写了这些还是不够完整,阿里 字节 卷进去加班!奥利给
ThreadLocal
线程变量存放在当前线程变量中,线程上下文中,set将变量添加到threadLocals变量中
Thread类中定义了两个ThreadLocalMap类型变量threadLocals、inheritableThreadLocals用来存储当前操作的ThreadLocal的引用及变量对象,把当前线程的变量和其他的线程的变量之间进行隔离,从而实现了线程的安全性
InheritableThreadLocal类重写get/set方法会对线程的inheritableThreadLocals变量初始化,在对子线程初始化时将子线程的inheritableThreadLocals变量赋值为父线程的inheritableThreadLocals变量值,实现了子线程继承父线程
内存泄漏问题
Thread->ThreadLocalMap->Entry->value,ThreadLocalMap是继承了WeakReference的entry集合,但是线程一直没有remove,threadLocal下次GC将弱引用对象回收,entry对象的key为null,value值却是强引用关系
ThreadLocal每次调用get、set、remove的时候都会直接或者间接的调用expungeStaleEntry方法清除掉key为null的Entry;
主线程执行ThreadLocal.remove()后,子线程中的ThreadLocal并不会被remove()判空,导致线程池中维护的ThreadLocal存储的值一直不变
池化:InheritableThreadLocal子线程使用线程池 更改存储 变量值不变
没找到对应的InheritableThreadLocal 自然改不了:普通的ThreadLocal会让子线程获取不到get值
池化:减少资源对象创建次数
private void init(ThreadGroup g, Runnable target, String name,long stackSize, AccessControlContext acc,boolean inheritThreadLocals) {//省略部分代码//如果父线程inheritableThreadLocals不为空,则保存下来if (inheritThreadLocals && parent.inheritableThreadLocals != null)this.inheritableThreadLocals =ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);//省略部分代码
}注意 使用静态和不使用静态时候
使用静态的InheritableThreadLocal 线程池复用时候不会有问题
ThreadLocal是线程本地变量,每个线程有自己的副本;InheritableThreadLocal具有继承性,在创建子线程时,子线程可以继承父线程的变量副本。
https://www.cnblogs.com/shanheyongmu/p/17922183.html
https://www.cnblogs.com/tiancai/p/17622821.html InheritableThreadLocal详解 - 简书
TransmittableThreadLocal
继承自InheritableThreadLocal,在线程池中传递ThreadLocal变量的值
GitHub - alibaba/transmittable-thread-local: 📌 a missing Java std lib(simple & 0-dependency) for framework/middleware, provide an enhanced InheritableThreadLocal that transmits values between threads even using thread pooling components.
/*
* holder里面存储所有关于TransmittableThreadLocal的引用
*/
public class TransmittableThreadLocal<T> extends InheritableThreadLocal<T> implements TtlCopier<T> {// 1. 此处的holder是他的主要设计点,后续在构建TtlRunnableprivate static InheritableThreadLocal<WeakHashMap<TransmittableThreadLocal<Object>, ?>> holder =new InheritableThreadLocal<WeakHashMap<TransmittableThreadLocal<Object>, ?>>() {@Overrideprotected WeakHashMap<TransmittableThreadLocal<Object>, ?> initialValue() {return new WeakHashMap<TransmittableThreadLocal<Object>, Object>();}@Overrideprotected WeakHashMap<TransmittableThreadLocal<Object>, ?> childValue(WeakHashMap<TransmittableThreadLocal<Object>, ?> parentValue) {return new WeakHashMap<TransmittableThreadLocal<Object>, Object>(parentValue);}};@SuppressWarnings("unchecked")private void addThisToHolder() {if (!holder.get().containsKey(this)) {holder.get().put((TransmittableThreadLocal<Object>) this, null); // WeakHashMap supports null value.}}@Overridepublic final T get() {T value = super.get();if (disableIgnoreNullValueSemantics || null != value) addThisToHolder();return value;}/*** see {@link InheritableThreadLocal#set}*/@Overridepublic final void set(T value) {if (!disableIgnoreNullValueSemantics && null == value) {// may set null to remove valueremove();} else {super.set(value);addThisToHolder();}}/*** see {@link InheritableThreadLocal#remove()}*/@Overridepublic final void remove() {removeThisFromHolder();super.remove();}private void superRemove() {super.remove();}
}1.继承InheritableThreadLocal,成立个TransmittableThreadLocal类, 该类中有一个hodel变量维护所有的TransmittableThreadLocal引用。
2.在实际submit任务到线程池的时候,需要调用TtlRunnable.get,构建一个任务的包装类。使用装饰者模式,对runnable线程对象进行包装,在初始化这个包装对象的时候,获取主线程里面所有的TransmittableThreadLocal引用,以及里面所有的值,这个值是当前父线程里面的(跟你当时创建这个线程的父线程没有任何关系,注意,这里讲的是线程池的场景)。
3.对数据做规整,根据收集到的captured (这个对象里面存储的都是主线程里面能够获取到TransmittableThreadLocal以及对应的值) 做规整,去掉当前线程里面不需要的,同时将剩余的key和value ,更新到当前线程的ThreadLocal里面。这样就达到了在池化技术里面父子线程传值的安全性
多线程篇-TransmittableThreadLocal解决池化复用线程的传值问题 - 知乎
hashMap1.7与1.8
1.7底层是entry数组+链表
颠倒链表顺序 元素插入前是否需要扩容,扩容后all元素重新计算下位置
头插法:逆序 环形链表死循环
ReentrantLock+Segment+HashEntry
第一次put hash(key)定位segment 未初始化cas赋值
第二次put,hashEntry ReentrantLock.tryLock获取锁,否自旋tryLock 获取锁 超次挂起
1.8node数组+链表+红黑树
保持原链表顺序 元素插入后检查是否扩容
