·请参考本系列目录:【mT5多语言翻译】之一——实战项目总览
[1] 模型训练与验证
在上一篇实战博客中,我们讲解了访问数据集中每个batch数据的方法。接下来我们介绍如何训练mT5模型进行多语言翻译微调。
首先加载模型,并把模型设置为训练状态,然后定义优化器、学习率衰减,并设置一些初始状态值。
model = AutoModelForSeq2SeqLM.from_pretrained(conf.pretrained_path)
model.train()optimizer = AdamW(model.parameters(), lr=config.learning_rate)
# 学习率指数衰减,每次epoch:学习率 = gamma * 学习率
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=len(train_iter) * config.num_epochs)
total_batch = 0 # 记录进行到多少batch
losses = []
【注】设置了
model.train()后,会激活dropout。而设置model.eval()后,会关闭dropout,防止影响模型的推理结果。
接着,我们就可以访问数据加载器中的数据进行模型的微调了:
for epoch in range(config.num_epochs):for i, (input_batch, label_batch) in enumerate(train_iter):optimizer.zero_grad()model_out = model.forward(input_ids=input_batch, labels=label_batch)loss = model_out.losslosses.append(loss.item())loss.backward()optimizer.step()scheduler.step()# 打印步if (total_batch + 1) % config.print_step == 0:avg_loss = np.mean(losses[-config.print_step:])logger.info('Epoch: {} | Step: {} | Train Avg. loss: {:.3f} | lr: {} | Time: {}'.format(epoch + 1,total_batch + 1, avg_loss, scheduler.get_last_lr()[0], get_time_dif(start_time)))# 验证步if (total_batch + 1) % config.checkpoint_step == 0:test_loss = evaluate(model, dev_iter)torch.save(model.state_dict(), config.save_path)time_dif = get_time_dif(start_time)logger.info('Test Avg. loss: {:.3f} | Time: {} '.format(test_loss, time_dif))model.train()total_batch += 1torch.save(model.state_dict(), config.save_path)
如上,训练的代码还是很少的,里面有一些注意事项需要详细说明。
1、由于我们不是每一个batch都要输出一下损失到控制台。所有我们需要设置打印步,来控制每隔多少个batch输出一次模型的loss。因此需要一个数组将每次的训练损失记录下来,然后打印时求下平均值。
2、同理,在验证集上测试性能也是这个道理。但是由于我们的数据集很大,即使模型在验证集上的loss不再下降,也不应该主动把模型停止。因为大模型的训练可以抽象为“压缩数据”的概念,它没见过的数据就是不会产生相应的知识,所以最好还是让模型一直训练下去,直到把数据集训练完。
模型的验证代码属于训练的阉割版,比较简单,如下:
