文章目录
- 前言
- 在Spark应用中使用Spark SQL
- SQL 表和视图
- 内部表和外部表
- 创建库和表
- 创建视图
- 查看元数据
- 表缓存
- 读取表数据
- 表和 DataFrame 的数据来源
- DataFrameReader
- DataFrameWriter
- Parquet
- JSON
- CSV
- Avro
- ORC
- Images
- Binary Files
- 总结
前言
本文将探讨 Spark 中 Spark SQL 接口是如何与其他外部组件交互的。下边列出了一些 Spark SQL 的能力:
- 为 Spark 上层结构化 API (DataSet, DataFram)提供查询引擎
- 可以读写各种结构化格式的数据(如JSON、Hive表、Parquet、Avro、ORC、CSV)。
- 允许我们使用JDBC/ODBC连接器从外部商业智能(BI)数据源(如Tableau, Power BI, Talend)或rdbms(如MySQL和PostgreSQL)查询数据。
- 提供一个编程接口,用于与数据库中存储为表或视图的结构化数据进行交互
- 提供一个交互式shell,用于对结构化数据发出SQL查询。
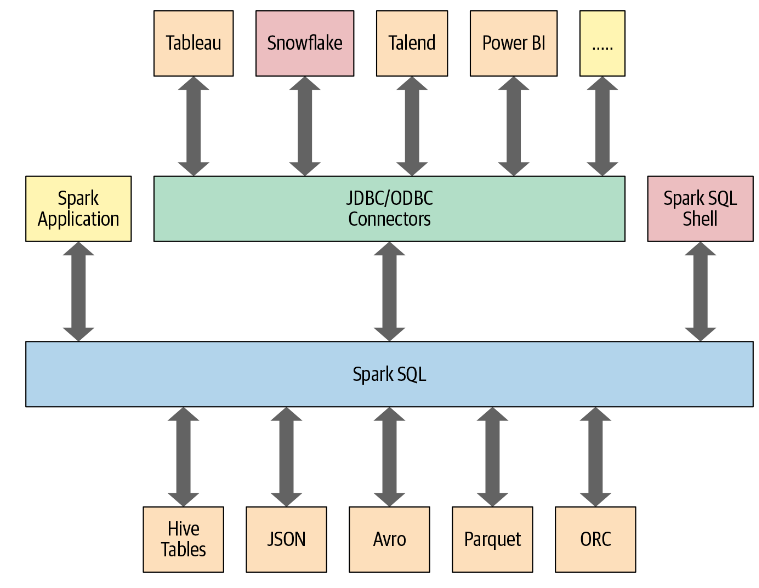
在Spark应用中使用Spark SQL
Spark 2.0 后可以通过实例化一个 SparkSession来执行 sql, 实例化完返回一个DataFram:
# In Python
from pyspark.sql import SparkSession
# Create a SparkSession
spark = (SparkSession.builder.appName("SparkSQLExampleApp").getOrCreate())# Path to data set
csv_file = "/databricks-datasets/learning-spark-v2/flights/departuredelays.csv"# Read and create a temporary view
# Infer schema (note that for larger files you
# may want to specify the schema)
df = (spark.read.format("csv").option("inferSchema", "true").option("header", "true").load(csv_file))
df.createOrReplaceTempView("us_delay_flights_tbl")
现在我们有了一个临时视图,可以使用Spark SQL发出SQL查询:
spark.sql("""SELECT distance, origin, destination
FROM us_delay_flights_tbl WHERE distance > 1000
ORDER BY distance DESC""").show(10)+--------+------+-----------+
|distance|origin|destination|
+--------+------+-----------+
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
+--------+------+-----------+
only showing top 10 rows
上边的 sql 查询也可以转换为使用 DataFrame 查询:
# In Python
from pyspark.sql.functions import col, desc
(df.select("distance", "origin", "destination").where(col("distance") > 1000).orderBy(desc("distance"))).show(10)# Or
(df.select("distance", "origin", "destination").where("distance > 1000").orderBy("distance", ascending=False).show(10))
SQL 表和视图
表保存数据。与Spark中的每个表相关联的是它的相关元数据,这些元数据是关于表及其数据的元信息:schema、描述、表名、数据库名、列名、分区、实际数据所在的物理位置等。所有这些都存储在中心 metastore 中。
默认情况下,Spark使用Apache Hive metastore(位于/user/ Hive /warehouse)来持久化关于表的所有元数据,而不是为Spark表提供单独的metastore。但是,可以通过将Spark配置变量spark.sql.warehouse.dir设置为另一个位置来更改默认位置,该位置可以设置为本地或外部分布式存储。
内部表和外部表
Spark允许创建两种类型的表: 内部表和外部表。对于内部表,Spark同时管理元数据和文件存储中的数据。内部表可以是本地文件系统、HDFS或对象存储(如Amazon S3或Azure Blob)。对于外部表,Spark只管理元数据,具体的数据保存在外部存储中。
对于内部表,由于Spark管理所有内容,因此像DROP table table_name这样的SQL命令可以同时删除元数据和数据。对于外部表,相同的命令将只删除元数据,而不删除实际数据。
创建库和表
创建库
// In Scala/Python
spark.sql("CREATE DATABASE learn_spark_db")
spark.sql("USE learn_spark_db")
创建内部表
// In Scala/Python
spark.sql("CREATE TABLE managed_us_delay_flights_tbl (date STRING, delay INT, distance INT, origin STRING, destination STRING)")
也可以通过 DataFrame API 创建:
