Zookeeper的集群搭建
1)zk集群中的角色
Zookeeper集群中的节点有三个角色:
- Leader:处理集群的所有事务请求,集群中只有一个Leader
- Follwoer:只能处理读请求,参与Leader选举
- Observer:只能处理读请求,提升集群读的性能,但不能参与Leader选举

2)搭建zk集群
- 创建4个节点的myid,并设值
在/usr/local/zookeeper中创建以下四个文件/usr/local/zookeeper/zkdata/zk1# echo 1 > myid /usr/local/zookeeper/zkdata/zk2# echo 2 > myid /usr/local/zookeeper/zkdata/zk3# echo 3 > myid /usr/local/zookeeper/zkdata/zk4# echo 4 > myid - 编写四个zoo.cfg文件,并修改zoox.cfg文件中的配置
修改clientPort,cp zoo.cfg zoox.cfgserver.<id>=<ip>:<port>:<port>
并设置其中一个为zookeeper服务端的角色为observer
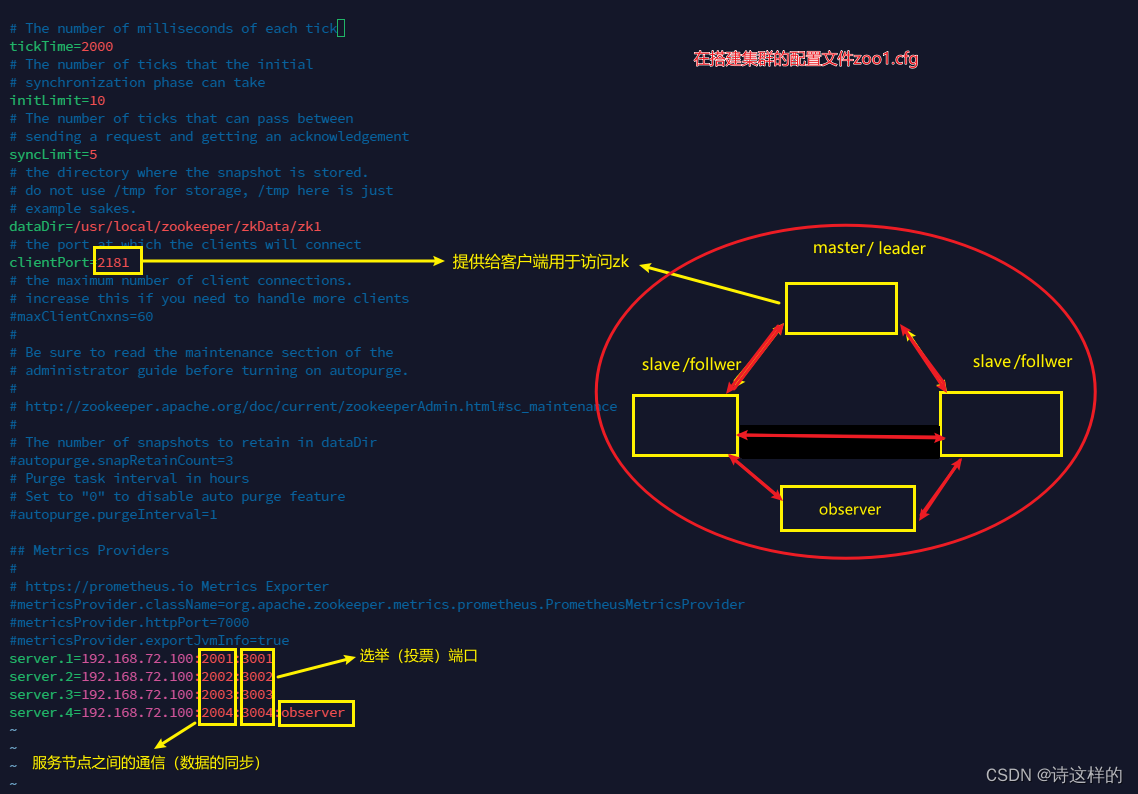
- 启动4台zookeeper
