1. 单链表的概念和结构
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表 中的指针链接次序实现的 。
链表与顺序表都属于线性表,顺序表在物理存储结构上是线性的,但是链表在物理存储结构上却是非线性的,它是由一个个的结点所构成。
一个个结点通过地址链接在一起,所以这种逻辑上的线性存储结构就叫做链表。
准确来说,结点之间只有逻辑上的关系,链表只是假想出来的对这些相互之间有联系的结点的统称。
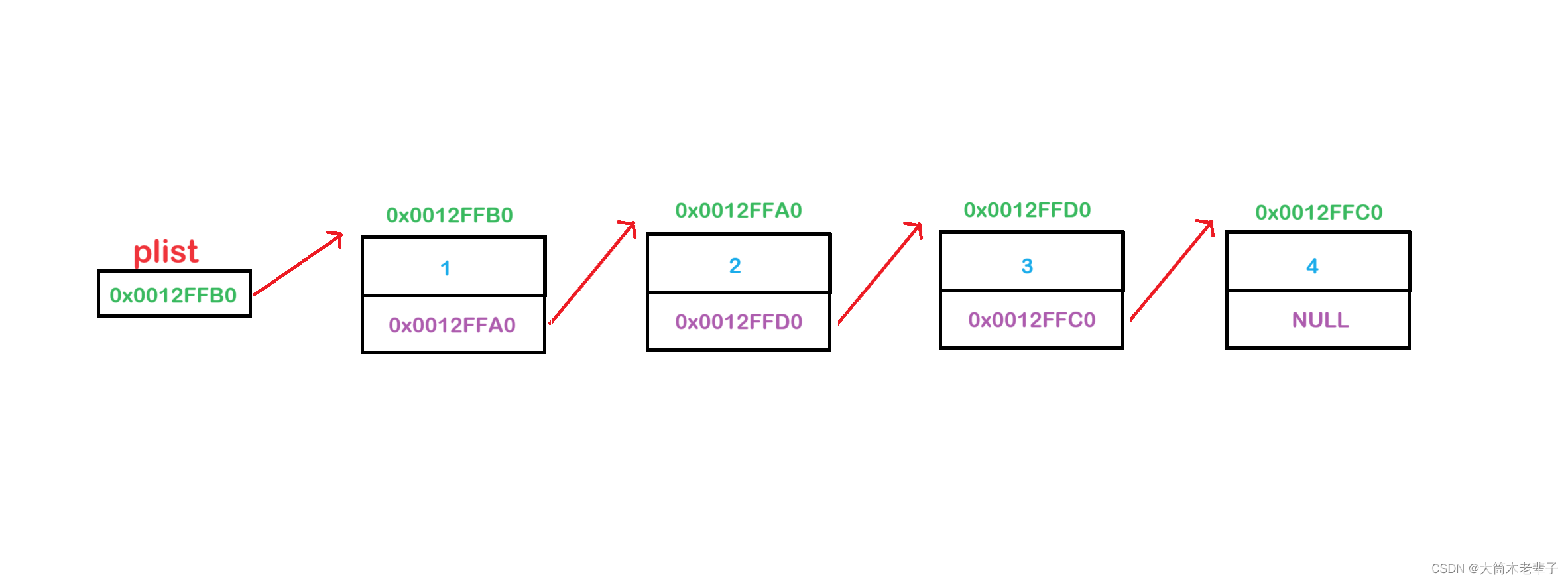
单链表的“单”意味着每个结点除了存储自己的要存储的数据之外,就只存储了另外一个结点的地址(其逻辑上,下一个结点的地址)。
每个结点并没有自己的名字或直接被查找到的方式,他们只能被上一个元素存储的指针所找到。
其结构体定义如下:
typedef int SLTDataType;//要存储的数据的类型,此处是inttypedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;其中,data表示要存的数据,next是指向下一个结点的指针。
在之后的学习中,我们还会遇到双向链表,循环链表,十字链表等。
稀疏矩阵的链式存储结构:十字链表-CSDN博客
既然这些结点在逻辑上被视作一个整体,那么要如何表示这个整体呢?
