学习目录:
深度学习理论基础(一)Python及Torch基础篇
深度学习理论基础(二)深度神经网络DNN
深度学习理论基础(三)封装数据集及手写数字识别
深度学习理论基础(四)Parser命令行参数模块
深度学习理论基础(五)卷积神经网络CNN
深度学习理论基础(六)Transformer多头自注意力机制
深度学习理论基础(七)Transformer编码器和解码器
本文目录
- 学习目录:
- 前述: Transformer总体结构框图
- 一、编码器encoder
- 1. 编码器作用
- 2. 编码器部分
- (1)单个编码器层代码
- (2)编码器总体代码
- 二、解码器decoder
- 1. 解码器作用
- 2. 解码器部分
- (1)单个解码器层代码
- (2)解码器总体代码
- 三、Transformer
- 1. 框图
- 2. 代码
前述: Transformer总体结构框图

(1)嵌入层:编码器的输入是一系列的词嵌入(Word Embeddings),它将文本中的每个词映射到一个高维空间中的向量表示。
嵌入层的作用是将离散符号转换为连续的向量表示,降低数据维度同时保留语义信息,提供词语的上下文信息以及初始化模型参数,从而为深度学习模型提供了有效的输入表示。
class Embedder(nn.Module):def __init__(self, vocab_size, d_model):super().__init__()self.d_model = d_modelself.embed = nn.Embedding(vocab_size, d_model)def forward(self, x):return self.embed(x)
(2)位置编码器:为了使 Transformer 能够处理序列信息,位置编码被引入到词嵌入中,以区分不同位置的词。通常使用正弦和余弦函数来生成位置编码。
一句话中同一个词,如果词语出现位置不同,意思可能发生翻天覆地的变化,就比如:我爱你 和 你爱我。这两句话的意思完全不一样。可见获取词语出现在句子中的位置信息是一件很重要的事情。但是Transformer 的是完全基于self-Attention地,而self-attention是不能获取词语位置信息的,就算打乱一句话中词语的位置,每个词还是能与其他词之间计算attention值,就相当于是一个功能强大的词袋模型,对结果没有任何影响。所以在我们输入的时候需要给每一个词向量添加位置编码。
位置编码是通过在输入序列的每个位置上添加一个与位置相关的固定向量来实现的。这个向量会在前向传播过程中与输入的词嵌入向量相加,以产生具有位置信息的新的向量表示。
●公式:

① PE:表示位置编码矩阵,可先使用 torch.zeros(行,列) 创建一个全0的矩阵,然后再通过操作将其中的某些元素赋值,形成含有位置信息的矩阵。
② pos:表示输入序列所在行的位置。范围0~输入序列矩阵行长度。
③ d_model :输入、输出向量的维度大小。
④ i:取值范围为 [ 0, d_model] ,但每次移动步长为2。 因为当 i 为偶数时,使用sin函数,当 i 为奇数时,使用cos函数。
●代码:
class PositionalEncoder(nn.Module):def __init__(self, d_model, max_seq_len = 200, dropout = 0.1):super().__init__()self.d_model = d_model #输入维度self.dropout = nn.Dropout(dropout)pe = torch.zeros(max_seq_len, d_model) # 创建一个形状为 (max_seq_len, d_model) 的位置编码矩阵,元素权威0for pos in range(max_seq_len):for i in range(0, d_model, 2):pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model)))pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * i)/d_model)))pe = pe.unsqueeze(0) # 在第0维度上添加一个维度,变成 (1, max_seq_len, d_model)# PE位置编码矩阵其中的元素修改好后,可以注册位置编码矩阵为模型的 buffer,即封装起来。self.register_buffer('pe', pe) def forward(self, x):# 将输入乘以一个与模型维度相关的缩放因子x = x * math.sqrt(self.d_model)# 将位置编码添加到输入中seq_len = x.size(1)pe = self.pe[:, :seq_len].clone().detach() # 从缓冲区中获取位置编码if x.is_cuda:pe = pe.cuda() # 将位置编码移到GPU上,如果输入张量也在GPU上x = x + pe # 输入向量,加上位置编码器。return self.dropout(x) # 加上丢弃层,防止过拟合。
(3)多头注意力层:这是编码器的核心组件之一。它允许模型在输入序列中学习词与词之间的依赖关系,通过计算每个词对其他词的注意力权重来实现。多头机制允许模型在不同的表示空间中并行地学习多种关注方向。多头注意力层详情查看地址!