./bin/zkServer.sh start ../conf/zoox.cfg - 查看主从节点的状态
./bin/zkServer.sh status ../conf/zoox.cfg
注意:这里我是先启动的zoo2.cfg,因为一些原因zoo1.cfg启动失败了🥲,所以最后才启动的zoo1.cfg。 - 连接Zookeeper集群
./zkCli.sh -server 192.160.72.100:2181,192.160.72.100:2182,192.160.72.100:2183,192.160.72.100:2184
ZAB协议
zookeeper作为非常重要的分布式协调组件,需要进行集群部署,集群中会以一主多从的形式进行部署。zookeeper为了保证数据的一致性,使用了ZAB(Zookeeper Atomic Broadcast)协议,这个协议解决了Zookeeper的崩溃恢复和主从数据同步的问题。
1)ZAB协议的四种节点状态
- Looking:选举状态
- Following:Following节点(从节点)所处的状态
- Leading:Leader节点(主节点)所处状态
- Observing:观察者节点所处的状态
2)Leader选举的过程
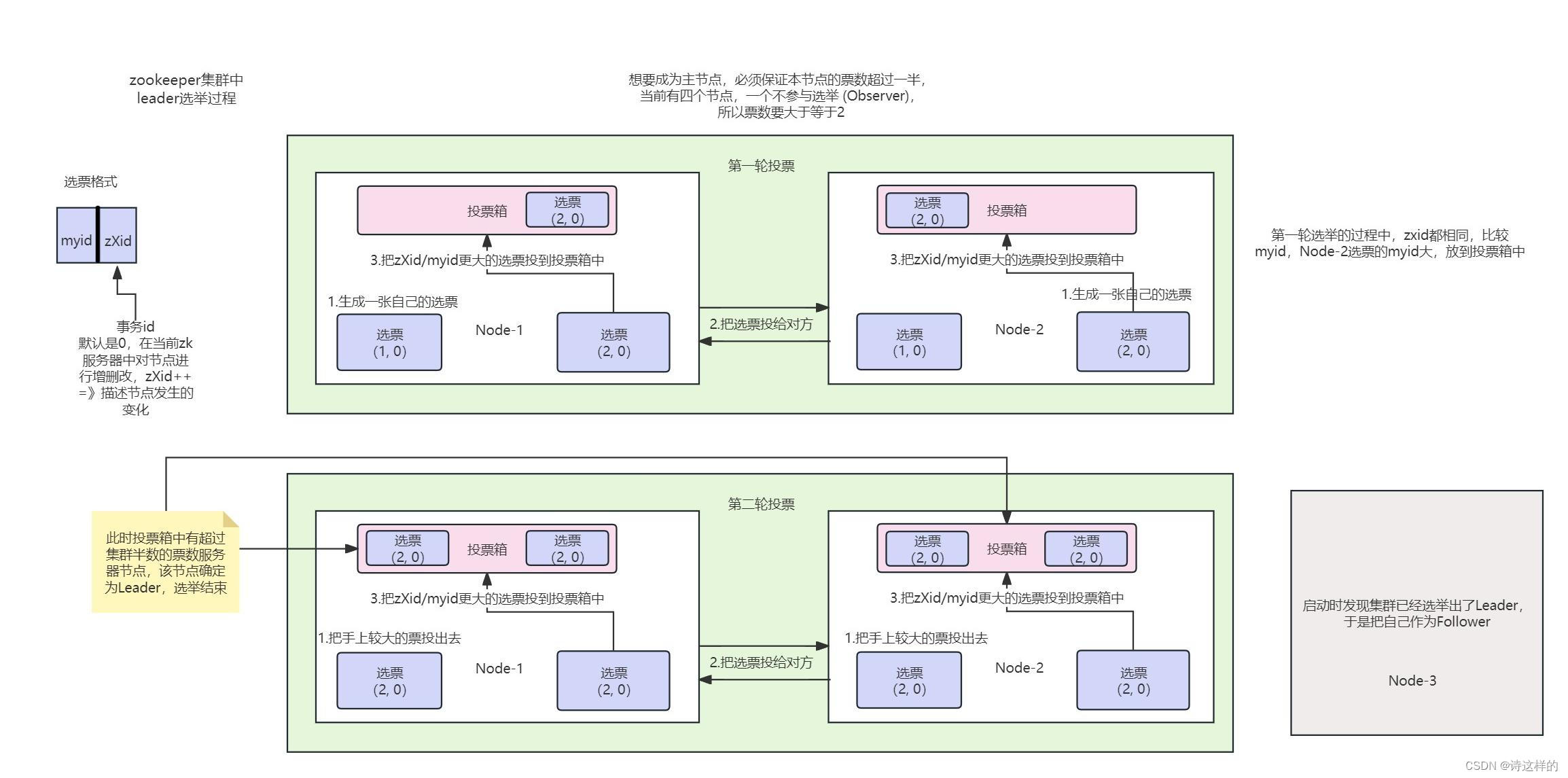
查看原始图片
一般设置非Observer服务器的个数为奇数个。
