文章目录
- DBUtils工具包
- 准备工作
- DBUtils的介绍
- QueryRunner
- 空参的QueryRunner的介绍以及使用
- 有参QueryRunner的介绍以及使用
- ResultSetHandler结果集
- BeanHandler<T>
- BeanListHandler<T>
- ScalarHander
- ColumnListHander
- 事务
- 事务
- 事务_转账分析图
- 实现转账(不加事务)
- 事务的介绍
- DButils实现转账(添加事务)
- mysql中操作事务
- 分层思想介绍以及框架搭建
- 转账_表现层实现
- 转账_服务层实现
- 转账_持久层实现
- ThreadLocal
- ThreadLocal基本使用和原理
- 连接池对象管理类(小秘书)
- 事务的特性以及隔离级别
- 事务特性ACID
- 并发访问问题
- 隔离级别:解决问题
- 演示
DBUtils工具包
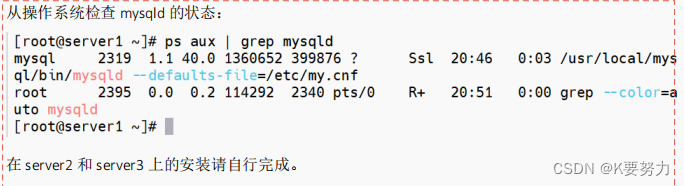
准备工作
DBUtils的介绍
1.概述:简化jdbc开发的工具
2.三大核心对象
QueryRunner 执行sql
ResultSetHandler:处理结果集
DBUtils类: 主要用于事务管理,关闭资源等
QueryRunner
空参的QueryRunner的介绍以及使用
1.构造:QuerryRunner()
2.特点:
连接对象需要我们自己维护,自己关闭
3.方法
int update(Connection conn, String sql, Object… params)-> 针对于增删改
conn:连接对象
sql:sql语句->支持?占位符
params:为?赋值->可变参数
第一个值自动匹配sql语句中的第一个?以此类推
query(Connection conn, String sql, ResultSetHandler rsh, Object… params)->针对查询
public class test04 {public static void main(String[] args) throws SQLException {QueryRunner queryRunner = new QueryRunner();Connection conn = DruidUtils.getConn();String sql = "insert into category(cname) values(?);";queryRunner.update(conn,sql,"服装");DruidUtils.close(conn,null,null);}
}
有参QueryRunner的介绍以及使用
1.构造:QueryRunner(DataSource ds)
2.特点:
Connection连接对象,不用我们自己管理,全部交由连接池管理
3.方法:
int update(String sql, Object… params)-> 针对于增删改
sql:sql语句->支持?占位符
params:为?赋值->可变参数
第一个值自动匹配sql语句中的第一个?以此类推
query(String sql, ResultSetHandler rsh, Object… params)->针对查询
代码示例
ResultSetHandler结果集
BeanHandler
1.作用:将查询出来的结果集中的第一行数据封装成javabean对象
2.方法
query(String sql, ResultSetHandler rsh, Object… params)>有参QueryRunner时使用
