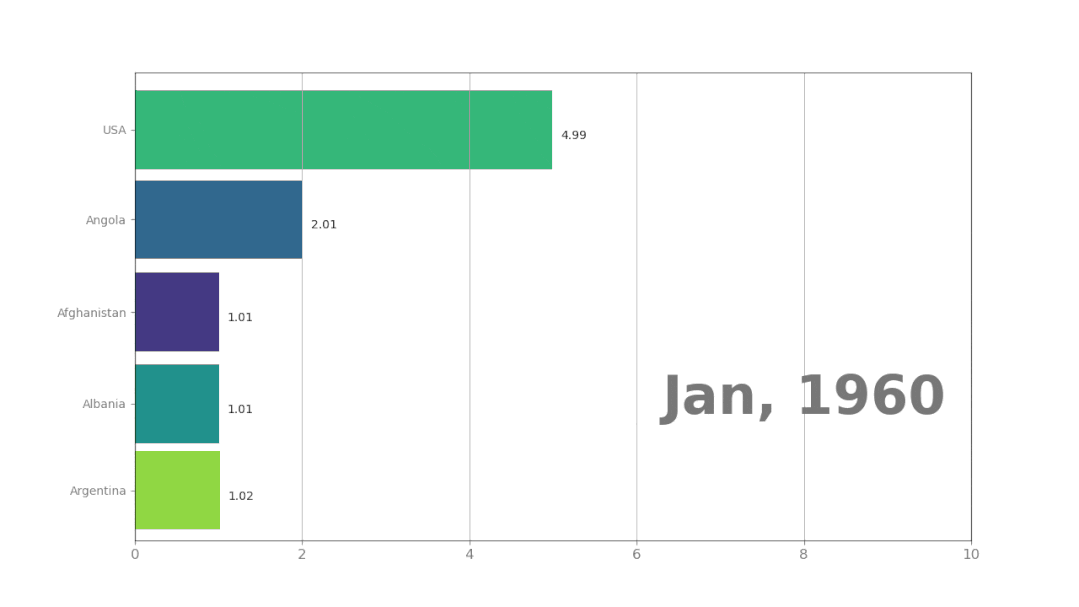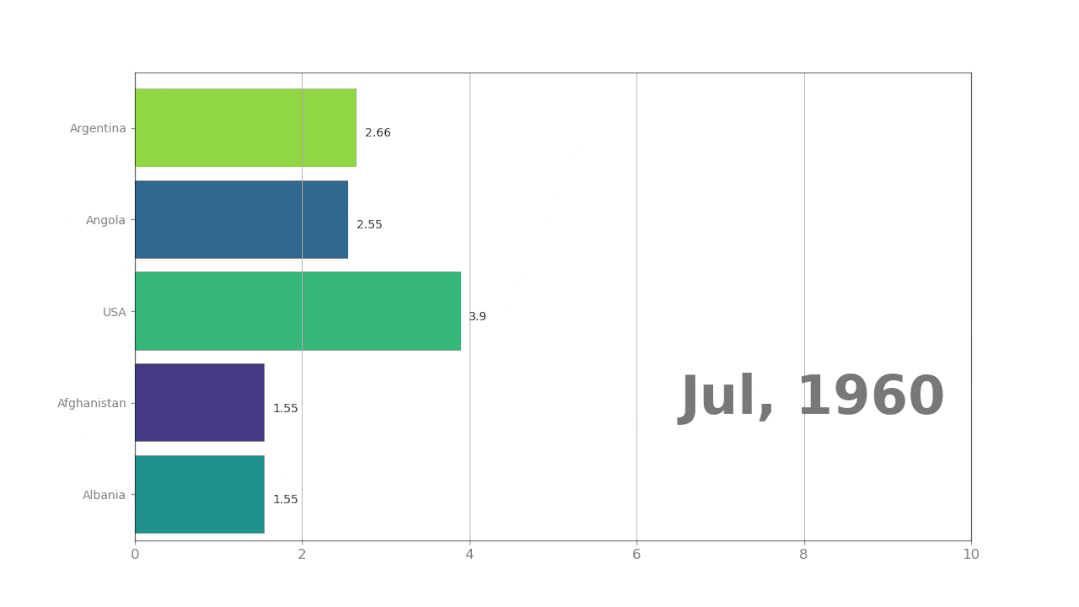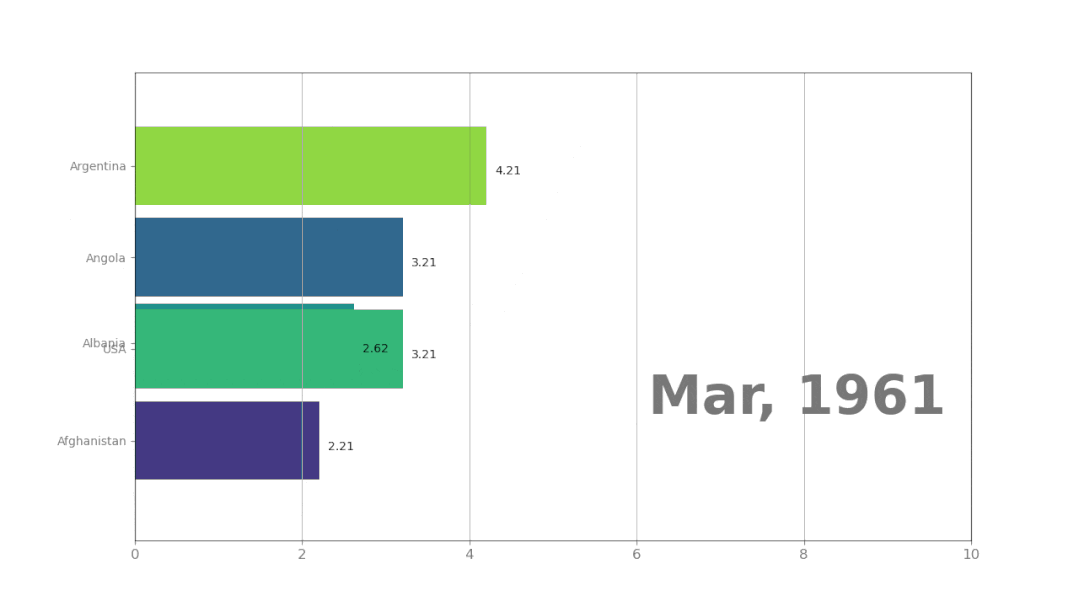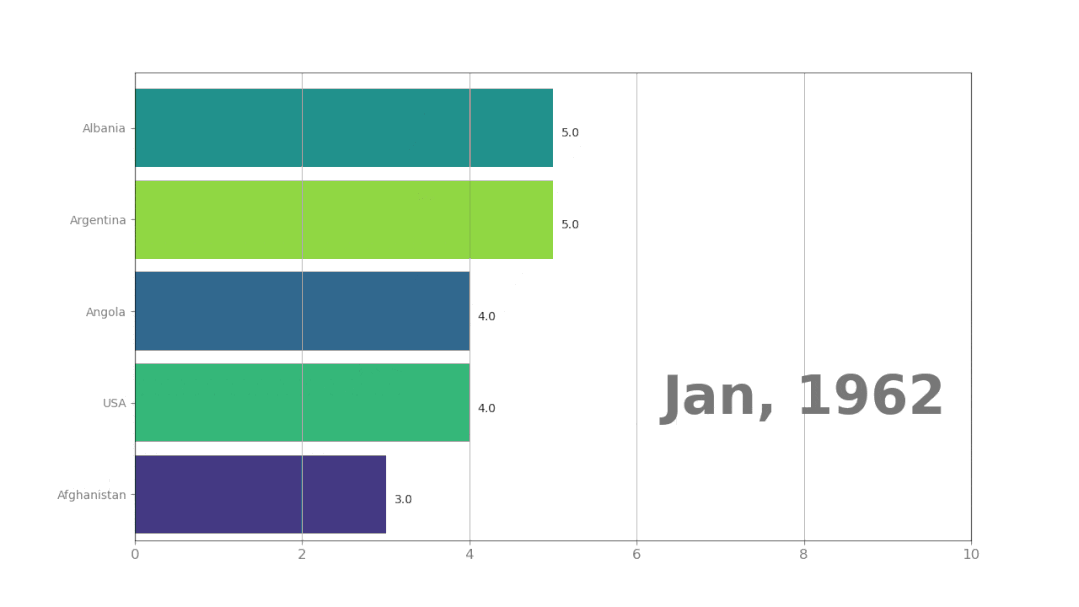现在有很多个网页:

要批量提取网页内的文本:

可以在ChatGPT中这样写提示词:
你是一个Python专家,写一段Python程序,完全提取网页文本内容的任务,下面是一步步的步骤:
打开表格文件,文件路径:F:\传感器企业大全(传感器专家网)20230714.xlsx;
获取表格E2单元格到E3939的单元格的内容,如“/brand/6182.html”,前面加上“https://www.sensorexpert.com.cn”,构成一个URL,注意:从第2行开始读取;
打开这个URL,Request headers为:
Authority:
http://www.sensorexpert.com.cn
:Method:
GET
:Path:
/brand/6182.html
:Scheme:
https
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding:
gzip, deflate, br
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8
Cache-Control:
max-age=0
Sec-Ch-Ua:
"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"
