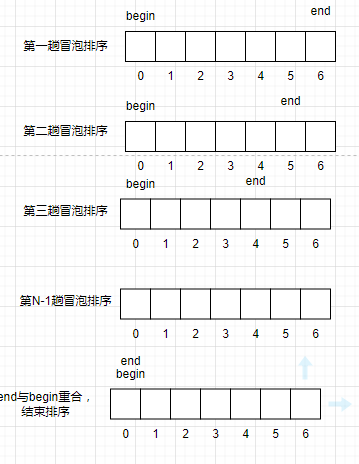
可以发现、在第一趟冒泡排序结束后,最大值7排到了最后一位,而升序数组中的7也是排到最后一位。这一趟冒泡排序就确定了升序数组中的一位。
当第二趟冒泡排序开始时,由于最后一位的数据已经确定了,因此不再需要参与排序,将end向前移动一位,以此类推。
冒泡排序的代码及原理
void Swap(int* e1, int* e2)//交换函数
{int tmp = *e1;*e1 = *e2;*e2 = tmp;
}
void BubbleSort(int* a, int n)
{for (int i = 0; i < n-1; i++)//共计排n-1趟{int end = n - i - 1;for (int begin = 0;//每趟冒泡排序从0开始begin < end;//当begin=end时结束begin++){if (a[begin] > a[begin + 1])//满足条件交换数据{Swap(&a[begin], &a[begin + 1]);}}}
}
冒牌排序的原理如下:
每一趟冒泡排序都能使至少一个数据处于正确的升降序的位置。即每趟排序都能让当前范围的最大值,位于最后一个位置,好比水中的鱼吐出的泡泡,从水底到水面渐渐变大。
快速排序
快速排序和冒泡排序都有一个相似之处,或者是一种排序的思路,即一趟排序完成单个或多个数据的定位(将数据排在最终确定的位置上),多次排序后将所有数据都完成定位,最终完成排序操作。
冒泡排序的思路是每次确定最后一位,因此每趟排序都需要将整个数组遍历一遍,导致时间复杂度非常高。快速排序作为最著名昭著的排序算法,以高效率深受程序员喜爱,这里讲讲快排的优化之处。
先来了解一下快速排序的步骤:
(1)选取数组中的任意一个数据作为关键数据(key)
(2)让key左边的数据小于(大于)key,右边的数据大于(小于)key
(3)将整体分割为两部分,一部分是key左边,另一部分是key右边,以这些部分作为一个整体,重复(1)(2)(3)操作,直到所以数据不可分割为止。
这个思路单凭讲述时很难理解其中奥义的。我们先拆分步骤逐渐讲解。
(1)选取key可以选择区间中的任意数据,选取方法通常有三种:取队首、取队尾、随机值取中间数,通常来说结合三数取中(即在队首、队尾、随机之间选择中间数作为key)是最合理的。但这里为了方便讲解,选择取队首作为key
(2)中让key左边的数据小于key,右边的数据大于key有多种方法,总体而言对效率影响不大,我们先来了解快排发明者霍尔的方法。
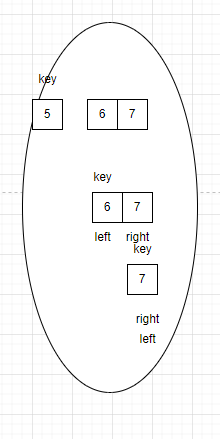
首先将待排序的区间选出,队首第一个值为key值。区间最左边设置一个left,最右边设置一个right。如图:
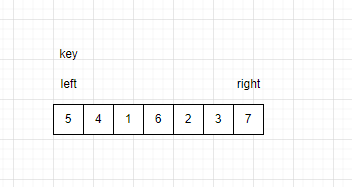
让right往左边遍历,若遍历的数据小于key,则right停留在该数据处。
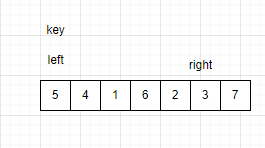
当right找到比key小的数后,让left向右遍历找到比key大的数。找到比key大的数后,停留在该数据处。

当left和right都停留时,交换left和right
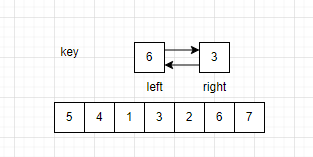
交换结束后,重复上述步骤,让right向左遍历。
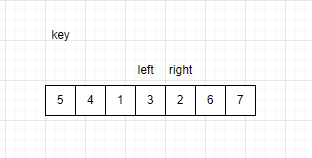
此时left继续向右遍历,left与right重合,此时将key与重合位置的数据交换。
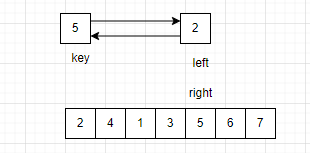
以key为分割线,将这段区间分为两个区间。
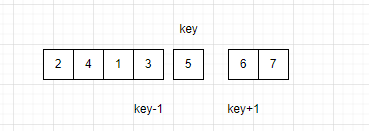
再对这两个区间进行快排。以此类推。
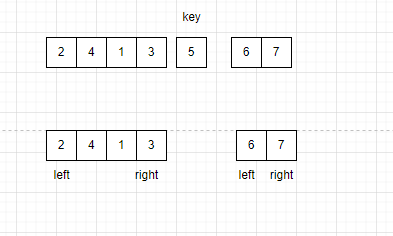
当某个区间的left和right重合,数据不可再分割,不再需要排序。
快速排序的代码和原理
快速排序的原理如下:
和冒泡排序有个类似的点,每一趟冒泡排序都有一个数据被定位,快速排序也是如此,key位置的左边小于key,右边大于key,那么key这个位置就是符合排序要求的位置的。那么快速排序比冒泡排序有效率的点在哪呢?
