一、原始消费数据buy.txt
zhangsan 5676 2765 887
lisi 6754 3234 1232
wangwu 3214 6654 388
lisi 1123 4534 2121
zhangsan 982 3421 5566
zhangsan 1219 36 45
二、实现思路:先通过一个MapReduce将顾客的消费金额进行汇总,再通过一个MapReduce来根据金额进行排序
三、定义一个实体类(其中compareTo方法实现了排序规则):
package cn.edu.tju;import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class Buy implements WritableComparable<Buy> {private double jingdong;private double taobao;private double duodian;public Buy() {}public Buy(double jingdong, double taobao, double duodian) {this.jingdong = jingdong;this.taobao = taobao;this.duodian = duodian;}public double getJingdong() {return jingdong;}public void setJingdong(double jingdong) {this.jingdong = jingdong;}public double getTaobao() {return taobao;}public void setTaobao(double taobao) {this.taobao = taobao;}public double getDuodian() {return duodian;}public void setDuodian(double duodian) {this.duodian = duodian;}@Overridepublic String toString() {return "" +"" + jingdong +"\t" + taobao +"\t" + duodian;}@Overridepublic void write(DataOutput out) throws IOException {out.writeDouble(jingdong);out.writeDouble(taobao);out.writeDouble(duodian);}@Overridepublic void readFields(DataInput in) throws IOException {this.jingdong =in.readDouble();this.taobao = in.readDouble();this.duodian = in.readDouble();}@Overridepublic int compareTo(Buy o) {if(this.jingdong>o.getJingdong()){return 1;} else if(this.getJingdong()< o.getJingdong()){return -1;} else {if(this.getTaobao()>o.getTaobao()){return 1;}else if(this.getTaobao()< o.getTaobao()){return -1;} else return 0;}}
}四、定义第一对Mapper和Reducer
package cn.edu.tju;import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class MyBuyMapper1 extends Mapper<LongWritable, Text, Text, Buy> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String str = value.toString();String[] fieldList = str.split(" ");double jingdong = Double.parseDouble(fieldList[1]);double taobao = Double.parseDouble(fieldList[2]);double duodian = Double.parseDouble(fieldList[3]);String person = fieldList[0];context.write(new Text(person), new Buy(jingdong,taobao,duodian));}
}package cn.edu.tju;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.util.Iterator;public class MyBuyReducer1 extends Reducer<Text, Buy, Text, Buy> {@Overrideprotected void reduce(Text key, Iterable<Buy> values, Reducer<Text, Buy, Text, Buy>.Context context) throws IOException, InterruptedException {double sum1 = 0;double sum2 = 0;double sum3 = 0;Iterator<Buy> iterator = values.iterator();while (iterator.hasNext()) {Buy next = iterator.next();sum1 += next.getJingdong();sum2 += next.getTaobao();sum3 += next.getDuodian();}context.write(key, new Buy(sum1, sum2, sum3));}
}五、定义第二对Mapper和Reducer
package cn.edu.tju;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class MyBuyMapper2 extends Mapper<LongWritable, Text, Buy, Text> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String str = value.toString();String[] fieldList = str.split("\t");double jingdong = Double.parseDouble(fieldList[1]);double taobao = Double.parseDouble(fieldList[2]);double duodian = Double.parseDouble(fieldList[3]);String person = fieldList[0];context.write(new Buy(jingdong,taobao,duodian), new Text(person));}
}package cn.edu.tju;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.util.Iterator;public class MyBuyReducer2 extends Reducer<Buy, Text, Text, Buy> {@Overrideprotected void reduce(Buy key, Iterable<Text> values, Context context) throws IOException, InterruptedException {Iterator<Text> iterator = values.iterator();while(iterator.hasNext()){Text next = iterator.next();context.write(next, key);}}
}六、定义主类,其中定义两个Job,等第一个job运行结束之后第二Job开始运行
package cn.edu.tju;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class MyBuyMain2 {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration(true);configuration.set("mapreduce.framework.name", "local");Job job = Job.getInstance(configuration);//job.setJarByClass(MyBuyMain.class);//job namejob.setJobName("buy-" + System.currentTimeMillis());//设置Reducer数量//job.setNumReduceTasks(3);//输入数据路径FileInputFormat.setInputPaths(job, new Path("D:\\tool\\TestHadoop3\\buy.txt"));//输出数据路径,当前必须不存在FileOutputFormat.setOutputPath(job, new Path("count_1" ));job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Buy.class);job.setMapperClass(MyBuyMapper1.class);job.setReducerClass(MyBuyReducer1.class);//等待任务执行完成job.waitForCompletion(true);Job job2 = Job.getInstance(configuration);job2.setJarByClass(MyBuyMain2.class);job2.setJobName("buy2-" + System.currentTimeMillis());FileInputFormat.setInputPaths(job2, new Path("D:\\tool\\TestHadoop3\\count_1\\part-r-00000"));//输出数据路径,当前必须不存在FileOutputFormat.setOutputPath(job2, new Path("count_2" ));job2.setMapOutputKeyClass(Buy.class);job2.setMapOutputValueClass(Text.class);job2.setMapperClass(MyBuyMapper2.class);job2.setReducerClass(MyBuyReducer2.class);//等待任务执行完成job2.waitForCompletion(true);}
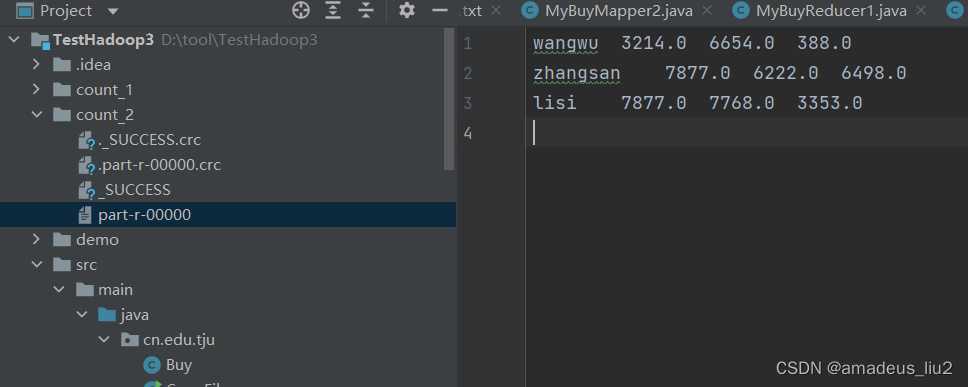
}七、运行结果:



![BUUCTF:BUU UPLOAD COURSE 1[WriteUP]](https://img-blog.csdnimg.cn/direct/22970d30ac8645f38d61cdfec8d396c8.png)