# In Python
# Path to our US flight delays CSV file
csv_file = "/databricks-datasets/learning-spark-v2/flights/departuredelays.csv"
# Schema as defined in the preceding example
schema="date STRING, delay INT, distance INT, origin STRING, destination STRING"
flights_df = spark.read.csv(csv_file, schema=schema)
flights_df.write.saveAsTable("managed_us_delay_flights_tbl")
创建外部表
可以将外部已有数据源作为外部表,支持 Parquet, CSV, or JSON 格式, 下边是使用 CSV 作为外部表的例子:
spark.sql("""CREATE TABLE us_delay_flights_tbl(date STRING, delay INT, distance INT, origin STRING, destination STRING) USING csv OPTIONS (PATH '/databricks-datasets/learning-spark-v2/flights/departuredelays.csv')""")
通过 API 创建:
(flights_df.write.option("path", "/tmp/data/us_flights_delay").saveAsTable("us_delay_flights_tbl"))
创建视图
视图是一个虚拟表,只包含查询结果,不会持久化数据。Spark 的视图分为临时视图和全局临时视图。
临时视图只能在当前 session 中查询,全局临时视图可以在全局 session 中生效。
创建全局临时视图
通过 SQL 创建
-- In SQL
CREATE OR REPLACE GLOBAL TEMP VIEW us_origin_airport_SFO_global_tmp_view ASSELECT date, delay, origin, destination from us_delay_flights_tbl WHERE origin = 'SFO';CREATE OR REPLACE TEMP VIEW us_origin_airport_JFK_tmp_view ASSELECT date, delay, origin, destination from us_delay_flights_tbl WHERE origin = 'JFK'
通过 API 创建
# In Python
df_sfo = spark.sql("SELECT date, delay, origin, destination FROM us_delay_flights_tbl WHERE origin = 'SFO'")
df_jfk = spark.sql("SELECT date, delay, origin, destination FROM us_delay_flights_tbl WHERE origin = 'JFK'")# Create a temporary and global temporary view
df_sfo.createOrReplaceGlobalTempView("us_origin_airport_SFO_global_tmp_view")
df_jfk.createOrReplaceTempView("us_origin_airport_JFK_tmp_view")
使用视图
创建完全局临时视图后,可以通过global_temp.<view_name>的方式访问视图:
-- In SQL
SELECT * FROM global_temp.us_origin_airport_SFO_global_tmp_view
// In Scala/Python
spark.read.table("us_origin_airport_JFK_tmp_view")
// Or
spark.sql("SELECT * FROM us_origin_airport_JFK_tmp_view")
删除视图
-- In SQL
DROP VIEW IF EXISTS us_origin_airport_SFO_global_tmp_view;
DROP VIEW IF EXISTS us_origin_airport_JFK_tmp_view
// In Scala/Python
spark.catalog.dropGlobalTempView("us_origin_airport_SFO_global_tmp_view")
spark.catalog.dropTempView("us_origin_airport_JFK_tmp_view")
查看元数据
在 Spark 中,元数据 Catalog 是一个用于管理和维护数据源、表、视图等元数据信息的组件。它允许用户查询、浏览和操作存储在 Spark 中的数据结构和元数据信息。元数据 Catalog 提供了一个统一的接口,使用户可以通过编程方式访问和操作元数据,而无需直接操作底层的数据存储。
Spark 提供了两种类型的元数据 Catalog:Hive 元数据 Catalog 和 In-Memory 元数据 Catalog。
Hive 元数据 Catalog
Hive 元数据 Catalog 是 Spark 的默认元数据存储和管理系统,它允许 Spark 与 Hive 集成,并使用 Hive 元数据存储和元数据服务。通过 Hive 元数据 Catalog,Spark 可以读取和写入 Hive 表、视图和分区,并执行 Hive 兼容的 SQL 查询。
In-Memory 元数据 Catalog
In-Memory 元数据 Catalog 是 Spark 2.0 引入的新特性,它是一个轻量级的元数据存储系统,将元数据信息存储在 Spark 的内存中,不依赖于外部的元数据存储系统。In-Memory 元数据 Catalog 支持创建、查询、删除临时视图、全局临时视图、数据源表等操作,但不支持持久化的表或分区。
查询元数据
// In Scala/Python