由于每个结点中存储了下一个结点的地址,所以我们只要找到第一个结点,就可以找到之后所有被链接起来的结点。
由于这些结点并没有自己的名字,所以我们会单独定义一个头结点指针plist来指向第一个结点。
这样,通过plist我们就可以遍历整个链表,通常就将plist当作链表这个整体。
这个其实不难理解,类比数组即可:
数组名既是首元素地址,又代表了整个数组;plist既是首元素地址,又代表了整个链表。
2. 对单链表进行操作用到的函数声明
//打印
void SLTPrint(SLTNode* phead);
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//尾删
void SLTPopBack(SLTNode** pphead);
//头删
void SLTPopFront(SLTNode** pphead);
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//指定位置之前插入
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//指定位置之后插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//删除pos位置节点
void SLTErase(SLTNode** pphead, SLTNode* pos);
//删除pos之后的节点
void SLTEraseAfter(SLTNode* pos);
//销毁链表
void SListDesTroy(SLTNode** pphead);其中,打印链表的函数需要根据具体情况来实现,打印完一个结点的数据再打印下一个,直到某个元素的next指针为NULL为止,本文对这个函数不做过多解释。
由于每个插入函数在插入结点时都需要申请一个新的结点来插入,所以除了上面这些函数,我们在实现链表的文件中还会额外定义一个函数来进行结点的申请:
//创建新结点
SLTNode* SLTBuyNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc fail!");exit(1);}newnode->data = x;newnode->next = NULL;return newnode;
}3. 插入函数
3.1 尾插
申请新结点,找到链表中的尾结点,使尾结点的next指针指向新的结点即可。
注意,当我们的头结点指针为NULL时(链表中没有元素),我们需要让头结点指向新申请的结点,此时需要修改头结点指针的值。
所以,我们在传入数据时,传入的是头结点指针的地址。
在函数中,要修改实参的值就需要传入实参的地址。
我们要修改头结点指针的值就要传入头结点指针的地址,即一个二级指针。
接下来的,传入了二级指针的函数也是由于在某些情况下需要更改头结点指针的值。
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);if (*pphead == NULL){*pphead = newnode;}else{SLTNode* ptail = *pphead;while (ptail->next != NULL){ptail = ptail->next;}ptail->next = newnode;}
}3.2 头插
申请新的结点,然后将链表原本的头结点链接在新结点之后,再让头结点指针指向新结点即可。
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);newnode->next = *pphead;*pphead = newnode;
}3.3 在指定位置之前插入
在指定位置之前插入,需要使该位置之前原本的结点的next指针指向新结点,再让新结点的next指针指向该位置的结点。
由于在单链表中,我们只能查找到某个结点的下一个结点,所以,在某个结点之前插入就需要遍历链表,来找到该位置之前的那个结点。
这也是单链表的一个缺陷。
在某个位置前插入,那么链表中一定要有结点才能插入,所以pphead和*pphead都不能为NULL。
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead && *pphead);assert(pos);if (pos == *pphead){SLTPushFront(pphead, x);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}SLTNode* newnode = SLTBuyNode(x);newnode->data = x;newnode->next = prev->next;prev->next = newnode;}
}3.4 在指定位置之后插入
先让该位置的下一个结点接在新结点之后,再让新结点接在该位置之后。
注意,这两步次序不能交换,如果先进行第二步,则不能通过该位置结点的next指针找到原本的下一个结点。
//指定位置之后插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = SLTBuyNode(x);newnode->next = pos->next;pos->next = newnode;
}4. 删除函数
4.1 尾删
找到尾结点,再将其释放即可,当然,在释放掉尾结点之后,需要将前一个结点的next指针置为NULL。
但我们无法通过尾结点来找到前一个结点,所以每次让ptail指针指向下一个结点之前,可以另外设置一个prev指针来记录下当前的结点。
也可以采取如下的写法,直接找尾结点的前一个结点。
当链表中只有一个结点时,上述的两种写法都会导致解引用NULL的错误,所以我们需要单独处理一下这种情况。
//尾删
void SLTPopBack(SLTNode** pphead)
{assert(pphead && *pphead);if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{SLTNode* ptail = *pphead;while (ptail->next->next != NULL){ptail = ptail->next;}free(ptail->next);ptail->next = NULL;}
}4.2 头删
释放掉头结点,然后让头结点指针指向第二个结点即可。
但是,释放掉头结点会导致我找不到第二个结点,所以我们定义了一个newphead指针来指向第二个结点。
//头删
void SLTPopFront(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* newphead = (*pphead)->next;free(*pphead);*pphead = newphead;
}4.3 删除指定位置的结点
与尾删类似,只不过要找的是某个指定的结点而不是尾结点,同样需要遍历链表。
//删除指定位置节点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead && *pphead);assert(pos);if (pos == *pphead){SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);}
}4.4 删除指定位置之后的结点
释放掉该位置之后的结点,然后将之后剩余的结点接到该位置之后即可。
要注意的与头删类似。
//删除指定位置之后的节点
void SLTEraseAfter(SLTNode* pos)
{assert(pos && pos->next);SLTNode* del = pos->next;pos->next = del->next;free(del);del = NULL;
}5. 查找结点
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{assert(phead);SLTNode* pcur = phead;while (pcur){if (pcur->data == x)return pcur;pcur = pcur->next;}return NULL;
}6. 销毁单链表
依次删除每个结点即可。
//销毁链表
void SListDesTroy(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}7. 结语
单链表相对于顺序表来说,优势有:
1. 对数据进行增加删除较为方便,因为我只需要改变结点之间的链接关系即可。
2. 不会浪费空间,有需要我才会开辟新的结点(尽管每个结点都是结构体,所占空间比数组元素多)。
劣势:
1. 查找不便,只能一个一个地通过next指针来查找,且无法访问某结点的前一个结点。而顺序表则可通过下标访问操作符来对数据进行直接访问。

![[从0开始AIGC][Transformer相关]:算法的时间和空间复杂度](https://img-blog.csdnimg.cn/img_convert/28f9da9b3e171eaf456b2974d0ff1a6f.webp?x-oss-process=image/format,png)