deepseek 本地部署
纯新手教学,手把手5分钟带你在本地部署一个私有的deepseek,再也不用受网络影响。流畅使用deepseek!!!
如果不想看文章,指路:Deep seek R1本地部署 小白超详细教程 ,请大家多多投币,不胜感激~~
Ollama 下载安装
-
Ollama官网指路:Ollama,下载这步都会就没必要截图了,如果下载的慢建议科学上网,多试试。
-
在C盘以外的盘新建一个
Ollama文件夹存放ollama的安装位置(为什么要这样做,因为ollama不能指定安装位置)。 -
注意下载完成后不要立刻点击安装,将下载的可行性程序(OllamaSetup.exe)在文件资源管理器中打开,输入cmd

-
在命令行中执行如下命令:
ollamasetup.exe /DIR=+文件夹路径,这个文件夹的路径就是你创建的Ollama文件夹。

-
指定位置安装后如下图所示:

-
现在要修改模型默认下载的位置(因为模型下载也是默认在C盘的,但是一般模型体积会很大,C盘吃不消的),在C盘以外的盘新建一个
ollamaimagers文件夹存放ollama的安装位置。 -
编辑系统环境变量:
OLLAMA_MODELS,完成后,保存重启电脑,让环境变量生效。
小结:现在已经完成了Ollama指定位置的安装,和模型指定位置的安装
模型下载
-
模型网址链接:deepseek-r1
-
根据你自己的电脑配置,选择合适的模型进行下载,笔者这里使用的为1.5b模型,在命令行窗口中输入:
ollama run deepseek-r1:1.5b
-
中途如果下载很慢,可以按
ctrl + c结束下载,再运行模型下载的命令,会接着继续下载。
-
成功下载后,即可与本地deepseek对话。
附件
这是由deepseek推荐的各个模型的显卡配置:
| 模型规模 | 推荐显存(推理) | 推荐显卡(推理) | 推荐显存(训练) | 推荐显卡(训练) | 备注 |
|---|---|---|---|---|---|
| 1.5B | ≥4GB | GTX 1660 (6GB)、RTX 3050 (8GB) | ≥8GB | RTX 3060 (12GB)、RTX 2080 Ti (11GB) | FP16推理,训练需额外显存。 |
