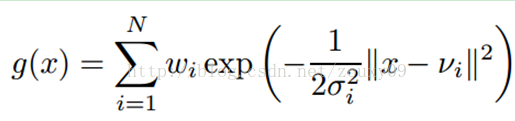【通览一百个大模型】Anthropic LLM(Anthropic)
作者:王嘉宁,本文章内容为原创,仓库链接:https://github.com/wjn1996/LLMs-NLP-Algo
订阅专栏【大模型&NLP&算法】可获得博主多年积累的全部NLP、大模型和算法干货资料大礼包,近200篇论文,300份博主亲自撰写的markdown笔记,近100个大模型资料卡,助力NLP科研、学习和求职。
Anthropic LLM大模型基本信息资料卡
| 序号 | 大模型名称 | 归属 | 推出时间 | 规模 | 预训练语料 | 评测基准 | 模型与训练方法 | 开源 | 论文 | 模型地址 | 相关资料 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 32 | Anthropic LM | Anthropic | 2022-04 | 52B | 核心的base数据集:数据来自于基础语言模型(context-distilled LM,参数量是520亿),包括了4.4万有效数据对和4.2万条无害数据对。 RS数据集:通过拒绝采样模型搜集(该模型是在base数据集上训练得到的偏好模型,参数量是520亿),包含了5.2万的有效数据对和2千个无害数据对, online数据集:来自于RLHF模型,在5周里,每周更新一次,包含2.2万有效数据对,不包含无害性数据。 |  论文的整体流程如上图所示,以预训练模型为起点(PLM),往左根据互联网的比较数据进行预训练,得到预训练偏好模型(PMP),然后再在人类返回的比较数据集上微调,得到偏好模型(PM);再以PLM为起点,往下根据提示数据,将520亿参数的模型结果蒸馏给更小的模型(会独立训练多个不同参数量的模型,从1300万到520亿),这个模型会作为强化学习的初始策略模型,然后以PM模型作为奖励模型,基于PPO的方法进行强化学习训练;根据得到的强化学习策略模型,生成新的对比数据,人工标注后重新训练PM模型,然后再重新训练强化学习模型,如此迭代。 论文的整体流程如上图所示,以预训练模型为起点(PLM),往左根据互联网的比较数据进行预训练,得到预训练偏好模型(PMP),然后再在人类返回的比较数据集上微调,得到偏好模型(PM);再以PLM为起点,往下根据提示数据,将520亿参数的模型结果蒸馏给更小的模型(会独立训练多个不同参数量的模型,从1300万到520亿),这个模型会作为强化学习的初始策略模型,然后以PM模型作为奖励模型,基于PPO的方法进行强化学习训练;根据得到的强化学习策略模型,生成新的对比数据,人工标注后重新训练PM模型,然后再重新训练强化学习模型,如此迭代。 | HH-RLHF | 论文 | Anthropic LM介绍 |
论文标题:Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
论文链接:https://arxiv.org/pdf/2204.05862.pdf
论文数据地址:https://github.com/anthropics/hh-rlhf
LLM系列主要会分享大语言模型,包括gpt1、gpt2、gpt3、codex、InstructGPT、Anthropic LLM、ChatGPT、LIMA、RWKV等论文或学术报告。本文主要分享Anthropic LLM的论文。
介绍
该论文与InstructGPT很像,发表时间也很接近,可以连贯起来一起看。
论文通过收集人类偏好数据,使用偏好模型(PM)以及强化学习技术(PPO/RLHF)训练自然语言模型,使得模型既相对有效又比较无害。
论文根据RLHF训练的模型在大部分nlp任务上效果都比原始的模型要好,如下图所示。论文认为可以将对齐任务和特定的nlp任务混合起来训练,能够不影响对齐效果也不影响任务性能。
整体流程

论文的整体流程如上图所示,以预训练模型为起点(PLM),往左根据互联网的比较数据进行预训练,得到预训练偏好模型(PMP),然后再在人类返回的比较数据集上微调,得到偏好模型(PM);再以PLM为起点,往下根据提示数据,将520亿参数的模型结果蒸馏给更小的模型(会独立训练多个不同参数量的模型,从1300万到520亿),这个模型会作为强化学习的初始策略模型,然后以PM模型作为奖励模型,基于PPO的方法进行强化学习训练;根据得到的强化学习策略模型,生成新的对比数据,人工标注后重新训练PM模型,然后再重新训练强化学习模型,如此迭代。
论文认为,整个流程中最重要的步骤是:人类反馈数据收集,偏好模型训练以及RLHF训练。