链表长度达到8/元素总数达到64
synchronized+CAS+HashEntry+红黑树
没有初始化initTable
没有hash冲突 cas插入,否 加锁
链表遍历到尾部插入 ,红黑树就是红黑树的结构插入
添加成功addCount统计size是否需要扩容
高低位指针的形式,将低位上的数据移动到原来的位置,高位上的数据移动到【原来的位置+旧数组容量】的位置,避免了rehash
AQS
ConditionObject的await和signal等同Object的wait、notify函数(Synchronized)

五层
如果被请求的共享资源空闲,将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;
如果共享资源被占用,需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列(Craig、Landin and Hagersten,是单向链表)的变体实现的,将暂时获取不到锁的线程加入到队列中(AQS是通过将每条请求共享资源的线程封装成一个节点node来实现锁的分配)
理解AQS的原理及应用总结_aqs原理-CSDN博客 这篇阿里P6+的水平了
CountDownLatch和CyclicBarrier
CountDownLatch放行由其他线程控制,一直等待直到线程完成操作
计数器 aqs,countDown减state-1,await 判断state==0 非加入队列阻塞 头节点自旋等待state=0
CyclicBarrier本身控制,线程到达状态 暂停等待其他线程,all线程到达后 继续执行
任务线程调用,线程相互等待,可重用
ReentrantLock加上Condition,await,count -1 ReentrantLock线程安全性,如count不为0,加则condition队列中,如count==0,把节点从condition队列添加至AQS的队列中进行全部唤醒,并且将parties的值重新赋值为count的值(实现复用)
volatile
共享变量:主内存
线程有自己的工作内存
线程间变量的值传递需要主内存
一个线程使用共享变量先判断当前副本变量的状态 无效状态的话 向总线发送read 消息读取变量最新数据 总线贯穿这个变量用到的所有缓存以及主存 读取到的最新数据可能来自主存 也可能来自其他线程
lock指令 本地线程写入内存,其他线程失效
read指令 读取变量最新数据
禁止指令重排
字节码层面:使用volatile修饰变量,在编译后的字节码中为变量添加ACC_VOLATILE标记
JVM层面:JVM规范中有4个内存屏障,LoadLoad/StoreStore/LoadStore/StoreLoad,在读到ACC_VOLATILE标记时会在内存区读写之前都加屏障
操作系统和硬件层面:操作系统执行该程序时,查到有内存屏障,使用lock指令,在指令前后都加lock(屏障),保证前后不乱序
volatile 指令重排以及为什么禁止指令重排_volatile为什么要禁止重排序-CSDN博客
总线风暴
volatile和cas导致bus总线缓存一致性流量激增
一个变量在多个高速缓存中存在,高速缓存间数据不共享 数据不一致
总线锁定 缓存锁定
MESI:已修改modified 互斥独占exclusive 共享share 无效invalid
1使用共享数据 拷贝到1缓存中 设为E
2也使用共享数据,拷贝到2缓存
1把变量回写到主存,先锁住缓存行,状态=M 向总线发消息告诉其他 在嗅探的cpu 该变量被修改并写会主存,其他CPU 状态S=> I无效,需要时从内存获取
发现缓存地址被改了,无效I
失效:共享变量大于缓存行大小 ,mesi 无法对缓存行加锁


高速缓存:时间局部性(变量被访问 近期may再次被访问)
空间局部性(变量被访问 周围变量可能被近期访问)
缓存行默认64字节
https://blog.51cto.com/u_16213606/7587478
java数据结构
树
前序遍历 ①先访问根节点 ②在访问左节点,接着访问右节点
后序遍历 ①先访问左节点,在访问右节点 ②最后访问根节点

二叉树
一颗非空二叉树的第i层上最多有2^(i-1)个节点
一颗高度为k的二叉树,最多有2^k -1 个节点
满二叉
一颗高度为K 并且具有2^k - 1 个节点
完全二叉树
哈夫曼树
哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树
数据结构——哈夫曼树-CSDN博客
二叉排序树
左小右大
