注意:由于该文章由jupyter nbconvert导出,若单独执行代码可能出现变量找不到或者没有导入库的情况,正确的做法是将所有的代码片段按顺序放到一个.py文件里面或者按顺序放入一个.ipynb文件的多个代码块中。
SVM(Support Vector Machine)
Vapnik发明用于解决二分类问题的机器学习算法。
线性可分与非线性可分
在二维平面中,线性可分指的是可以通过一条直线对平面上的点进行划分使得标签相同的点在直线的同一侧,标签不同的点在直线的不同侧。
在二维平面中,非线性可分则是指除去线性可分的情况。
下面是一个线性可分的例子:
import matplotlib.pyplot as plot
from random import random
x1 = []
x2 = []
y1 = []
y2 = []
figSize = (6, 6)
dotNum = 20
for i in range(dotNum):x1.append(random() * 1 + 4.5 - 0.5)x2.append(random() * 1 + 4.5 + 0.5)y1.append(x1[-1] + random() * 1 + 0.5)y2.append(x2[-1] - random() * 1 - 0.5)fig, ax = plot.subplots(figsize = figSize)
ax.axis([3.5, 6.5, 2, 8])
ax.plot(x1, y1, "x")
ax.plot(x2, y2, "o")
ax.plot([3, 7], [3, 7], linewidth = 1)
ax.plot([3, 7], [2, 8], linewidth = 1)
ax.plot([3, 7], [1, 9], linewidth = 1)
下面是一个非线性可分的例子:
import numpy as np
plot.close()
dotNum = 50
x1 = np.random.rand(dotNum) * 2 - np.ones(dotNum)
x2 = np.random.rand(dotNum) - 0.5 * np.ones(dotNum)
y1 = np.append(np.sqrt(1 - x1 ** 2), -1 * np.sqrt(1 - x1 ** 2))
x1 = np.append(x1, x1)
y2 = np.append(np.sqrt(0.25 - x2 ** 2), -1 * np.sqrt(0.25 - x2 ** 2))
x2 = np.append(x2, x2)
fig, ax = plot.subplots(figsize=figSize)
ax.axis([-1.5, 1.5, -1.5, 1.5])
ax.plot(x1, y1, "x")
ax.plot(x2, y2, "o")
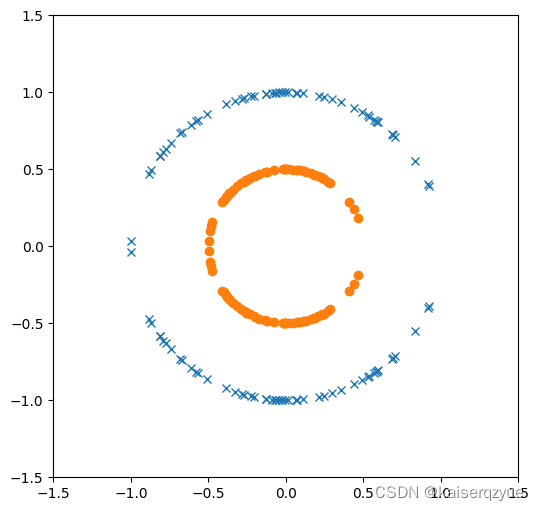
问题引入
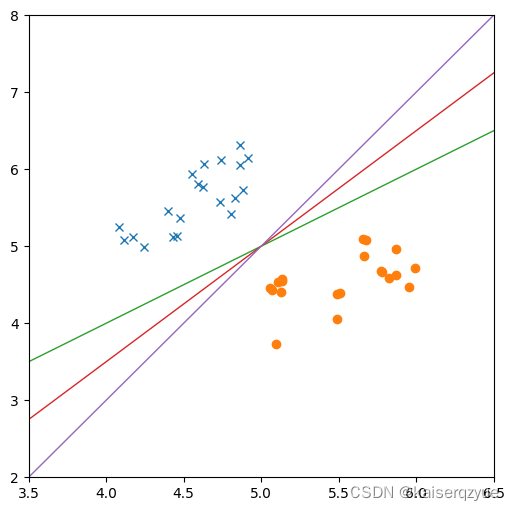
对于一个线性可分的数据集,存在着多条线段均可以达到划分数据集的目的,哪条直线的分类效果最好?