def attention(q, k, v, d_k, mask=None, dropout=None): scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:mask = mask.unsqueeze(1)scores = scores.masked_fill(mask == 0, -1e9) scores = F.softmax(scores, dim=-1)if dropout is not None:scores = dropout(scores)output = torch.matmul(scores, v)return outputclass MultiHeadAttention(nn.Module):def __init__(self, heads, d_model, dropout = 0.1):super().__init__()self.d_model = d_model #输入向量的维度self.d_k = d_model // heads #每个头分配向量的维度self.h = headsself.q_linear = nn.Linear(d_model, d_model)self.k_linear = nn.Linear(d_model, d_model)self.v_linear = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)self.out = nn.Linear(d_model, d_model)def forward(self, q, k, v, mask=None):bs = q.size(0)# perform linear operation and split into N headsq = self.q_linear(q).view(bs, -1, self.h, self.d_k)k = self.k_linear(k).view(bs, -1, self.h, self.d_k) v = self.v_linear(v).view(bs, -1, self.h, self.d_k)# transpose to get dimensions bs * N * sl * d_modelk = k.transpose(1,2)q = q.transpose(1,2)v = v.transpose(1,2)scores = attention(q, k, v, self.d_k, mask, self.dropout)concat = scores.transpose(1,2).contiguous().view(bs, -1, self.d_model)output = self.out(concat)return outputif __name__ == '__main__': heads = 8d_model = 64# 创建输入张量 x2 和 mask# 假设 x2 和 mask 的形状为 [batch_size, seq_len, embedding_dim]batch_size = 16seq_len = 10embedding_dim = d_modelx2 = torch.randn(batch_size, seq_len, embedding_dim)mask = torch.zeros(batch_size, seq_len) # 假设没有特殊的 mask# 实例化 MultiHeadAttention 模型attn = MultiHeadAttention(heads, d_model, dropout=0.1)# 使用 MultiHeadAttention 进行前向传播output = attn(x2, x2, x2, mask)print(output.shape) # 输出张量的形状
(4) 规范化层:用于在神经网络中对输入数据进行归一化操作。在多头自注意力层之后,通常会添加残差连接和规范化层来加速训练和提高模型稳定性。