二叉平衡树AVL
左右子树 高度差 <=1
数据结构——常见的几种树(万字解析)_数据结构如何判断型lr型rr型rl型-CSDN博客
红黑树:带颜色 非黑即红
二叉查找树:
Trie树:前缀树/字典树
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串
B树:多路平衡查找树
每个节点最多只有m个子节点
非叶子节点中不仅包含索引,也会包含数据
B+树
所有的叶子结点中包含了全部关键字的信息
总结下各种常见树形结构的定义及特点(二叉树、AVL树、红黑树、Trie树、B树、B+树) - 知乎
mysql
count1和count*
数据量大 *费时 没有主键 *慢,联合主键 *比主键慢 一个字段*最快
*自动优化指定到某列字段
唯一索引和普通索引的区别
changeBuffer:buffer pool一部分,缓存非唯一索引,当操作命中缓存中索引时 合并操作 空闲写入磁盘 减少IO
目的是减少查询索引表,唯一索引校验唯一性 不得不查索引表 不能使用changeBuffer
merge过程:
磁盘读取数据页到内存 changeBuffer找到数据页changeBuffer,应用到新数据页
redoLog含数据变更信息,changBuffer数据变更动作

Mysql - 普通索引与唯一索引之间性能差别change buffer-CSDN博客
redoLog与changeBuffer:
redoLog节省随机写磁盘的IO消耗 转成顺序写
changeBuffer随机读磁盘的IO消耗
唯一索引和普通索引的区别,以及changeBuffer_唯一索引和普通索引区别 changebuffer-CSDN博客
普通索引和唯一索引,难道还分不清 - 知乎
页分裂
我也快分裂了 什么世道 卷吧 比鸡蛋卷还🌹
一个数据页满的情况下,为插入新数据 将该页分裂为两页 新数据插入新页
减少数据迁移 提供插入效率
过程:新建页 原页一半数据移动到新页 插入新数据到新页 更新原页指针指向新页
调控优化:
innodb_autoinc_lock_mode 控制自增字段锁定方式,2页级锁定 减少锁定粒度 提供库性能
innodb_fill_factor控制数据页填充的程度,参数越小 填充程度越高 减少页分裂次数
优化查询语句 合并事务
https://blog.51cto.com/u_16175465/9573866
页合并
ibd文件:segment段 extent区1M 64pages page页16k 2-N数据行 max8000bytes
merge_threshold
mysql InnoDB中的页合并与分裂_mysq页合并-CSDN博客
删除一行记录 标上flaged 且被容许使用 ,删除记录达到merge_threshold 页体积50% innodb寻找最靠近的页 是否可将两个合并
JVM
癫狂吧这个世界
可达性分析算法中根节点
GC管理主要是堆,你像方法区 栈 本地方法区
本地方法栈中JNI native方法引用的对象
虚拟机栈(局部变量表)引用的对象
方法区类静态属性引用的对象
方法区常量引用的对象
tracingGC 通过找到活对象把其他的空间认定为无用
hotspot
OopMap记录根对象引用
类加载完 hotspot会把对象内什么偏移量是什么类型的数据计算出来
特定位置 记录栈 寄存器哪些位置是引用
安全点:all线程尽快在安全点停下来 GC时挂起 方法调用/循环跳转/异常跳转
安全区域:内引用关系不变化 回收垃圾是安全的
记忆集:记录从非收集区域指向收集区域的指针集合
YGC时老年代对象引用了新生代对象,老年代加入可达性分析中
卡表:非收集区2的N次幂字节数大小区域,HotSpot中是2的9次幂=512字节
0无 1有 -1脏
写屏障:维护卡表,引用类型字段赋值前后加上前/后屏障 aop
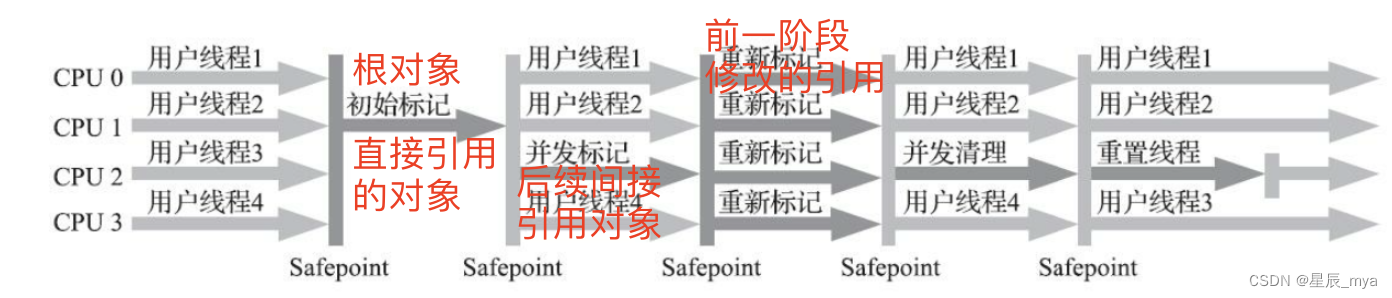
并发的可达性分析
根节点出发 找出所有存活对象,线程进入安全点或安全区域 停顿等待可达性分析完成
避免长时间停顿,分为两阶段 初始标记STW(根节点all被引用对象) 和 并发标记(被引用对象出发找到后续引用对象) CMS G1
三色标记:
白色 未被引用的垃圾对象 黑色已扫描过的存活对象 灰色:本身存活 至少一个未扫描的引用
垃圾对象白色被重新引用:对象消失
插入一条/多条黑色对象到白色的引用 同时删除灰色对象到白色对象的引用
解决:
增量更新:写屏障在引用变化时将相关黑色对象标记为灰色对象,重新标记阶段灰色被发现 白色也被发现 存活 CMS 黑色就不扫了所以灰色强制扫