要找到最好,我们首先要知道什么叫做好。
Vapnik定义了性能指标:间隔。
一些定义
- 数据集:输入 X = [ x 1 , x 2 , . . . , x n ] X=[x_1, x_2, ..., x_n] X=[x1,x2,...,xn],输出 Y = [ y 1 , y 2 , . . . , y n ] , y i ∈ { − 1 , 1 } Y=[y_1, y_2, ..., y_n], y_i\in\{-1, 1\} Y=[y1,y2,...,yn],yi∈{−1,1}。
- 支持向量:将划分线分别向两侧平移后首次经过的数据向量集合。
- 间隔:将划分线分别向两侧移动至首次经过数据时,移动后形成的两条线之间的距离。
- 线性模型: W T x + b = 0 W^Tx+b=0 WTx+b=0
- 线性可分: ∃ W , b \exists W, b ∃W,b使得 y i ( W T x i + b ) ≥ 0 , 1 ≤ i ≤ n , i ∈ Z y_i(W^Tx_i+b)\ge0,\quad 1\le i \le n, i \in Z yi(WTxi+b)≥0,1≤i≤n,i∈Z
在下图中,上下两侧经过的点是支持向量,而上下两条直线之间的距离即间隔。
Vapnik认为间隔越大的直线越能够抵抗噪声的影响,因此Vapnik希望在能够划分数据集的直线中找到使间隔最大的那一条。
从下图中我们不难发现间隔最大的直线有无数条,而这无数条直线中我们只需要找到支持向量到直线距离相同的那一条(即中间那条直线)即可,这样能够尽可能的区分两类样本。
plot.close()
x1 = []
x2 = []
y1 = []
y2 = []
dotNum = 20
for i in range(dotNum):x1.append(random() * 1 + 4.5 - 0.5)x2.append(random() * 1 + 4.5 + 0.5)y1.append(x1[-1] + random() * 1 + 0.5)y2.append(x2[-1] - random() * 1 - 0.5)
line1X = [3, 7]
line1Y = [2, 8]
def dotDis2Line(dot, line):a = (line[1][1] - line[1][0]) / (line[0][1] - line[0][0])b = -1c = a * (-line[0][0]) + line[1][0]return np.abs(a * dot[0] + b * dot[1] + c) / np.sqrt(a ** 2 + b ** 2)
def moveDis2Dot(x, y, line): d = -1for i in range(len(x)):if d == -1 or d > dotDis2Line([x[i], y[i]], line):d = dotDis2Line([x[i], y[i]], line)return d
d1 = moveDis2Dot(x1, y1, [line1X, line1Y])
d2 = moveDis2Dot(x2, y2, [line1X, line1Y])
print(d1, d2)
line2X = line1X
line2Y = line1Y + d1 / ((line1X[1] - line1X[0]) / (np.sqrt((line1X[1] - line1X[0]) ** 2 + (line1Y[1] - line1Y[0]) ** 2)))
line3X = line1X
line3Y = line1Y - d2 / ((line1X[1] - line1X[0]) / (np.sqrt((line1X[1] - line1X[0]) ** 2 + (line1Y[1] - line1Y[0]) ** 2)))
fig, ax = plot.subplots(figsize=figSize)
ax.axis([3.5, 6.5, 2, 8])
ax.plot(x1, y1, "x")
ax.plot(x2, y2, "o")
ax.plot(line1X, line1Y, linewidth = 1)
ax.plot(line2X, line2Y, linewidth = 1)
ax.plot(line3X, line3Y, linewidth = 1)
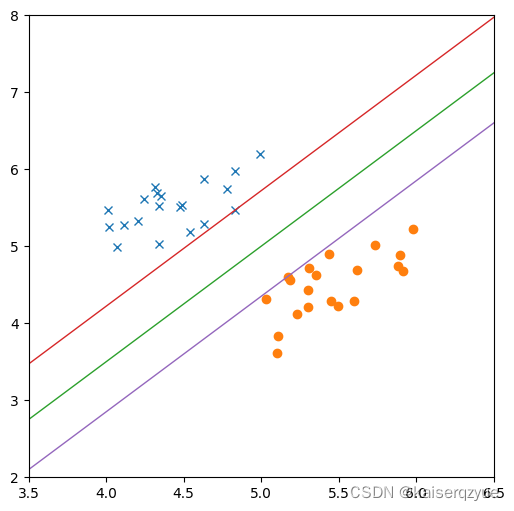
SVM的数学推导
复习两条知识:
- W T x + b = 0 W^Tx+b=0 WTx+b=0与 a W T x + a b = 0 , ∀ a ≠ 0 aW^Tx+ab=0, \forall a\ne0 aWTx+ab=0,∀a=0为同一个(超)平面
- 欧式空间中点到(超)平面(直线)的距离: d = ∣ W T x + b ∣ ∥ W ∥ d = \frac{\vert W^Tx+b\vert}{\parallel W\parallel} d=∥W∥∣WTx+b∣
有了上面的知识我们便可以写出SVM的数学模型:
m a x d = ∣ W T x i + b ∣ ∥ W ∥ , x i i s S V s . t . y i ( W T x i + b ) ≥ 0 , 1 ≤ i ≤ n , i ∈ Z W T x i = W T x j , x i a n d x j a r e a n y S V max\quad d = \frac{\vert W^Tx_i+b\vert}{\parallel W\parallel},\quad x_i\ is\ SV\quad s.t.\\ y_i(W^Tx_i+b)\ge0,\quad 1\le i \le n, i \in Z\\ W^Tx_i = W^Tx_j,\quad x_i\ and\ x_j\ are\ any\ SV maxd=∥W∥∣WTxi+b∣,xi is SVs.t.yi(WTxi+b)≥0,1≤i≤n,i∈ZWTxi=WTxj,xi and xj are any SV
上面的式子并不简单,因为我们不能很好的确定那些向量是支持向量。
不过,对于任何一个线性模型,我们总可以用 a a a去放缩支持向量到线性模型的距离,也就是: ∃ a , a ∣ W T x i + b ∣ = 1 , x i i s S V \exists a, a\vert W^Tx_i+b\vert=1,\quad x_i\ is\ SV ∃a,a∣WTxi+b∣=1,xi is SV。
