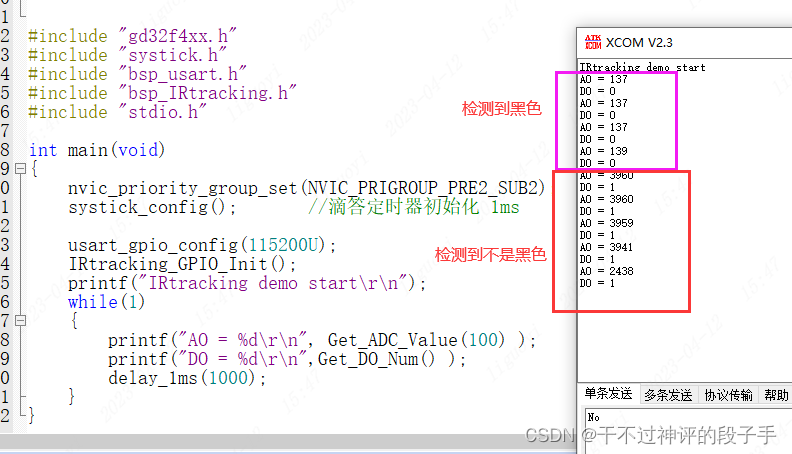
硬件准备
实验环境
pip config set global.extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple
# Writing to /opt/conda/pip.conf
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# Writing to /opt/conda/pip.conf
pip config set global.trusted-host https://pypi.tuna.tsinghua.edu.cn/simple
# Writing to /opt/conda/pip.confgit clone git@github.com:chenyifanthu/THU-Cloud-Downloader.gitcd THU-Cloud-Downloaderpip install argparse requests tqdmpython main.py --link https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/ --save ../chatglm-6b/git clone git@github.com:THUDM/ChatGLM-6B.gitchange model path
run cli_demo.py
python cli_demo.py
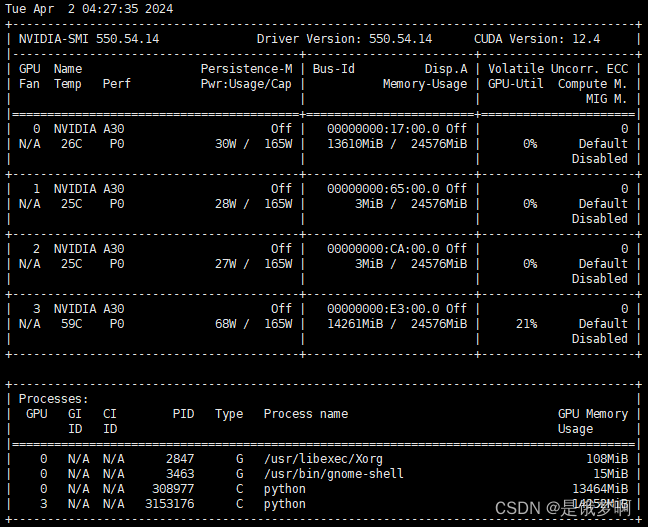
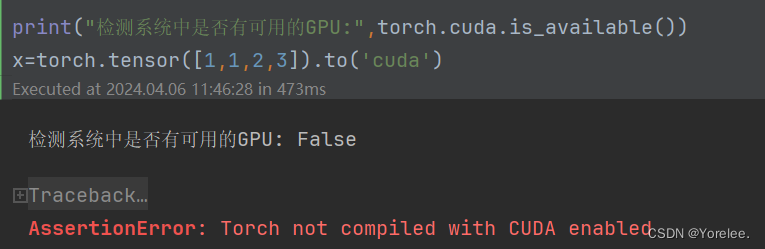
查看显存占用情况:nvidia-smi
高效微调:P-tuning v2
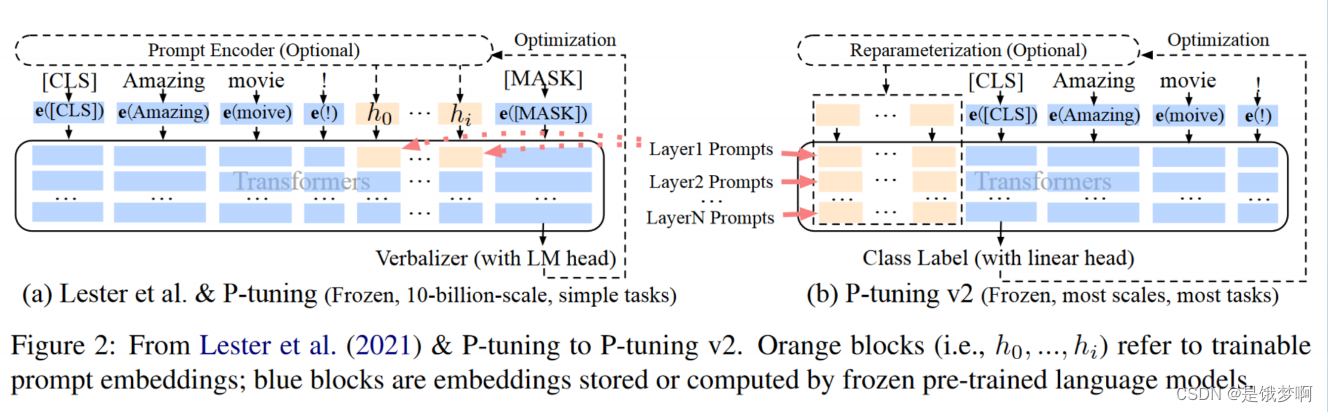
该方法在每一层都加入了Prompts tokens作为输入,不只是在输入层,因此有两点好处:
更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%);
加入到更深层结构中的Prompt能给模型预测带来更直接的影响;
#安装依赖
pip install rouge_chinese nltk jieba datasets#下载数据集
https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1修改/THU-Cloud-Downloader/ChatGLM-6B/ptuning/train.sh文件中train_file、validation_file、model_name_or_path、CUDA_VISIBLE_DEVICES
解释一下参数含义:
PRE_SEQ_LEN=128
LR=2e-2CUDA_VISIBLE_DEVICES=0 python3 main.py \--do_train \ # 进行训练--train_file /home/shishuhan/ChatGLM/AdvertiseGen/train.json \ # 训练数据--validation_file /home/shishuhan/ChatGLM/AdvertiseGen/dev.json \ #验证数据--prompt_column content \ # prompt--response_column summary \ # respose--overwrite_cache \ # 将数据集的预处理部分保存至cache,这个参数会每次覆盖cache,如果你的数据集没有改变,可用去掉这个参数--model_name_or_path /home/shishuhan/ChatGLM/chatglm-6b \ # 模型位置--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \ # 输出位置--overwrite_output_dir \ # 覆盖输出路径--max_source_length 64 \ # 最大的prompt的token长度--max_target_length 64 \ # 最大的respose的token长度--per_device_train_batch_size 1 \ # 