●公式:

① α 是可学习的缩放参数。
② mean(x) 是输入张量 x 在最后一个维度上的均值。
③ std(x) 是输入张量 x 在最后一个维度上的标准差。
④ bias 是可学习的偏置参数。
⑤ eps 是一个非常小的数,用于防止分母为零。
●代码:
"""规范化层"""
class Norm(nn.Module):def __init__(self, d_model, eps = 1e-6):super().__init__()self.size = d_model #输入维度# 创建了一个大小为 self.size 的张量,其中所有元素的值都初始化为 1。#并将这个张量转换为一个可学习的参数,使得它可以被模型访问和更新。self.alpha = nn.Parameter(torch.ones(self.size))self.bias = nn.Parameter(torch.zeros(self.size))self.eps = epsdef forward(self, x):norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) / (x.std(dim=-1, keepdim=True) + self.eps) + self.biasreturn norm(5) 残差连接:主要是通过将数据处理后与原数据相加来得到下一层新的输入数据。目的是为了保存原图信息,防止重要信息的丢失。残差连接使得模型能够更有效地传递梯度,并减轻了训练深层网络时的梯度消失问题。
残差连接要求两个输入的形状相同,以便加法操作后输出张量的形状相同。
通常情况下,残差连接被应用在规范化之后,因为这样可以确保输入和输出的分布一致性,并且有助于提高模型的稳定性和收敛速度。
(6) 前馈全连接层:在多头自注意力层之后,还有一个前馈全连接层,它对每个位置的词向量进行非线性变换和映射。这个前馈全连接层的作用是对输入张量进行两个线性变换,并通过激活函数进行非线性变换,以增加网络的表达能力。
class FeedForward(nn.Module):def __init__(self, d_model, d_ff=2048, dropout = 0.1):super().__init__() # We set d_ff as a default to 2048self.linear_1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.linear_2 = nn.Linear(d_ff, d_model)def forward(self, x):x = self.dropout(F.relu(self.linear_1(x)))x = self.linear_2(x)return x
一、编码器encoder
1. 编码器作用
编码器的作用是将输入序列转换为语义表示,学习输入序列中词与词之间的依赖关系,并提取输入序列的特征表示,为解码器生成目标序列提供有用的信息。
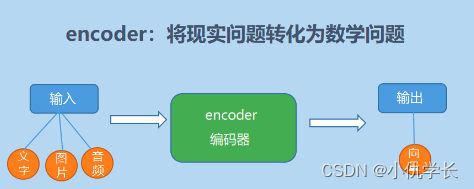
2. 编码器部分
(1)单个编码器层代码
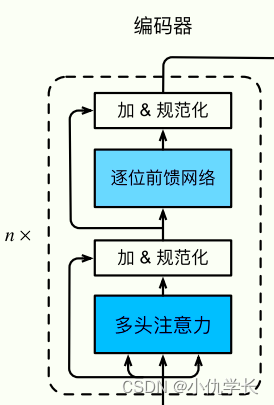
框图解析:对于输入数据,我们先将数据传入注意力机制,然后进行规范化。最后与原数据进行残差连接。前馈网络也如此。这种写法是框图上的顺序写法。但是为了是输入的数据是规范的数据,我们通常先将输入数据进行规范化操作,将规范后的数据传入注意力机制,然后与原数据进行残差连接。详细过程如下:
class EncoderLayer(nn.Module):def __init__(self, d_model, heads, dropout=0.1):super().__init__()self.norm_1 = Norm(d_model) #定义两个规范化层self.norm_2 = Norm(d_model)self.attn = MultiHeadAttention(heads, d_model, dropout=dropout) #定义多头注意力层self.ff = FeedForward(d_model, dropout=dropout) #前馈全连接层self.dropout_1 = nn.Dropout(dropout) #定义两个丢弃层self.dropout_2 = nn.Dropout(dropout)def forward(self, x, mask):x1 = self.norm_1(x)x2 = x + self.dropout_1(self.attn(x1,x1,x1,mask))x3 = self.norm_2(x2)x4 = x2 + self.dropout_2(self.ff(x3))return x4 """ 框图结构中的写法如下: def forward(self, x, mask):x1 = self.dropout_1( self.attn(x,x,x,mask) ) #对输入进行注意力机制,并通过丢弃层,防止过拟合。x1 = self.norm_1(x1) #对x1进行规范化。x2 = x + x1 #进行残差连接,注意力中qkv全部来自自身。x3 = self.dropout_2(self.ff(x2)) #将残差连接后的数据传入前馈全连接层x3 = self.norm_2(x3) #对输入x2进行规范化x4 = x2 + x3 #进行残差连接return x4
"""
(2)编码器总体代码
这里需要将上述的编码器层进行克隆复制n份。
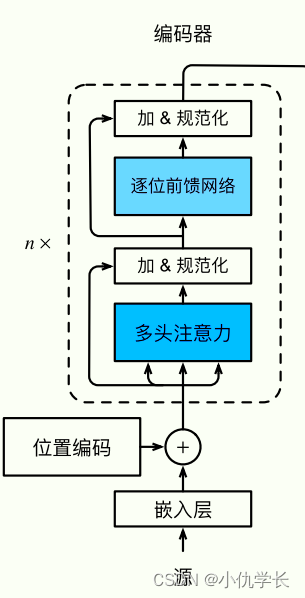
"""编码器总体"" #克隆多层编码器层 def get_clones(module, N):return nn.ModuleList([copy.deepcopy(module) for i in range(N)])class Encoder(nn.Module):def __init__(self, vocab_size, d_model, N, heads, dropout):super().__init__()self.N = N #n个编码器层self.embed = Embedder(vocab_size, d_model) #嵌入层self.pe = PositionalEncoder(d_model, dropout=dropout) #位置编码self.layers = get_clones(EncoderLayer(d_model, heads, dropout), N) #复制n个编码器层self.norm = Norm(d_model) #规范化层def forward(self, src, mask):x = self.embed(src)x = self.pe(x)for i in range(self.N):x = self.layers[i](x, mask)return self.norm(x) #确保输出的数据为规范数据
二、解码器decoder
1. 解码器作用
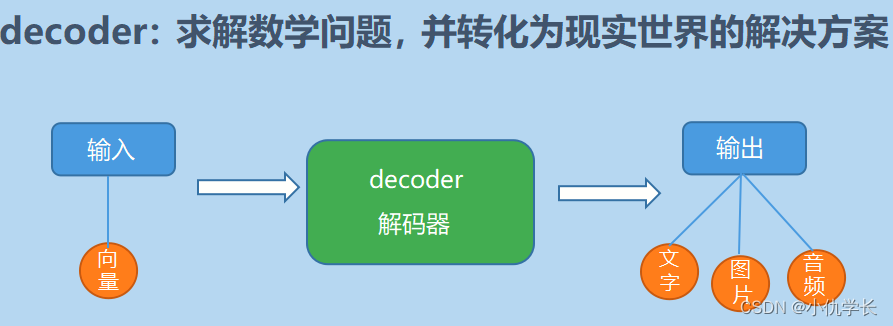
2. 解码器部分
(1)单个解码器层代码
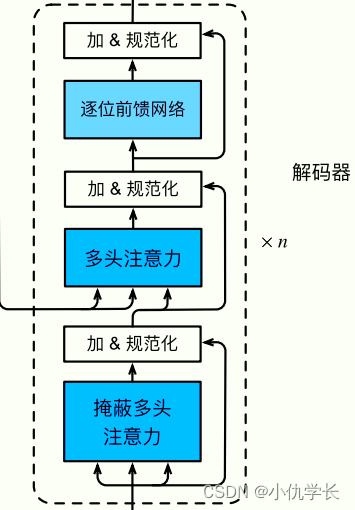
class DecoderLayer(nn.Module):def __init__(self, d_model, heads, dropout=0.1):super().