而 W T x + b = 0 W^Tx+b=0 WTx+b=0与 a W T x + a b = 0 , ∀ a ≠ 0 aW^Tx+ab=0, \forall a\ne0 aWTx+ab=0,∀a=0为同一个(超)平面(直线),我们只需要求出 a W T x + a b = 0 , ∀ a ≠ 0 aW^Tx+ab=0, \forall a\ne0 aWTx+ab=0,∀a=0即可。因此,我们可以对上面的式子进行如下整理:
m i n 1 2 ∥ W ∥ 2 s . t . y i ( W T x i + b ) ≥ 1 , 1 ≤ i ≤ n , i ∈ Z min\quad \frac 1 2{\parallel W\parallel}^2\quad s.t.\\ y_i(W^Tx_i+b)\ge1,\quad 1\le i \le n, i \in Z\\ min21∥W∥2s.t.yi(WTxi+b)≥1,1≤i≤n,i∈Z
上面的优化问题显然是一个凸优化,可以通过最优化理论学习到的知识找到最优解。
非线性可分模型
我们只需要在原优化问题中引入松弛变量 ϵ \epsilon ϵ便可继续求解 W , b W,b W,b,即:
m i n 1 2 ∥ W ∥ 2 + C ∑ i = 1 n ϵ i s . t . y i ( W T x i + b ) ≥ 1 − ϵ i , 1 ≤ i ≤ n , i ∈ Z ϵ i ≥ 0 , 1 ≤ i ≤ n , i ∈ Z min\quad \frac 1 2{\parallel W\parallel}^2 + C\sum_{i=1}^{n}\epsilon_i\quad s.t.\\ y_i(W^Tx_i+b)\ge 1 - \epsilon_i,\quad 1\le i \le n, i \in Z\\ \epsilon_i \ge 0,\quad 1\le i \le n, i \in Z\\ min21∥W∥2+Ci=1∑nϵis.t.yi(WTxi+b)≥1−ϵi,1≤i≤n,i∈Zϵi≥0,1≤i≤n,i∈Z
上面的问题依然是一个凸优化,但是我们不难发现,即使我们求出 W , b W,b W,b,我们依然不能通过 W x + b = 0 Wx+b=0 Wx+b=0对非线性可分数据集进行划分。
如何解决?升维,如果一个数据集在低维非线性可分,其在高维可能线性可分。
升维如何通过数学表示?函数。
下面给出另一个非线性可分的例子(异或问题):
plot.close()
dotNum = 10
delta = 0.05
x1 = np.random.rand(dotNum) + delta
y1 = np.random.rand(dotNum) + delta
x2 = (np.random.rand(dotNum) + delta) * -1
y2 = (np.random.rand(dotNum) + delta) * -1
x3 = np.random.rand(dotNum) + delta
y3 = (np.random.rand(dotNum) + delta) * -1
x4 = (np.random.rand(dotNum) + delta) * -1
y4 = np.random.rand(dotNum) + delta
fig, ax = plot.subplots(figsize=figSize)
ax.plot(x1, y1, "x", color = "red")
ax.plot(x2, y2, "x", color = "red")
ax.plot(x3, y3, "o", color = "blue")
ax.plot(x4, y4, "o", color = "blue")
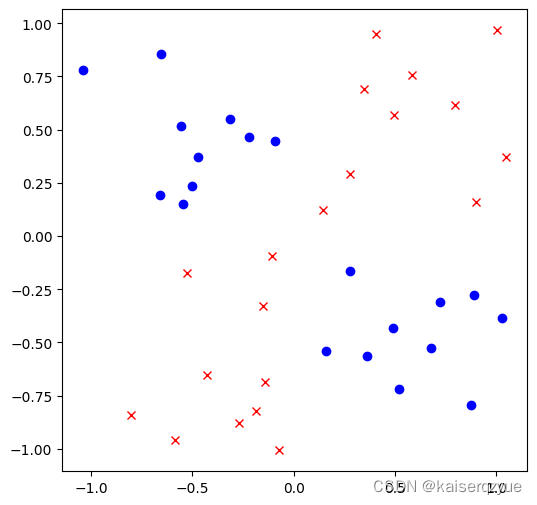
上面的例子显然非线性可分,不过如果我们通过升维函数: Φ ( x , y ) = ( x , y , x × y ) \Phi(x, y) = (x, y, x \times y) Φ(x,y)=(x,y,x×y)便可以获得三维坐标系下的一个线性可分数据集。
其中 z ≥ 0 z\ge0 z≥0的是一类, z < 0 z\lt0 z<0的是一类。
plot.close()
def upgrageXOR(x):return x[0] * x[1]
z1 = list(map(upgrageXOR, zip(x1, y1)))
z2 = list(map(upgrageXOR, zip(x2, y2)))
z3 = list(map(upgrageXOR, zip(x3, y3)))
z4 = list(map(upgrageXOR, zip(x4, y4)))
fig = plot.figure(figsize = figSize)
ax = plot.axes(projection = '3d')
partSlice = slice(0, 5, 1)
ax.scatter3D(x1, y1, z1, color = "red")
ax.scatter3D(x2, y2, z2, color = "red")
ax.scatter3D(x3, y3, z3, color = "blue")
ax.scatter3D(x4, y4, z4, color = "blue")
print(z1[partSlice], z2[partSlice], z3[partSlice], z4[partSlice], sep = "\n")
[0.239201108785093, 0.017559350544461505, 0.08023209278548173, 0.14450350214058533, 0.4912453255956246]
[0.5598293060799046, 0.04942993213533571, 0.23619320598941207, 0.2792950680234368, 0.010465888992148398]
[-0.21178774554679936, -0.39726697761636637, -0.20384691182268425, -0.6917409633280558, -0.37480972879922647]
[-0.28958407125871255, -0.08269375663158536, -0.8102547901685642, -0.12668636290350974, -0.17468973945750135]

另一个问题,高维一定线性可分吗?
