Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
PDF: https://arxiv.org/pdf/2403.14608.pdf
1 概述
大型模型在多个领域取得了显著进展,但它们的大规模参数带来了高昂的计算成本。这些模型需要大量资源来执行,尤其是在针对特定任务进行定制时。参数有效微调(PEFT)提供了一种解决方案,它通过调整预训练模型的参数来适应特定任务,同时尽量减少额外的参数和计算资源消耗。
本文对PEFT算法进行了全面研究,评估了它们的性能和计算成本,并探讨了使用这些算法的应用程序。同时,本文也讨论了降低PEFT成本的常用技术,并研究了不同系统设计中的实施成本。这项研究为理解PEFT算法及其系统实现提供了宝贵的资源,为研究人员提供了最新的进展和实际应用的深入见解。
2 LLaMA-7B模型
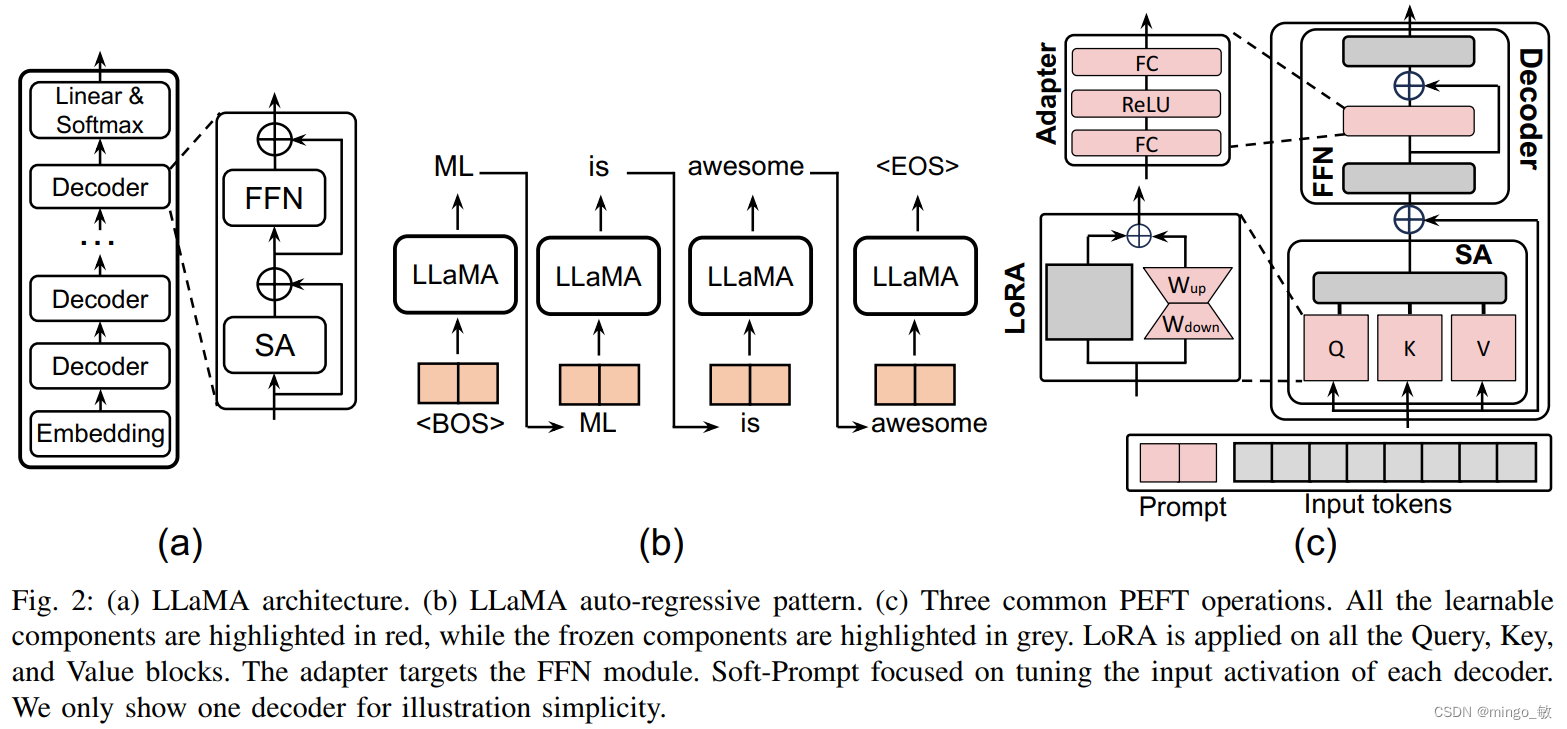
LLaMA-7B模型是基于Transformer架构的大规模语言模型,具有70亿参数量。它在设计上进行了一些优化和改进,以提高模型的性能和效率。以下是LLaMA-7B模型的结构和训练过程的详细描述。
模型结构
- 嵌入层(Embedding Layer):LLaMA-7B模型的输入是文本数据,首先需要通过嵌入层将文本转换为数值向量。嵌入层的主要作用是将离散的文本信息转换为连续的数值表示,这些数值向量也被称为tokens。在LLaMA模型中,嵌入层的位置编码采用了旋转位置编码(RoPE),这是一种通过绝对位置编码来表示相对位置的方法,可以更好地捕捉序列中元素之间的相对位置关系。
- 解码器层(Decoder Layers):嵌入层的输出被送入一系列的解码器层。每个解码器层包含两个主要的子模块:多头自注意力(Multihead Self-Attention, MSA)和前馈网络(Feedforward Network, FFN)。MSA模块允许模型在处理一个token时考虑到序列中的其他token,而FFN则对MSA的输出进行进一步的处理。LLaMA-7B模型中的MSA模块使用了Group Query Attention(GQA),这是一种改进的注意力机制,可以减少参数量并提高模型的训练效率。
- 归一化(Normalization):为了提高训练的稳定性,LLaMA-7B在每个Transformer子层的输入上应用了归一化。具体来说,它使用了Root Mean Square Layer Normalization(RMSNorm),这是一种比传统的LayerNorm更高效的归一化方法,可以加速训练过程。
- 激活函数(Activation Function):LLaMA-7B使用了SwiGLU作为激活函数,这是一种比ReLU更平滑的激活函数,有助于改善模型的优化过程和收敛速度。
3 PEFT TAXONOMY