__init__()self.norm_1 = Norm(d_model) #定义规范化层self.norm_2 = Norm(d_model)self.norm_3 = Norm(d_model)self.dropout_1 = nn.Dropout(dropout) #定义丢弃层self.dropout_2 = nn.Dropout(dropout)self.dropout_3 = nn.Dropout(dropout)self.attn_1 = MultiHeadAttention(heads, d_model, dropout=dropout) #多头注意力层self.attn_2 = MultiHeadAttention(heads, d_model, dropout=dropout)self.ff = FeedForward(d_model, dropout=dropout) #前馈全连接层def forward(self, x, e_outputs, src_mask, trg_mask):x2 = self.norm_1(x)x = x + self.dropout_1(self.attn_1(x2, x2, x2, trg_mask))x2 = self.norm_2(x)x = x + self.dropout_2(self.attn_2(x2, e_outputs, e_outputs, src_mask))x2 = self.norm_3(x)x = x + self.dropout_3(self.ff(x2))return x
(2)解码器总体代码
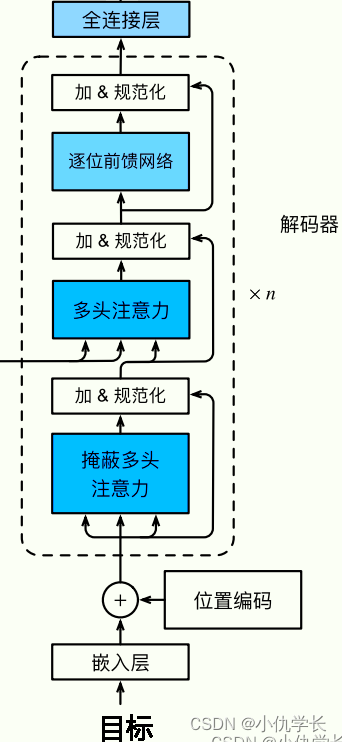
def get_clones(module, N):return nn.ModuleList([copy.deepcopy(module) for i in range(N)])class Decoder(nn.Module):def __init__(self, vocab_size, d_model, N, heads, dropout):super().__init__()self.N = Nself.embed = Embedder(vocab_size, d_model) #嵌入层self.pe = PositionalEncoder(d_model, dropout=dropout) #位置编码self.layers = get_clones(DecoderLayer(d_model, heads, dropout), N) #复制n层解码器层self.norm = Norm(d_model) #规范化层def forward(self, trg, e_outputs, src_mask, trg_mask):x = self.embed(trg) x = self.pe(x)for i in range(self.N):x = self.layers[i](x, e_outputs, src_mask, trg_mask)return self.norm(x)
三、Transformer
1. 框图
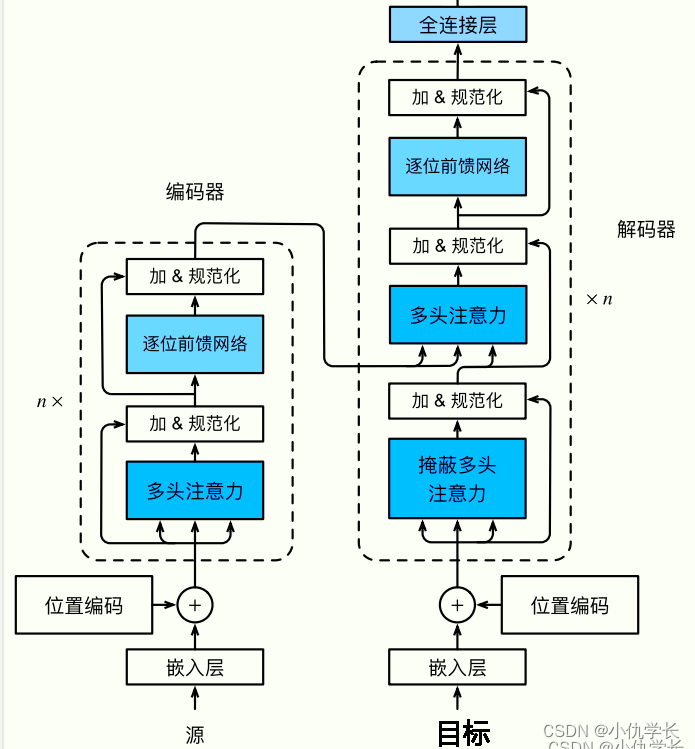
2. 代码
class Transformer(nn.Module):def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout):super().__init__()self.encoder = Encoder(src_vocab, d_model, N, heads, dropout) #编码器总体self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout) #解码器总体self.out = nn.Linear(d_model, trg_vocab) #全连接层输出def forward(self, src, trg, src_mask, trg_mask):e_outputs = self.encoder(src, src_mask) d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)output = self.out(d_output)return outputmodle=Transformer()