文章目录
- 1、前言
- 2、源项目实现功能
- 3、运行环境
- 4、如何运行
- 5、运行结果
- 6、遇到问题
- 7、使用框架
- 8、目标检测系列文章
1、前言
1、本文基于YOLOv5+DeepSort的行人车辆的检测,跟踪和计数。
2、该项目是基于github的黄老师傅,黄老师傅的项目输入视频后,直接当场利用cv2.imshow(),查看识别的结果, 无法当场保存检测完视频,而且无法在服务器上跑,本文实现保存视频的结果已经命令行修改视频。
2、源项目实现功能
- 实现了 出/入 分别计数。
- 显示检测类别。
- 默认是 南/北 方向检测,若要检测不同位置和方向,可在 main.py 文件第13行和21行,修改2个polygon的点。
- 默认检测类别:行人、自行车、小汽车、摩托车、公交车、卡车。
- 检测类别可在 detector.py 文件第60行修改。
本项目实现功能
保存识别视频提供命令行修改视频
3、运行环境
- python 3.6+,pip 20+
- pip install -r requirements.txt
4、如何运行
-
下载代码
git clone https://github.com/wisdom-zhe/yolov5-deepsort-counting.git因此repo包含weights及mp4等文件,若 git clone 速度慢,直接点击这里下载zip文件
-
进入目录
cd yolov5-deepsort-counting -
创建 python 虚拟环境
python3 -m venv venv -
激活虚拟环境
source venv/bin/activate -
升级pip
python -m pip install --upgrade pip -
安装pytorch
根据你的操作系统、安装工具以及CUDA版本,在 https://pytorch.org/get-started/locally/ 找到对应的安装命令。我的环境是 ubuntu 18.04.5、pip、CUDA 11.0。
$ pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html -
安装软件包
$ pip install -r requirements.txt -
在 detect-car.py 文件中第262行,设置要检测的视频文件路径,默认为default= ‘./video/test.mp4’
140MB的测试视频可以在这里下载:https://pan.baidu.com/s/1qHNGGpX1QD6zHyNTqWvg1w 提取码: 8ufq
parser.add_argument('--input_video_path', type=str, default='./video/test02.mp4',help='source video path.') -
运行程序
# 本项目运行方式 python detect-car.py # 黄老师傅运行方式 python main.py
5、运行结果
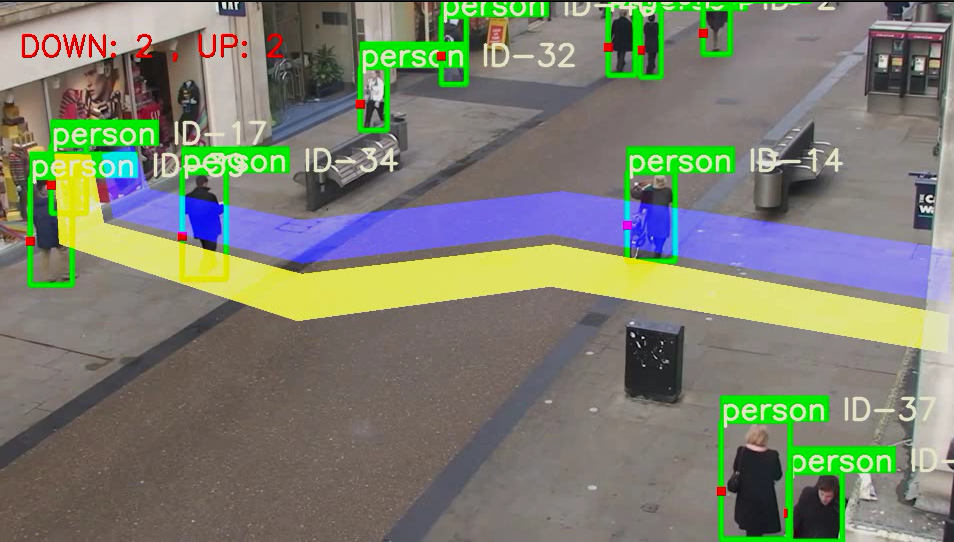
6、遇到问题
问题:视频并未出现两条撞线。
原因:在图片拼接时候,大小不一致。
即cv2.add图像运算方式需要输出的图像–必须与输入的图像具有相同的大小、类型和通道数。即两张图片大小一致。
import numpy as np
import cv2# cv2.add图像运算方式需要输出的图像–必须与输入的图像具有相同的大小、类型和通道数。即两张图片大小一致。
# 查看大小:image.shape
# 背景图
mask_image_temp = np.zeros((1080, 1920), dtype = np.uint8)# 初始化2个撞线polygon
list_pts_blue = [[204, 305], [227, 431], [605, 522], [1101, 464], [1900, 601], [1902, 495], [1125, 379], [604, 437],[299, 375], [267, 289]]
ndarray_pts_blue = np.array(list_pts_blue, np.int32)
polygon_blue_value_1 = cv2.fillPoly(mask_image_temp, [ndarray_pts_blue], color = 1)
polygon_blue_value_1 = polygon_blue_value_1[:, :, np.newaxis]
polygon_mask_blue_and_yellow = cv2.resize(polygon_blue_value_1, (960, 540))# 蓝 色盘 b,g,r
blue_color_plate = [255, 0, 0]
# 蓝 polygon图片
blue_image = np.array(polygon_blue_value_1 * blue_color_plate, np.uint8)
blue_image=cv2.resize(blue_image,(960,540))# 输出背景图片形状
print(f'blue_image_shape:{blue_image.shape}')
# 读取图片
output_image_frame = cv2.imread('./5.jpg')
print(f'output_image_frame_shape:{output_image_frame.shape}')
output_image_frame=cv2.resize(output_image_frame,(960,540))
print(f'output_image_frame_960_540:{output_image_frame.shape}')output_image_frame = cv2.add(output_image_frame, blue_image)text_draw='down---up'
draw_text_postion = (int(960 * 0.01), int(540 * 0.05))
font_draw_number = cv2.FONT_HERSHEY_SIMPLEX
output_image_frame = cv2.putText(img = output_image_frame, text = text_draw,org = draw_text_postion,fontFace = font_draw_number,fontScale = 1, color = (255, 255, 255), thickness = 2)# 显示图像
cv2.imshow('img', output_image_frame)
# cv2.imshow('img', blue_image)
cv2.waitKey(0)
cv2.destroyAllWindows()'''
输出:
blue_image_shape:(540, 960, 3)
output_image_frame_shape:(480, 640, 3)
output_image_frame_960_540:(540, 960, 3)
'''
7、使用框架
- https://github.com/Sharpiless/Yolov5-deepsort-inference
- https://github.com/ultralytics/yolov5/
- https://github.com/ZQPei/deep_sort_pytorch
- 黄老师傅
8、目标检测系列文章
- YOLOv5s网络模型讲解(一看就会)
- 生活垃圾数据集(YOLO版)
- YOLOv5如何训练自己的数据集
- 双向控制舵机(树莓派版)
- 树莓派部署YOLOv5目标检测(详细篇)
- YOLO_Tracking 实践 (环境搭建 & 案例测试)
- 目标检测:数据集划分 & XML数据集转YOLO标签
- YOLOv5改进–轻量化YOLOv5s模型