每个设备上面放几个batch_size--per_device_eval_batch_size 1 \ # 每个设备上面平均的batch_size--gradient_accumulation_steps 16 \ #多少步累加一次梯度,模仿大的一个batch_size--predict_with_generate \ #--max_steps 3000 \ #训练多少步--logging_steps 10 \ #打印log的步数--save_steps 1000 \ #保存模型的步数--learning_rate $LR \ #学习率--pre_seq_len $PRE_SEQ_LEN \ #P-tuning中添加的token长度--quantization_bit 4 #量化参数开始训练:
bash train.sh大概需要三个多小时

跑完了用了6个小时(用了4bit量化,一张A30显卡)
测试一下(修改路径!!!):
bash evaluate.sh跑起来大概是这个样子,不知道要跑多久,先不管了
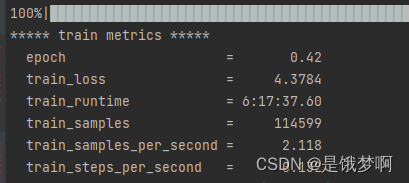
 跑完了就是这样样子(关于评估指标的一些数据):
跑完了就是这样样子(关于评估指标的一些数据):
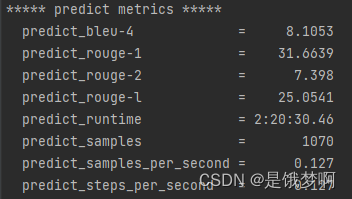
我根据源代码,修改了一份窗口版,然后让chatgpt生成了一些数据,有兴趣的可用拿来玩玩
import os
import platform
import signal
from transformers import AutoTokenizer, AutoModel,AutoConfig
import readline
import torchmodel_name_or_path = "../../../ChatGLM/chatglm-6b"
ptuning_checkpoint = "./output/adgen-chatglm-6b-pt-128-2e-2/checkpoint-3000"pre_seq_len = 128
prefix_projection = False #是否投影前缀嵌入(token),默认值为false,表示使用P-Tuning v2, 如果为true,则表示使用 Prefix Tuningconfig = AutoConfig.from_pretrained(model_name_or_path, trust_remote_code=True)
config.pre_seq_len = pre_seq_len
config.prefix_projection = prefix_projectiontokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)model = AutoModel.from_pretrained(model_name_or_path, config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join(ptuning_checkpoint, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():if k.startswith("transformer.prefix_encoder."):new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)model = model.quantize(quantization_bit)
model = model.half().cuda()
model.transformer.prefix_encoder.float()model = model.eval()os_name = platform.system()
clear_command = 'cls' if os_name == 'Windows' else 'clear'