与InstructGPT相比,InstructGPT包含了一个监督学习的阶段,本论文没有该阶段,不过有个较为相似的蒸馏阶段;InstructGPT没有进行无害性训练,而本论文结合了有效性数据和无害性数据一起训练;InstructGPT的PM模型只有60亿参数,本论文的PM模型最大有520亿参数;InstructGPT在RL阶段混合了预训练数据来避免评估性能的损失,而本论文并没有混合预训练数据。
还有一个最大的不同,本论文进行了“在线”训练,部署不同的模型供用户使用,以获取更高质量的数据以及降低长尾数据分布的影响,然后不断迭代训练新的模型。
下图展示了经过RLHF训练后的模型效果。可以看出,经过RLHF训练的模型比原模型效果普遍更好,且随着模型规模提高模型效果越好;“online”在线训练能让模型效果更好,如果只在有效性数据上进行训练,模型效果更好,但同时无害性也有一定下降,一定程度表明有效性跟无害性的对立关系。
数据
论文论证了有效性和无害性通常是对立的,所以有效性数据和无害性数据也是分开收集的。对于有效性数据收集任务,标注人员会判断哪个结果更有效,对于无害性数据收集任务,标注人员则会判断哪个结果更无害。数据主要包括了以下三类:
- 核心的base数据集:数据来自于基础语言模型(context-distilled LM,参数量是520亿),包括了4.4万有效数据对和4.2万条无害数据对。
- RS数据集:通过拒绝采样模型搜集(该模型是在base数据集上训练得到的偏好模型,参数量是520亿),包含了5.2万的有效数据对和2千个无害数据对,
- online数据集:来自于RLHF模型,在5周里,每周更新一次,包含2.2万有效数据对,不包含无害性数据。
下文中涉及到的大多数数据或者“静态”数据都是指base数据集+RS数据集,所以可以看出,训练PM的数据基本来自于520亿参数的模型,但在进行RLHF训练时,较小规模的模型根据提示产生的回复,可能就在PM训练数据的分布之外,这增加了小规模模型的训练难度。但实际从上小节图片中可以看出,小规模参数模型依然学习到了有用的信息,哪怕参数量小55倍,依然比不进行RLHF训练的大参数模型效果更好。
上下文蒸馏
该阶段会将520亿参数模型的效果,蒸馏给不同大小的模型,以此作为后续强化学习的初始策略模型。 蒸馏时batch size为32,学习率是预训练【1】时的0.05倍,会一直衰减到0,蒸馏过程一共使用了3.5亿个token数据。该阶段的训练步骤大体如下:
- 准备提示数据,50%来自于预训练,50%来自于StackExchange数据集。对于预训练数据,直接把提示放到“Human:”后面,作为对话中用户侧的输入;对于StackExcahnge 数据,则将问题作为用户侧的输入,点赞率最高的作为模型助手的回复。
- 对于两类提示数据,都输入到预训练好的520亿参数的语言模型中,然后记录下top50的对数概率/token及其索引,形成一个新的小数据集。
- 进行上下文的蒸馏,所有不同大小的模型都在步骤2中的数据上进行微调,使用KL散度作为loss,对于每一个token都是一个51分类,第51分类代表除了top50之外的所有token的概率和。
偏好模型
偏好模型是在比较数据集上进行训练的,每一个样本包括一个提示数据以及一对回复数据,提示里面可能包含了人类和模型的多轮对话信息。
PM模型的大小从1300万到520亿不等,所有的模型都经过了三个阶段:
- 在大规模语料上进行语言模型的预训练【1】。
- 偏好模型的预训练,训练数据来自于StackExchange/Reddit/Wikipedia的混合对比数据。学习率是LM预训练的10%。
- 在人类反馈数据上进行微调,学习率是LM预训练的1%,最大序列长度是1024,基于“online”继续训练时,最大长度为2048。
为了防止过拟合,每个阶段只训练了一轮。更多细节参考【1】。
上图显示了PM训练数据的对话轮次分布和不同大小的模型在不同分布上的准确性差异。大部分数据对话轮次都在3轮之内;模型在首轮对话的准确性最高,2轮对话后就有较大下降,多轮之后继续缓慢下降;也可以看出,模型参数规模越大,准确性越高。
这张图依然展示了PM模型的准确性,比较训练数据量/模型规模/有效性数据集/无害性数据集对准确性的影响。图中可以看出,训练数据的增加和模型参数量的增大,整体的准确性越来越高;对于不同的数据集,也几乎是模型规模越大效果越好,在无害性数据上,模型规模的继续提高并没有再有效果。
该图展示了PM模型得分的准确性,PM的得分差异越大,PM的准确性就越高;并且PM只在有效性数据上训练的时候效果更好,在有效性和无害性混合数据上训练的时候,是欠拟合的。
论文还观察到,如果要求样本对中的每个PM得分都要超过一个阈值,那么PM的准确性将随着阈值的增大而降低,如下图所示。这表明PM模型对高分样本判断不置信,一定程度上是因为缺少高质量高分样本对导致的,所以论文增加了“online”学习阶段,“online”阶段可以提供更多的高分样本,用来重新训练PM模型。
RLHF
论文根据PM模型进行强化学习(RL),包括下面两个步骤:
- 准备比较数据集,训练PM模型,PM模型会给“更好的回复”一个更高的得分。
- 获取之前所有的提示数据,根据PM的得分,训练一个RL策略(该策略会给每一个提示生成一个回复,PM会给每一个回复提供一个得分)。
上述步骤2中的提示数据,不完全来自于已有的训练数据,还有一些提示是使用大语言模型生成的。
该流程的主要思想是使用偏好模型来引导策略生成更好的回答。然而如前面所讲,PM在得分较高时也会变得不那么置信,因此更高的奖励并不一定意味着更好的表现。
论文基于PPO方法进行RL训练,奖励是根据PM得分及KL散度惩罚获取的,公式如下所示:
t t o t a l = r P M − λ K L × D K L ( p o l i c y ∣ ∣ p o l i c y 0 ) t_{total}=r_{PM}-\lambda_{KL}\times D_{KL}(policy||policy_0) ttotal=rPM−λKL×DKL(policy∣∣policy0)
其中 λ K L \lambda_{KL} λKL是大于0的超参数,实际应用中, λ K L = 0.001 \lambda_{KL}=0.001 λKL=0.001,该值非常小,在RL训练过程中,大部分情况起到的作用都比较小,因为 D K L D_{KL} DKL通常小于100,所以这部分有可能是不需要的。 r P M r_{PM} rPM是PM模型的得分,可以根据下面公式计算“相比于B选择A”的概率:
P ( A > B ) = 1 1 + e r P M ( B ) − r P M ( A ) P(A>B)=\frac{1}{1+e^{r_{PM(B)}-r_{PM(A)}}} P(A>B)=1+erPM(B)−rPM(A)1
论文发现,模型的效果与 D P M \sqrt{D_{PM}} DPM基本成线性关系(且不同规模的模型都有相似的线性系数),如下图所示,但随着 D P M \sqrt{D_{PM}} DPM持续增大到某个阈值之后,模型效果略有下降,这表明偏好模型不那么稳健,更容易在更高的回报中被利用。
除此之外,论文在实验中还发现:RLHF在较高的PM分数下逐渐变得不那么鲁棒,较大的偏好模型比较小的偏好模型更鲁棒,以及有效性数据和无害性数据之间的对立性。
在线迭代RLHF
PM在高分数据上不太鲁棒,为了缓解缺少高分数据的问题,论文提出了在线迭代RLHF:
- 先训练出效果最好的RLHF策略模型,根据该模型生成比较数据进行人工标注。因为该RLHF模型已经被PM模型优化过,所以其产生的数据会偏向于让PM得分比较高的数据。
- 将新比较数据与已有的数据混合,训练一个新的PM模型,然后再用新的PM模型训练新的RLHF策略模型。
论文假设在线RLHF策略能够收集PM得分比较高的数据,这样训练出来的新PM模型会在更高得分的数据上表现更好,从而能够辅助训练更好的RLHF策略模型。
不过RLHF往往会降低策略的熵(loss下降是个熵减过程),这将会降低收集数据的多样性(数据越多样,熵越高)。论文通过部署不同版本的RL模型和在线迭代模型来缓解该问题。
其他
论文担心对齐技术可能会损害模型的性能,但从实验结果看,似乎参数量越大的模型损害得越小。
各种实验都表明,有效性和无害性是有对立关系的,论文里是通过调整loss权重的方式结合有效数据和无害数据,公式如下:
L o s s T o t a l = L o s s H e l p f u l n e s s + λ × L o s s H a r m l e s s n e s s Loss_{Total}=Loss_{Helpfulness}+\lambda\times Loss_{Harmlessness} LossTotal=LossHelpfulness+λ×LossHarmlessness
论文还提出了一些降低模型有害性输出的方法,比如OOD(分布外检测),通过直接判断提示文本,来拒绝部分奇怪或者有害的请求。
参考
【1】A general language assistant as a laboratory for alignment.
博客记录着学习的脚步,分享着最新的技术,非常感谢您的阅读,本博客将不断进行更新,希望能够给您在技术上带来帮助。
【大模型&NLP&算法】专栏
近200篇论文,300份博主亲自撰写的markdown笔记。订阅本专栏【大模型&NLP&算法】专栏,或前往https://github.com/wjn1996/LLMs-NLP-Algo即可获得全部如下资料:
- 机器学习&深度学习基础与进阶干货(笔记、PPT、代码)
- NLP基础与进阶干货(笔记、PPT、代码)
- 大模型全套体系——预训练语言模型基础、知识预训练、大模型一览、大模型训练与优化、大模型调优、类ChatGPT的复现与应用等;
- 大厂算法刷题;