已经有定理证明随着维度的提升,新的数据集线性可分的概率单调不减,且线性可分的概率收敛于 1 1 1(这里当然得是双射函数才行)。
也就是说我们只要找到一个无穷升维函数,便一定可以将一个非线性可分的数据集化成线性可分的数据集。
如果假设我们现在已经找到了这样的 Φ \Phi Φ,那么我们的优化问题便可以写成如下的形式:
m i n 1 2 ∥ W ∥ 2 + C ∑ i = 1 n ϵ i s . t . y i ( W T Φ ( x i ) + b ) ≥ 1 − ϵ i , 1 ≤ i ≤ n , i ∈ Z ϵ i ≥ 0 , 1 ≤ i ≤ n , i ∈ Z min\quad \frac 1 2{\parallel W\parallel}^2 + C\sum_{i=1}^{n}\epsilon_i\quad s.t.\\ y_i(W^T\Phi(x_i)+b)\ge 1 - \epsilon_i,\quad 1\le i \le n, i \in Z\\ \epsilon_i \ge 0,\quad 1\le i \le n, i \in Z\\ min21∥W∥2+Ci=1∑nϵis.t.yi(WTΦ(xi)+b)≥1−ϵi,1≤i≤n,i∈Zϵi≥0,1≤i≤n,i∈Z
即使让 C C C等于 0 0 0上面优化问题依然存在解,不过此时 C ∑ i = 1 n ϵ i C\sum_{i=1}^{n}\epsilon_i C∑i=1nϵi的作用是作为正则项防止出现过拟合的情况。
Kernel Function
新的问题出现了,如何找到 Φ \Phi Φ使得变换后的数据集是线性可分的?
事实上,找到这样的 Φ \Phi Φ是非常困难的,我们似乎从一个死胡同走到了另一个死胡同。
真的没有办法了吗?
非也,找不到 Φ \Phi Φ,我们去找一个其他Kernel Function。
事实上,有下面的定理成立:
我们并不需要找到一个 Φ \Phi Φ,只需要找到一个 K K K,其满足 K ( x 1 , x 2 ) = Φ ( x 1 ) T Φ ( x 2 ) K(x_1,x_2) = \Phi(x_1)^T\Phi(x_2) K(x1,x2)=Φ(x1)TΦ(x2),这样的 K K K依然可以求解上述优化问题。
新的问题又出现了,这样的 K K K一定能找到吗?