query(Connection conn, String sql, ResultSetHandler rsh, Object… params)->空参QueryRunner时使用
3.构造
BeanHandler(class type)
传递的是class对象其实就是我们想要封装的javabean类的class对象
将想查询出来的数据封装成哪个Javabean对象,就写哪个javabean的class对象
4.怎么理解
将查询出来的数据为javabean中的成员变量赋值
@Testpublic void beanHandler() throws SQLException {QueryRunner queryRunner = new QueryRunner(DruidUtils.getDataSource());Category category = queryRunner.query("select * from category",new BeanHandler<>(Category.class));System.out.println("category = " + category);}
注意在写之前需要创建一个javabean对象
public class Category {private int id;private String cname;public Category() {}public Category(int id, String cname) {this.id = id;this.cname = cname;}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getCname() {return cname;}public void setCname(String cname) {this.cname = cname;}
}
BeanListHandler
1.作用 将查询出来的结果每一条数据都封装成一个个的javabean对象,将这些javabean对象放到list集合中
2.构造
BeanListHandler(Class type)
传递的是class对象其实就是我们想要封装的javabean类的class对象
想将查询出来的数据封装成哪个javabean对象,就写哪个javabean的class对象
3.怎么理解“
将查询出来的多条数据封装成多个javabean对象,将多个javabean对象放到list集合中
public void beanListHandler() throws SQLException {QueryRunner queryRunner = new QueryRunner(DruidUtils.getDataSource());List<Category> list = queryRunner.query("select * from category",new BeanListHandler<>(Category.class));for (Category category : list) {System.out.println(category.getCid());}}
ScalarHander
1.作用:主要是用于处理单值的查询结果,执行的select语句,结果集只有一个
2.构造:
ScalarHandler(int columnIndex)->不常用->指定第几列
ScalarHandler(String columnName)->不常用->指定列名
ScalarHandler()->常用
3.注意:
ScalarHander和聚合函数使用更有意义
