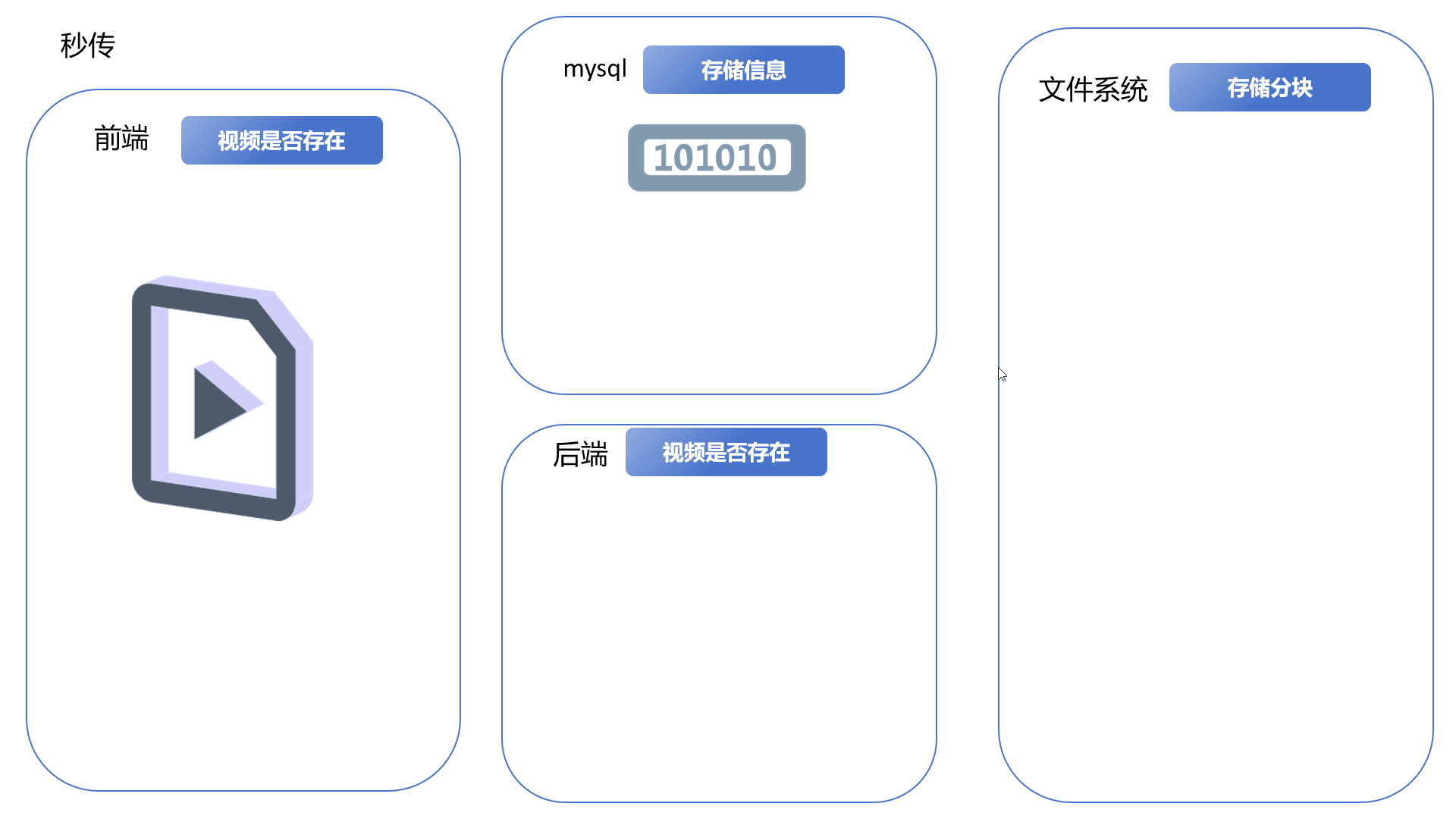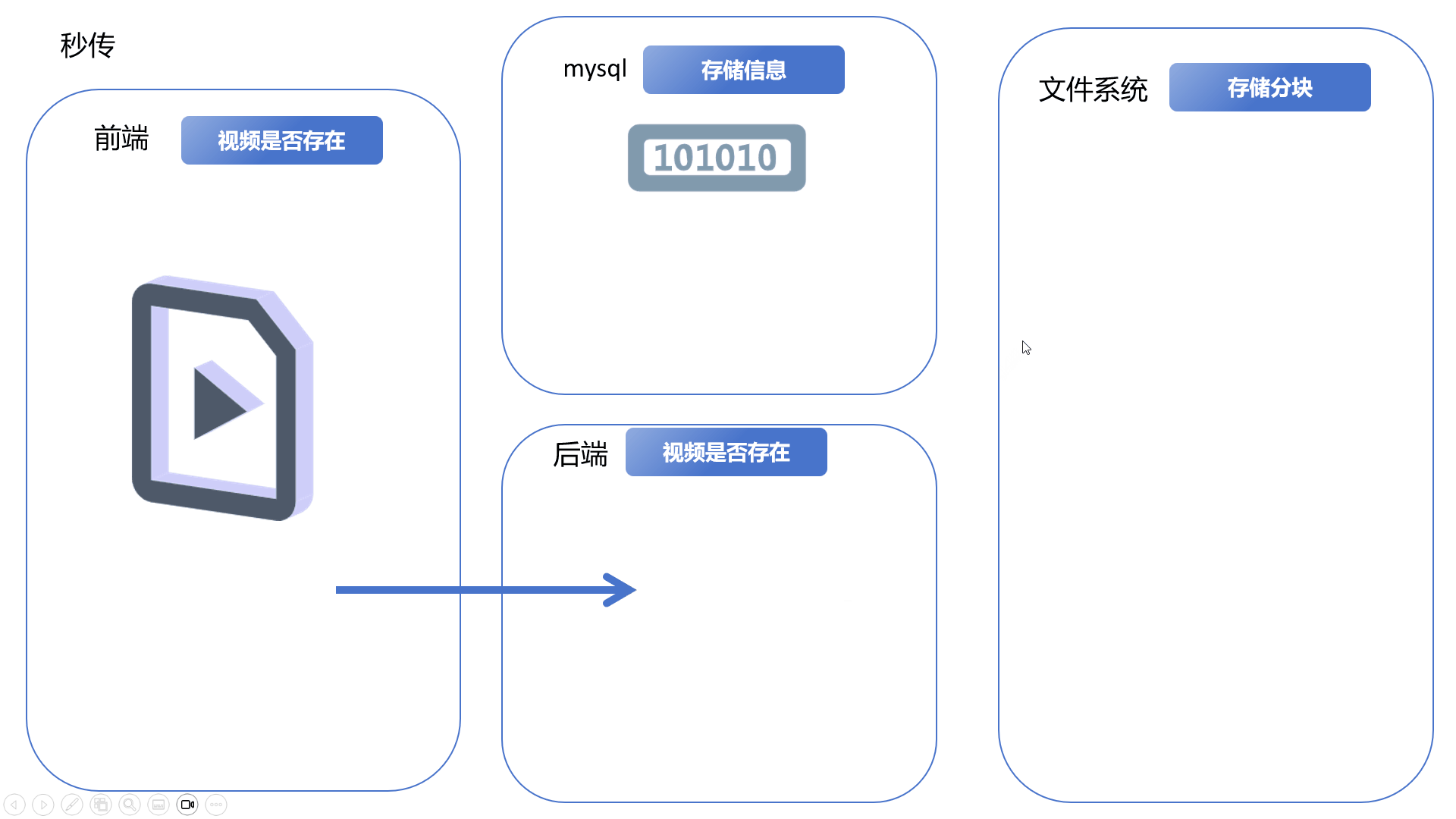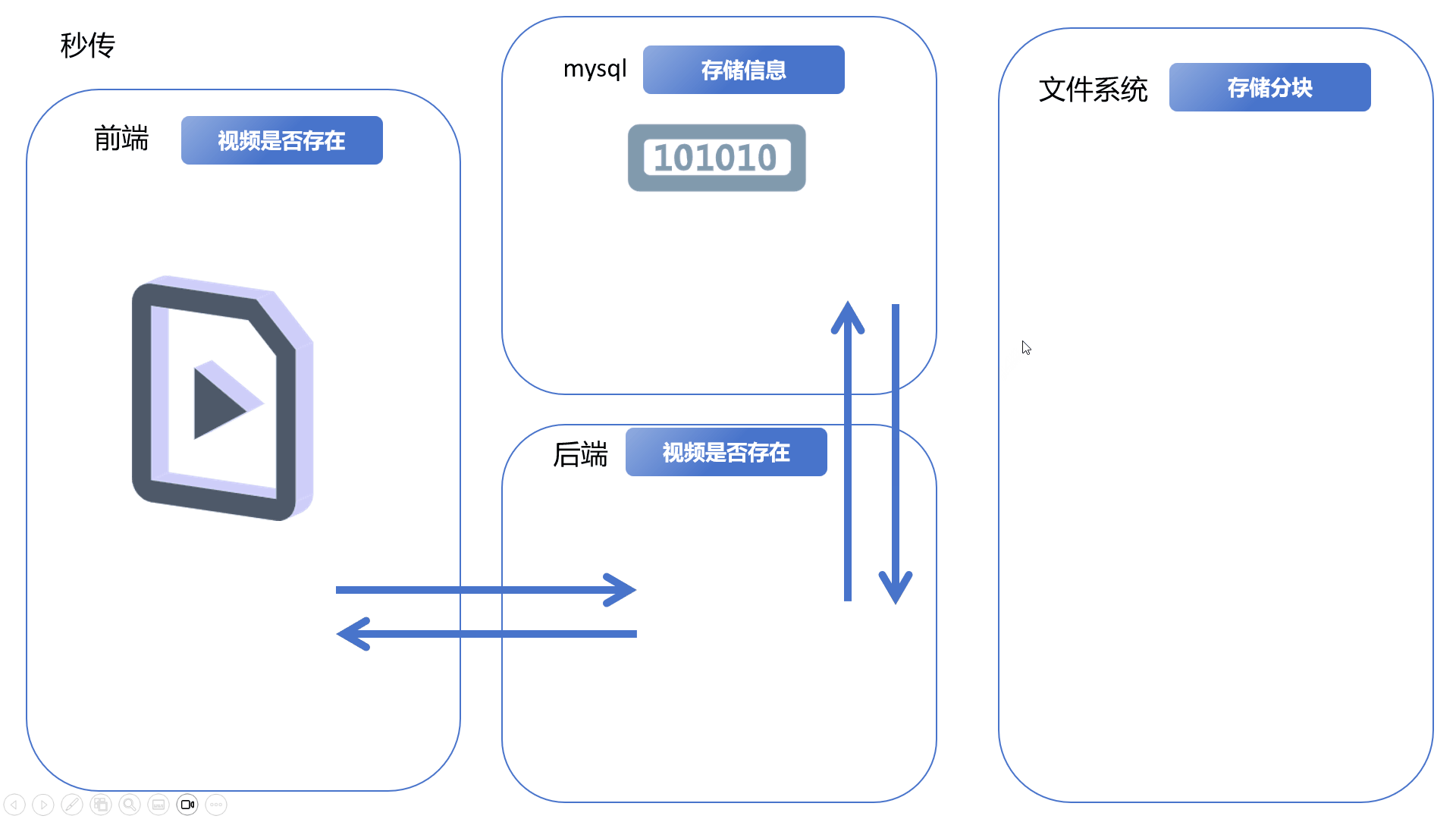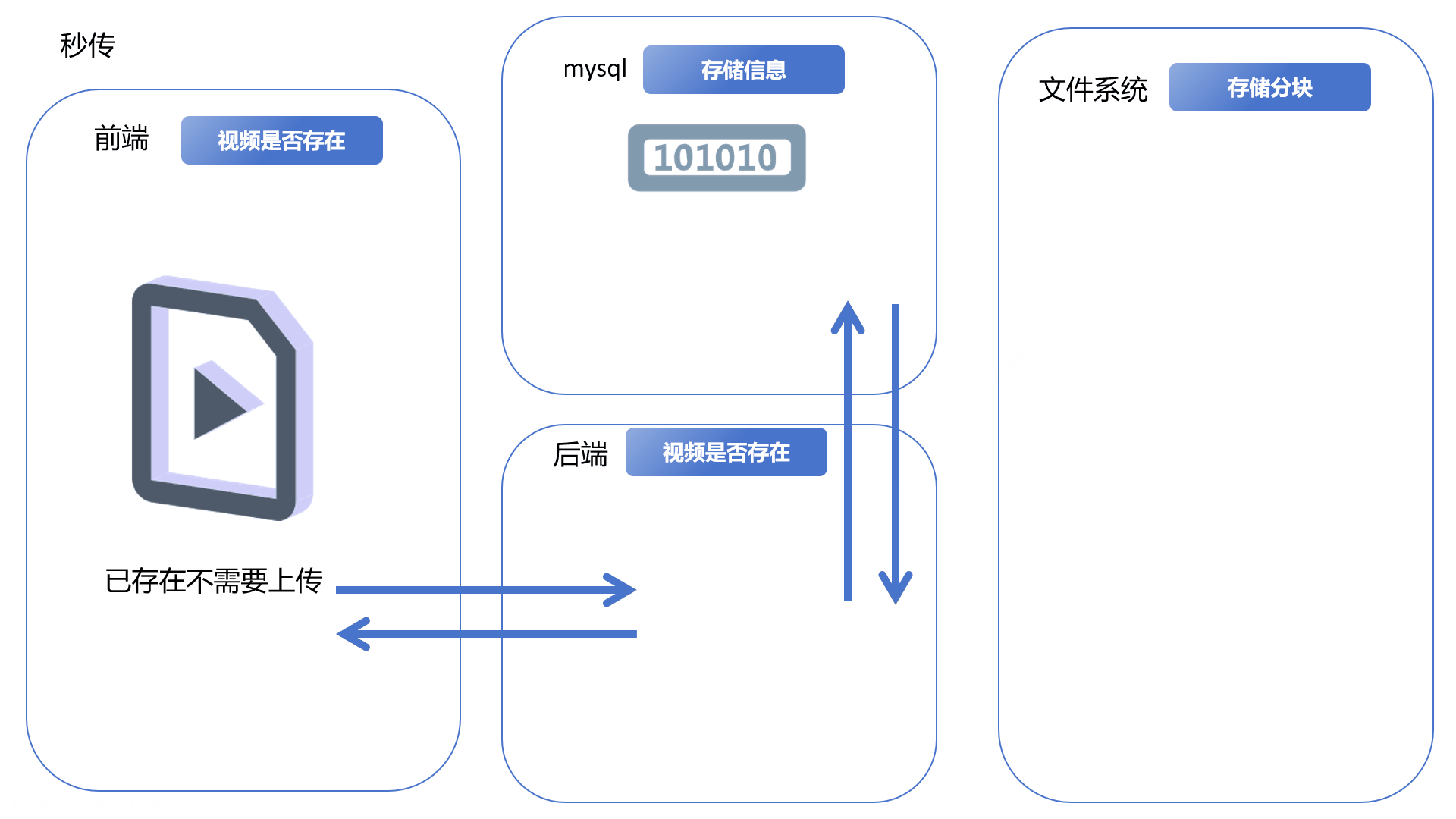
在实际的应用中,其实大多数是主从结构。而采用主备,一般都需要一定的费用。
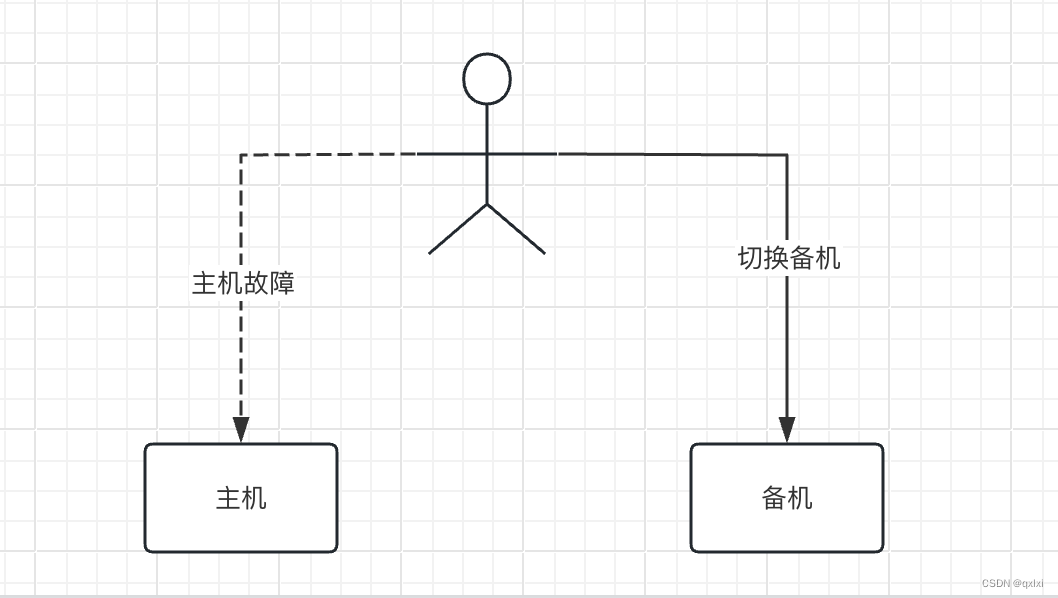
对于主备,如果主机故障,那么只需要直接将流量打到备机就可以,但是对于一主多从,还需要将从库连接到主库上。
对于切换的操作,一种是主动切换,(人为升级配置),另一种是被动切换,(主机故障)。那么如何判断一个数据库是否出问题。