spark.catalog.listDatabases()
spark.catalog.listTables()
spark.catalog.listColumns("us_delay_flights_tbl")
表缓存
在 Spark 中,通过缓存表(Cache Table)可以将数据缓存在内存中,以提高查询性能。缓存表可以加快对数据的访问速度,减少重复计算,特别是当数据需要被频繁地查询或者被多次使用时。
在 Spark 中,可以通过以下方式将表缓存到内存中:
# 使用 SQL
spark.sql("CACHE TABLE table_name")
# 使用 API
df.cache()
这会将指定的表缓存到内存中,以供后续查询使用。
读取表数据
将外部表的数据读取生成 DataFrame。
// In Scala
val usFlightsDF = spark.sql("SELECT * FROM us_delay_flights_tbl")
val usFlightsDF2 = spark.table("us_delay_flights_tbl")
# In Python
us_flights_df = spark.sql("SELECT * FROM us_delay_flights_tbl")
us_flights_df2 = spark.table("us_delay_flights_tbl")
表和 DataFrame 的数据来源
DataFrameReader
使用方式如下:
DataFrameReader.format(args).option("key", "value").schema(args).load()
只能通过SparkSession实例访问DataFrameReader:
SparkSession.read
// or
SparkSession.readStream
read读取静态数据源,readStream读取动态数据源。
DataFrameReader API 的参数说明如下:
| 方法 | 参数 | 说明 |
|---|---|---|
| format() | "parquet", "csv", "txt", "json", "jdbc", "orc", "avro", 等 | 如果不指定此方法,则默认为Parquet或spark.sql.sources.default中设置的任何方法 |
| option() | (“mode”, {PERMISSIVE | FAILFAST | DROPMALFORMED } ) (“inferSchema”, {true | false}) (“path”, “path_file_data_source”) | 一系列键/值对和选项。 Spark文档展示了一些示例,并解释了不同的schema及其操作。默认schema 为“permit”。“interschema”和“mode”选项是特定于JSON和CSV文件格式的。 |
| schema() | DDL String or StructType, e.g., ‘A INT, B STRING’ or StructType(…) | 对于JSON或CSV格式,可以在option()方法中指定推断schema。通常,为任何格式提供schema都可以加快加载速度,并确保数据符合预期的schema。 |
| load() | “/path/to/data/source” | 数据源的路径。如果在option(“path”, “…”)中指定,则可以为空。 |
下边是一些使用案例:
// In Scala
// Use Parquet
val file = """/databricks-datasets/learning-spark-v2/flights/summary-data/parquet/2010-summary.parquet"""
val df = spark.read.format("parquet").load(file)
// Use Parquet; you can omit format("parquet") if you wish as it's the default
val df2 = spark.read.load(file)
// Use CSV
val df3 = spark.read.format("csv").option("inferSchema", "true").option("header", "true").option("mode", "PERMISSIVE").load("/databricks-datasets/learning-spark-v2/flights/summary-data/csv/*")
// Use JSON
val df4 = spark.read.format("json").load("/databricks-datasets/learning-spark-v2/flights/summary-data/json/*")
DataFrameWriter
DataFrameWriter 将数据保存或写入指定的内置数据源。
DataFrameWriter.format(args).option(args).bucketBy(args).partitionBy(args).save(path)DataFrameWriter.format(args).option(args).sortBy(args).saveAsTable(table)
方法和参数说明:
| 方法 | 参数 | 说明 |
|---|---|---|
| format() | “parquet”, “csv”, “txt”, “json”, “jdbc”, “orc”, “avro”, etc. | 如果不指定此方法,则默认为Parquet或spark.sql.sources.default中设置的任何方法。 |
| option() | (“mode”, {append | overwrite | ignore | error or errorifexists} ) (“mode”, {SaveMode.Overwrite | SaveMode.Append, SaveMode.Ignore, SaveMode.ErrorIfExists}) (“path”, “path_to_write_to”) | 一系列键/值对和选项。Spark文档展示了一些示例。这是一个重载方法。默认模式选项是error或errorifexists和SaveMode.ErrorIfExists;如果数据已经存在,它们会在运行时抛出异常。 |
