原论文:The Hadoop Distributed File System (MSST’10)
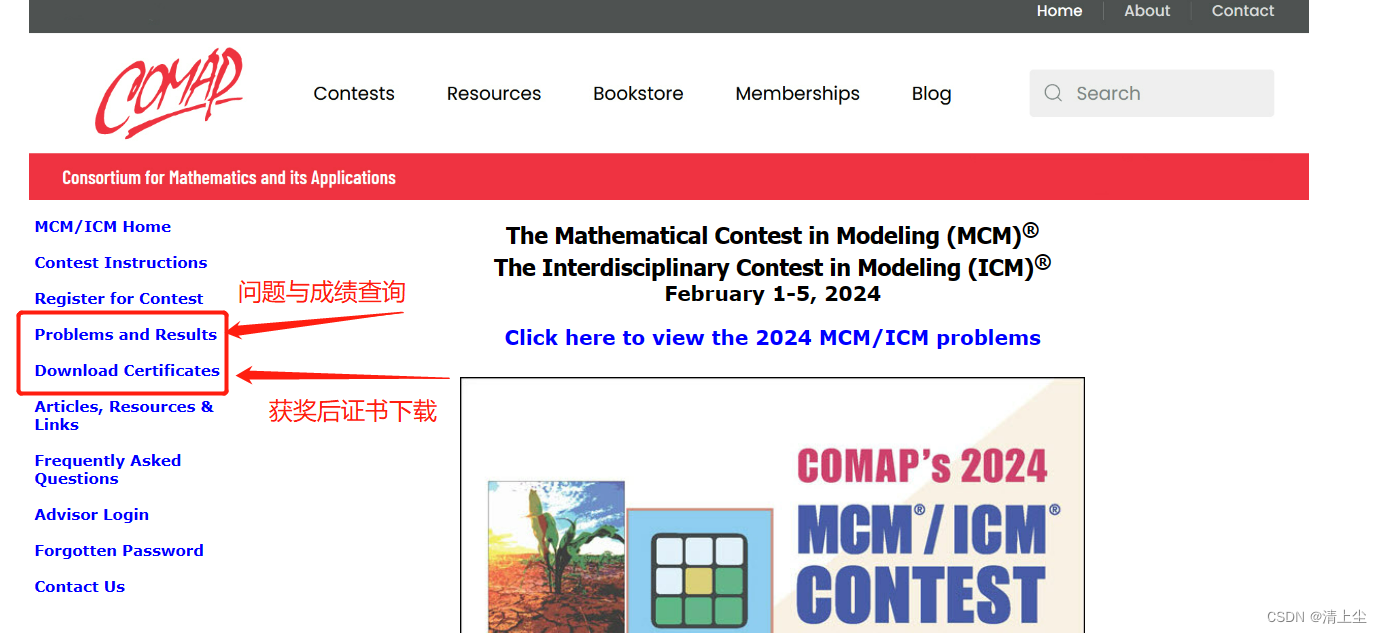
HDFS关键技术要点概览
- 设计目标:HDFS旨在可靠地存储大型数据集,并以高带宽流式传输这些数据集到用户应用程序。它通过在大量服务器上分布存储和计算资源,使得资源可以随着需求的增长而扩展,同时保持经济高效。
- 架构组成:HDFS是Hadoop项目的一部分,包括了分布式文件系统、MapReduce计算框架、HBase列式存储系统、Pig数据流语言、Hive数据仓库基础设施、ZooKeeper分布式协调服务等多个组件。
- 存储和元数据分离:HDFS将文件系统元数据和应用数据分开存储。元数据存储在专用的NameNode服务器上,而应用数据存储在DataNode服务器上。
- 数据复制:HDFS不像传统的文件系统使用RAID等数据保护机制,而是通过在多个DataNode上复制文件内容来确保数据的可靠性。这种策略不仅保证了数据的持久性,还提高了数据传输带宽,并为计算任务提供了更多的机会来靠近所需数据。
- NameNode和DataNode:NameNode维护文件系统的namespace tree和block到DataNode的映射关系。DataNode则存储实际的数据块,并与NameNode通信以报告其健康状况和存储状态。
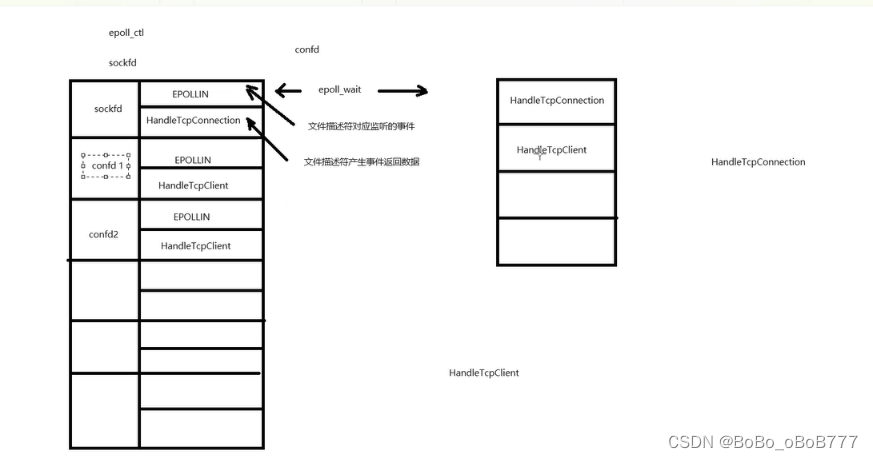
- 客户端操作:HDFS客户端提供了一系列文件系统操作,如读写文件、创建和删除目录等。客户端与NameNode交互以获取文件块的位置信息,然后直接与DataNode通信来读取或写入数据。
- 容错和数据完整性:HDFS通过复制数据块来提高容错能力。如果检测到数据块损坏,HDFS会从其他DataNode获取有效副本。此外,HDFS还提供了块扫描器来定期检查数据块的完整性。
- 平衡器(Balancer):为了确保集群中数据的均匀分布,HDFS提供了一个平衡器工具,它可以将数据从一个DataNode复制到另一个DataNode,以平衡集群中的磁盘空间使用。
- 升级和快照:HDFS支持在软件升级期间创建文件系统快照,以便在升级导致数据损坏时可以回滚到升级前的状态。
- 性能基准测试:论文提供了HDFS在不同操作(如读取、写入、追加)下的性能基准测试结果,以及在生产环境中的实际性能表现。