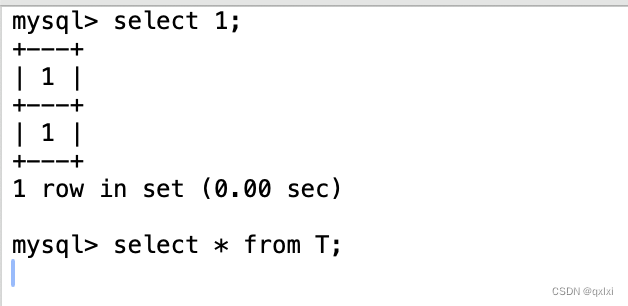
select 1 判断
set global innodb_thread_concurrency=1;
| session A | session B |
|---|---|
| select sleep(100) from T; | select 1; |
| select * from T; |
innodb_thread_concurrency 控制InnoDB的并发线程上限,达到这个值,InnoDB在接受新的请求,就会进入等待状态,直到有退出的线程,才会执行。
我们讲 innodb_thread_concurrency 设置为1,然后session A就阻塞,然后在执行session B中的 select 1 ,发现正常返回结果,1,但是如果查询表T 发现被阻塞了。所以select 1 只能表示数据库进程还在,但是检测不出问题。
并发连接和并发查询
innodb_thread_concurrency 默认参数是0,表示不限制并发连接数。一般并发数会受到操作系统底层的线程。建议设置在 64-128之间。 那么可能有人会想,128并发连接数是不是有点低。因为对于大型互联网应用来说,动辄都是秒级别的上万流量。
其实并发连接和并发查询不是同一个事情,并发连接是客户端和服务端建立了连接,多占用内存。也就是通过 show processlist , 而并发查询是当前正在执行的语句。
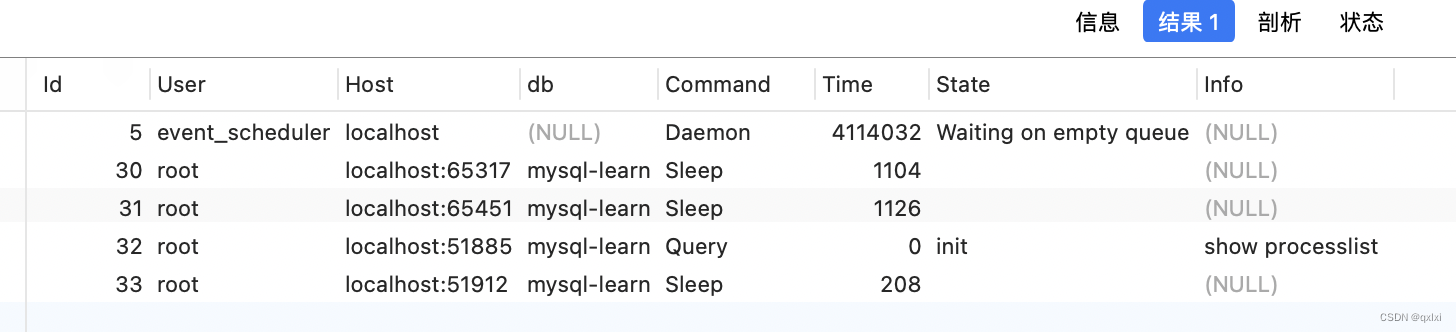