public void scalarhander() throws SQLException {QueryRunner queryRunner = new QueryRunner(DruidUtils.getDataSource());Object o1 = queryRunner.query("select * from category;", new ScalarHandler<>(2));Object o2 = queryRunner.query("select * from category;", new ScalarHandler<>("cname"));Object o3 = queryRunner.query("select * from category;", new ScalarHandler<>());System.out.println(o1);System.out.println(o2);System.out.println(o3);}
ColumnListHander
1.作用 将查询出来的结果中的某一列数据,存储到list集合中
2.构造:
ColumnListHandler(int columnIndex)->指定第几列
ColumnListHandler(String columnName)->指定列名
ColumnListHandler()-> 默认显示查询结果中的第一列数据
3.注意:
ColumnListHandler可以指定泛型类型,如果不指定,返回的list泛型就是object类型
public void columnListHandler() throws SQLException {QueryRunner queryRunner = new QueryRunner(DruidUtils.getDataSource());List<Object> query = queryRunner.query("select * from category;", new ColumnListHandler<>(2));List<Object> query_1 = queryRunner.query("select * from category;", new ColumnListHandler<>());for (Object o : query) {System.out.println(o);}}
事务
事务
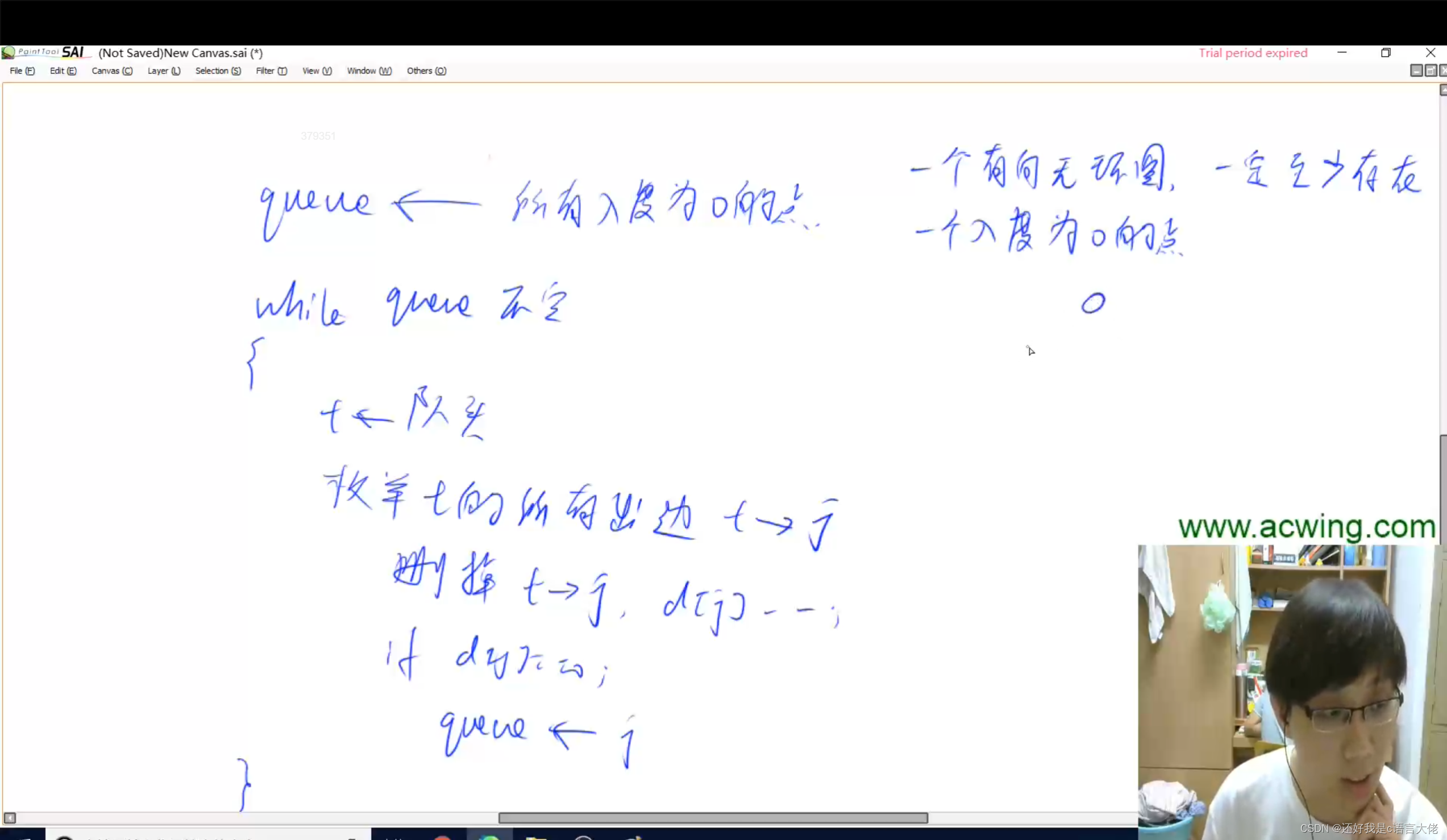
事务_转账分析图

建表
CREATE TABLE account(`name` VARCHAR(20),money INT
);
实现转账(不加事务)
public class test01 {public static void main(String[] args) {QueryRunner queryRunner = new QueryRunner();Connection conn = DruidUtils.getConn();String outMoney = "update account set money = money - 1000 where name = ?";String inputMoney = "update account set money = money + 1000 where name = ?";try {queryRunner.update(conn,outMoney,"王也");queryRunner.update(conn,inputMoney,"张楚岚");} catch (SQLException e) {e.printStackTrace();}finally {DruidUtils.close(conn,null,null);}}