PEFT策略可以宽泛地分为以下四类:
- Additive PEFT,它通过引入新的可训练模块或参数来改进模型架构;
- Selective PEFT,它在微调过程中精选出部分参数进行训练;
- Reparameterized PEFT,它先对原始模型参数进行低维重参数化以适应训练需求,然后在推理时等效地转换回原始参数;
- Hybrid PEFT,它汲取不同PEFT方法的精华,综合构建出一个统一的PEFT模型。

3-1 Additive PEFT
3-1-1 Adapters
适配器方法通过在Transformer块中插入小型适配器层来实现。适配器层通常由降维矩阵、非线性激活函数和升维矩阵组成。其中,d代表隐藏层维度,r是配置适配器的瓶颈维度超参数

Serial Adapter(Parameter-efficient transfer learning for nlp)通过在Transformer块的自注意力层和前馈网络(FFN)层之后添加适配器模块来增强模型。然而,添加适配器层可能会增加计算成本,因此后续研究提出了改进的框架,如AdapterFusion(Adapterfusion: Non-destructive task composition for transfer learning.),它通过在FFN层后的’Add & Norm’步骤后插入适配器层来提高计算效率。
为了解决顺序适配器可能降低模型并行性的问题,引入了parallel adapter(PA)(Towards a unified view of parameter-efficient transfer learning)方法,它将适配器层作为并行的侧网络运行,以提高效率。CoDA(Conditional adapters: Parameter-efficient transfer learning with fast inference)等模型采用了稀疏激活机制,通过软top-k选择过程集中处理重要的tokens,以优化推理效率。
此外,为了进一步提升适配器的性能和泛化能力,研究者们实施了多任务学习策略,如AdapterFusion、AdaMix、PHA等。这些方法通过不同的方式融合多任务信息,如AdapterFusion使用融合模块合并信息,而MerA通过最优传输将多个适配器合并为一个,避免了引入额外的可训练参数。Hyperformer则采用共享的超网络结构,根据任务和层的ID嵌入生成特定的适配器参数,减少了新任务所需的训练参数数量。这些方法在提高模型适应性和效率方面取得了显著进展。