| bucketBy() | (numBuckets, col, col…, coln) | 桶的数量和要桶的列的名称。在文件系统上使用Hive的bucket方案。 |
| save() | “/path/to/data/source” | 保存路径。如果在option(“path”, “…”)中指定,则可以为空 |
| saveAsTable() | “table_name” | 保存到的表。 |
使用案例:
// In Scala
// Use JSON
val location = ...
df.write.format("json").mode("overwrite").save(location)
Parquet
它是Spark中的默认数据源,建议在转换和清理数据之后,将dataframe保存为Parquet格式,以供下游使用。
读取 Parquet 文件生成 DataFrame
// In Scala
val file = """/databricks-datasets/learning-spark-v2/flights/summary-data/parquet/2010-summary.parquet/"""
val df = spark.read.format("parquet").load(file)
# In Python
file = """/databricks-datasets/learning-spark-v2/flights/summary-data/parquet/2010-summary.parquet/"""
df = spark.read.format("parquet").load(file)
读取 Parquet 文件创建表
-- In SQL
CREATE OR REPLACE TEMPORARY VIEW us_delay_flights_tblUSING parquetOPTIONS (path "/databricks-datasets/learning-spark-v2/flights/summary-data/parquet/2010-summary.parquet/" )
将 DataFrames 保存为 Parquet 文件
// In Scala
df.write.format("parquet")
.mode("overwrite")
.option("compression", "snappy")
.save("/tmp/data/parquet/df_parquet")
# In Python
(df.write.format("parquet").mode("overwrite").option("compression", "snappy").save("/tmp/data/parquet/df_parquet"))
Parquet是默认的文件格式, 即使不指定 format()方法,DataFrame仍将保存为Parquet文件。
将 DataFrames 保存为内部表
// In Scala
df.write
.mode("overwrite")
.saveAsTable("us_delay_flights_tbl")s
# In Python
(df.write.mode("overwrite").saveAsTable("us_delay_flights_tbl"))
JSON
读取 JSON 文件创建 DataFrame
// In Scala
val file = "/databricks-datasets/learning-spark-v2/flights/summary-data/json/*"
val df = spark.read.format("json").load(file)
# In Python
file = "/databricks-datasets/learning-spark-v2/flights/summary-data/json/*"
df = spark.read.format("json").load(file)
读取 JSON 文件创建表
-- In SQL
CREATE OR REPLACE TEMPORARY VIEW us_delay_flights_tblUSING jsonOPTIONS (path "/databricks-datasets/learning-spark-v2/flights/summary-data/json/*")
将 DataFrame 保存为 JSON 文件
// In Scala
df.write.format("json")
.mode("overwrite")
.option("compression", "snappy")
.save("/tmp/data/json/df_json")
# In Python
(df.write.format("json").mode("overwrite").option("compression", "snappy").save("/tmp/data/json/df_json"))
CSV
读取 CSV 文件创建 DataFrame
// In Scala
val file = "/databricks-datasets/learning-spark-v2/flights/summary-data/csv/*"
val schema = "DEST_COUNTRY_NAME STRING, ORIGIN_COUNTRY_NAME STRING, count INT"val df = spark.read.format("csv")
.schema(schema)
.option("header", "true")
.option("mode", "FAILFAST") // Exit if any errors
.option("nullValue", "") // Replace any null data with quotes
.load(file)