stop_stream = Falsedef build_prompt(history):prompt = "欢迎使用 ChatGLM-6B-广告语生产模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"for query, response in history:prompt += f"\n\n用户:{query}"prompt += f"\n\nChatGLM-6B:{response}"return promptdef signal_handler(signal, frame):global stop_streamstop_stream = Truedef main():history = []global stop_streamprint("欢迎使用 ChatGLM-6B 广告语生产模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")while True:query = input("\n用户:")if query.strip() == "stop":breakif query.strip() == "clear":history = []os.system(clear_command)print("欢迎使用 ChatGLM-6B 广告语生产模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")continuecount = 0for response, history in model.stream_chat(tokenizer, query, history=history):if stop_stream:stop_stream = Falsebreakelse:count += 1if count % 8 == 0:os.system(clear_command)print(build_prompt(history), flush=True)signal.signal(signal.SIGINT, signal_handler)os.system(clear_command)print(build_prompt(history), flush=True)if __name__ == "__main__":main()
类型#裙子版型#修身颜色#红色风格#优雅图案#花朵裙款式#连衣裙裙长#及膝*裙腰型#高腰
类型#家具材质#实木颜色#原木色风格#简约图案#无家具类型#沙发家具风格#现代
类型#手机型号#智能手机颜色#银色风格#时尚图案#无手机品牌#苹果手机功能#拍照
类型#手表材质#不锈钢颜色#金色风格#豪华图案#无表款式#石英表盘形状#圆形
类型#包包材质#皮革颜色#棕色风格#复古图案#纹路包款式#手提包包型#方形
类型#运动鞋材质#网布颜色#白色风格#休闲图案#字母鞋款式#运动鞋鞋底材质#橡胶
类型#耳机连接方式#无线颜色#黑色风格#时尚图案#无耳机类型#耳塞音质#高清
类型#眼镜镜框材质#金属颜色#银灰色风格#经典图案#无镜框形状#方形镜片材质#树脂
类型#书包材质#尼龙颜色#深蓝色风格#休闲图案#印花包款式#双肩包包型#圆筒形
类型#床上用品材质#棉颜色#浅粉色风格#甜美图案#小星星用品类型#床单适用床型#双人床
类型#烘焙工具材质#硅胶颜色#彩色风格#可爱图案#卡通工具类型#搅拌器适用场景#厨房
类型#墙纸材质#纸质颜色#灰色风格#现代图案#几何图形纸张尺寸#大块装饰场所#客厅
类型#餐具材质#陶瓷颜色#白色风格#简约图案#素色用具类型#碗碟适用场景#餐厅
类型#雨伞材质#尼龙颜色#透明风格#清新图案#水滴伞型#折叠伞伞骨材质#铝合金
类型#笔记本封面材质#PU皮颜色#粉色风格#可爱图案#动物内页类型#格子适用场景#学习
类型#拼图材质#木质颜色#彩色风格#童趣图案#动物拼图形状#方形难度级别#简单
类型#香水容量#50ml香调#清新颜色#透明风格#优雅适用性别#女性香味类型#花香
类型#餐椅材质#塑料颜色#蓝色风格#现代图案#无椅子类型#餐椅适用场所#餐厅
类型#汽车品牌#奔驰颜色#银灰色风格#豪华图案#无车型#轿车车辆类型#豪华轿车
类型#围巾材质#羊毛颜色#灰色风格#经典图案#格子围巾类型#披肩适用季节#秋冬
类型#水杯材质#不锈钢颜色#粉红色风格#简约图案#纯色容量#500ml适用场景#户外活动
类型#手套材质#羊皮颜色#棕色风格#复古图案#无手套类型#保暖手套适用季节#冬季
类型#行李箱材质#PC+ABS颜色#黑色风格#时尚图案#纯色箱型#拉杆箱适用场景#旅行
类型#项链材质#银饰颜色#紫色风格#优雅图案#水滴项链类型#吊坠项链适用场合#晚宴