def evaluate(model, data_iter):model.eval()eval_losses = []with torch.no_grad():for input_batch, label_batch in data_iter:model_out = model.forward(input_ids=input_batch, labels=label_batch)eval_losses.append(model_out.loss.item())return np.mean(eval_losses)
[2] 中央日志
由于模型训练的时间较长,一旦断联可能就无法再继续观测模型在控制台打印的输出。因此,我们需要设计一个日志功能,让模型即可以实时的打印输出,又能同时记录输出到文件中,以便于我们后期查看。
还有一个待解决的问题是,项目中不同文件的输出日志,我们需要将其定位到同一个log日志中。
所以需要在项目中配置根日志器。配置代码如下:
import logging.config# 定义日志配置
LOGGING_CONFIG = {'version': 1,'formatters': {'default': {'format': '%(asctime)s - %(name)s - %(levelname)s - %(message)s',},},'handlers': {'console': {'class': 'logging.StreamHandler', # 输出到控制台'level': 'INFO','formatter': 'default',},'file': {'class': 'logging.FileHandler', # 输出到文件'filename': 'train.log','level': 'DEBUG','formatter': 'default',},},'loggers': {'': { # root logger'handlers': ['console', 'file'],'level': 'DEBUG',},},
}# 在根日志器(没有名称的日志器)上应用日志配置,那么所有子日志器都会继承这些设置
logging.config.dictConfig(LOGGING_CONFIG)
# 获取日志器
logger = logging.getLogger(__name__)
我们在项目的任意一个py文件中写下这样的配置。然后在其他py文件中只需要2行代码即可让输出流即展示在控制台也能保存在同一个log日志文件中:
# 获取日志器
logger = logging.getLogger(__name__)
# 记录日志
logger.info("xxxxxx")
[3] 训练可视化
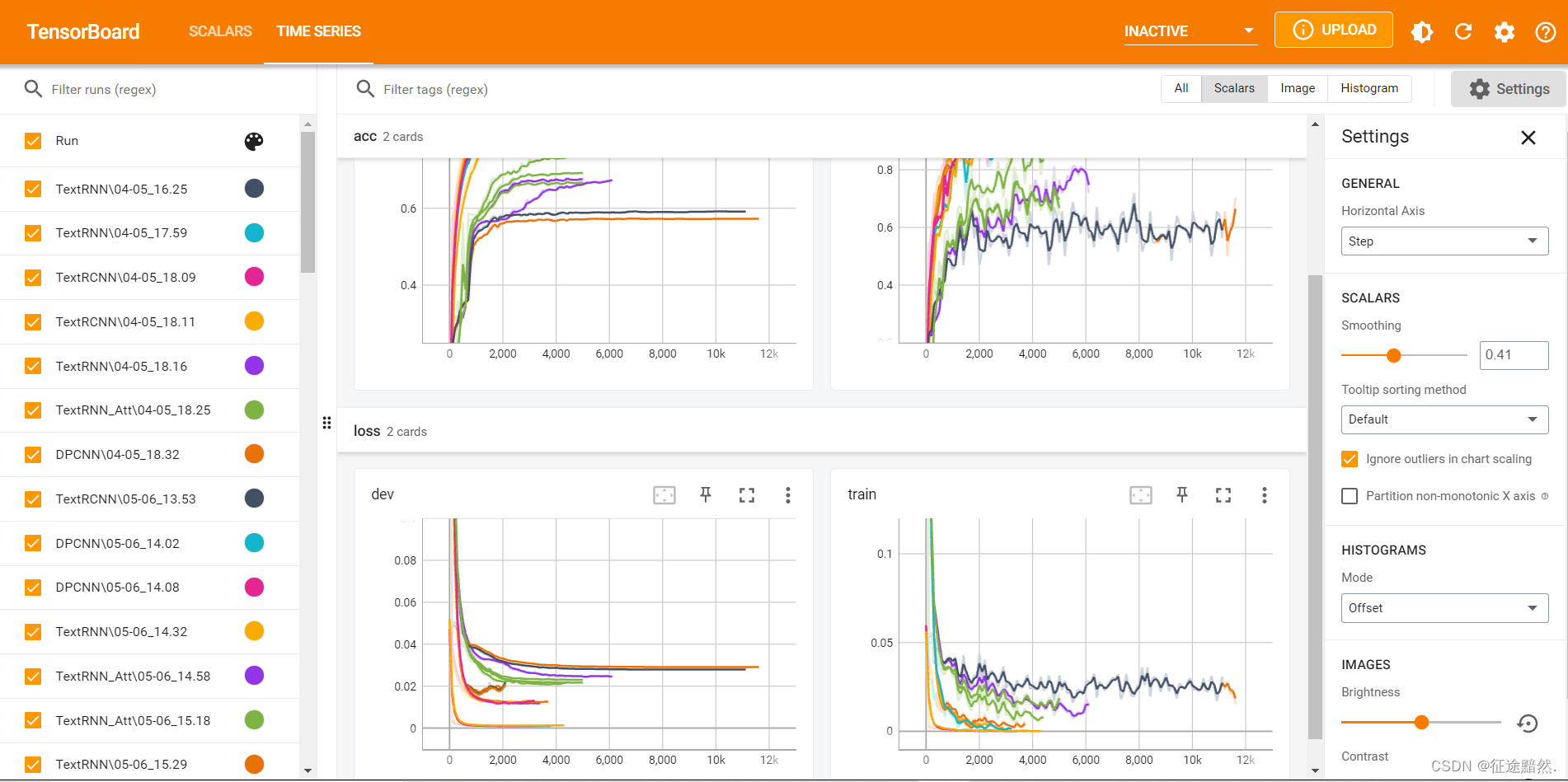
我们在训练过程中,会有实时观测损失波动、评价指标波动的需求。因此项目集成了tensorBoardX来进行训练可视化。
先上效果图:
首先安装tensorboard,输入命令:
pip install tensorboard
然后在代码中使用write即可,代码demo:
import numpy as np
from torch.utils.tensorboard import SummaryWriter # 也可以使用 tensorboardX
# from tensorboardX import SummaryWriter # 也可以使用 pytorch 集成的 tensorboardwriter = SummaryWriter('log') # 配置生成的数据保存的地址
for epoch in range(100):writer.add_scalar('test/squared', np.square(epoch), epoch)writer.close()
执行上述代码后在本文件更目录下生成一个logs文件,且包含了一个事件文件。
在pycharm中terminal终端输入:
tensorboard --logdir=logs
一定要注意起初配置的生成文件保存地址,你在terminal终端中命令的地址要能够访问的到!!!