# In Python
file = "/databricks-datasets/learning-spark-v2/flights/summary-data/csv/*"
schema = "DEST_COUNTRY_NAME STRING, ORIGIN_COUNTRY_NAME STRING, count INT"
df = (spark.read.format("csv").option("header", "true").schema(schema).option("mode", "FAILFAST") # Exit if any errors.option("nullValue", "") # Replace any null data field with quotes.load(file))
读取 CSV 文件创建表
-- In SQL
CREATE OR REPLACE TEMPORARY VIEW us_delay_flights_tblUSING csvOPTIONS (path "/databricks-datasets/learning-spark-v2/flights/summary-data/csv/*",header "true",inferSchema "true",mode "FAILFAST")s
将 DataFrame 保存为 CSV 文件
// In Scala
df.write.format("csv").mode("overwrite").save("/tmp/data/csv/df_csv")
# In Python
df.write.format("csv").mode("overwrite").save("/tmp/data/csv/df_csv")
Avro
读取 Avro 文件生成 DataFrame
// In Scala
val df = spark.read.format("avro")
.load("/databricks-datasets/learning-spark-v2/flights/summary-data/avro/*")
df.show(false)
# In Python
df = (spark.read.format("avro").load("/databricks-datasets/learning-spark-v2/flights/summary-data/avro/*"))
df.show(truncate=False)+-----------------+-------------------+-----+
|DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count|
+-----------------+-------------------+-----+
|United States |Romania |1 |
|United States |Ireland |264 |
|United States |India |69 |
|Egypt |United States |24 ||Equatorial Guinea|United States |1 ||United States |Singapore |25 ||United States |Grenada |54 ||Costa Rica |United States |477 ||Senegal |United States |29 ||United States |Marshall Islands |44 |+-----------------+-------------------+-----+only showing top 10 rows
读取 Avro 文件创建表
-- In SQL
CREATE OR REPLACE TEMPORARY VIEW episode_tblUSING avroOPTIONS (path "/databricks-datasets/learning-spark-v2/flights/summary-data/avro/*")
保存 DataFrame 为 Avro 文件
// In Scala
df.write
.format("avro")
.mode("overwrite")
.save("/tmp/data/avro/df_avro")
# In Python
(df.write.format("avro").mode("overwrite").save("/tmp/data/avro/df_avro"))
ORC
读取 ORC 文件生成 DataFrame
// In Scala
val file = "/databricks-datasets/learning-spark-v2/flights/summary-data/orc/*"
val df = spark.read.format("orc").load(file)
df.show(10, false)
# In Python
file = "/databricks-datasets/learning-spark-v2/flights/summary-data/orc/*"
df = spark.read.format("orc").option("path", file).load()
df.show(10, False)
读取 ORC 文件创建表
-- In SQL
CREATE OR REPLACE TEMPORARY VIEW us_delay_flights_tblUSING orcOPTIONS (path "/databricks-datasets/learning-spark-v2/flights/summary-data/orc/*")
保存 DataFrame 为 ORC 文件
// In Scala
df.write.format("orc")
.mode("overwrite")
.option("compression", "snappy")
.save("/tmp/data/orc/df_orc")
# In Python
(df.write.format("orc").mode("overwrite").option("compression", "snappy").save("/tmp/data/orc/flights_orc"))
Images