}
事务的介绍
1.事务:是管理多条sql语句的一个形式,可以将多条sql看成是一组操作,是的这一组操作要么全成功,要么全失败,mysql自带事务,带式mysql的事务一次只能管理一条sql,我们需要关闭sql的自带事务,开启手动事务
2.事务操作:Connection中的方法
a.void setAutoCommit(boolean autoCommit) -> 开启手动事务
autoCommit:false -> 代表关闭mysql自带事务,开启手动事务
b.void commit()-> 提交事务 -> 如果事务一旦提交,数据将永久保存,不可逆
c.void rollback()->回滚事务-> 如果事务回滚,数据将还原到上一次改变前的数据
3.注意
如果想让事务管理多条sql语句,那么sql之间用的连接或者说事务操作作用的连接对象必须是同一条连接对象
DButils实现转账(添加事务)
相关代码块
public class test02 {public static void main(String[] args) throws SQLException {QueryRunner queryRunner = new QueryRunner();java.sql.Connection conn1 = null;try {conn1 = DruidUtils.getConn();System.out.println(conn1);//开启事务conn1.setAutoCommit(false);String outputmoney = "update account set money = money - 1000 where name = ?";String inputmoney = "update account set money = money + 1000 where name = ?";queryRunner.update(conn1, outputmoney, "王也");queryRunner.update(conn1, inputmoney, "张楚岚");//提交事务conn1.commit();System.out.println("转账成功");}catch (Exception e){//回滚事务try {conn1.rollback();System.out.println("转账失败");}catch (SQLException ex){ex.printStackTrace();}e.printStackTrace();}finally {//关闭资源DruidUtils.close(conn1,null,null);}}
}
mysql中操作事务
1.开启事务
begin
2.提交事务
commit
3.回滚事务
rollback
#开启事务
BEGIN;
update account set money = money - 1000 where name = "王也";
update account set money = money + 1000 where name = "张楚岚";
#提交事务
COMMIT;
#回滚事务
ROLLBACK;
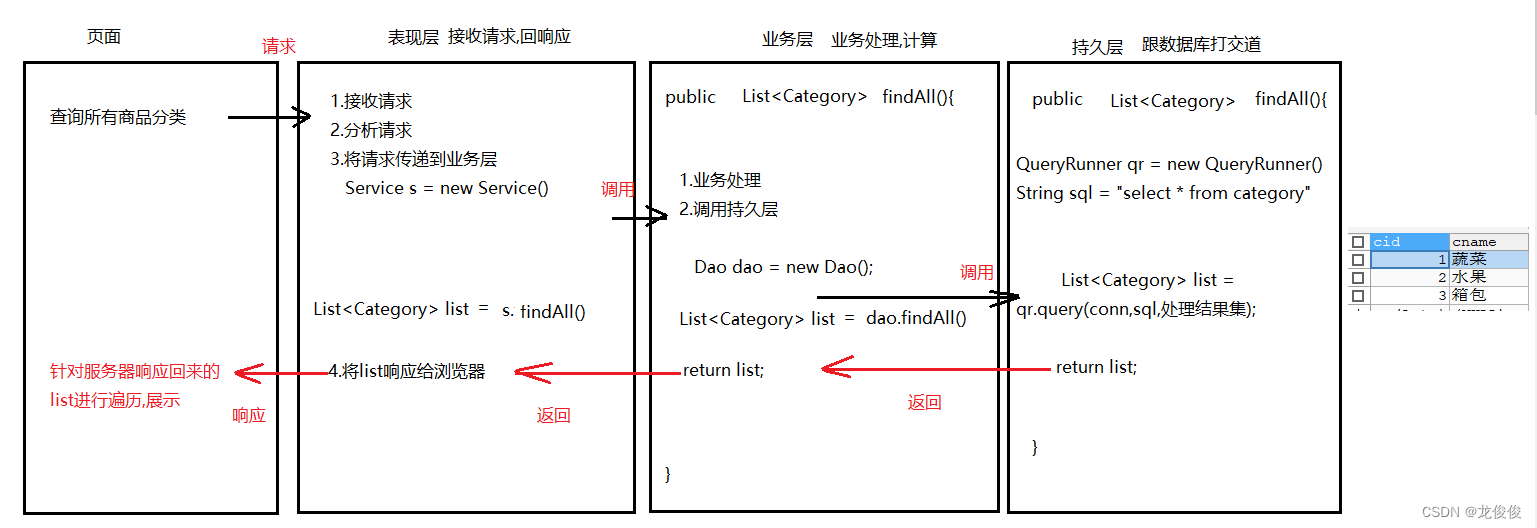
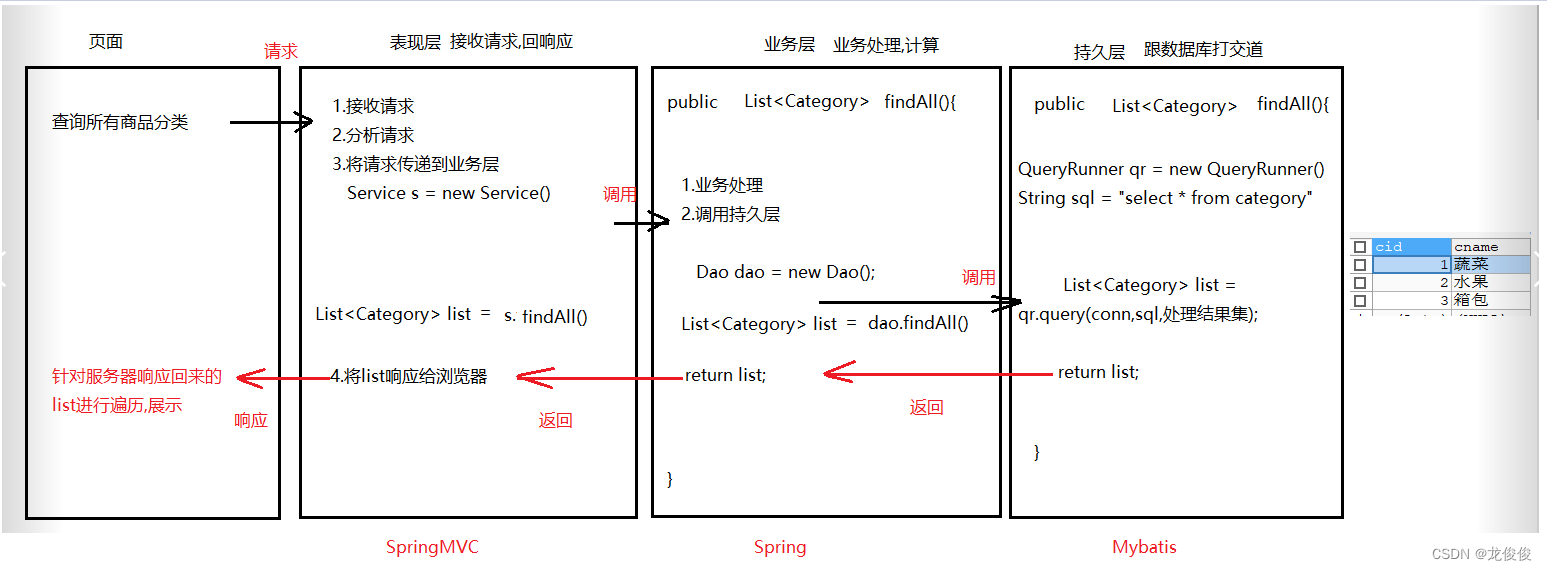
分层思想介绍以及框架搭建
1.表现层(web层) 和页面打交道 ---- 接收请求,回响应