原始快照:扫描生成对象图快照,删除灰色对白色引用时 删除的引用记录下来 并发扫描结束后将这些变动的引用中灰色作为根 按快照图重新扫描 快照图中保存了删除前引用关系 白色扫描到标记为存活G1
垃圾收集器
年轻代收集器:Serial、ParNew、Parallel Scavenge
老年代收集器:Serial Old、CMS、Parallel Old
Parallel Scavenge、Parallel Old:JDK8
提供jvm吞吐量,STW整个流程
-XX:MaxGCPauseMillis最大停顿时间,收集器尽量时间内回收,越小新生代越小 回收空间小 吞吐量容易变低
-XX:GCTimeRatio(垃圾收集时间比率0-100)运行用户代码时间占比
1:19 占1%总时间 ;最大占5%的总时间
CMS
缩短GC停顿时间,内存不足收集失败 就会用 serialOld单线程收集垃圾
问题:
cpu核数少 垃圾回收对用户程序影响大 ,默认开启(处理器核心数量 +3)/4 (2+4)/4=1占有50cpu资源
浮动垃圾下次GC才能回收
并发收集失败 concurrent mode failure单线程回收,预留内存不足分配新对象,老年代到了-XX:CMSInitiatingOccupancyFraction使用率 触发CMS 1-100,越小 预留空间越大 cms越频繁
标记清除算法内存碎片,开启内存整理(-XX:+UseCMS-CompactAtFullCollection)9废弃
G1
jdk9默认,物理上不分代,逻辑上分代;堆内存划分成N个相等大小的Region
动态指定region属于eden/survivor或老年代中的一种,大对象Humongous区域
-XX:MaxGCPauseMillis最大收集停顿时间200ms,region回收最小单元,维护可回收region集合collectionSet:g1计算回收能获得空间大小 时间 过往回收经验 按停顿时间 有计划回收高优先级收益大region
region维护哈希表结构的记忆集 记录跨region引用,key别的region的起始地址,value存储卡表的索引号集合,双向结构
TAMS指针:划分region空间分配新对象,默认存活不纳入回收范围

cms和G1区别
cms标记清除/g1复制清除
g1耗内存,维护region记忆集合20%甚至更多内存,cms只是记录跨代引用
g1负载高,cms g1写屏障维护记忆集合:变动的引用信息,g1复杂 维护成本高 cms简单卡表
并发标记对象消失问题:cms增量更新 黑变灰 ,g1 satb原始快照 停顿时间短
整体看:小内存应用cms优shi大 6-8G
satb
Snapshot-At-The-Beginning
开始标记生成快照图,标记存活对象,并发标记被改变对象入队(写屏障 all旧引用指向的对象变灰)
tams:top at mark start region记录prevTAMS nextTAMS,tasm分配新对象
JVM垃圾回收总结_可达性分析算法中根节点有哪些-CSDN博客
SATB深入详解与问题剖析【纯理论】-CSDN博客
怎样GC调优
Young GC后的存活对象小于Survivor区域50%,都留存在年轻代里
jstat:内存分配速率 GC次数/耗时
jstat -gc pid 时间间隔 次数
jmap:运行时对象分布/内存
jmap -histo:live pid
jmap -dump:live,format=b,file=dump.hprof <pid>
-XX:+HeapDumpOnOutOfMemoryError. -XX:HeapDumpPath=<path>. -XX:HeapDumpInterval=<seconds>
jstack:堆栈跟踪工具
当前时刻的线程快照
jstack pid|grep -A 100 线程id(printf '%x\n' * )
jinfo系统参数命令,启动参数
jinfo -flags pid
arthas:在线诊断工具https://arthas.aliyun.com/doc/
如何进行GC调优 - 简书
FullGC触发条件:
- 老年代空间不足:新生代空间不足放到老年代,老年代不足fullGC -- XX:NewRatio=n
- 永久代空间不足:7堆MaxPermSize8本地内存MaxMetaspaceSize,字符串常量池在堆中
- CMS碎片过多扛不住 CMSFullGCsBeforeCompaction多少次fullGC压缩堆,整理碎片