3)崩溃恢复时的Leader选举
Leader建立完后,Leader周期性地不断向Follower发送心跳(建立socket发送ping命令)。当Leader崩溃后,Follower发现socket通道已关闭,于是Follower开始进入到Looking(选举)状态,重新回到上一节中的Leader选举状态(BIO),此时集群不能对外提供服务。
类似于 Redis 中的哨兵机制
4)主从服务器之间的数据同步
客户端想实现写操作,但是连接的是从节点,那么由从节点把数据发送给主节点,由主节点负责数据的所有写操作,读操作直接由当前连接节点处理。
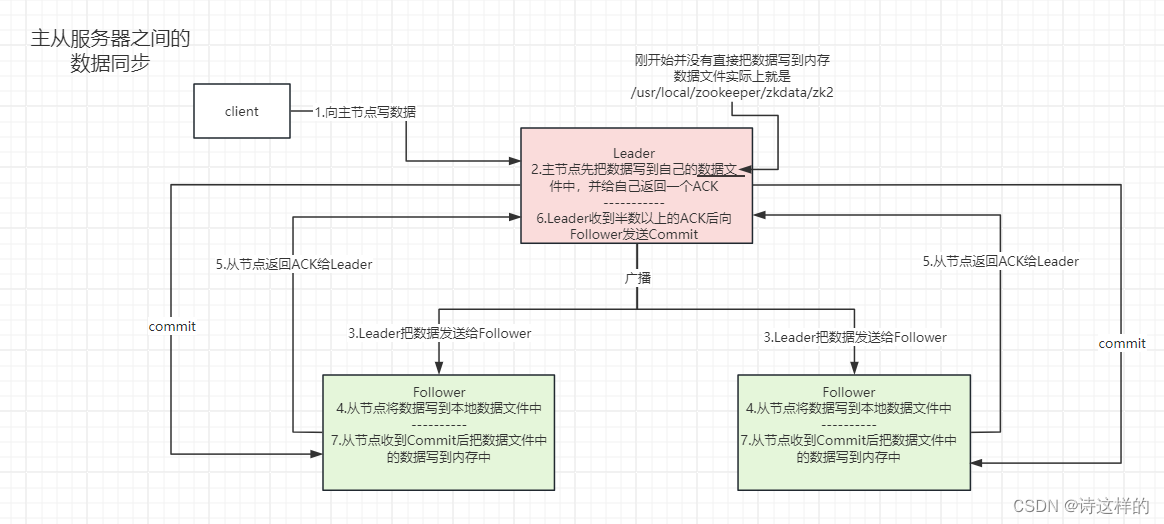
两阶段提交
5)Zookeeper中的NIO与BIO的应用
- NIO
- 用于被客户端连接的2181端口,使用的是NIO模式与客户端建立连接
- 客户端开启Watch时,也使用NIO,等待Zookeeper服务器的回调
- BIO
- 集群在选举时,多个节点之间的投票通信端口,使用BIO进行通信

![[大模型]Qwen1.5-4B-Chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/3d5a75cd6f444f10a3132c442ba19ebb.png#pic_center)