2.业务层(service层) 写业务的,做计算
3.持久层(dao层) 和数据库打交道—对数据库的数据进行增删改查
创建package ---- 公司域名倒着写,都是小写
转账_表现层实现
public class AccountController {public static void main(String[] args) {//创建scannerScanner scanner = new Scanner(System.in);System.out.println("请你输入要出钱的人");String outname = scanner.next();System.out.println("请你输入要收钱的人");String inname = scanner.next();System.out.println("请输入转账金额");int money = scanner.nextInt();//将输入的三个数据传递到service层AccountService accountService = new AccountService();accountService.transfer(outname,inname,money);}
}
转账_服务层实现
public class AccountService {public void transfer(String outname,String inname,int money){AccountDao accountDao = new AccountDao();Connection conn = DruidUtils.getConn();//开启事务try {conn.setAutoCommit(false);accountDao.outmoney(conn,outname,money);accountDao.inmoney(conn,inname,money);//提交事务conn.commit();System.out.println("转账成功");} catch (Exception e) {try {conn.rollback();System.out.println("转账失败");} catch (SQLException ex) {ex.printStackTrace();}e.printStackTrace();}finally {DruidUtils.close(conn,null,null);}}
}
转账_持久层实现
public class AccountDao {public void outmoney(Connection conn,String outname,int money) throws SQLException {QueryRunner queryRunner = new QueryRunner();String sql = "update account set money = money - ? where name = ?";queryRunner.update(conn,sql,money,outname);}public void inmoney(Connection conn,String inname,int money) throws SQLException {QueryRunner queryRunner = new QueryRunner();String sql = "update account set money = money + ? where name = ?";queryRunner.update(conn,sql,money,inname);}
}1.为什么要分层写代码?
