概述
通过使用jupyter进行网络运维的相关测试
设备为H3C
联通性测试
import paramiko
import time
import getpass
import re
import os
import datetimeusername = "*****"
password = "*****"
ip = "10.32.**.**"ssh_client = paramiko.SSHClient()
ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh_client.connect(hostname=ip,username=username,password=password,look_for_keys=False)
command = ssh_client.invoke_shell()print('=-=-=-=-=-=-=-=-=-=-=-=-=-=')
print('已经成功登陆交换机' +" "+ ip)# # 关闭分屏显示
# command.send("Screen-len disable"+"\n")
# # 获取配置信息
# command.send("display current-configuration | in sysname"+"\n")
# time.sleep(3)
# # 输出配置信息
# output_config=command.recv(65535).decode()
# print(output_config)
获取配置信息 + 执行其他命令
在联通性测试ok后,可以在jupyter执行查看配置信息
command.send("Screen-len disable"+"\n")# 获取配置信息
command.send("display current-configuration | in sysname"+"\n")
time.sleep(3)# 输出配置信息
output_config=command.recv(65535).decode()
print(output_config)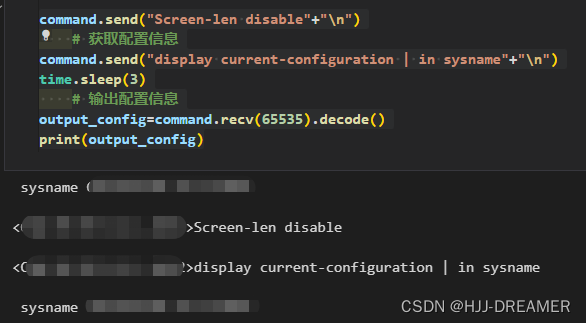
关闭链接
ssh_client.close()批量导出交换机配置
import paramiko
import time
import getpass
import re
import os
import datetimeusername = "******"
password = "******"
f = open('*****.list')# 创建备份目录
now = datetime.datetime.now()
now_date = now.date()
print("now date: " + str(now_date) + "\n")path = "./config/"
os.chdir(path)new_folder = str(now.date())+"-backup"
print("backup folder name: " + new_folder)# 判断目录存在
if not os.path.exists(new_folder):os.makedirs(new_folder)print("backup folder created")
else:print("backup folder already exists")
os.chdir("../")for line in f.readlines():ip = line.strip()ssh_client = paramiko.SSHClient()ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())ssh_client.connect(hostname=ip,username=username,password=password,look_for_keys=False)command = ssh_client.invoke_shell()print('=-=-=-=-=-=-=-=-=-=-=-=-=-=')print('已经成功登陆交换机' +" "+ ip)# 关闭分屏显示command.send("Screen-len disable"+"\n")# 获取配置信息command.send("display current-configuration"+"\n")time.sleep(3)# 输出配置信息output_config=command.recv(65535).decode()# print(output_config)# 交换机名称获取command.send("display current-configuration | in sysname"+"\n")time.sleep(2)swname=command.recv(65535).decode()# print(swname)print("")# 定义正则表达式pattern = r'(?<=<).*(?