- CMS GC时出现了promotion failed新生代把对象扔老年代,老年代不行和concurrent mode failure启动老年代内存占比阈值高,预留空间不足,担保机制
- 老年代增长过快触发full gc进行清理,CMSInitiatingOccupancyFraction降低触发CMS的阀值
- system.gc建议系统调用fullGC -XX:-DisableExplicitGC禁止此类full gc
- 新生代minor gc时晋升到老年代的平均大小大于老生代剩余空间
大对象:对象池技术 重复利用对象 ;分配从堆移动到本地内存
对象池的介绍与使用-CSDN博客
怎样排查CPU彪高
监控cpu使用率:top taskManager jstat
线程分析:jstack
关联分析:线程转储与CPU占用线程的操作系统id关联;ps -L -p pid进程中的线程 进程
代码分析:死循环 大量循环计算 密集字符串操作
性能剖析:visualVM YourKit JProfiler实时监控
Java CPU或内存使用率过高问题定位教程_java内存和cpu飙升-CSDN博客
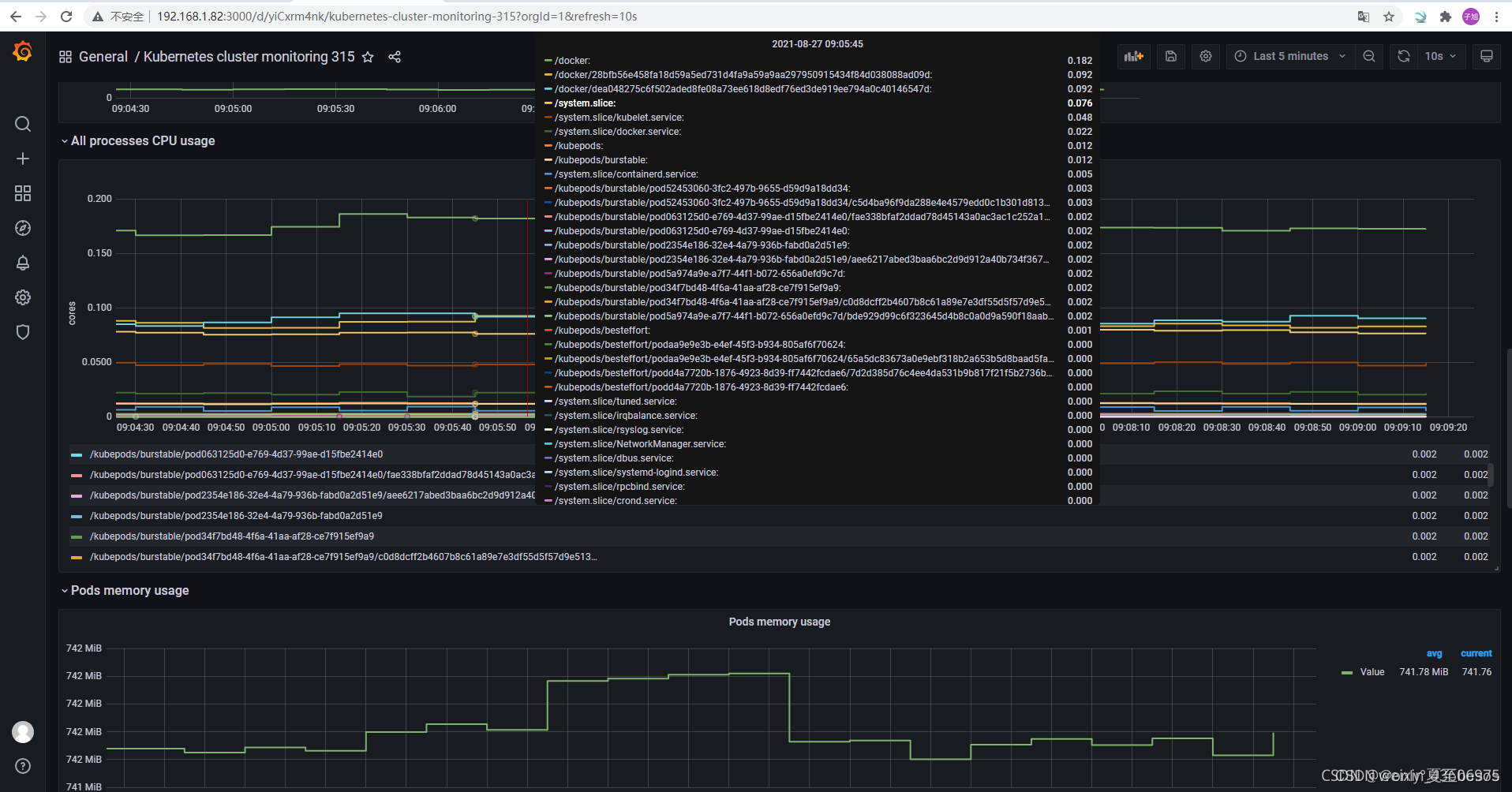
Prometheus如何收集数据
基于时间序列数据库的监控系统
- 拉取pull,定期拉取监控数据,默认
- 推送push,目标主动将监控数据推送到服务器
- 服务发现,支持多种服务发现机制 Consul, DNS, Kubernetes,自动发现需要监控的目标
- 集成第三方: Graphite, InfluxDB, Elasticsearch 等
克服网络障碍:Prometheus如何通过间接方式采集目标服务数据 - 知乎
grafana 和 Prometheus 采集数据并展示 - 简书
内存彪高
创建大量对象导致的 垃圾回收跟不上速度 内存泄漏无法回收
jstat -gc pid 查看gc次数 时间
jmap -histo pid | head -20 堆内存占用空间max的20个对象类型
逃逸分析
分析技术,分析对象的动态作用域,供其他优化措施提供依据
TLAB
为新对象分配内存空间时,让每个Java应用线程使用自己专属的分配指针来分配空间(Eden区,默认Eden的1%),减少同步开销
线程堆Eden中预分配私有内存,all线程都能访问,一个满了申请另一个
现在是北京时间 ****整 接着奏乐
标量替换:
逃逸分析:一个对象只会作用于方法内部 标量替换优化
Java线上服务CPU、内存飙升问题排查步骤!_java cpu过高排查-CSDN博客
redis
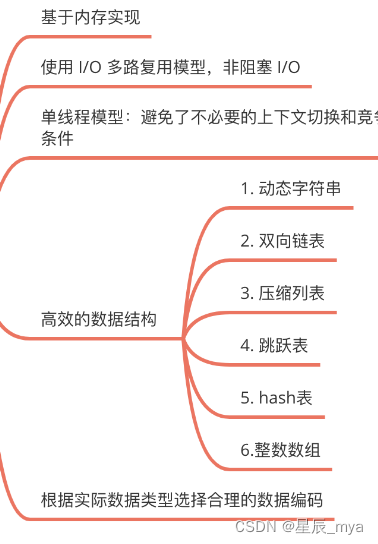
redis数据结构
redis原理深入解析之看完这篇还需要努力-CSDN博客
跳跃表:skip list
有序元素序列快速搜索的随机化数据结构
zset内部使用了
typedef struct zskiplistNode {// 成员对象,字符串保存SDSrobj *obj;// 分值,有序double score;// 后退指针,一次后退一步struct zskiplistNode *backward;// 层 数量越多访问其他节点的速度越快struct zskiplistLevel {// 指向表尾的前进指针struct zskiplistNode *forward;// 跨度 记录距离,跨度大距离远unsigned int span;} level[];
} zskiplistNode;Redis-跳跃表(skip List)_redis跳表-CSDN博客
我们项目redis qps能上多少
概念:qps:每秒查询率 tps:事务数/秒
思路一:仿真环境 py 测试每秒查询的次数
//官方单机可达到11万次/秒,其中写的速度大约为8万次/秒
思路二:Redis自带的`redis-benchmark`性能测试工具来测算Redis处理实际生产请求的QPS
具体:
社交类平台,日活百万 QPS 30w+
sentinel和cluster区别和各自适用场景
sentinel主从复制,周期性检测redis实例状态,主不可用 从选主 3个
cluster分布式,数据分散多个节点 吞吐量,自动分片/故障切换 3主3从
详解Redis三大集群模式,轻松实现高可用! - 知乎
redis cluster集群同步过程
16384个槽,每个槽被分配给主和*个从,节点加入离开 一致性哈希算法自动分片
redis单线程为什么快

单线程:网络io / 键值对读写 不需要创建线程/上下文切换/线程竞争/代码简单
io多路复用,并发处理连接
epoll 读写 关闭 连接转成事件,多路复用