那么处于锁等待的线程是否占用并发线程的计数,其实是不占用的,因为锁等待的线程是不占用CPU,没有必要占用。
查表判断
为了避免因并发线程数过多而导致的系统不可用,可以创建一张health_check 里放一条数据。然后定期执行。
select * from mysql.health_check;
但是,如果bin log的磁盘满了,那么就会导致无法更新语句,但是可以正常读取。之前在生产的时候就遇到过,磁盘满,查询语句可以执行,但是更新语句无法执行。
更新判断
update mysql.health_check set t_modified=now();
既然要更新,那么可以采用时间做处理,但是针对主从库检测的话,如果同步修改从库,那么就会出现行冲突,从库即接受主库的bin log,也接受自己的更新。所以可以采用多条数据。
mysql> CREATE TABLE `health_check` (`id` int(11) NOT NULL,`t_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`)
) ENGINE=InnoDB;/* 检测命令 */
insert into mysql.health_check(id, t_modified) values (@@server_id, now()) on duplicate key update t_modified=now();
但是这种方式其实有一定的随机性,那就是IO利用率已经100%。可能我们执行的update语句很快执行完毕,在超时时间内返回的,那么我们就无法检测出系统是否故障。
内部统计
当然我们可以采用 performance_schema 库本身的 redo log的时间统计。
总结
其实对于数据库来说,推荐使用 更新语句+内部统计的方式,其实不仅仅对于数据库来说,对于业务系统来说,需要保证服务高可用,而目前所在公司的方案是采用SLB+健康检查接口进行判断服务是否高可用。弊端的话 其实没有办法检测服务异常,只能检测服务进程是否宕机。


![[C#]OpenCvSharp使用帧差法或者三帧差法检测移动物体](https://img-blog.csdnimg.cn/direct/fcdbca9fb19848e4afe4d34a102b6544.png)