
MySQL索引、B+树相关知识汇总
- 一、有一个查询需求,MySQL中有两个表,一个表1000W数据,另一个表只有几千数据,要做一个关联查询,如何优化?
- 1、为关联字段建立索引
- 二、小表驱动大表
- 二、b树和b+树的区别
- 1、更高的查询效率
- 2、更高的空间利用率
- 3、查询效率更稳定
- 三、innodb使用数据页存储数据?默认数据页大小16K,我现在有一张表,有2kw数据,我这个b+树的高度有几层?
- 四、redis为什么快?
- 1、基于内存的数据存储
- 2、单线程模型
- 3、IO多路复用
- 4、高效的数据结构
- 五、建立联合索引(a,b,c),where c = 5是否会用到索引?为什么?
一、有一个查询需求,MySQL中有两个表,一个表1000W数据,另一个表只有几千数据,要做一个关联查询,如何优化?
如果 orders 表是大表(比如 1000 万条记录),而 users 表是相对较小的表(比如几千条记录)。
1、为关联字段建立索引
确保两个表中用于 JOIN 操作的字段都有索引。这是最基本的优化策略,避免数据库进行全表扫描,可以大幅度减少查找匹配行的时间。

二、小表驱动大表
在执行 JOIN 操作时,先过滤小表中的数据,这样可以减少后续与大表进行 JOIN 时需要处理的数据量,从而提高查询效率。
二、b树和b+树的区别
B+ 树相比较 B 树,有这些优势:
1、更高的查询效率
B+树的所有值(数据记录或指向数据记录的指针)都存在于叶子节点,并且叶子节点之间通过指针连接,形成一个有序链表。

这种结构使得 B+树非常适合进行范围查询,一旦到达了范围的开始位置,接下来的元素可以通过遍历叶子节点的链表顺序访问,而不需要回到树的上层。如 SQL 中的 ORDER BY 和 BETWEEN 查询。
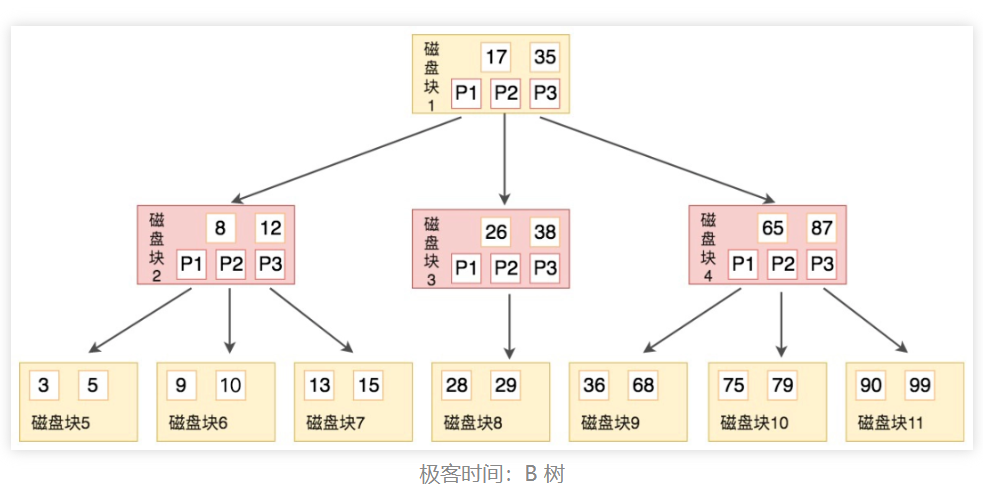
而 B 树的数据分布在整个树中,进行范围查询时可能需要遍历树的多个层级。
2、更高的空间利用率
在 B+树中,非叶子节点不存储数据,只存储键值,这意味着非叶子节点可以拥有更多的键,从而有更多的分叉。
这导致树的高度更低,进一步降低了查询时磁盘 I/O 的次数,因为每一次从一个节点到另一个节点的跳转都可能涉及到磁盘 I/O 操作。
3、查询效率更稳定
B+树中所有叶子节点深度相同,所有数据查询路径长度相等,保证了每次搜索的性能稳定性。而在 B 树中,数据可以存储在内部节点,不同的查询可能需要不同深度的搜索。
三、innodb使用数据页存储数据?默认数据页大小16K,我现在有一张表,有2kw数据,我这个b+树的高度有几层?
在 MySQL 中,InnoDB 存储引擎的最小存储单元是页,默认大小是16k
如果有 2KW 条数据,那么这颗 B+树的高度为 3 层。
四、redis为什么快?
1、基于内存的数据存储
Redis 将数据存储在内存当中,使得数据的读写操作避开了磁盘 I/O。而内存的访问速度远超硬盘,这是 Redis 读写速度快的根本原因。
2、单线程模型
Redis 使用单线程模型来处理客户端的请求,这意味着在任何时刻只有一个命令在执行。这样就避免了线程切换和锁竞争带来的消耗。
3、IO多路复用
Redis 单个线程处理多个 IO 读写的请求。
4、高效的数据结构
Redis 提供了多种高效的数据结构,如字符串(String)、列表(List)、集合(Set)、有序集合(Sorted Set)等,这些数据结构经过了高度优化,能够支持快速的数据操作。
五、建立联合索引(a,b,c),where c = 5是否会用到索引?为什么?
在这个查询中,只有索引的第三列 c 被用作查询条件,而前两列 a 和 b 没有被使用。这不符合最左前缀原则,因此 MySQL 不会使用联合索引 (a,b,c)。
1、对empname,deptid,jobs3列建立索引语句:
create index idx_t1_bcd on employees(empname,deptid,jobs)
2、EXPLAIN select * from employees where jobs=“测试经理” ,没有使用索引