Sec-Ch-Ua-Mobile:
?0
Sec-Ch-Ua-Platform:
"Windows"
Sec-Fetch-Dest:
document
Sec-Fetch-Mode:
navigate
Sec-Fetch-Site:
none
Sec-Fetch-User:
?1
Upgrade-Insecure-Requests:
1
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36
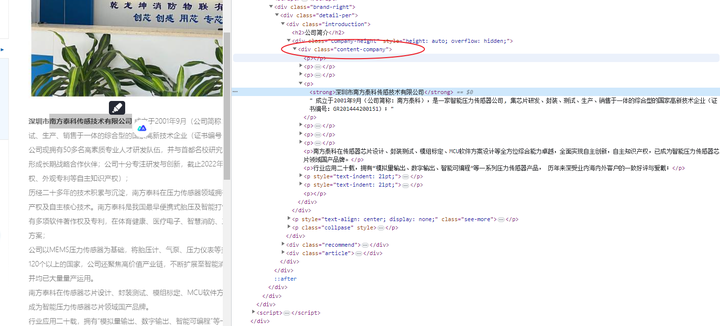
定位xpath=/html/body/div[1]/div/div/div[2]/div[3]/div/div[1]/div/div/p[5]/strong 的strong 元素,提取里面的内容,设为变量:sensortitile,打印输出;
定位class="content-company"的div元素,使用 xpath('.//text()') 来获取所有子元素的文本,并使用 join() 方法将它们连接在一起,然后使用 strip() 方法进行清理;提取的文本内容设为变量:sensorcompany;
在F盘新建一个Excel:传感器企业简介.xlsx,第1列写入sensortitile,第2列写入sensorcompany,第3列内容为“传感器企业大全(传感器专家网)20230714.xlsx”中的URL;
注意:每一步都要输出信息;
如果没有获取到strong 元素或div元素内容,就写入空值;
每爬取1个URL内容,随机暂停3秒以内;
要有应对反爬虫的措施,比如设置请求头;
程序运行后的结果: