4月7日,纽约时报在官网发布了一篇名为《科技巨头如何挖空心思,为AI收集数据》的技术文章。
纽约时报表示,OpenAI曾在2021年几乎消耗尽了互联网有用的文本数据源。为了缓解训练数据短缺的难题,便开发了知名开源语音识别模型Whisper。
随后在OpenAI副总裁Greg Brockman的带领下,从视频平台YT、有声播客/读物等转录了超过100万小时的视频数据,然后转化成文本数据用于训练GPT-4。
虽然这一举措游走在法律的边缘处于灰色地带,但也直接反映出了大模型厂商对于训练数据的饥渴程度。

纽约时报指出,不只是OpenAI,谷歌、Meta等科技巨头因为想搜集高质量训练数据而修改隐私数据条款,来避免版权法的制裁。
例如,Meta为了追赶OpenAI、微软,使用了互联网上几乎所有公开的英语书籍、散文、诗歌和新闻文章等内容。
甚至想直接买下一家大型出版社,来获取更高质量的有版权、付费数据。不过没有人敢轻易相信Meta的数据隐私条例。
这是因为2018年的“剑桥分析丑闻”让Meta的信誉陷入低谷(那时的名字是Facebook)。
该事件是,一家英国剑桥分析公司通过一款心理测试程序,非法获取了大约8700万Facebook用户的个人隐私数据,包括未经用户明确同意的信息。
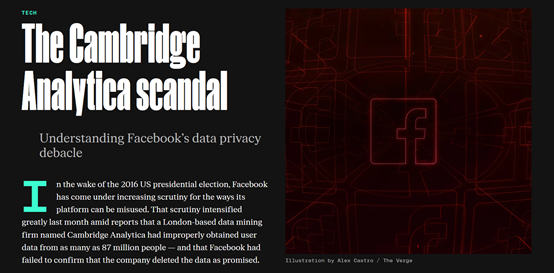
用户在参与测试时,不仅自己的数据被收集,就连Facebook好友的信息也被抓取。该丑闻爆发后,Facebook面临了前所未有的审查,该公司的数据隐私政策和管理不当受到严重处罚。
最后,以扎克伯格出面道歉、参加听证会才收场。
高质量数据,是生成式AI领域的“黄金”。
当你向ChatGPT、Gemini、Claude等提问获得文本答案时,心里是否会想过,这种内容的写法好像在哪里见过?
居然可以轻松写出古龙、金庸、莫言、莎士比亚、泰戈尔、芥川龙之介、夏目漱石等国内外知名作家风格的内容。
没错,大模型最擅长的便是抄袭然后二次创新,但整体框架、叙述方法还是以模仿为基石。
如果只用一句大白话来解释大模型的原理——通过海量预训练数据让大模型学会人类的写作技巧和习惯(视频、音频、图片架构会更复杂一些,但基本同理),然后进行排列组合、预测生成全新的内容(大模型的文本提示,相当于搜索引擎的关键字)。
所以,相比几千亿甚至上万亿的参数,在架构、算法差不多的情况下,训练数据对于大模型更重要。微软、Stability AI发布的Orca 2、Stable LM 2等模型也充分证明了——通过高质量数据训练的小参数模型,性能可以强过大参数模型。
就像上面的作家举例一样,A厂商的模型学习了夏目漱石的写作数据,而B没有,两家又都是基于Transformer架构,明显A的写作能力要大于B。
也可以把训练数据看成“内功心法”,当两位剑客的招式几乎差不多时,在关键时刻比拼的就是谁的内功高,谁便能技高一筹。
此外,为了获取高质量数据,2023年7月5日,谷歌 修改了数据隐私条款,将会抓取用户公开或来自其他公共来源的数据,用于训练Gemini(当时用名Bard)、谷歌翻译和云AI等产品。
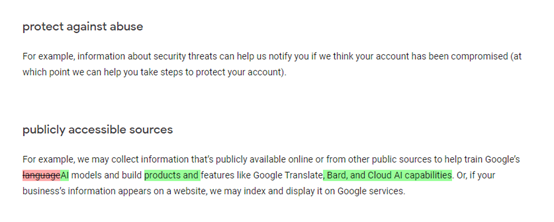
但好景不长,在公布消息的15天后,谷歌就接到了美国克拉克森律师事务所的起诉。在这份长达90页的诉讼书中,指控谷歌从网络秘密窃取大量数据来训练其AI产品。指控其疏忽、侵犯隐私、盗窃、侵犯版权以及从非法获取的个人数据中获利。
谷歌为了获取高质量数据铤而走险,可见数据对于大模型的重要性。
合成数据正成为主流
4月2日,华尔街日报在官网发布了一篇名为《对于大量消耗数据的AI企业来说,互联网太小了》的内容。
华尔街日报指出,对于大模型厂商来说互联网那点数据,就像一口被挖干的油井根本不够用。
尤其是对于训练视频、音频、图像这些比文本更复杂的模型,就像一个“数据黑洞”可以无限吸收各种数据。
但常在河边走哪有不湿鞋的事,各家科技巨头当然也清楚,游走在灰色地带只是无奈之举。所以,他们想了一个新办法使用合成数据。
合成数据是通过算法、机器学习模型自动合成的“虚拟数据”,以模拟真实世界数据的统计特性。基本上也是以模仿为主,但在法律和应用场景等方面有很多优势。
良好的隐私保护,合成数据可以在不暴露个人或敏感信息的情况下生成数据,这对于遵守GDPR或HIPAA等隐私法规非常重要。
无限数据源,理论上,可以生成无限量的合成数据,这对于需要大量数据但现实世界数据不足以支持的场景非常有用。
控制数据分布,可以精确控制合成数据的分布,能定制数据以探索特定的情况或增强模型在特定任务上的性能。
成本低,收集和标注大量真实世界数据比较贵,而生成合成数据的成本通常较低,主要由AI自动完成。
但合成数据也并非完美无缺,最致命的缺点便是过度拟合:如果合成数据过于简化或未能捕捉到真实数据的关键特征、表示,用于训练AI模型可能会过度拟合输出的内容同质化且繁重无用。
在合成数据应用方面,OpenAI在今年2月15日重磅发布的视频模型Sora,很多技术大咖就分析,Sora能生成如此高清的视频和时长,可能使用了虚幻引擎5生成的合成数据。
事实上,根据内测用户发布Sora生成的视频,然后与虚幻引擎5的示例视频进行了多维度对比,大概率是使用了合成的视频数据来训练Sora。
所以,使用合成数据训练AI模型,将成为未来主要趋势之一。
本文素材来源纽约时报、维基百科、谷歌官网、Meta官网、theverge官网,如有侵权请联系删除
END