a.减低耦合度
b.每层只干自己的事儿,别的层的事儿我不干,好维护
2.考虑问题:
1.问题1:service层中干了从数据库连接池中获取连接对象,也干了事务操作;但是service不应该干这些事儿
service其实只干业务逻辑判断,业务处理
2.问题2:如果不在service层获取连接对象,那么怎么传递到dao层呢?又怎么保证service和dao层中的连接对象是同一个呢?如果不是同一个,事务管理也就废废了
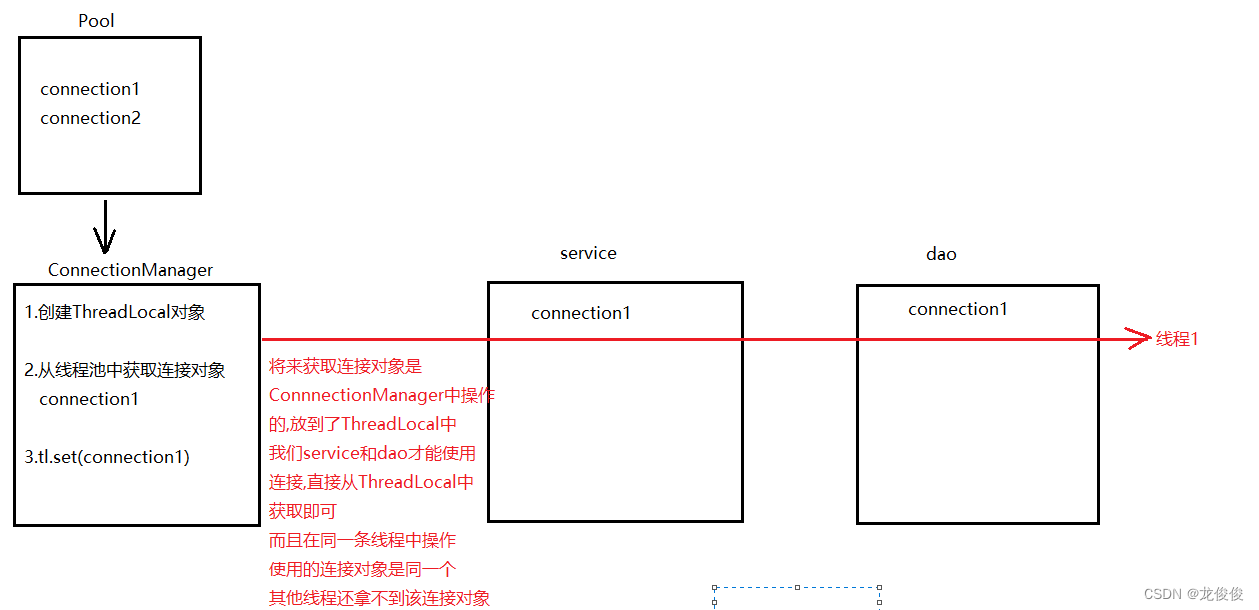
3.问题解决:给service和dao层面试一个"小秘书",获取连接,事务操作,都让"小秘书"干
同时还要保证service和dao使用的连接是同一条连接
ThreadLocal
ThreadLocal基本使用和原理
1.ThreadLocal:线程管理类
2.创建:
ThreadLocal 名字 = new ThreadLocal()
3.方法:
set(数据) – 往ThreadLocal中存储数据
get() — 获取数据
4.特点
a.ThreadLocal中一次只能存储一个数据,后米的数据会把前面的数据覆盖掉
b.一个线程往ThreadLocal中存储的数据,其他线程获取不到
c.ThreadLocal底层操作了Map,key为当前正在执行的线程对象,value为我们存储的数据
当我一存,值就会和当前前程绑死,也就是说值指数已当前线程对象,其他线程对象拿不到
public class Demo01ThreadLocal {public static void main(String[] args) {ThreadLocal<String> threadLocal = new ThreadLocal<>();threadLocal.set("王也");System.out.println(threadLocal.get());}
}
连接池对象管理类(小秘书)
代码实现
public class ConnectionManager {private static ThreadLocal<Connection> t1 = new ThreadLocal<Connection>();/** 从连接池中获取连接对象,放到ThreadLocal中* 然后从ThreadLocal中再拿出要使用的连接对象* */public static Connection getconn(){//先从ThreadLocal中获取连接对象Connection conn = t1.get();if (conn == null){//从连接池中获取连接对象conn = DruidUtils.getConn();t1.set(conn);}return conn;}//开启事务public static void begin(){try {getconn().setAutoCommit(false);} catch (SQLException e) {e.printStackTrace();}}//提交事务public static void commit(){try {getconn().commit();} catch (SQLException e) {e.printStackTrace();}}//回滚事务public static void back(){try {getconn().rollback();} catch (SQLException e) {e.printStackTrace();}}//关闭连接public static void close(){try {getconn().close();} catch (SQLException e) {e.printStackTrace();}}
}事务的特性以及隔离级别
事务特性ACID
1.原子性(atomicity)原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
2.一致性(Consistency)事务前后数据的完整性必须保持一致。
3.隔离性(Isolation)事务的隔离性是指多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离,正常情况下数据库是做不到这一点的,可以设置隔离级别,但是效率会非常低。
4.持久性(Durability)持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
并发访问问题
如果不考虑隔离性,事务存在3中并发访问问题
- 脏读:一个事务读到了另一个事务未提交的数据.