=>)'regex = re.compile(pattern)match = regex.search(swname)swname = match.group()print("SW Name: " + swname)print("")# 定义文件名file_name = match.group()+".cfg"print("Config file: " + file_name)print("")# 写入文件# w+ 覆盖写入# a+ 追加写入config_files = open("./config/"+ new_folder + "/" + file_name,"w+")print("writing from output_config to " + file_name + "\n") config_files.write(output_config)time.sleep(3)config_files.close()ssh_client.close()print("Job successful: " + ip + " " + swname + " " + file_name + "\n" )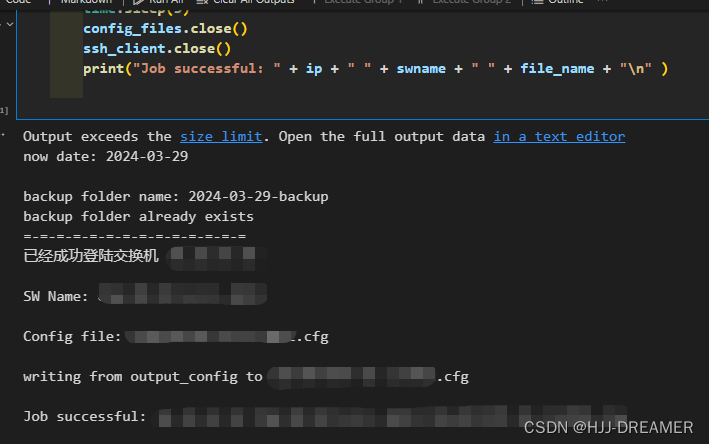
关于正则
# 定义正则表达式
pattern = r'(?:X|H|F)?GE1/0/[0-9].'# https://www.jyshare.com/front-end/854/
# 在Python中,使用re模块匹配字符串"XGE1/0"、"GE1/0"、"HGE1/0"和"FGE1/0"可以通过构造一个正则表达式来实现。
# 这个正则表达式需要能够匹配这四种不同的模式,
# 它们的共同点是都以"GE1/0"结尾,但是可能有不同的前缀("X"、"H"、"F"或没有前缀)。# 解释正则表达式:# (?: ... ):非捕获组,表示组内的模式匹配后不会被单独捕获。
# X|H|F:表示匹配字符"X"或"H"或"F"。
# ?:表示前面的非捕获组是可选的,即可以出现0次或1次。
# GE:表示字符串中必须出现"GE"。
# 1/0:表示字符串结尾是"1/0"。port_list1 = re.findall(pattern, port_list,re.S)
print(port_list1)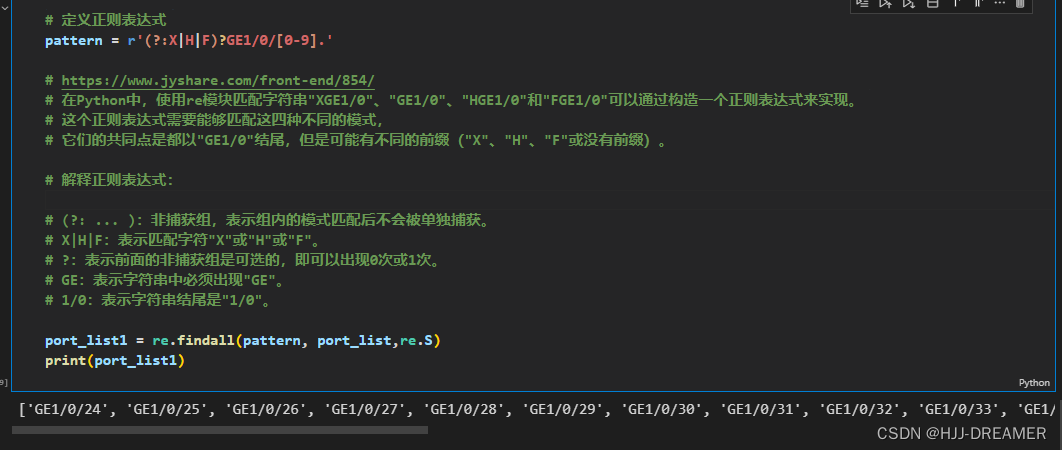
# print(output)
# 正则表达式,用于匹配接口及其媒体类型pattern = r'display\s+interface\s+(FGE1/0/\d+|GE1/0/\d+|HGE1/0/\d+|XGE1/0/\d+).*?Media type is ([^,]+)'# 正则表达式解释:# display\s+interface\s+: 匹配 display interface 开头的文本,\s+代表一个或多个空白字符。
# (FGE1/0/\d+|GE1/0/\d+|HGE1/0/\d+|XGE1/0/\d+): 匹配指定的接口,\d+ 匹配一个或多个数字。
# .*?: 非贪婪匹配任何字符,直到遇到 Media type is。
# Media type is ([^,]+): 匹配 Media type is 之后的文本,直到遇到逗号为止。括号中的 [^,]+ 匹配一系列非逗号的字符。
# 由于您的示例文本中的每个接口行后都直接跟随着媒体类型,因此我们不需要re.DOTALL参数。# 查找所有匹配项
matches = re.findall(pattern, output, re.DOTALL)
output1 = matches
print(output1)
# 打印匹配到的结果
for match in matches:interface, media_type = matchprint(f'Interface: {interface}, Media type: {media_type}')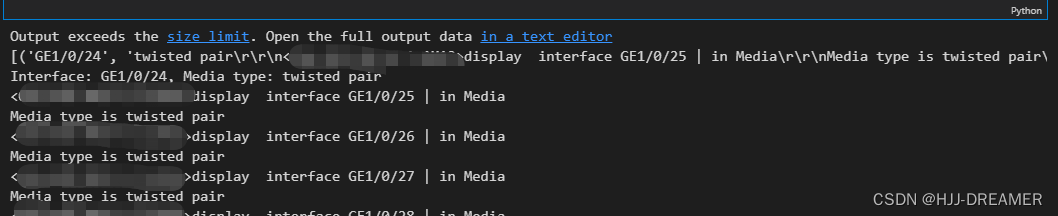
关于pandas使用
import pandas as pd# 将output1转换为DataFrame
df = pd.DataFrame(output1, columns=['Interface', 'Media Type'])# 将DataFrame写入Excel文件
df.to_csv(file_name, index=False, encoding='utf-8')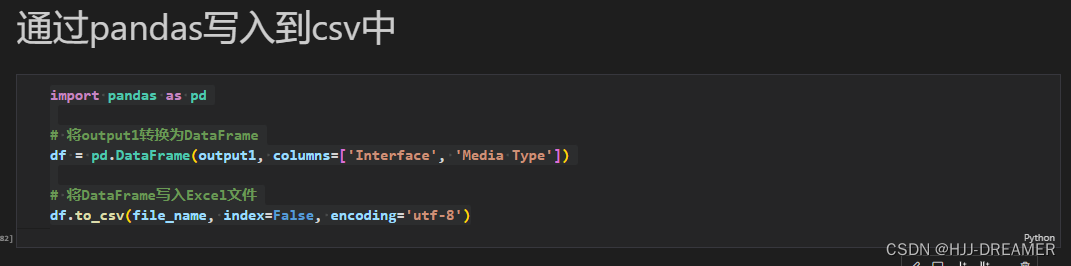
# 设置显示最大行数和列数
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)# 读取Excel文件
df1 = pd.read_csv(file_name)# 打印DataFrame的内容
print(df1)
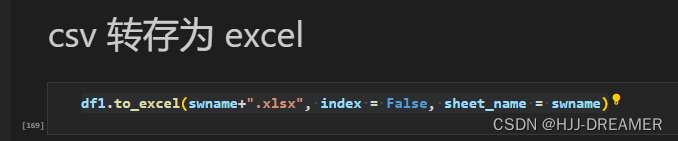
df1.to_excel(swname+".xlsx", index = False, sheet_name = swname)