io多路复用:多个socket 连接 复用一个线程,select poll epoll
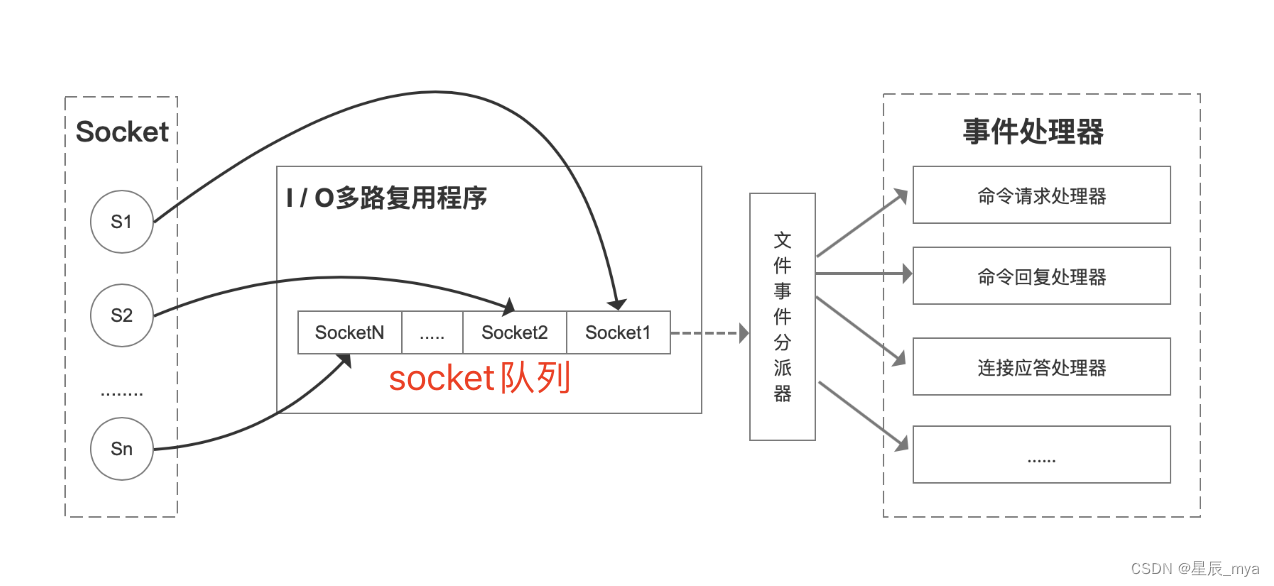
https://www.cnblogs.com/uniqueDong/p/15376479.html

string分布式锁,lua脚本 ;int raw
sds
list:关注: ziplist linkedlist
hash:用户信息 ziplist hashtable
链式哈希解决冲突,两个hash 先用1 rehash给2更大的空间 映射拷贝到2。释放1
set:动态点赞 踩(后面去掉了) 共同好友 ;intset hashtable
zset:金币数排行榜 / 签到排行榜 ziplist/skiplist
ziplist:特殊编码的连续内存块组成的顺序型的数据结构
struct ziplist<T> {int32 zlbytes; // 整个压缩列表占用字节数int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点int16 zllength; // 元素个数T[] entries; // 元素内容列表,挨个挨个紧凑存储int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
quicklist:ziplist 和 linkedlist
skipList有序数据结构
大key:key对应的value过大
string:10kb. set/zset/hash 5000条
bigkeys查找,阻塞线程
解决:数据结构优化/数据分片到多个key/压缩数据/分布式存储/及时清理过期数据
热key产生原因和后果以及怎么解决
业务规划不足,无效数据堆积,访问突增
4.0起提供了MEMORY USAGE命令来帮助分析Key的内存占用
4.0起提供了UNLINK命令,该命令能够以非阻塞的方式缓慢逐步的清理传入的Key
4.0起提供hotkeys参数来进行实例级的热Key分析功,该参数能够返回所有Key的被访问次数
Redis内存报警阈值来提醒我们此时可能有大Key正在产生
详解Redis中BigKey、HotKey的发现与处理 - 知乎
增加分片副本,二级缓存,jvm本地缓存
Redis中的热点Key问题_redis 热点key 问题-CSDN博客
Redis-大key热点key的问题_redis 大key 热点-CSDN博客
Tair:分布式缓存系统:
Tair首页、文档和下载 - 分布式key/value存储系统 - OSCHINA - 中文开源技术交流社区

Redis原理之BigKey和热点Key_redis hotkeys命令原理-CSDN博客
mdb:高效缓存存储引擎 memcached 内存管理方式
fdb:简单高效持久化存储引擎,key 的 hash 值索引数据,索引文件 数据文件分离,尽量保持索引文件在内存中
京东hotkey
 hotkey: 京东App后台中间件,毫秒级探测热点数据,毫秒级推送至服务器集群内存,大幅降低热key对数据层查询压力
hotkey: 京东App后台中间件,毫秒级探测热点数据,毫秒级推送至服务器集群内存,大幅降低热key对数据层查询压力
本地缓存需要高时效性怎么办
缓存雪崩/击穿/穿透
一致性:mq/canal+mq
脑裂
两个主节点。当前主库暂时性失联,哨兵主从切换机制 原主库恢复开始处理请求
min-slaves-to-write(最小从服务器数) 和 min-slaves-max-lag(从连接的最大延迟时间)
主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的请求了,客户端也就不能在原主库中写入新数据;
spring
spring的作用
开源框架,IOC AOP
spring循环依赖怎么解决(说出三级缓存源码细节)
一级缓存singletonObjects存放经过spring完整生命周期的单例bean
二级缓存earlySingletonObjects已经实例化/经过aop的半成品bean
三级缓存singletonFactories存放工厂,将bean提前aop 没有属性填充/没有完成初始化
百度安全验证 写得挺好
addSingletonFactory方法在createBeanInstance之后
spring aop原理(动态代理)
JDK:Proxy类和InvocationHandler接口
@EnableCaching(mode = AdviceMode.ASPECTJ)
