目录
- 一、YOLOV5下载安装
- 二、KITTI数据集
- 三、标签格式转换
- 四、修改配置文件
- 五、训练
- 六、测试
一、YOLOV5下载安装
git clone https://github.com/ultralytics/yolov5.git
conda create -n yolov5 python=3.8 -y
conda activate yolov5
cd yolov5
pip install -r requirements.txt
二、KITTI数据集
1、简介
KITTI数据集是由 Motional 的团队开发的用于自动驾驶的公共大规模数据集。传感器在采集车上的布置如图3所示。数据采集车装配有2个灰度摄像机,2个彩色摄像机,一个Velodyne 64线3D激光雷达,4个光学镜头,以及1个GPS导航系统。

2、下载
地址:http://www.semantic-kitti.org/dataset.html#download
选择我们需要的图片与标签文件,并按照以下的目录结构放入YOLOV5在中,在yolov5/dataset下创建文件夹kitti,kiiti中放入我们的数据;标签数据暂时不放入,后面进行格式转换
|——kitti├── imgages│ ├── train│ │ ├── 00XXXA.png │ │ └── ....... │ ├── val│ │ ├── 00XXXB.png │ │ └── ....... │ └── test│ └── 00XXXC.png │ └── ....... │└── labels├── train│ ├── 00XXXA.txt │ └── ....... ├── val│ ├── 00XXXB.txt │ └── ....... └── test├── 00XXXC.txt └── .......
三、标签格式转换
kitti标签内容:000000.txt
Pedestrian 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01
yolov5中COCO标签内容: 000000000659.txt
0 0.132172 0.552259 0.118562 0.537176
0 0.249211 0.569659 0.104453 0.456165
0 0.0285469 0.491588 0.0545625 0.312024
0 0.0884609 0.379012 0.0463594 0.112612
6 0.446703 0.554741 0.554625 0.794565
0 0.165211 0.391718 0.0635781 0.0516706
0 0.165625 0.400082 0.0372188 0.130424
0 0.178945 0.354788 0.0235156 0.0436471
26 0.174266 0.664047 0.0525 0.119341
将kitti标签内容转成yolov5需要的标签,转换代码:
1、将原来的8类物体转换为我们现在需要的3类:
{‘Misc’, ‘Cyclist’, ‘Van’, ‘Pedestrian’, ‘Person_sitting’, ‘Truck’, ‘Car’, ‘DontCare’, ‘Tram’}转成{‘Car’, ‘Cyclist’, ‘Pedestrian’}
# modify_annotations_txt.py
import glob
import string
txt_list = glob.glob('H:/dataset/kitti-yolov5/labels/label_2/*.txt') # 存储Labels文件夹所有txt文件路径 注意要保留/*
def show_category(txt_list):category_list= []for item in txt_list:try:with open(item) as tdf:for each_line in tdf:labeldata = each_line.strip().split(' ') # 去掉前后多余的字符并把其分开category_list.append(labeldata[0]) # 只要第一个字段,即类别except IOError as ioerr:print('File error:'+str(ioerr))print(set(category_list)) # 输出集合
def merge(line):each_line=''for i in range(len(line)):if i!= (len(line)-1):each_line=each_line+line[i]+' 'else:each_line=each_line+line[i] # 最后一条字段后面不加空格each_line=each_line+'\n'return (each_line)
print('before modify categories are:\n')
show_category(txt_list)
for item in txt_list:new_txt=[]try:with open(item, 'r') as r_tdf:for each_line in r_tdf:labeldata = each_line.strip().split(' ')if labeldata[0] in ['Truck','Van','Tram']: # 合并汽车类labeldata[0] = labeldata[0].replace(labeldata[0],'Car')if labeldata[0] == 'Person_sitting': # 合并行人类labeldata[0] = labeldata[0].replace(labeldata[0],'Pedestrian')if labeldata[0] == 'DontCare': # 忽略Dontcare类continueif labeldata[0] == 'Misc': # 忽略Misc类continuenew_txt.append(merge(labeldata)) # 重新写入新的txt文件with open(item,'w+') as w_tdf: # w+是打开原文件将内容删除,另写新内容进去for temp in new_txt:w_tdf.write(temp)except IOError as ioerr:print('File error:'+str(ioerr))
print('\nafter modify categories are:\n')
show_category(txt_list)

2、将txt文件转换为xml文件
创建一个Annotations文件夹用于存放xml
文件夹结构
|——kitti├── imgages│ └── image_2│ ├── 000001.png │ └── ....... └── labels├── label_2│ ├── 000001.txt │ └── ....... └── xml
# kitti_txt_to_xml.py
# kitti_txt_to_xml.py
# encoding:utf-8
# 根据一个给定的XML Schema,使用DOM树的形式从空白文件生成一个XML
from xml.dom.minidom import Document
import cv2
import glob
import os