冒泡排序每趟排序都需要将整个数组遍历一遍。快速排序使用了一种分治的方法,将区间分割成多个小区间进行排序,减少了需要遍历的元素个数。
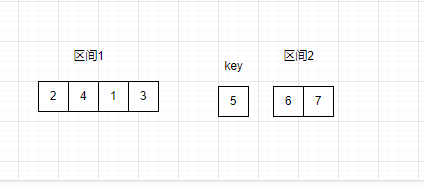
此时快速排序就不再需要遍历整个数组了,而是遍历小区间,遍历区间1只用遍历4个数据,定位一个,区间2只需遍历2个数据,定位1,当数据数量变得很多时,快速排序的优势更加明显,效率更快。
代码如下:
void QuickSort(int* a, int begin, int end)
{int left = begin;int right = end-1;if (left >= right)//区间不可再分割,结束递归{return;}int key = left;//队首取keywhile (left < right)//遍历条件{while (left < right && a[key] < a[right])//right向左寻找比key小的值{right--;}while (left < right&&a[key]>a[left])//left向右寻找比key大的值{left++;}Swap(&a[left], &a[right]);//找到之后交换}Swap(&a[key], &a[left]);//left与right相等,与key交换。key = left;QuickSort(a, begin, key);//分割QuickSort(a, key + 1, end);//分割
}
快速排序的其他排序方法
这里介绍另外一种排序方式——前后指针法。霍尔使用left和right的找寻方法非常巧妙,但是代码较复杂。这里讲一种较为简洁的找寻方法(对效率影响不大)。
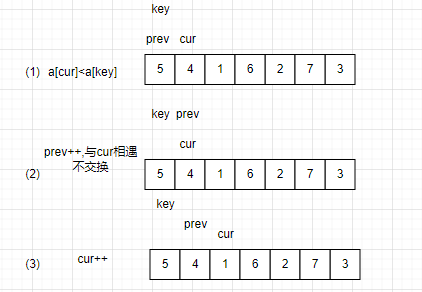
定义一个prev和cur指向队首与队首的后一个元素,key值仍取队首。
步骤如下:
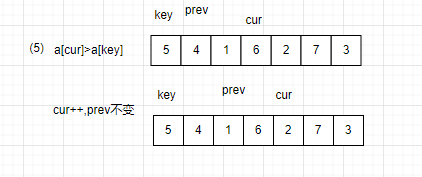
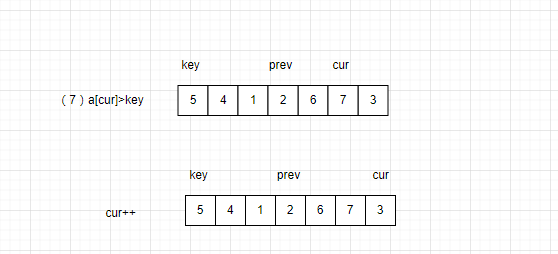
(1)判断cur的值是否大于prev
若大于:cur往前移动一位,prev不变。
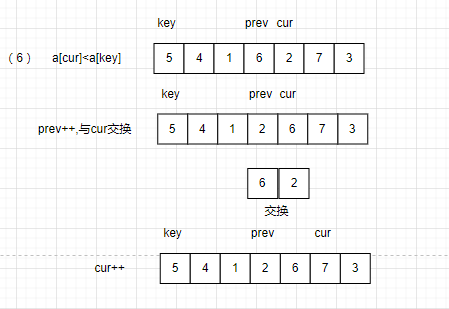
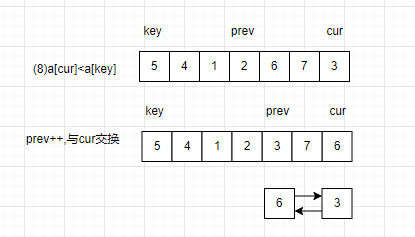
若小于:prev往前移动一位,与cur交换数据,cur再往前移动一位。(若prev指针与cur相遇,不交换)。
(2)当cur超出区间后,让key与prev交换数据。
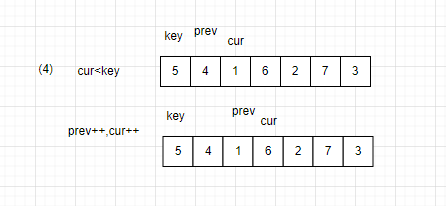
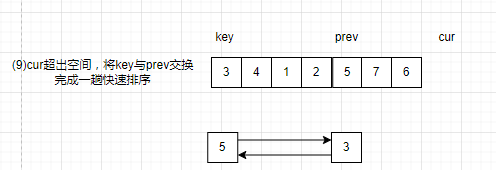
剩下也是将key分割两个区间继续分治,只是找寻方法改变了。
为什么这种方法能完成key的左边比key小,右边比key大呢?