是的,这样的 K K K一定能找到,真是踏破铁鞋无觅处,得来全不费工夫。
实际上,若一个 K K K,满足以下两点:
- K ( x 1 , x 2 ) = K ( x 2 , x 1 ) K(x_1, x_2) = K(x_2, x_1) K(x1,x2)=K(x2,x1)
- ∀ c i , x i , i ∈ [ 1 , n ] , i ∈ Z , 都有 ∑ i = 1 n ∑ j = 1 n c i c j K ( x i , x j ) ≥ 0 \forall c_i, x_i, i\in[1, n], i\in Z, 都有\sum_{i=1}^{n}\sum_{j=1}^{n} c_ic_jK(x_i,x_j) \ge 0 ∀ci,xi,i∈[1,n],i∈Z,都有∑i=1n∑j=1ncicjK(xi,xj)≥0
则这样的 K K K即满足 K ( x 1 , x 2 ) = Φ ( x 1 ) T Φ ( x 2 ) K(x_1,x_2) = \Phi(x_1)^T\Phi(x_2) K(x1,x2)=Φ(x1)TΦ(x2),其中 Φ \Phi Φ是一个无限升维函数。
常用的两个核函数:
- K ( x 1 , x 2 ) = e − ∥ x 1 − x 2 ∥ 2 2 σ 2 K(x_1, x_2) = e^{-\frac{\parallel x_1 - x_2 \parallel ^2}{2\sigma^2}} K(x1,x2)=e−2σ2∥x1−x2∥2
- K ( x 1 , x 2 ) = ( x 1 T x 2 + 1 ) d K(x_1, x_2) = (x_1^Tx_2+1)^d K(x1,x2)=(x1Tx2+1)d
有了核函数,就可以通过解决对偶问题来解决原问题了(实际上应该是原问题不好解决,尝试解决对偶问题发现可以通过核函数求解对偶问题)。
相信大家都学习过最优化理论这门课程,那么写出上述问题的对偶问题应该不是难事。
完了最优化理论课程上只讲了线性对偶问题,非线性的对偶问题没有涉及。讲了,但只讲了一点点。
对偶问题
对于一个优化问题:
m i n f ( W ) s . t . g i ( W ) ≤ 0 , i ∈ [ 1 , k ] , i ∈ Z h i ( W ) = 0 , , i ∈ [ 1 , k ] , i ∈ Z min\quad f(W)\quad s.t.\\ g_i(W) \le 0, i \in [1, k],\quad i \in Z \\ h_i(W) = 0, , i \in [1, k],\quad i \in Z \\ minf(W)s.t.gi(W)≤0,i∈[1,k],i∈Zhi(W)=0,,i∈[1,k],i∈Z
定义 L ( W , α , β ) = f ( W ) + ∑ i = 1 k α i g i ( W ) + ∑ i = 1 m β i h i ( W ) L(W, \alpha, \beta) = f(W) + \sum_{i = 1}^{k}\alpha_i g_i(W) + \sum_{i = 1}^{m}\beta_i h_i(W) L(W,α,β)=f(W)+∑i=1kαigi(W)+∑i=1mβihi(W),则其对偶问题如下:
m a x Θ ( α , β ) = i n f W L ( W , α , β ) s . t . α i ≥ 0 , i ∈ [ 1 , k ] , i ∈ Z β i ≥ 0 , , i ∈ [ 1 , k ] , i ∈ Z max\quad \Theta(\alpha, \beta) = \underset{W}{inf} L(W, \alpha, \beta)\quad s.t. \\ \alpha_i \ge 0, i \in [1, k],\quad i \in Z \\ \beta_i \ge 0, , i \in [1, k],\quad i \in Z \\ maxΘ(α,β)=WinfL(W,α,β)s.t.αi≥0,i∈[1,k],i∈Zβi≥0,,i∈[1,k],i∈Z
这里的对偶问题与最优化理论课程中介绍的线性对偶问题有着一些相似的定理。
∀ W ∗ , α ∗ , β ∗ \forall W^*,\alpha^*,\beta^* ∀W∗,α∗,β∗是各自问题的可行解,则有 f ( W ∗ ) ≥ Θ ( α ∗ , β ∗ ) f(W^*)\ge\Theta(\alpha^*, \beta^*) f(W∗)≥Θ(α∗,β∗),证明如下:
Θ ( α ∗ , β ∗ ) ≤ L ( W ∗ , α ∗ , β ∗ ) = f ( W ∗ ) + ∑ i = 1 k α i g i ( W ∗ ) ≤ f ( W ∗ ) (1) \Theta(\alpha^*, \beta^*) \le L(W^*, \alpha^*, \beta^*)=f(W^*)+\sum_{i = 1}^{k}\alpha_i g_i(W^*)\le f(W^*) \tag{1} Θ(α∗,β∗)≤L(W∗,α∗,β∗)=f(W∗)+i=1∑kαigi(W∗)≤f(W∗)(1)
强对偶定理:若 f ( W ) f(W) f(W)为凸函数, g i , h i g_i,h_i gi,hi均为线性函数,则有 f ( W ∗ ) = Θ ( α ∗ , β ∗ ) f(W^*)=\Theta(\alpha^*, \beta^*) f(W∗)=Θ(α∗,β∗)。
不难发现若强对偶定理成立,那么 ( 1 ) (1) (1)中的不等号全部要变成等号,于是可以得到 K . K . T . K.K.T. K.K.T.条件: α i g i ( W ∗ ) = 0 , i ∈ [ 1 , k ] , i ∈ Z \alpha_i g_i(W^*)=0,\quad i \in [1, k], i \in Z αigi(W∗)=0,i∈[1,k],i∈Z
要写出 S V M SVM SVM数学问题的对偶形式,我们首先要将原优化问题化成与上面对应的标准形式:
m i n 1 2 ∥ W ∥ 2 − C ∑ i = 1 n ϵ i s . t . − y i Φ ( x i ) T W − y i b + 1 + ϵ i ≤ 0 , 1 ≤ i ≤ n , i ∈ Z ϵ i ≤ 0 , 1 ≤ i ≤ n , i ∈ Z min\quad \frac 1 2{\parallel W\parallel}^2 - C\sum_{i=1}^{n}\epsilon_i\quad s.t.\\ -y_i\Phi(x_i)^TW-y_ib + 1 + \epsilon_i \le 0,\quad 1\le i \le n, i \in Z\\ \epsilon_i \le 0,\quad 1\le i \le n, i \in Z\\ min21∥W∥2−Ci=1∑nϵis.t.−yiΦ(xi)TW−yib+1+ϵi≤0,1≤i≤n,i∈Zϵi≤0,1≤i≤n,i∈Z
于是不难写出其对偶问题如下:
m a x Θ ( α , β ) = i n f ϵ , W , b { 1 2 ∥ W ∥ 2 − C ∑ i = 1 n ϵ i + ∑ i = 1 n α i ( − y i Φ ( x i ) T W − y i b + 1 + ϵ i ) + ∑ i = 1 n β i ϵ i } s . t . α i ≥ 0 , 1 ≤ i ≤ n , i ∈ Z β i ≥ 0 , 1 ≤ i ≤ n , i ∈ Z max\quad \Theta(\alpha, \beta) = \underset{\epsilon,W,b}{inf}\left\{\frac 1 2{\parallel W\parallel}^2 - C\sum_{i=1}^{n}\epsilon_i + \sum_{i=1}^{n}\alpha_i(-y_i\Phi(x_i)^TW-y_ib + 1 + \epsilon_i)+ \sum_{i=1}^{n}\beta_i\epsilon_i\right\}\quad s.t.\\ \alpha_i \ge 0,\quad 1\le i \le n, i \in Z\\ \beta_i \ge 0,\quad 1\le i \le n, i \in Z\\ maxΘ(α,β)=ϵ,W,binf{21∥W∥2−Ci=1∑nϵi+i=1∑nαi(−yiΦ(xi)TW−yib+1+ϵi)+i=1∑nβiϵi}s.t.αi≥0,1≤i≤n,i∈Zβi≥0,1≤i≤n,i∈Z
对偶问题的求解
我们不难发现,上述问题满足强对偶定理,于是我们尝试通过 K . K . T . K.K.T. K.K.T.点求解对偶问题。
我们首先解决inf,对于凸函数而言,只需要其偏导数均等于0即可,因此:
{ ∂ L ∂ W = W − ∑ i = 1 n α i y i Φ ( x i ) = 0 ∂ L ∂ b = α i + β i − C = 0 , 1 ≤ i ≤ n , i ∈ Z ∂ L ∂ ϵ i = ∑ i = 1 n α i y i = 0 , 1 ≤ i ≤ n , i ∈ Z \left\{ \begin{aligned} &\frac {\partial L} {\partial W}=W-\sum_{i=1}^{n}\alpha_i y_i \Phi(x_i) = 0\\ &\frac {\partial L} {\partial b}=\alpha_i+\beta_i-C = 0,\quad 1\le i \le n, i \in Z\\ &\frac {\partial L} {\partial \epsilon_i}=\sum_{i=1}^n\alpha_i y_i = 0,\quad 1\le i \le n, i \in Z\\ \end{aligned} \right. ⎩ ⎨ ⎧∂W∂L=W−i=1∑nαiyiΦ(xi)=0∂b∂L=αi+βi−C=0,1≤i≤n,i∈Z∂ϵi∂L=i=1∑nαiyi=0,1≤i≤n,i∈Z
我们稍加整理便可以得到:
{ W = ∑ i = 1 n α i y i Φ ( x i ) α i + β i = C , 1 ≤ i ≤ n , i ∈ Z ∑ i = 1 n α i y i = 0 , 1 ≤ i ≤ n , i ∈ Z \left\{ \begin{aligned} &W=\sum_{i=1}^{n}\alpha_i y_i \Phi(x_i)\\ &\alpha_i+\beta_i=C,\quad 1\le i \le n, i \in Z\\ &\sum_{i=1}^n\alpha_i y_i = 0,\quad 1\le i \le n, i \in Z\\ \end{aligned} \right. ⎩ ⎨ ⎧W=i=1∑nαiyiΦ(xi)αi+βi=C,1≤i≤n,i∈Zi=1∑nαiyi=0,1≤i≤n,i∈Z
将三个式子带入到 Θ ( α , β ) \Theta(\alpha, \beta) Θ(α,β)中,便可以将对偶问题进行化简得到:
m a x Θ ( α , β ) = Θ ( α ) = ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ i = 1 n α i α j y i y j Φ T ( x i ) Φ ( x j ) = ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ i = 1 n α i α j y i y j K ( x i , x j ) s . t . α i ≥ 0 , 1 ≤ i ≤ n , i ∈ Z ∑ i = 1 n α i y i = 0 , 1 ≤ i ≤ n , i ∈ Z max\quad \Theta(\alpha, \beta)=\Theta(\alpha)=\sum_{i=1}^{n}\alpha_i-\frac 1 2 \sum_{i=1}^{n}\sum_{i=1}^{n}\alpha_i\alpha_jy_iy_j\Phi^T(x_i)\Phi(x_j) =\sum_{i=1}^{n}\alpha_i-\frac 1 2 \sum_{i=1}^{n}\sum_{i=1}^{n}\alpha_i\alpha_jy_iy_jK(x_i,x_j)\quad s.t.\\ \alpha_i \ge 0,\quad 1 \le i \le n, i \in Z\\ \sum_{i=1}^{n}\alpha_i y_i = 0,\quad 1\le i \le n, i \in Z\\ maxΘ(α,β)=Θ(α)=i=1∑nαi−21i=1∑ni=1∑nαiαjyiyjΦT(xi)Φ(xj)=i=1∑nαi−21i=1∑ni=1∑nαiαjyiyjK(xi,xj)s.t.αi≥0,1≤i≤n,i∈Zi=1∑nαiyi=0,1≤i≤n,i∈Z
我们可以通过SMO算法求解上述问题。
新的问题,我们如何通过已经求解出来的 α i \alpha_i αi来求解 W , b W,b W,b?