3-1-2 Soft Prompt
Prompt tuning是另一种通过微调提升模型性能的方法。与通过上下文学习优化离散标记不同, Soft Prompt的连续嵌入空间被认为包含更多信息。因此,研究者直接在输入序列的开头添加可调向量(即 Soft Prompt)。

其中, X l X^{l} Xl是层l的输入标记序列,包括软提示标记 s i l s_{i}^{l} sil和随后的原始输入标记 x i l x_{i}^{l} xil。 N S N_{S} NS是软提示标记的数量, N X N_{X} NX是原始输入标记的数量。
Prefix-tuning是一种微调技术,通过在所有Transformer层的键(k)和值(v)前添加可学习的前缀向量来实现。为了优化过程中的稳定性,它使用MLP层生成这些向量,而非直接优化。微调后,仅保存前缀向量用于推理。该技术在后续研究中得到改进,例如p-tuning v2取消了重参数化并扩展到更大模型和任务。APT引入了自适应门控机制控制每层的前缀重要性。p-tuning和prompttuning只在词嵌入层使用可学习向量,提高效率。Xprompt通过分层剪枝优化了小模型的性能。IDPG根据输入句子生成提示,而LPT在中间层之后添加提示,加速训练并保留任务相关信息。SPT进一步探索了提示插入策略,引入概率门控机制决定使用旧提示还是新提示。APrompt在自注意力块中添加额外的可学习提示。软提示被用于多个任务,但训练可能不稳定,SPoT和TPT通过任务间的提示转移来改善这一点。InfoPrompt开发了基于互信息的损失函数以优化提示。PTP通过引入扰动正则化器来稳定训练过程。DePT将软提示分解为短提示和低秩矩阵,提高效率。SMoP使用短软提示降低成本,并通过门控机制在推理时选择合适提示。IPT通过自编码器识别任务子空间,减少新任务的调整参数。
3-1-3 Other Additive Methods

3-2 Selective PEFT
选择性PEFT(参数高效微调)与增加模型复杂度的累加式PEFT不同,它通过微调现有参数的子集来提升模型在下游任务上的性能。这种方法不仅避免了模型过度膨胀,还通过精准调整关键参数,实现了对模型性能的有效提升。通过这种方式,模型能够更加专注于与特定任务相关的参数,从而在保持模型简洁的同时,实现性能的优化。