读取图片生成 DataFrame
// In Scala
import org.apache.spark.ml.source.imageval imageDir = "/databricks-datasets/learning-spark-v2/cctvVideos/train_images/"
val imagesDF = spark.read.format("image").load(imageDir)imagesDF.printSchemaimagesDF.select("image.height", "image.width", "image.nChannels", "image.mode", "label").show(5, false)
# In Python
from pyspark.ml import imageimage_dir = "/databricks-datasets/learning-spark-v2/cctvVideos/train_images/"
images_df = spark.read.format("image").load(image_dir)
images_df.printSchema()root|-- image: struct (nullable = true)| |-- origin: string (nullable = true)| |-- height: integer (nullable = true)| |-- width: integer (nullable = true)| |-- nChannels: integer (nullable = true)| |-- mode: integer (nullable = true)| |-- data: binary (nullable = true)|-- label: integer (nullable = true)images_df.select("image.height", "image.width", "image.nChannels", "image.mode", "label").show(5, truncate=False)+------+-----+---------+----+-----+
|height|width|nChannels|mode|label|
+------+-----+---------+----+-----+
|288 |384 |3 |16 |0 |
|288 |384 |3 |16 |1 |
|288 |384 |3 |16 |0 |
|288 |384 |3 |16 |0 |
|288 |384 |3 |16 |0 |
+------+-----+---------+----+-----+
only showing top 5 rows
Binary Files
读取二进制文件生成 DataFrame
// In Scala
val path = "/databricks-datasets/learning-spark-v2/cctvVideos/train_images/"
val binaryFilesDF = spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.load(path)
binaryFilesDF.show(5)
# In Python
path = "/databricks-datasets/learning-spark-v2/cctvVideos/train_images/"
binary_files_df = (spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load(path))
binary_files_df.show(5)+--------------------+-------------------+------+--------------------+-----+
| path| modificationTime|length| content|label|
+--------------------+-------------------+------+--------------------+-----+
|file:/Users/jules...|2020-02-12 12:04:24| 55037|[FF D8 FF E0 00 1...| 0|
|file:/Users/jules...|2020-02-12 12:04:24| 54634|[FF D8 FF E0 00 1...| 1|
|file:/Users/jules...|2020-02-12 12:04:24| 54624|[FF D8 FF E0 00 1...| 0|
|file:/Users/jules...|2020-02-12 12:04:24| 54505|[FF D8 FF E0 00 1...| 0|
|file:/Users/jules...|2020-02-12 12:04:24| 54475|[FF D8 FF E0 00 1...| 0|
+--------------------+-------------------+------+--------------------+-----+
only showing top 5 rows
通过设置 recursiveFileLookup为 true, 可以不指定文件路劲递归读取文件:
// In Scala
val binaryFilesDF = spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load(path)
binaryFilesDF.show(5)
总结
探本文主要总结了 DataFrame API和Spark SQL之间的交互,并且总结了我们能够通过 Spark SQL 做什么:
- 使用Spark SQL和DataFrame API创建内部表和外部表。
- 读取和写入各种内置数据源和文件格式。
- 通过
spark.sql接口对存储为Spark sql表或视图的结构化数据进行 sql 查询。 - 通过
Catalog查询表和视图的元信息。 - 使用
DataFrameWriter和DataFrameReaderAPI。