类型#雨靴材质#橡胶颜色#黄色风格#可爱图案#小鸭子鞋款式#中筒适用场合#雨天
类型#手链材质#玛瑙颜色#黑色风格#复古图案#龙纹手链类型#手镯适用性别#男女皆宜
类型#床垫材质#乳胶颜色#米白色风格#舒适图案#无尺寸#双人床适用场所#卧室
类型#沙滩巾材质#棉麻颜色#彩色风格#清爽图案#植物巾类类型#浴巾适用场合#沙滩度假
类型#键盘连接方式#蓝牙颜色#黑色风格#时尚图案#无键盘类型#机械键盘适用场景#办公
类型#墙钟材质#塑料颜色#白色风格#简约图案#数字钟表类型#挂钟适用场所#客厅
类型#园艺工具材质#不锈钢颜色#绿色风格#实用图案#无工具类型#铲子适用场景#花园
类型#香水瓶材质#玻璃颜色#粉色风格#浪漫图案#花朵容量#100ml适用场合#晚宴
类型#咖啡杯材质#陶瓷颜色#白色风格#复古图案#植物容量#200ml适用场景#咖啡厅
类型#手表盒材质#皮革颜色#棕色风格#古典图案#花纹适用表款#单表适用场合#收藏
类型#椅垫材质#羊毛颜色#米黄色风格#温馨图案#无适用椅型#餐椅适用场所#家庭餐厅
类型#口红材质#液态颜色#珊瑚橙风格#时尚图案#无适用妆容#日常妆适用场合#约会
类型#毛巾材质#纯棉颜色#浅蓝色风格#清爽图案#波浪用途#擦手巾适用场景#浴室
类型#耳环材质#黄金颜色#金色风格#典雅图案#花朵耳环类型#耳钉适用场合#晚宴
类型#雨衣材质#PVC颜色#透明风格#简约图案#无衣款式#连帽雨衣适用场合#下雨天
类型#座椅材质#皮革颜色#深棕色风格#经典图案#纹理适用场所#办公室椅子类型#办公椅
类型#项链材质#黄金颜色#金色风格#豪华图案#十字架项链类型#吊坠项链适用场合#晚宴
类型#手机壳材质#硅胶颜色#透明风格#简约图案#无适用手机型号#iPhone 12适用场合#日常
类型#扇子材质#竹子颜色#米白色风格#传统图案#梅花扇骨材质#鹅毛适用场合#夏日
类型#手提包材质#帆布颜色#卡其色风格#休闲图案#无包款式#单肩包适用季节#春季
类型#打火机材质#金属颜色#银色风格#经典图案#无适用燃料#但充电适用场合#户外活动
类型#墙壁装饰材质#树脂颜色#金色风格#欧式图案#花朵装饰类型#壁挂适用场所#客厅

高效微调:LORA
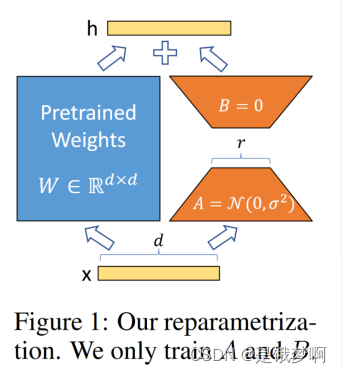
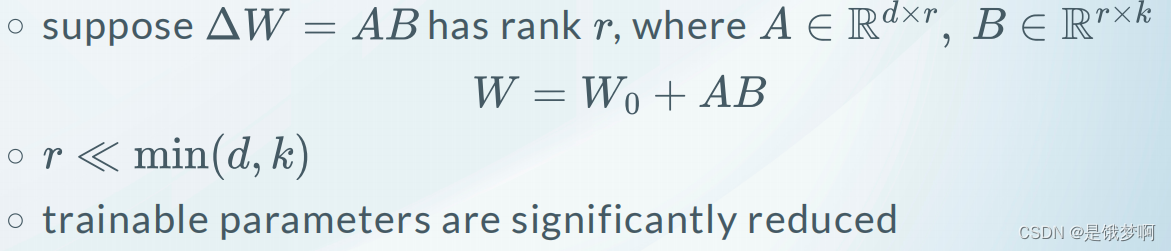
LoRA核心思想是在原始预训练语言模型旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank(预训练模型在各类下游任务上泛化的过程其实就是在优化各类任务的公共低维本征(low-dimensional intrinsic)子空间中非常少量的几个自由参数)。
训练的时候固定预训练语言模型的参数,只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变,输出时将 AB 与预训练语言模型的参数叠加。用随机高斯分布初始化 A,用 0 矩阵初始化 B。这样能保证训练开始时,新增的通路AB=0,从而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可,h=Wx+ABx=(W+AB)x,所以,只要将训练完成的矩阵乘积AB跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。
LoRA 的最大优势是速度更快,使用的内存更少;因此,可以在消费级硬件上运行。
官方给的东西要下载一个新的模型参数dddd什么的,我偏不下,我就要用这个搞;
经过了一大堆bug都修改,还真被我搞出来; peft == 0.3.0 这个很重要,要考!!!
from glob import glob
import os
import pandas as pd
import shutil
from itertools import chain
from tqdm import tqdm
from pathlib import Path
from transformers.trainer_callback import TrainerCallback, TrainerState, TrainerControlfrom transformers import Trainer, TrainingArguments
import random
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModel
from peft import get_peft_model, LoraConfig, TaskType
from typing import Optional
import torchos.environ["CUDA_VISIBLE_DEVICES"] = "0"tokenizer = AutoTokenizer.from_pretrained("../../../ChatGLM/chatglm-6b", trust_remote_code=True)model = AutoModel.from_pretrained("../../../ChatGLM/chatglm-6b", trust_remote_code=True).half().cuda()peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1,target_modules=['query_key_value', ],
)
model = get_peft_model(model, peft_config)class MyTrainer(Trainer):def _save(self, output_dir: Optional[str] = None, state_dict=None):# If we are executing this function, we are the process zero, so we don't check for that.output_dir = output_dir if output_dir is not None else self.args.output_diros.makedirs(output_dir, exist_ok=True)def save_tunable_parameters(model, path):saved_params = {k: v.to("cpu") for k, v in model.named_parameters() if v.requires_grad}# saved_params = model.state_dict()torch.save(saved_params, path)save_tunable_parameters(self.model, os.path.join(output_dir, "chatglm-lora.pt"))random.seed(42)dataset = load_dataset("json",data_files={'train': ["../../../ChatGLM/AdvertiseGen/train.json"],'valid': ["../../../ChatGLM/AdvertiseGen/dev.json"]},cache_dir="cache_data"
)def get_masks_and_position_ids(seq, seq_len, context_length, device, gmask=False, position_encoding_2d=True
):mask_position = (seq_len - 2) # is equal to `seq.index(mask_token)` or `seq.index(150001)`attention_mask = torch.ones((1, context_length, context_length), device=device)attention_mask.tril_()attention_mask[..., : mask_position - 1] = 1attention_mask = (attention_mask < 0.5).bool()if position_encoding_2d:seq_length = seq_len - 1 # is equal to `seq_length = seq.index(150004)`position_ids = torch.arange(context_length, dtype=torch.long, device=device)if not gmask:position_ids[seq_length:] = mask_positionblock_position_ids = torch.cat((torch.zeros(seq_length, dtype=torch.long, device=device),torch.arange(context_length - seq_length, dtype=torch.long, device=device)+ 1,))position_ids = torch.stack((position_ids, block_position_ids), dim=0)else:position_ids = torch.arange(context_length, dtype=torch.long, device=device)if not gmask:position_ids[context_length - 1 :] = mask_positionreturn attention_mask, position_idsdef data_collator(features: list) -> dict:len_ids = [len(feature["input_ids"]) for feature in features]longest = max(len_ids) + 1input_ids = []attention_mask_list = []position_ids_list = []labels_list = []for ids_l, feature in sorted(zip(len_ids, features), key=lambda x: -x[0]):ids = feature["input_ids"]seq_len = feature["seq_len"]labels = ([-100] * (seq_len - 1)+ ids[(seq_len - 1) :]+ [tokenizer.pad_token_id]+ [-100] * (longest - ids_l - 1))ids = ids + [tokenizer.pad_token_id] * (longest - ids_l)_ids = torch.LongTensor(ids)attention_mask, position_ids = get_masks_and_position_ids(ids, seq_len, longest, _ids.device, gmask=False)labels_list.append(torch.LongTensor(labels))input_ids.append(_ids)attention_mask_list.append(attention_mask)position_ids_list.append(position_ids)input_ids = torch.stack(input_ids)labels = torch.stack(labels_list)attention_mask = torch.stack(attention_mask_list)position_ids = torch.stack(position_ids_list)return {"input_ids": input_ids,"labels": labels,"attention_mask": attention_mask,"position_ids": position_ids,}def format_example(example: dict) -> dict:return examplemax_seq_length = 512def preprocess(example):prompt = example["content"]target = example["summary"]prompt_ids = tokenizer.encode(prompt, max_length=max_seq_length, truncation=True)target_ids = tokenizer.encode(target, max_length=max_seq_length, truncation=True, add_special_tokens=False)input_ids = prompt_ids + target_ids + [tokenizer.eos_token_id]return {"input_ids": input_ids, "seq_len": len(prompt_ids)}def filter_nan(example):return example['content'] is not None and example['summary'] is not Nonetokenized_datasets = dataset.map(function=format_example).filter(function=filter_nan)