def generate_xml(name,split_lines,img_size,class_ind):doc = Document() # 创建DOM文档对象annotation = doc.createElement('annotation')doc.appendChild(annotation)title = doc.createElement('folder')title_text = doc.createTextNode('KITTI')title.appendChild(title_text)annotation.appendChild(title)img_name=name+'.jpg'title = doc.createElement('filename')title_text = doc.createTextNode(img_name)title.appendChild(title_text)annotation.appendChild(title)source = doc.createElement('source')annotation.appendChild(source)title = doc.createElement('database')title_text = doc.createTextNode('The KITTI Database')title.appendChild(title_text)source.appendChild(title)title = doc.createElement('annotation')title_text = doc.createTextNode('KITTI')title.appendChild(title_text)source.appendChild(title)size = doc.createElement('size')annotation.appendChild(size)title = doc.createElement('width')title_text = doc.createTextNode(str(img_size[1]))title.appendChild(title_text)size.appendChild(title)title = doc.createElement('height')title_text = doc.createTextNode(str(img_size[0]))title.appendChild(title_text)size.appendChild(title)title = doc.createElement('depth')title_text = doc.createTextNode(str(img_size[2]))title.appendChild(title_text)size.appendChild(title)for split_line in split_lines:line=split_line.strip().split()if line[0] in class_ind:object = doc.createElement('object')annotation.appendChild(object)title = doc.createElement('name')title_text = doc.createTextNode(line[0])title.appendChild(title_text)object.appendChild(title)bndbox = doc.createElement('bndbox')object.appendChild(bndbox)title = doc.createElement('xmin')title_text = doc.createTextNode(str(int(float(line[4]))))title.appendChild(title_text)bndbox.appendChild(title)title = doc.createElement('ymin')title_text = doc.createTextNode(str(int(float(line[5]))))title.appendChild(title_text)bndbox.appendChild(title)title = doc.createElement('xmax')title_text = doc.createTextNode(str(int(float(line[6]))))title.appendChild(title_text)bndbox.appendChild(title)title = doc.createElement('ymax')title_text = doc.createTextNode(str(int(float(line[7]))))title.appendChild(title_text)bndbox.appendChild(title)# 将DOM对象doc写入文件f = open(r'H:/dataset/kitti-yolov5/labels/xml/'+name+'.xml','w') #(1)生成的xml文件所在路径f.write(doc.toprettyxml(indent = ''))f.close()
if __name__ == '__main__':class_ind=('Pedestrian', 'Car', 'Cyclist')# cur_dir=os.getcwd()labels_dir= r"H:\dataset\kitti-yolov5\labels\label_2" #(2)txt文件所在路径# labels_dir=os.path.join(cur_dir,'label_2')for parent, dirnames, filenames in os.walk(labels_dir):# 分别得到根目录,子目录和根目录下文件for file_name in filenames:full_path=os.path.join(parent, file_name) # 获取文件全路径f=open(full_path)split_lines = f.readlines() #以行为单位读name= file_name[:-4] # 后四位是扩展名.txt,只取前面的文件名img_name=name+'.png'img_path=os.path.join('H:\dataset\kitti-yolov5\images\image_2',img_name) # (3)图片所在路径img_size=cv2.imread(img_path).shapegenerate_xml(name,split_lines,img_size,class_ind)
print('txts has converted into xmls')
3、格式的转化与数据集划分
把.xml转化为适合于yolo训练的标签模式,按照8:1:1构造数据集、测试集、验证集;将此文件放置在你的数据集根目录下
|——kitti├── imgages│ ├── train│ │ ├── 00XXXA.png │ │ └── ....... │ ├── val│ │ ├── 00XXXB.png │ │ └── ....... │ └── test│ └── 00XXXC.png │ └── ....... │└── labels├── train│ ├── 00XXXA.txt │ └── ....... ├── val│ ├── 00XXXB.txt │ └── ....... └── test├── 00XXXC.txt └── .......