3、EXPLAIN select * from employees where deptid=“1003” ,没有使用索引

4、EXPLAIN select * from employees where empname=“张飞” 使用了索引

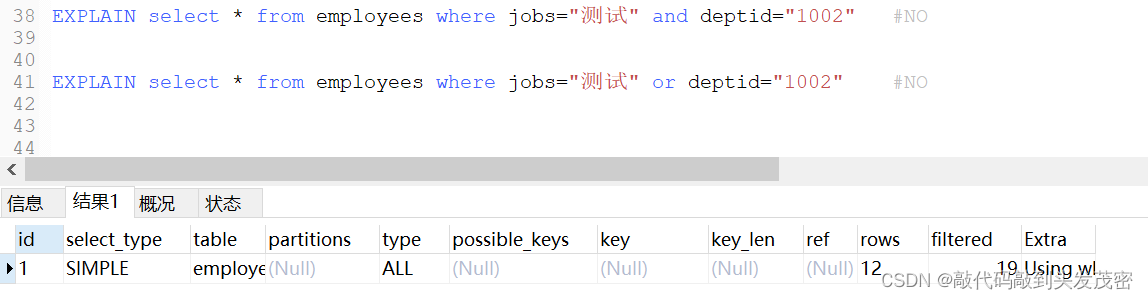
5、EXPLAIN select * from employees where jobs=“测试” and deptid=“1002”
没有使用索引
6、EXPLAIN select * from employees where jobs=“测试” or deptid=“1002”
没有使用索引
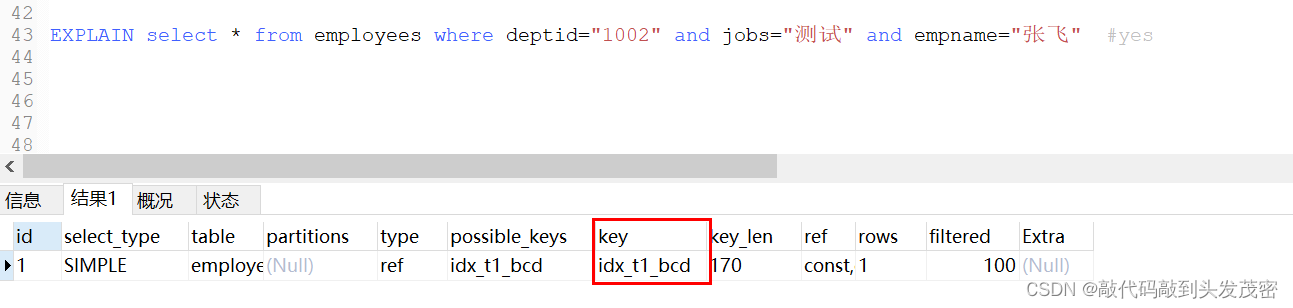
7、EXPLAIN select * from employees where deptid=“1002” and jobs=“测试” and empname=“张飞” 使用了索引
8、EXPLAIN select * from employees where deptid=“1002” or jobs=“测试” or empname=“张飞” 不使用索引

9、EXPLAIN select * from employees where deptid=“1002” and jobs=“测试” and empname LIKE “%飞”;不使用索引

10、EXPLAIN select * from employees where deptid LIKE “%002” and jobs=“测试” and empname = “张飞”;使用了索引









![Missing artifact org.opencv:opencv:jar:4.10.0 [opencv-4.10.0.jar]](https://img-blog.csdnimg.cn/direct/57b50d1e93a44feea9b45303326310ea.png)