首先,我们可以发现,cur与prev之间的元素都是比key大的。我们重新回顾一下步骤。
(1)最初开始时,prev与cur之间不存在任何数据(因为他们相邻)。
(2)cur与prev最初是挨着的,当cur遍历到比key大的树据才会有所距离(此时距离之间的数据都是比key大到数)。
(3)为了保持cur与key之间的数都是大于key值,需要将prev后一位的数据(一定大于key),与小于key值的cur进行交换
(4)最后prev的值一定是小于key的(因为此时prev的值是从小于key的cur值里交换而来的)。所以prev一定小于key。
如果prev和cur中间的数据保持比key大,那么当cur超出范围时,key左边一定小于key,右边一定大于key
代码如下:
void QuickSort(int* a, int begin, int end)
{if (begin >= end)//区间不可分割时,停止递归{return;}int prev = begin;int cur = begin + 1;int key = begin;while (cur < end)//cur没超出区间{if (a[cur] <= a[key])//当cur小于key的值时{prev++;if (prev != cur){Swap(&a[prev], &a[cur]);}}cur++;//不管是大于key还是小于key,cur最后都要++}Swap(&a[prev], &a[key]);key = prev;QuickSort(a, begin, key);QuickSort(a, key+1, end);
}
非递归的快速排序
前面讲了快排的递归形式,但是递归就说明需要大量的调用堆栈,一旦递归深度过高,就会导致栈溢出,因此有人想出了快速排序的非递归方法。
想要替代递归的作用,就得先找到为什么使用递归以及递归是为了实现什么。
快速排序中的递归起的作用是为了记录分割的区间的起始点与结束点
QuickSort(a, begin, key);
QuickSort(a, key+1, end);
如果我们有办法将每趟快速排序的分割区间记录下来。就能取代递归的作用。
我们可以创建一个栈,用来记录快速排序的区间。这样子就不再需要递归了。
记录的步骤如下:
(1)将左区间和右区间压入栈中
(2)将左区间和右区间弹出。将弹出的数据作为一个区间进行一趟快速排序
(3)完成快速排序后,将新分割好的节点压入栈中
(4)若取出的左右区间不构成新区间,不执行这个操作。
循环往复,直到栈变成空栈。
代码如下:
void QuickSort(int* a, int begin, int end)
{stack s1;StackInit(&s1);//初始化栈StackPush(&s1,begin);//压入左区间StackPush(&s1,end);//压入右区间while (!StackEmpty(&s1)){int right = StackTopData(&s1);//出栈StackPop(&s1);int left = StackTopData(&s1);//出栈StackPop(&s1);int cur = left+1;int prev = left;int key = left;while (cur < right){if (a[cur] < a[key]){prev++;if (prev != cur){Swap(&a[cur], &a[prev]);}}cur++;}Swap(&a[prev], &a[key]);key = prev;//[left,key],[key+1,right]if (left < key){StackPush(&s1, left);//压入分割后的左区间StackPush(&s1, key);//压入分割后的右区间}if (key + 1 < right){StackPush(&s1, key + 1);//压入分割后的左区间StackPush(&s1, right);//压入分割后的右区间}}StackDestory(&s1);
}
栈的实现函数
void StackInit(stack* ps)//栈的初始化
{ps->data = NULL;ps->capacity = 0;ps->top = 0;
}void StackPush(stack* ps, datatype n)//压栈
{assert(ps);if (ps->top == ps->capacity){int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;datatype* tmp = (datatype*)realloc(ps->data, sizeof(stack) * newcapacity);assert(tmp);ps->data = tmp;ps->capacity = newcapacity;}ps->data[ps->top] = n;ps->top++;
}void StackPop(stack* ps)//出栈
{if (StackEmpty(ps)){perror("Stack is empty\n");return;}ps->top--;
}bool StackEmpty(stack* ps)//判断是否空栈
{return ps->top == 0;
}datatype StackTopData(stack* ps)//取栈顶
{if (StackEmpty(ps)){perror("Stack is empty\n");exit(1);}return ps->data[ps->top - 1];
}void StackDestory(stack* ps)//销毁栈
{assert(ps);free(ps->data);ps->data = NULL;ps->top = 0;ps->capacity = 0;
}





![[WinForm开源]原神混池模拟器-蒙德篇:软件的基本介绍、使用方法、常见问题解决与代码开源](https://img-blog.csdnimg.cn/direct/bb8f21542c99420aae39e801b56d2226.png)