似乎可以通过 W = ∑ i = 1 n α i y i Φ ( x i ) W=\sum_{i=1}^{n}\alpha_i y_i \Phi(x_i) W=∑i=1nαiyiΦ(xi)求解 W W W,不过我们并不知道 Φ ( x i ) \Phi(x_i) Φ(xi)。
事实上,我们没有必要求解 W W W,对于测试数据,我们只需要知道 W T Φ ( x ) W^T\Phi(x) WTΦ(x):
W T Φ ( x ) = ( ∑ i = 1 n α i y i Φ ( x i ) ) T Φ ( x ) = ∑ i = 1 n α i y i Φ T ( x i ) Φ ( x ) = ∑ i = 1 n α i y i K ( x i , x ) W^T\Phi(x)=(\sum_{i=1}^{n}\alpha_i y_i \Phi(x_i))^T\Phi(x)=\sum_{i=1}^{n}\alpha_i y_i \Phi^T(x_i)\Phi(x) = \sum_{i=1}^{n}\alpha_i y_i K(x_i, x) WTΦ(x)=(i=1∑nαiyiΦ(xi))TΦ(x)=i=1∑nαiyiΦT(xi)Φ(x)=i=1∑nαiyiK(xi,x)
因此我们只需要求解 b b b即可。
由 K . K . T . K.K.T. K.K.T.条件可以知道:
β i ϵ i = 0 , 1 ≤ i ≤ n , i ∈ Z α i ( − y i Φ ( x i ) T W − y i b + 1 + ϵ i ) = 0 , 1 ≤ i ≤ n , i ∈ Z \beta_i\epsilon_i=0,1\le i \le n,\quad i \in Z\\ \alpha_i(-y_i\Phi(x_i)^TW-y_ib + 1 + \epsilon_i)=0,\quad 1\le i \le n, i \in Z\\ βiϵi=0,1≤i≤n,i∈Zαi(−yiΦ(xi)TW−yib+1+ϵi)=0,1≤i≤n,i∈Z
我们可以让 β i ≠ 0 \beta_i\ne 0 βi=0,则 ϵ i = 0 \epsilon_i=0 ϵi=0,若 α i ≠ 0 \alpha_i\ne 0 αi=0则有:
b = 1 − y i Φ ( x i ) T W y i b=\frac{1-y_i\Phi(x_i)^TW}{y_i}\\ b=yi1−yiΦ(xi)TW
我们可以选择多个 α i ≠ 0 \alpha_i \ne 0 αi=0算出多个 b b b求平均值作为最终的 b b b。
最后给出一个例子SVM求解非线性可分的例子(之前的异或问题):
from sklearn import svm
from sklearn.metrics import accuracy_scoremodel = svm.SVC(C = 1, kernel = "rbf", gamma = "scale")
trainDataLen = 100
x1 = np.random.rand(trainDataLen) + delta * np.ones(trainDataLen)
y1 = np.random.rand(trainDataLen) + delta * np.ones(trainDataLen)
x2 = (np.random.rand(trainDataLen) + delta * np.ones(trainDataLen)) * -1
y2 = (np.random.rand(trainDataLen) + delta * np.ones(trainDataLen)) * -1
x3 = np.random.rand(trainDataLen) + delta * np.ones(trainDataLen)
y3 = (np.random.rand(trainDataLen) + delta * np.ones(trainDataLen)) * -1
x4 = (np.random.rand(trainDataLen) + delta * np.ones(trainDataLen)) * -1
y4 = np.random.rand(trainDataLen) + delta * np.ones(trainDataLen)
feature = []
for i in range(trainDataLen):feature.append([x1[i], y1[i]])feature.append([x2[i], y2[i]])feature.append([x3[i], y3[i]])feature.append([x4[i], y4[i]])
label = [1, 1, -1, -1] * trainDataLen
testDataLen = 1000
testFeature = list(zip( np.random.rand(testDataLen) + delta * np.ones(testDataLen),np.random.rand(testDataLen) + delta * np.ones(testDataLen)))
testFeature += list(zip((np.random.rand(testDataLen) + delta * np.ones(testDataLen)) * -1,(np.random.rand(testDataLen) + delta * np.ones(testDataLen)) * -1))