tokenized_datasets = tokenized_datasets.map(function=preprocess)class EmptyCacheCallBack(TrainerCallback):"""通过callback的形式,解决显存不够的问题"""def __init__(self) -> None:super().__init__()def on_log(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, logs, **kwargs):"""Event called after logging the last logs."""torch.cuda.empty_cache()def on_epoch_begin(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):torch.cuda.empty_cache()def on_step_begin(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):torch.cuda.empty_cache()eccb = EmptyCacheCallBack()args = TrainingArguments(output_dir="output/adgen-chatglm-6b-lora-512-5e-4",per_device_train_batch_size=2,per_device_eval_batch_size=1,evaluation_strategy="steps",eval_steps=1000,logging_steps=100,gradient_accumulation_steps=8,num_train_epochs=4,weight_decay=0.1,warmup_steps=0,lr_scheduler_type="cosine",learning_rate=5e-4,save_steps=1000,fp16=True,push_to_hub=False,remove_unused_columns=False
)trainer = MyTrainer(model=model,tokenizer=tokenizer,args=args,data_collator=data_collator,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["valid"],# callbacks=[eccb]
)
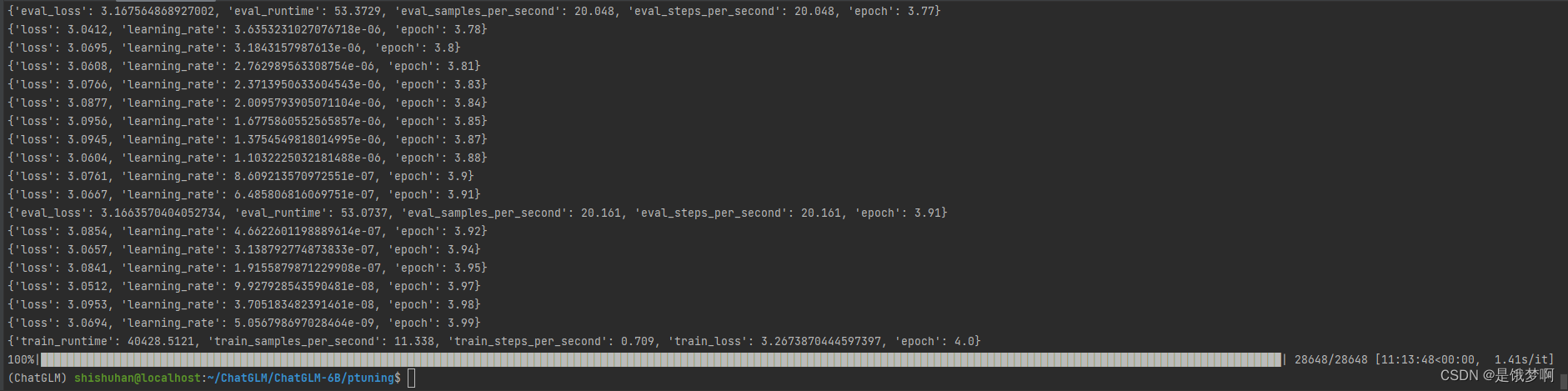
trainer.train()
一张A30卡上跑,大概要用10个小时左右吧 ;nvidia-smi
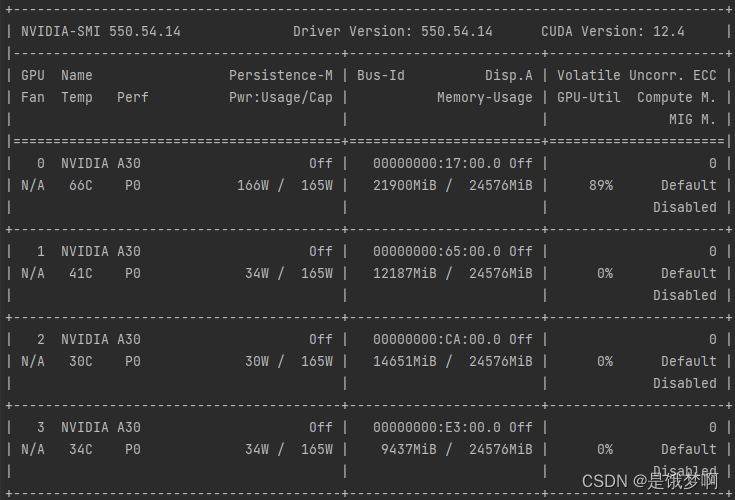
等了大半天,终于跑完了,这个loss一直都降不下来啊
lora模型进行推理
from transformers import AutoTokenizer,AutoModel
import torch
from peft import get_peft_model, LoraConfig, TaskType
import platform
import os
import signalmodel = AutoModel.from_pretrained("../../../ChatGLM/chatglm-6b", trust_remote_code=True).half().cuda()peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1,target_modules=['query_key_value',],