输入命令后,会生成一个地址,访问即可。

在本实战项目的实际训练中,通过is_write变量来控制是否要进行训练可视化,因此实际的代码如下:
model.train()...if config.is_write:writer = SummaryWriter(log_dir="{0}/{1}".format(config.tb_log_path, time.strftime('%m-%d_%H.%M', time.localtime())))for epoch in range(config.num_epochs):for i, (input_batch, label_batch) in enumerate(train_iter):...# 验证步...if config.is_write:writer.add_scalar('loss/train', loss.item(), total_batch)...if config.is_write:writer.close()
上述的代码判断is_write变量如果为True,那么会创建一个writer对象,并且每个batch都会记录训练loss。
[4] PEFT微调
PEFT微调可能是大家最需要的方法。
官方已经提供了peft库,直接安装即可:
pip install peft
不过在使用之前,我们需要明确2点:1)使用PEFT如何修改模型结构?2)使用PEFT如何保存模型?
其实非常简单!
使用PEFT如何修改模型结构?
常规加载模型的代码为:
model = AutoModelForSeq2SeqLM.from_pretrained(conf.pretrained_path)
使用PEFT方法修改加载模型后的代码为:
from peft import get_peft_model, LoraConfigmodel = AutoModelForSeq2SeqLM.from_pretrained(conf.pretrained_path)
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
model = get_peft_model(model, peft_config)
【注】朋友们,没看错!使用PEFT只需要在原来的基础上加两行代码即可,其他模型训练阶段的代码完全不需要改变。我这里演示的是使用LoRA进行微调,peft里目前还集成了Prefix Tuning等其他方法。
使用PEFT如何保存模型?
我们知道,使用PEFT微调模型是不会修改大模型本身的参数的,因此我们保存只要保存PEFT方法添加的那部分参数即可,PEFT模型保存方法如下:
model.save_pretrained(config.peft_save)
而传统保存全量参数的代码如下:
torch.save(model.state_dict(), config.save_path)
【注】peft使用起来真的太方便了。
[5] 集成了所有以上功能的模型训练与验证代码
# 获取日志器
logger = logging.getLogger(__name__)def train(config, model, train_iter, dev_iter):start_time = time.time()model.train()optimizer = AdamW(model.parameters(), lr=config.learning_rate)# 学习率指数衰减,每次epoch:学习率 = gamma * 学习率scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0,num_training_steps=len(train_iter) * config.num_epochs)total_batch = 0 # 记录进行到多少batchlosses = []if config.is_write:writer = SummaryWriter(log_dir="{0}/{1}".format(config.tb_log_path, time.strftime('%m-%d_%H.%M', time.localtime())))for epoch in range(config.num_epochs):for i, (input_batch, label_batch) in enumerate(train_iter):optimizer.zero_grad()model_out = model.forward(input_ids=input_batch, labels=label_batch)loss = model_out.losslosses.append(loss.item())loss.backward()optimizer.step()scheduler.step()# 打印步if (total_batch + 1) % config.print_step == 0:avg_loss = np.mean(losses[-config.print_step:])logger.info('Epoch: {} | Step: {} | Train Avg. loss: {:.3f} | lr: {} | Time: {}'.format(epoch + 1,total_batch + 1, avg_loss, scheduler.get_last_lr()[0], get_time_dif(start_time)))# 验证步if (total_batch + 1) % config.checkpoint_step == 0:test_loss = evaluate(model, dev_iter)if config.is_peft:model.save_pretrained(config.peft_save)else:torch.save(model.state_dict(), config.save_path)time_dif = get_time_dif(start_time)logger.info('Test Avg. loss: {:.3f} | Time: {} '.format(test_loss, time_dif))if config.is_write:writer.add_scalar('loss/train', loss.item(), total_batch)model.train()total_batch += 1if config.is_peft:model.save_pretrained(config.peft_save)else:torch.save(model.state_dict(), config.save_path)if config.is_write:writer.close()def evaluate(model, data_iter):model.eval()eval_losses = []with torch.no_grad():for input_batch, label_batch in data_iter:model_out = model.forward(input_ids=input_batch, labels=label_batch)eval_losses.append(model_out.loss.item())return np.mean(eval_losses)
[6] 进行下一篇实战
【mT5多语言翻译】之六——推理:多语言翻译与第三方接口设计