testFeature += list(zip( np.random.rand(testDataLen) + delta * np.ones(testDataLen),(np.random.rand(testDataLen) + delta * np.ones(testDataLen)) * -1))
testFeature += list(zip((np.random.rand(testDataLen) + delta * np.ones(testDataLen)) * -1,np.random.rand(testDataLen) + delta * np.ones(testDataLen)))
testLabel = [1] * testDataLen * 2 + [-1] * testDataLen * 2
testDataLen *= 4fig, ax = plot.subplots(figsize=figSize)
model.fit(feature, label)
predictLabel = list(model.predict(testFeature))
print("testLabel: ", testLabel[:10])
print("predictLabel:", predictLabel[:10])
print("accuracy ratio:", accuracy_score(testLabel, predictLabel))
class1X = []
class1Y = []
class2X = []
class2Y = []
for i in range(testDataLen):if predictLabel[i] == 1:class1X.append(testFeature[i][0])class1Y.append(testFeature[i][1])else:class2X.append(testFeature[i][0])class2Y.append(testFeature[i][1])
ax.plot(class1X, class1Y, "x")
ax.plot(class2X, class2Y, "o")
testLabel: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
predictLabel: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
accuracy ratio: 1.0
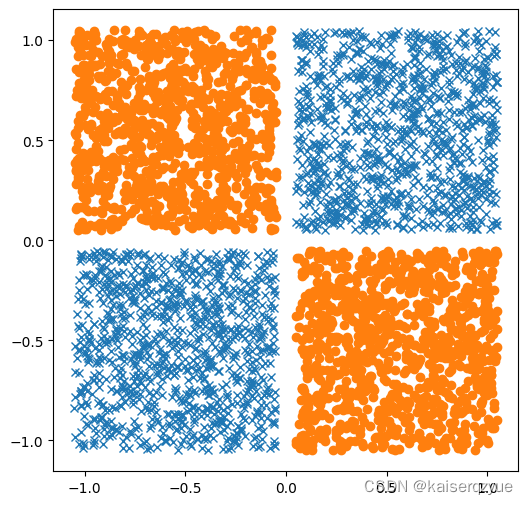
在介绍线性可分的情况下,我们只说了优化问题是一个凸优化,没有给出具体的求解算法。
实际上,对于线性可分的数据集,也可以通过对偶问题求解,相当于使用“核函数” K ( x i , x j ) = x i T x j K(x_i, x_j)=x_i^Tx_j K(xi,xj)=xiTxj(严格来说不是核函数,其不一定满足半正定性)。这样就可以同样使用SMO算法求解线性可分的情况。
处理多类别数据
一个SVM可以解决二分类问题,那么对于一个N分类问题,我们使用多个个SVM即可进行分类。
以三分类问题为例
一类对其他类方法(构造 N N N个SVM):
S V M 1 : ( C 2 C 3 ) v . s . ( C 1 ) S V M 2 : ( C 1 C 3 ) v . s . ( C 2 ) S V M 3 : ( C 1 C 2 ) v . s . ( C 3 ) SVM1:(C_2C_3)v.s.(C1)\\ SVM2:(C_1C_3)v.s.(C2)\\ SVM3:(C_1C_2)v.s.(C3)\\ SVM1:(C2C3)v.s.(C1)SVM2:(C1C3)v.s.(C2)SVM3:(C1C2)v.s.(C3)
一类对另一类方法(构造 C N 2 C^2_N CN2个SVM):
S V M 1 : ( C 1 ) v . s . ( C 2 ) S V M 2 : ( C 1 ) v . s . ( C 3 ) S V M 3 : ( C 2 ) v . s . ( C 3 ) SVM1:(C_1)v.s.(C2)\\ SVM2:(C_1)v.s.(C3)\\ SVM3:(C_2)v.s.(C3)\\ SVM1:(C1)v.s.(C2)SVM2:(C1)v.s.(C3)SVM3:(C2)v.s.(C3)
其他的方法(构造 N − 1 N-1 N−1个SVM):
S V M 1 : ( C 2 C 3 ) v . s . ( C 1 ) S V M 2 : ( C 3 ) v . s . ( C 2 ) \begin{aligned} &SVM1:(C_2C_3)v.s.(C1)\\ &SVM2:(C_3)v.s.(C2)\\ \end{aligned} SVM1:(C2C3)v.s.(C1)SVM2:(C3)v.s.(C2)
参考
【SVM支持向量机】讲解
scikit-learn
matplotlib






![[问题记录] oracle问题汇总记录](https://img-blog.csdnimg.cn/direct/c0ce29a1d53f478c9e18daa0b9e06057.png)