| 7B | ≥16GB | RTX 3090 (24GB)、RTX 4090 (24GB) | ≥24GB | 单卡A100 40GB、双RTX 3090(并行) | 无量化时需24GB显存;4位量化可降至约8GB,单卡RTX 3090即可推理。 |
| 8B | ≥16GB | RTX 3090 (24GB)、Tesla T4 (16GB) | ≥32GB | 双A100 40GB(并行) | 需注意T4可能因带宽不足导致速度较慢。 |
| 14B | ≥28GB | 单卡A100 40GB、双RTX 3090(并行) | ≥56GB | 双A100 40GB(并行)或四RTX 3090 | 4位量化推理需约14GB,单卡RTX 3090可运行。 |
| 32B | ≥64GB(FP16) | 双A100 40GB(并行)、四RTX 3090 | ≥128GB | 四A100 80GB集群、多卡H100 | 需模型并行;4位量化后显存降至约32GB,单A100 40GB可推理。 |
| 70B | ≥140GB(FP16) | 四A100 40GB(并行) | ≥280GB | 专业集群(如8xA100 80GB) | 4位量化后显存约35GB,单A100 40GB可推理,但需优化库(如vLLM)。 |
| 671B | ≥1.3TB(FP16) | 大规模分布式系统(如TPU Pod) | ≥2.6TB | 超算集群(数百张A100/H100) | 仅限企业和研究机构;需分布式训练框架(如DeepSpeed、Megatron-LM)。 |
Ollama 命令
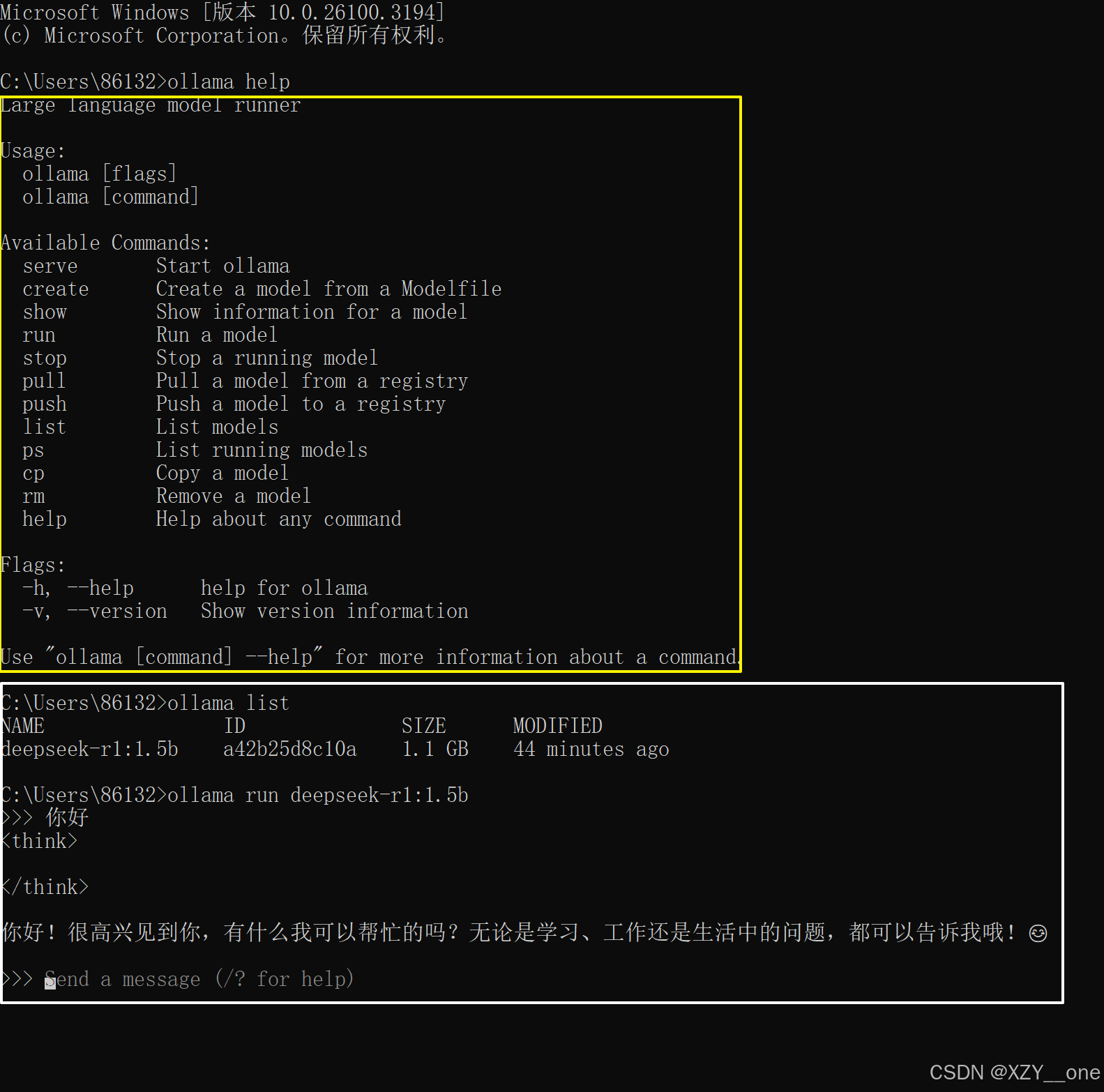
- 输入
ollama help,即可看到命令帮助,这里最常用的命令就是:ollama list和ollama run ollama list:查看下载的所有模型ollama run:运行你下再的模型,命令后面跟模型的名称,如:ollama run deepseek-r1:1.5b,即可重新开始对话。ollama rm:删除模型,命令后面跟模型的名称,如:ollama rm deepseek-r1:1.5b。