)
model = get_peft_model(model, peft_config)# 在这里加载lora模型,注意修改chekpoint
peft_path = "output/adgen-chatglm-6b-lora-512-5e-4/checkpoint-28000/chatglm-lora.pt"
model.load_state_dict(torch.load(peft_path), strict=False)
model.eval()tokenizer = AutoTokenizer.from_pretrained("../../../ChatGLM/chatglm-6b", trust_remote_code=True)# text ="为什么冰红茶和柠檬茶的味道一样?"
#
# with torch.autocast("cuda"):
# res, history = model.chat(tokenizer=tokenizer, query=text,max_length=300)
# print(res)os_name = platform.system()
clear_command = 'cls' if os_name == 'Windows' else 'clear'
stop_stream = Falsedef build_prompt(history):prompt = "欢迎使用 ChatGLM-6B-广告语生产模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"for query, response in history:prompt += f"\n\n用户:{query}"prompt += f"\n\nChatGLM-6B:{response}"return promptdef signal_handler(signal, frame):global stop_streamstop_stream = Truedef main():history = []global stop_streamprint("欢迎使用 ChatGLM-6B 广告语生产模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")while True:query = input("\n用户:")if query.strip() == "stop":breakif query.strip() == "clear":history = []os.system(clear_command)print("欢迎使用 ChatGLM-6B 广告语生产模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")continuecount = 0for response, history in model.stream_chat(tokenizer, query, history=history):if stop_stream:stop_stream = Falsebreakelse:count += 1if count % 8 == 0:os.system(clear_command)print(build_prompt(history), flush=True)signal.signal(signal.SIGINT, signal_handler)os.system(clear_command)print(build_prompt(history), flush=True)if __name__ == "__main__":main()
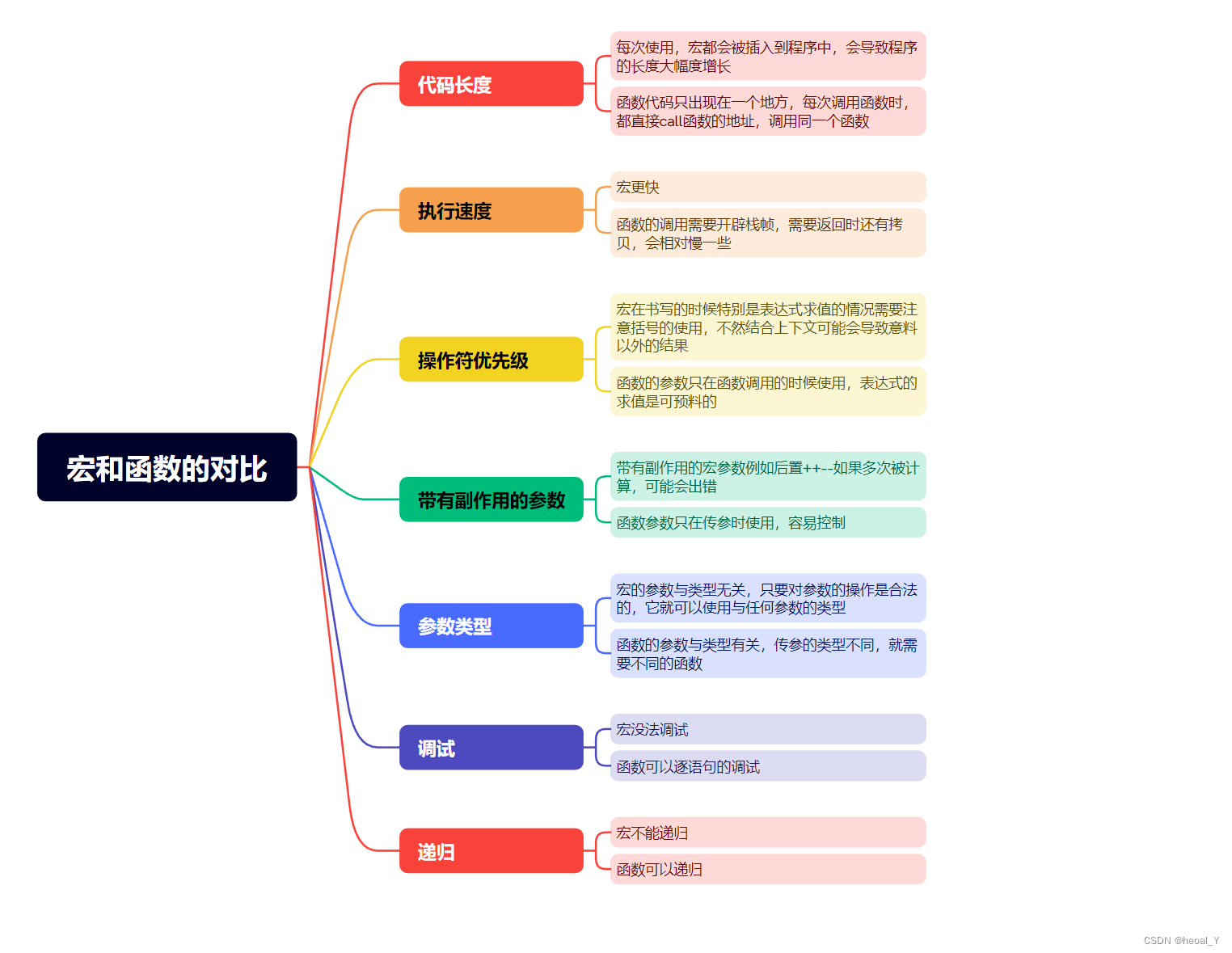
P-tuning v2 VS LORA
P-tuning v2

lora

我们对这两个进行测试,发现两个微调后的性能是半斤八两,一个是‘有着立体的立体感’,一个是‘无适用燃料但可充电’ 。
我也是初学这个微调技术,不太懂是什么地方出现了问题。有知道的大佬可以留言讨论一下








![15 个最佳 Word 文档恢复工具 [免费下载]](https://img-blog.csdnimg.cn/img_convert/0c275243404fcb2b59ebf556a224e84f.png)