Diff pruning是一种在微调时对模型权重应用可学习二进制掩码的技术,通过L0范数的可微近似进行正则化以提高参数效率。PaFi选择绝对值最小的模型参数进行训练。FishMask和Fish-Dip利用费舍尔信息确定参数重要性,并据此形成掩码M,后者会在每个训练周期动态更新掩码。LTSFT和SAM分别基于彩票假设和二阶近似方法选择参数掩码。Child-tuning在每次迭代中选择一个子网络进行参数更新。
非结构化参数掩码可能导致计算和硬件效率降低。结构化掩码如Diff pruning通过分组权重参数进行剪枝,FAR对BERT模型的FFN权重进行分组和排名,Bitfit专注于微调DNN层的偏置参数。S-BitFit将NAS应用于Bitfit,保持其结构特性。Xattn Tuning专门微调Transformer的交叉注意力层。SPT通过一阶泰勒展开识别敏感参数,然后应用PEFT技术进行结构化调整。这些方法旨在提高微调的效率和性能。
3-3 Reparameterized PEFT
重参数化是一种通过变换模型参数来改变模型架构的技术,在参数高效微调(PEFT)中,它通常用于构建低秩参数化,以提高训练时的参数效率。在推理阶段,模型可以恢复到原始权重参数化,以保持推理速度不变。LoRA是一种流行的重参数化技术,它通过引入两个可训练的权重矩阵来实现增量更新,从而嵌入特定任务的知识。DyLoRA和AdaLoRA是LoRA的变体,它们通过动态选择秩和基于重要性得分的奇异值剪枝来优化LoRA的训练过程。
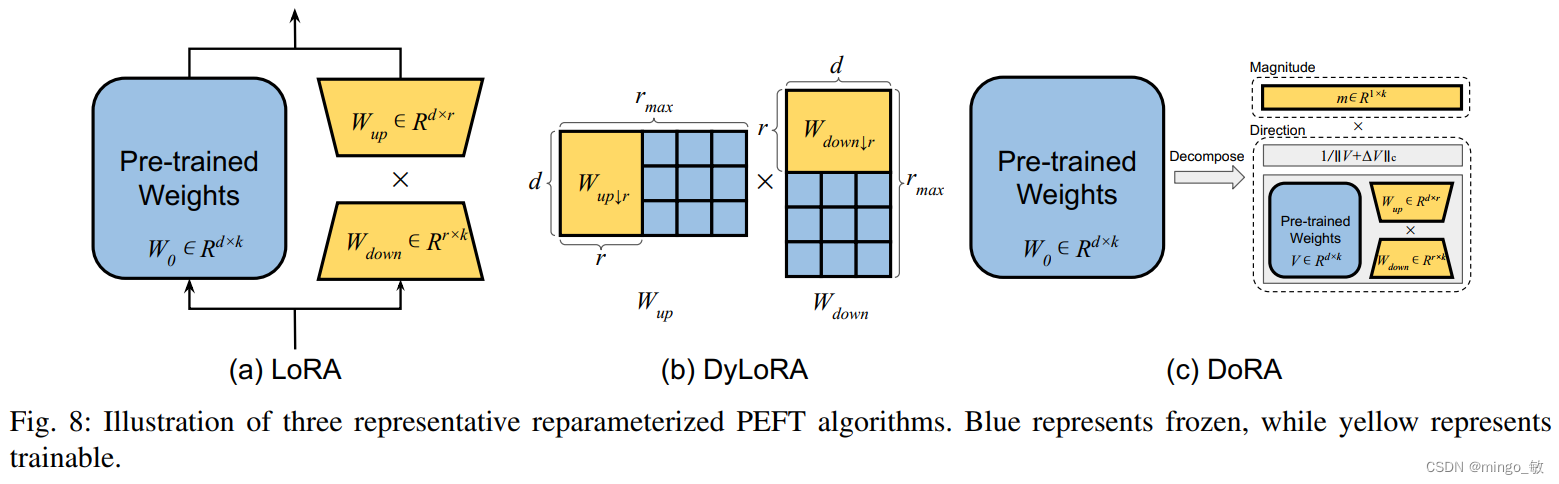
除了LoRA,其他重参数化技术如Compacter、KronA、KAdaptation和HiWi也在不断涌现,它们通过不同的方法减少参数数量并提高模型效率。DoRA通过分解模型权重为幅度和方向,并采用独特的微调策略,在多个任务和模型上显示出优异的性能。这些技术通过有效管理和减少参数数量,提高了大型语言模型微调的效率和性能。
3-4 Hybrid PEFT
各种参数高效微调(PEFT)方法在不同任务中的效果可能会有显著差异。为了最大化这些方法的效益,许多研究致力于融合不同PEFT技术的优势,或者通过分析它们的共性来寻求一个统一的框架。例如,UniPELT通过将LoRA、前缀调整和适配器技术整合到每个Transformer块中,实现了一个综合的微调策略。为了精确控制哪些PEFT子模块应当被激活,UniPELT引入了一个精巧的门控机制。这个机制由三个小型的前馈网络(FFN)构成,每个FFN生成一个标量值,这些值随后用于调节LoRA、前缀和适配器矩阵的激活程度。通过这种方法,UniPELT能够灵活地适应不同的任务需求,优化微调过程,并提高模型的整体性能。
4 efficient PEFT design
在计算领域,处理延迟和峰值内存消耗是设计高效模型时需要特别关注的关键因素。本文将探讨一系列旨在应对计算挑战的高效PEFT方法,包括PEFT修剪、PEFT量化以及内存高效PEFT技术。这些方法旨在在优化模型性能的同时,尽可能减少资源消耗。