# xml_to_txt_yolo.py
import xml.etree.ElementTree as ET
import os
import shutil
import randomxml_file_path = 'H:/dataset/kitti-yolov5/labels/xml/' # 检查和自己的xml文件夹名称是否一致
images_file_path = 'H:/dataset/kitti-yolov5/images/image_2/' # 检查和自己的图像文件夹名称是否一致
# 改成自己的类别名称
classes = ['Pedestrian', 'Car', 'Cyclist']
# 数据集划分比例,训练集80%,验证集10%,测试集10%
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
# 此处不要改动,只是创一个临时文件夹
if not os.path.exists('temp_labels/'):os.makedirs('temp_labels/')
txt_file_path = 'temp_labels/'def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, hdef convert_annotations(image_name):in_file = open(xml_file_path + image_name + '.xml')out_file = open(txt_file_path + image_name + '.txt', 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):# difficult = obj.find('difficult').textcls = obj.find('name').text# if cls not in classes or int(difficult) == 1:# continueif cls not in classes == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')total_xml = os.listdir(xml_file_path)
num_xml = len(total_xml) # XML文件总数for i in range(num_xml):name = total_xml[i][:-4]convert_annotations(name)# *********************************************** #
# parent folder
# --data
# ----images
# ----train
# ----val
# ----test
# ----labels
# ----train
# ----val
# ----test
def create_dir():if not os.path.exists('images/'):os.makedirs('images/')if not os.path.exists('labels/'):os.makedirs('labels/')if not os.path.exists('images/train'):os.makedirs('images/train')if not os.path.exists('images/val'):os.makedirs('images/val')if not os.path.exists('images/test'):os.makedirs('images/test/')if not os.path.exists('labels/train'):os.makedirs('labels/train')if not os.path.exists('labels/val'):os.makedirs('labels/val')if not os.path.exists('labels/test'):os.makedirs('labels/test')return# *********************************************** #
# 读取所有的txt文件
create_dir()
total_txt = os.listdir(txt_file_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_valtrain = random.sample(list_all_txt, num_train)
# train从list_all_txt取出num_train个元素
# 所以list_all_txt列表只剩下了这些元素:val_test
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
# 检查两个列表元素是否有重合的元素
# set_c = set(val_test) & set(val)
# list_c = list(set_c)
# print(list_c)
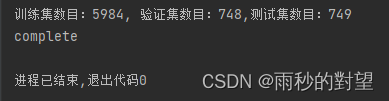
