1.问题引入
接着前两节课的内容,今天我们要构建一个人工智能系统。
它的目的是像人类一样,区分评价的情感是正面还是负面的。
接下来,我们要对提取的文本进行感情色彩的分析,这个就是文本情感分析,我们要使用机器学习里面的--------监督学习
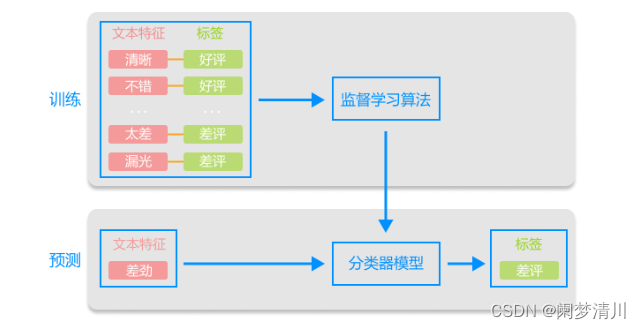
2.监督学习
监督学习是机器学习的一种,是指通过让机器去学习我们“标记好”的数据集,训练出一个模型,然后根据该模型对“未标记”的数据进行分类或预测。
举一个通俗的例子:在学习中,父母帮忙指正“对”和“错”。根据父母的指导,我们有了自己的判断。在下次碰到的时候,我们也能分辨出“对”和“错”。这就是我们在父母的帮助下“监督”学习。
在监督学习中,用于训练模型的数据都既有特征(feature)又有对应标签(label)。
我们将这样的数据集称为训练集(train set)。
通常,特征需要使用代码提取,标签则是人工直接标注在数据集上的。
原始的数据集在提取完文本和标签以后,就要被随机划分为2个部分,训练集和测试集;
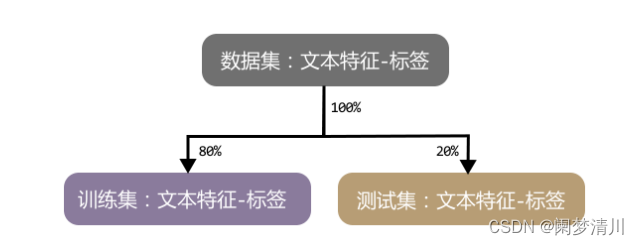
这个随机的比例不是固定的,我们在自己的代码里面可以进行对应的设置,一般是大部分的用来训练找到对应的算法,少部分测试集用来测试这个算法是否准确;
3.提取数据集中的文本特征和对应的标签
这个其实我们昨天已经实现了,我们昨天的就是提取词频数大于15的,但是我们想要用机器学习实现分类器模型的构造,我们就必须提取所有的评论,而不是评价的次数大于15的词语了,所以我们要把原来的max_features=15去掉:
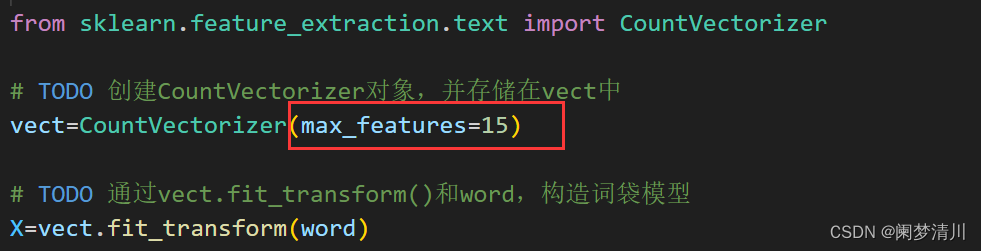
为了训练分类器模型,我们需要将文本特征从稀疏矩阵转换为一个二维的NumPy数组。
这是因为每条评价都对应多个特征,通过二维数组的行和列,可以清晰定位出某一个词语在某条评价里出现的次数。同时,不论之后选择哪一种机器学习的算法,都可以直接传入NumPy数组进行训练,非常方便。
我们只需对X使用toarray()函数,就可以将其转换为二维数组了。
我们已经获得了数据集,接下来就要提取数据集的标签:
# 创建一个空列表y,用于存储标签
y = []
# TODO 使用for循环遍历data,将遍历的数据存储到allInfo变量中
for allInfo in data:# TODO 提取allInfo中的标签数据,并存储在变量label中label = allInfo[1]# TODO 使用append()函数,将标签逐一添加到列表y中y.append(label)# 输出列表y进行查看
print(y)4.将数据集划分为训练集和测试集
我们可以借助sklearn.model_selection这个模块,它包含了划分数据的相关功能。
该模块中有一个train_test_split类,其中的train_test_split()函数,可按照用户设定的比例,将数据集随机划分为训练集和测试集。
# TODO 从sklearn.model_selection中导入train_test_split
from sklearn.model_selection import train_test_split# TODO 划分数据集,将数据分为训练集和测试集
result = train_test_split(X, y, train_size=0.8, random_state=1)# 输出result进行查看
print(result)X:将需要进行划分的数据集的文本特征(简单来说就是前面的评价部分);
y:简单来说就是后面的标签(好评还是差评);
train_size=0.8:我们从数据集里面选择80%的作为训练集(就是通过这个80%)的出一种算法,让剩下的20%测试这个算法;
random_state=1:随机种子,让每次的数据划分一致。






![[WinForm开源]原神混池模拟器-蒙德篇:软件的基本介绍、使用方法、常见问题解决与代码开源](https://img-blog.csdnimg.cn/direct/bb8f21542c99420aae39e801b56d2226.png)