- 不可重复读:一个事务读到了另一个事务已经提交(update)的数据。引发另一个事务,在事务中的多次查询结果不一致。
- 虚读 /幻读:一个事务读到了另一个事务已经提交(insert)的数据。导致另一个事务,在事务中多次查询的结果不一致。
隔离级别:解决问题
数据库规定了四种隔离级别,分别用于描述两个事务并发的所用情况
- read uncommitted 读未提交,一个事务读到另一个事务没有提交的数据。
a)存在:3个问题(脏读、不可重复读、虚读)。
b)解决:0个问题 - read committed 读已提交,一个事务读到另一个事务已经提交的数据。
a)存在:2个问题(不可重复读、虚读)。
b)解决:1个问题(脏读) - repeatable read:可重复读,在一个事务中读到的数据始终保持一致,无论另一个事务是否提交。
a)存在:1个问题(虚读)。
b)解决:2个问题(脏读、不可重复读)
4.serializable 串行化,同时只能执行一个事务,相当于事务中的单线程。
a)存在:0个问题。
b)解决:3个问题(脏读、不可重复读、虚读)
安全和性能对比
安全性:serializable > repeatable read > read committed > read uncommitted
性能 :serializable < repeatable read < read committed < read uncommitted
常见数据库的默认隔离级别:
- MySql:
repeatable read - Oracle:
read committed
演示
查询数据库的隔离级别
show variables like '%isolation%';
select @@tx_isolation;
设置数据库的隔离级别
-
set session transactionisolation level级别字符串 -
级别字符串:
readuncommitted、read committed、repeatable read、serializable -
例如:
set session transaction isolation level read uncommitted;
读未提交:readuncommitted -
A窗口设置隔离级别
- AB同时开始事务
- A 查询
- B 更新,但不提交
- A 再查询?-- 查询到了未提交的数据
- B 回滚
- A 再查询?-- 查询到事务开始前数据
-
读已提交:read committed
- A窗口设置隔离级别
- AB同时开启事务
- A查询
- B更新、但不提交
- A再查询?–数据不变,解决问题【脏读】
- B提交
- A再查询?–数据改变,存在问题【不可重复读】
- A窗口设置隔离级别
-
可重复读:repeatable read
- A窗口设置隔离级别
- AB 同时开启事务
- A查询
- B更新, 但不提交
- A再查询?–数据不变,解决问题【脏读】
- B提交
- A再查询?–数据不变,解决问题【不可重复读】
- A提交或回滚
- A再查询?–数据改变,另一个事务
- A窗口设置隔离级别
-
串行化:serializable
- A窗口设置隔离级别
- AB同时开启事务
- A查询
- B更新?–等待(如果A没有进一步操作,B将等待超时)
- A回滚
- B 窗口?–等待结束,可以进行操作
总结:
我们最理想的状态是:一个事务和其他事务互不影响
但是如果不考虑隔离级别的话,就会出现多个事务之间互相影响
而事务互相影响的表现方式为:
脏读
不可重复读
虚读/幻读