- 未来工作:论文讨论了HDFS未来的发展方向,包括提高NameNode的可扩展性、实现自动化故障转移、支持多个namespace以及改进集群间的协作。
HDFS原论文阅读
Introduction
-
Hadoop提供了一个分布式文件系统和一个基于MapReduce实现的对超大数据集的分析和转换的框架。
-
Hadoop的重要特点:数据的分割、横跨成千上万个主机的计算、在接近数据的地方并行执行应用程序的计算。
-
Hadoop集群通过简单地增加服务器来扩展计算容量、存储容量和IO带宽。
-
Hadoop 项目的组成元件
-
Hadoop将元数据存储在NameNode上,将应用程序数据存储在DataNode上,所有服务器通过TCP-based协议连接和通信。
-
和GFS类似,Hadoop通过存储多个副本在DataNodes上来实现数据的可靠性。
-
一个文件通过一个哈希函数将名称映射到特定的MDS(namespace服务器)。

Architecture
NameNodes
- HDFS namespace是一个文件和目录的层级结构。在NameNode中,文件和目录是通过inodes来呈现的,内容包括属性值(如允许的权限)、修改和访问时间、namespace和磁盘空间配额等。
- 文件内容被分割成(默认为128MB大小的)块,然后每个块独立地在其他DataNodes上有多个副本(一般为三副本)。
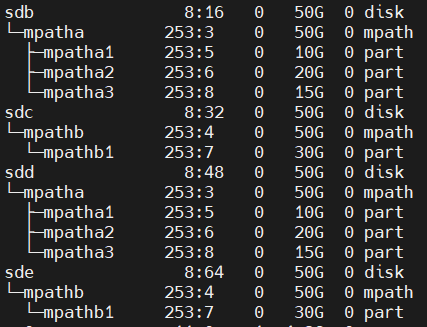
- Namenode保存着namespace tree以及blocks到DataNode的映射表(文件数据的物理位置)。
- 想要读取文件的 HDFS clients首先会联系 NameNode 以获取组成文件的数据块位置,然后从最靠近client的 DataNode 读取块内容。在写入数据时,clients会要求 NameNode 指定由三个DataNodes来管理数据块副本。然后,clients以流水线方式向DataNodes写入数据。
- HDFS将整个namespace存储在RAM中。命名系统元数据image由inode的数据和属于每个文件的block list组成,存储在本地主机本地文件系统中的image持久记录称为checkpoint,NameNode 还会在本地主机的本地文件系统中存储名为jo