# print(len(list_c))print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:name = total_txt[i][:-4]srcImage = images_file_path + name + '.png'srcLabel = txt_file_path + name + '.txt'if i in train:dst_train_Image = 'images/train/' + name + '.png'dst_train_Label = 'labels/train/' + name + '.txt'shutil.copyfile(srcImage, dst_train_Image)shutil.copyfile(srcLabel, dst_train_Label)elif i in val:dst_val_Image = 'images/val/' + name + '.png'dst_val_Label = 'labels/val/' + name + '.txt'shutil.copyfile(srcImage, dst_val_Image)shutil.copyfile(srcLabel, dst_val_Label)else:dst_test_Image = 'images/test/' + name + '.png'dst_test_Label = 'labels/test/' + name + '.txt'shutil.copyfile(srcImage, dst_test_Image)shutil.copyfile(srcLabel, dst_test_Label)
print("complete")
四、修改配置文件
1、修改数据集配置文件
将data目录下的coco128.yaml复制一份修改为kitti.yaml;修改内容如下:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
#path: ../dataset/kitti # dataset root dir
train: /home/mengwen/yolov5/dataset/kitti/images/train # train images (relative to 'path') 128 images
val: /home/mengwen/yolov5/dataset/kitti/images/val # val images (relative to 'path') 128 images
test: /home/mengwen/yolov5/dataset/kitti/images/test # test images (optional)# Classes
names:0: Pedestrian1: Car2: Cyclist# Download script/URL (optional)
#download: https://ultralytics.com/assets/coco128.zip
2、修改models配置文件
修改nc(类别数量)
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 3 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10, 13, 16, 30, 33, 23] # P3/8- [30, 61, 62, 45, 59, 119] # P4/16- [116, 90, 156, 198, 373, 326] # P5/32
3、修改训练文件train.py
def parse_opt(known=False):"""Parses command-line arguments for YOLOv5 training, validation, and testing."""parser = argparse.ArgumentParser()parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")parser.add_argument("--cfg", type=str, default="models/yolov5s.yaml", help="model.yaml path")parser.add_argument("--data", type=str, default=ROOT / "data/kitti.yaml", help="dataset.yaml path")parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")parser.add_argument("--epochs", type=int, default=100, help="total training epochs")parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch")parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="train, val image size (pixels)")parser.add_argument("--rect", action="store_true", help="rectangular training")parser.add_argument("--resume", nargs="?", const=True, default=False, help="resume most recent training")parser.add_argument("--nosave", action="store_true", help="only save final checkpoint")parser.add_argument("--noval", action="store_true", help="only validate final epoch")parser.add_argument("--noautoanchor", action="store_true", help="disable AutoAnchor")parser.add_argument("--noplots", action="store_true", help="save no plot files")parser.add_argument("--evolve", type=int, nargs="?", const=300, help="evolve hyperparameters for x generations")parser.add_argument("--evolve_population", type=str, default=ROOT / "data/hyps", help="location for loading population")
epochs: 指的就是训练过程中整个数据集将被迭代多少次,显卡不行你就调小点。
batch-size: 一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点。
cfg: 存储模型结构的配置文件
data: 存储训练、测试数据的文件
img-size: 输入图片宽高,显卡不行你就调小点。
rect: 进行矩形训练
resume: 恢复最近保存的模型开始训练
nosave: 仅保存最终checkpoint
notest: 仅测试最后的epoch
evolve: 进化超参数
bucket: gsutil bucket
cache-images: 缓存图像以加快训练速度
weights: 权重文件路径
name: 重命名results.txt to results_name.txt
device: cuda device, i.e. 0 or 0,1,2,3 or cpu
adam: 使用adam优化
multi-scale: 多尺度训练,img-size +/- 50%
single-cls: 单类别的训练集
五、训练
1、训练指令
python train.py --img 640 --batch 16 --epoch 100 --data data/kitti.yaml --cfg models/yolov5s.yaml --weights yolov5s.pt --device '0'

2、效果
1)结果统计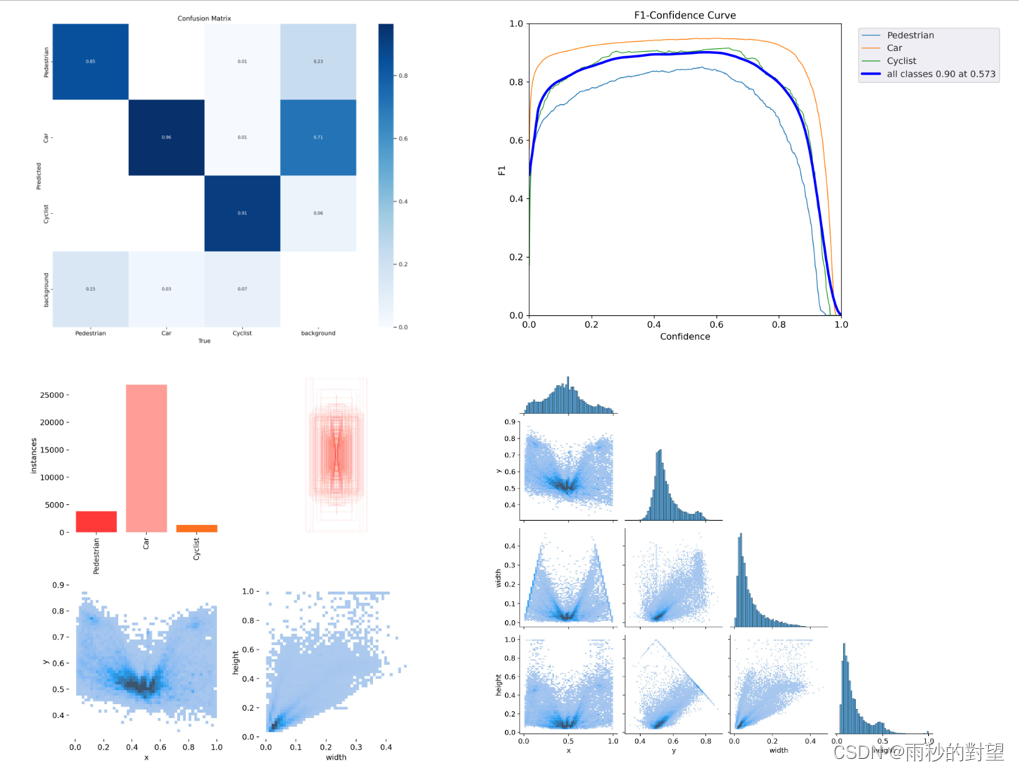
2)val_batch0_labels

六、测试
1、修改detect.py
@smart_inference_mode()
def run(weights=ROOT / "runs/train/exp4/weights/best.pt", # model path or triton URLsource=ROOT / "classify/data/videos", # file/dir/URL/glob/screen/0(webcam)data=ROOT / "data/kitti.yaml", # dataset.yaml pathimgsz=(640, 640), # inference size (height, width)conf_thres=0.25, # confidence thresholdiou_thres=0.45, # NMS IOU thresholdmax_det=1000, # maximum detections per imagedevice="", # cuda device, i.e. 0 or 0,1,2,3 or cpuview_img=False, # show resultssave_txt=False, # save results to *.txtsave_csv=False, # save results in CSV formatsave_conf=False, # save confidences in --save-txt labelssave_crop=False, # save cropped prediction boxesnosave=False, # do not save images/videosclasses=None, # filter by class: --class 0, or --class 0 2 3agnostic_nms=False, # class-agnostic NMSaugment=False, # augmented inferencevisualize=False, # visualize featuresupdate=False, # update all modelsproject=ROOT / "runs/detect", # save results to project/namename="exp", # save results to project/nameexist_ok=False, # existing project/name ok, do not incrementline_thickness=3, # bounding box thickness (pixels)hide_labels=False, # hide labelshide_conf=False, # hide confidenceshalf=False, # use FP16 half-precision inferencednn=False, # use OpenCV DNN for ONNX inferencevid_stride=1, # video frame-rate stride
):
...
def parse_opt():"""Parses command-line arguments for YOLOv5 detection, setting inference options and model configurations."""parser = argparse.ArgumentParser()parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "runs/train/exp4/weights/best.pt", help="model path or triton URL")parser.add_argument("--source", type=str, default=ROOT / "/home/mengwen/yolov5/classify/data/videos", help="file/dir/URL/glob/screen/0(webcam)")parser.add_argument("--data", type=str, default=ROOT / "data/kitti.yaml", help="(optional) dataset.yaml path")parser.add_argument("--imgsz", "--img", "--img-size", nargs="+", type=int, default=[640], help="inference size h,w")parser.add_argument("--conf-thres", type=float, default=0.25, help="confidence threshold")parser.add_argument("--iou-thres", type=float, default=0.45, help="NMS IoU threshold")parser.add_argument("--max-det", type=int, default=1000, help="maximum detections per image")parser.add_argument("--device", default="", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")parser.add_argument("--view-img", action="store_true", help="show results")parser.add_argument("--save-txt", action="store_true", help="save results to *.txt")parser.add_argument("--save-csv", action="store_true", help="save results in CSV format")parser.add_argument("--save-conf", action="store_true", help="save confidences in --save-txt labels")parser.add_argument("--save-crop", action="store_true", help="save cropped prediction boxes")parser.add_argument("--nosave", action="store_true", help="do not save images/videos")parser.add_argument("--classes", nargs="+", type=int, help="filter by class: --classes 0, or --classes 0 2 3")parser.add_argument("--agnostic-nms", action="store_true", help="class-agnostic NMS")parser.add_argument("--augment", action="store_true", help="augmented inference")parser.add_argument("--visualize", action="store_true", help="visualize features")parser.add_argument("--update", action="store_true", help="update all models")parser.add_argument("--project", default=ROOT / "runs/detect", help="save results to project/name")parser.add_argument("--name", default="exp", help="save results to project/name")parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")parser.add_argument("--line-thickness", default=3, type=int, help="bounding box thickness (pixels)")parser.add_argument("--hide-labels", default=False, action="store_true", help="hide labels")parser.add_argument("--hide-conf", default=False, action="store_true", help="hide confidences")parser.add_argument("--half", action="store_true", help="use FP16 half-precision inference")parser.add_argument("--dnn", action="store_true", help="use OpenCV DNN for ONNX inference")parser.add_argument("--vid-stride", type=int, default=1, help="video frame-rate stride")opt = parser.parse_args()opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expandprint_args(vars(opt))return opt
2、视频效果
1)视频截取:
import numpy as np
import cv2
import os
import timeSTART_HOUR = 0
START_MIN = 0
START_SECOND = 36
START_TIME = START_HOUR * 3600 + START_MIN * 60 + START_SECOND # 设置开始时间(单位秒)
END_HOUR = 0
END_MIN = 0
END_SECOND = 50
END_TIME = END_HOUR * 3600 + END_MIN * 60 + END_SECOND # 设置结束时间(单位秒)video = "E:/044_2M_20230306_172207_ningxia_yinchuan_0B_0_5.mp4"
cap = cv2.VideoCapture(video)
FPS = cap.get(cv2.CAP_PROP_FPS)
print(FPS)
FPS = 10
# size = (cap.get(cv2.CAP_PROP_FRAME_WIDTH), cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
size = (1920,1080)
print(size)
TOTAL_FRAME = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数
frameToStart = START_TIME * FPS # 开始帧 = 开始时间*帧率
print(frameToStart)
frametoStop = END_TIME * FPS # 结束帧 = 结束时间*帧率
print(frametoStop)
videoWriter =cv2.VideoWriter('E:/video/video1.avi',cv2.VideoWriter_fourcc('X','V','I','D'),FPS,size)# cap.set(cv2.CAP_PROP_POS_FRAMES, frameToStart) # 设置读取的位置,从第几帧开始读取视频
COUNT = 0
while True:success, frame = cap.read()if success:COUNT += 1if COUNT <= frametoStop and COUNT > frameToStart: # 选取起始帧print('correct= ', COUNT)videoWriter.write(frame)# print('mistake= ', COUNT)if COUNT > frametoStop:break
print('end')
2)效果
video1







![[大模型]Qwen1.5-4B-Chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/3d5a75cd6f444f10a3132c442ba19ebb.png#pic_center)