LTW加载时织入:JVM加载类的时候,对jar包里的类做一些修改,两种方式
classLoader:@EnableLoadTimeWeaving只在应用容器中运行,tomcat jboss,boot是jar❌
jvm传递javaagent:aspectjweaver.jar 启动时指定jar包路径 -javaagent:path
spring bean生命周期(源码细节,以及各个位置的设计思路,有什么可扩展的)
Spring Boot教程(20) – 用AspectJ实现AOP内部调用 - 知乎
区别:aop运行时创建目标对象代理类 AspectJ编译/类加载 改变class字节码 织入切面到代码
https://www.cnblogs.com/hackem/p/9718311.html
待续
dubbo
海燕呐~
dubbo服务暴露和引用过程
远程暴露:发布到远程注册中心,通过协议 dubbo rmi hessian http 网络传输发布到中心 消费者订阅注册中心获取提供者地址,通过协议进行网络通信,调用方法
url = exportRemote(url, registryURLs);#指定的协议进行暴露 url暴露的服务信息 registryRULs注册中心
MetadataUtils.publishServiceDefinition(url, providerModel.getServiceModel(), getApplicationModel());
额外的导出协议(解析url上String[] extProtocols = extProtocol.split(",", -1);) 也是这样流程 遍历注册中心 跳过自省/本地暴露
url 添加 DYNAMIC_KEY MONITOR_KEY
registryURL 添加PROXY_KEY
// 把服务消息作为一个属性包裹在注册中心url内,并执行导出
doExportUrl(registryURL.putAttribute(EXPORT_KEY, url), true);//会根据协议类型来选择实现类来进行发布 ZookeeperRegistry
public void doRegister(URL url) {try {checkDestroyed();zkClient.create(toUrlPath(url), url.getParameter(DYNAMIC_KEY, true), false);} catch (Throwable e) {throw new RpcException("Failed to register " + url + " to zookeeper " + getUrl() + ", cause: " + e.getMessage(), e);}
}
本地暴露:服务发布到jvm,同一jvm其他服务调用;提供者实现类通过代理注入本地jvm缓存中,消费者从jvm缓存获取代理对象,调用方法
injvm协议构建URL protocolSPI.export(invoker) 进行导出 实现类InjvmProtocol
Dubbo最核心功能——服务暴露的配置、使用及原理_dubbo服务暴露及服务调用流程-CSDN博客
SPI全双工串行通信
同步数据总线,单独数据线 时钟信号=》收发端同步 SPI协议详解(图文并茂+超详细) - 知乎
dubbo的spi
配置目录 meat-inf/dubbo/
@Adaptive自适应 不确定哪个类实现
Activate什么条件下可用
加载某个扩展点的所有配置,所谓配置,其实就是<简称,类名>这种配置
【爆肝两万字 收藏向】从用法到源码,一篇文章让你精通Dubbo的SPI机制-CSDN博客ff
服务暴露的触发
@EnableDubbo import DubboComponentScanRegistrar
把dubbo部分类融入spring框架initialize
开发代码dubbo服务注册进spring: registerServiceAnnotationPostProcessor
负载均衡策略
容错机制在哪里实现的源码
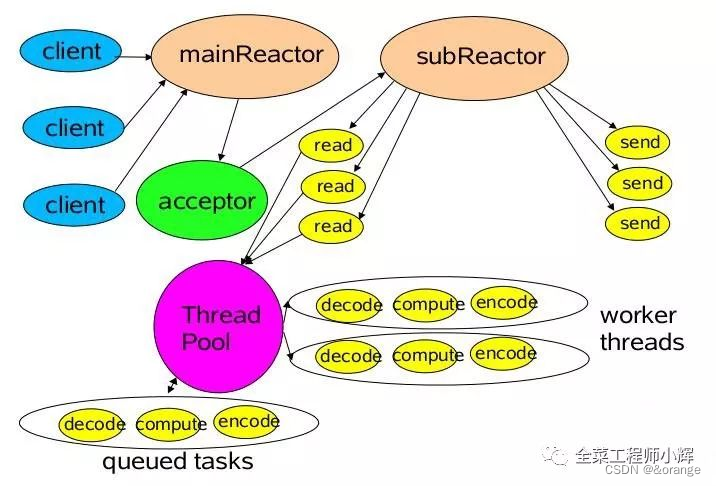
NIO、BIO区别,NIO解决了什么问题,Netty线程模型(源码拷问)
MQ相关(RocketMQ、kafaka奇怪的是你写啥面试官问啥,面试官啥都会,技术广度深度令人发指)




![[通俗易懂]《动手学强化学习》学习笔记2-第2、3、4章](https://img-blog.csdnimg.cn/direct/94e1741388d64c5fa269f0a907341644.png)