4-1 针对PEFT效率的KV缓存管理 KV-cache Management for PEFT Efficiency
LLM模型的核心是一个自回归Transformer模型,如图2所示。自回归特性在设计推理系统时带来了挑战,因为每次生成新的令牌时,LLM模型都需要将所有权重从内存转移到图形处理器的内存中,这对单用户任务调度或多用户工作负载平衡不利。自回归范式的挑战在于,所有先前的序列都必须被缓存并保存以供下一次迭代使用,这些缓存的激活被存储为键值缓存(KV缓存)。
KV缓存的存储不仅消耗内存空间,还影响IO性能,导致工作负载内存受限和系统计算能力未充分利用。以往的工作提出了多种解决方案,如KV缓存控制管理和压缩,以提高吞吐量或减少延迟。在设计PEFT方法时,考虑KV缓存的特性至关重要,以补充其优势。例如,在推理阶段应用软提示时,通过确保与提示相关的数据易于访问,可以有效地利用KV缓存来加快响应时间。
4-2 PEFT的修剪策略 Pruning Strategies for PEFT
修剪技术的引入显著提高了PEFT方法的效率。AdapterDrop通过在AdapterFusion中删除较低层的转换适配器和多任务适配器,展示了在最小化性能损失的同时提高训练和推理效率的可能性。SparseAdapter研究了不同的修剪方法,发现高稀疏率(80%)在某些情况下优于标准适配器。此外,通过增加瓶颈尺寸并保持参数预算恒定(例如,以50%的稀疏度将尺寸翻倍),可以显著增强模型的容量并提高性能。
4-3 PEFT的量化策略 Quantization Strategies for PEFT
量化是另一种提高计算效率和减少内存使用的技术。BI Adapter通过研究适配器对噪声的抵抗力,引入了一种基于聚类的量化方法。值得注意的是,他们证明了适配器的1位量化不仅最大限度地减少了存储需求,而且在所有精度设置中都实现了卓越的性能。PEQA(参数高效和量化感知自适应)采用两级流水线来实现参数高效和量化器感知微调。QA LoRA解决了QLoRA在微调后难以保持其量化特性的问题,通过使用INT4量化并引入分组运算符在推理阶段实现量化,从而提高了效率和准确性。
4-4 内存高效的PEFT方法 Memory-efficient PEFT Methods
为了提高内存效率,已经开发了多种技术,以减少在微调期间对整个LLM的缓存梯度的需求,从而降低内存使用。例如,Side-Tuning和LST(Ladder-Side Tuning)都引入了与主干模型并行的可学习网络分支。通过专门通过这个并行分支引导反向传播,避免了存储主模型权重的梯度信息的需求,显著降低了训练期间的内存需求。类似地,Res Tuning将PEFT调谐器(例如,即时调谐、适配器)与主干模型分离。基于这种分解,提出了一个名为Res-Mtuning Bypass的高效内存微调框架,该框架通过去除从解耦的调谐器到主干的数据流,生成与主干模型并行的旁路网络。


![[python] Numpy库用法(持续更新)](https://img-blog.csdnimg.cn/direct/48d12cbb283544aaa6ce837ef3dfb970.png)