目录
基本代码
prompt模块
prompt模版控制长度
outputparse格式化输出
并行使用调用链
LangChain表达式语言,或者LCEL,是一种声明式的方式,可以轻松地将链条组合在一起
langchian 可以使用 通义千问,我们用通义千问,用法也要申请 api:通义千问API如何使用_模型服务灵积(DashScope)-阿里云帮助中心
然后再代码目录创建一个 .env 文件,用来保存 api-key,例如
DASHSCOPE_API_KEY=sk-xxxxxxxxxx
这样就可以用了,就不需要官网默认示例的 openai 了,那个比较麻烦。
基本代码
import os
from dotenv import load_dotenv
from langchain_community.llms import Tongyi
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParserload_dotenv('key.env') # 指定加载 env 文件
key = os.getenv('DASHSCOPE_API_KEY') # 获得指定环境变量
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"] # 获得指定环境变量model = Tongyi(temperature=1)
# 设定系统上下文,构建提示词
template = """请扮演一位资深的技术博主,您将负责为用户生成适合在微博发送的中文帖文。
请把用户输入的内容扩展成 140 字左右的文字,并加上适当的 emoji 使内容引人入胜并专业。"""# 创建提示词对象,用于显示给用户的最终提示
prompt = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")])# 通过 LCEL 构建调用链并执行得到文本输出
# StrOutputParser() 模型对象的输出转为字符串
chain = prompt | model | StrOutputParser()
res = chain.invoke({"input": "给大家推荐一本新书《LangChain实战》,让我们一起开始来学习 LangChain 吧!"})
print(res)

prompt模块
上面的提示词不带参数,我们使用 langchain 的 prompt 模块来做一个带参数的提示词
import os
from dotenv import load_dotenv
from langchain_community.llms import Tongyi
from langchain_core.prompts import ChatPromptTemplateload_dotenv('key.env') # 指定加载 env 文件
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"] # 获得指定环境变量
prompt = ChatPromptTemplate.from_template("请编写一篇关于{topic}的中文小故事,不超过100字")
model = Tongyi(temperature=1)
chain = prompt | model
res = chain.invoke({"topic": "小白兔"})
print(res)

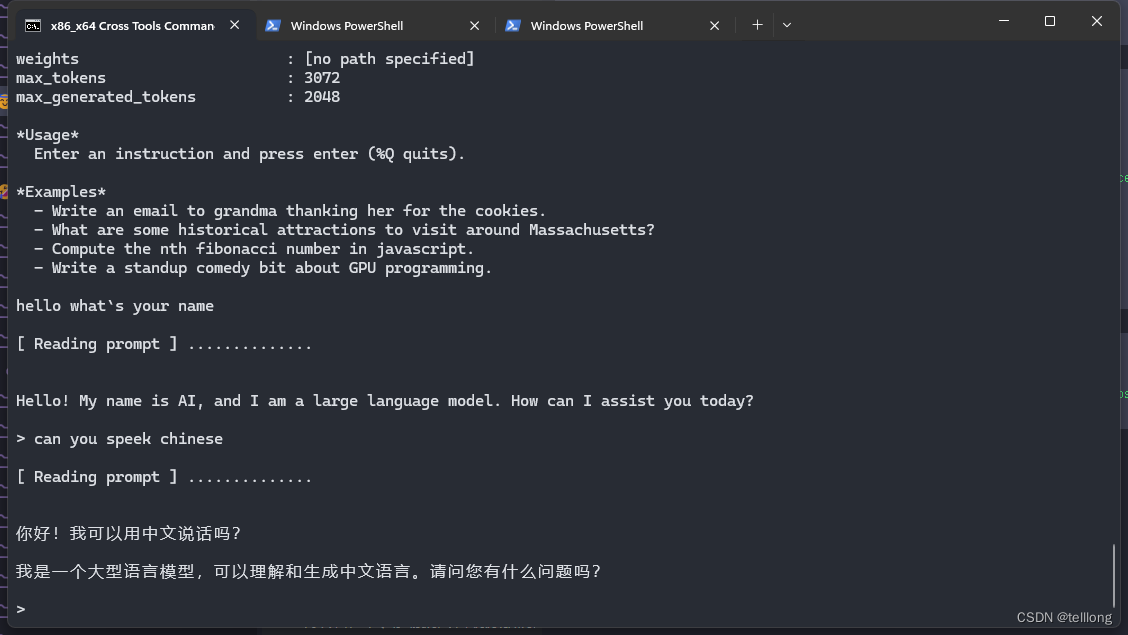
对话提示词模版
import os
from dotenv import load_dotenv
load_dotenv('key.env') # 指定加载 env 文件
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"] # 获得指定环境变量from langchain_core.prompts import ChatPromptTemplatechat_template = ChatPromptTemplate.from_messages([("system", "You are a helpful AI bot. Your name is {name}."),("human", "Hello, how are you doing?"),("ai", "I'm doing well, thanks!"),("human", "{user_input}"),]
)
res = chat_template.format_messages(name="Bob", user_input="What is your name?")
print(res)

prompt模版控制长度
示例选择器
可以根据用户输入的长度,输入较长选择更多示例,输入较短选择更少示例
import os
from dotenv import load_dotenv
load_dotenv('key.env') # 指定加载 env 文件
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"] # 获得指定环境变量from langchain_core.prompts import PromptTemplate
from langchain_core.prompts import FewShotPromptTemplate
from langchain.prompts.example_selector import LengthBasedExampleSelector# 创建一些反义词输入输出的示例内容
examples = [{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"},{"input": "energetic", "output": "lethargic"},{"input": "sunny", "output": "gloomy"},{"input": "windy", "output": "calm"},
]example_prompt = PromptTemplate(input_variables=["input", "output"],template="Input: {input}\nOutput: {output}",
)
example_selector = LengthBasedExampleSelector(examples=examples,example_prompt=example_prompt,# 设定期望的示例文本长度max_length=25
)
dynamic_prompt = FewShotPromptTemplate(example_selector=example_selector,example_prompt=example_prompt,# 设置示例以外部分的前置文本prefix="Give the antonym of every input",# 设置示例以外部分的后置文本suffix="Input: {adjective}\nOutput:\n\n",input_variables=["adjective"],
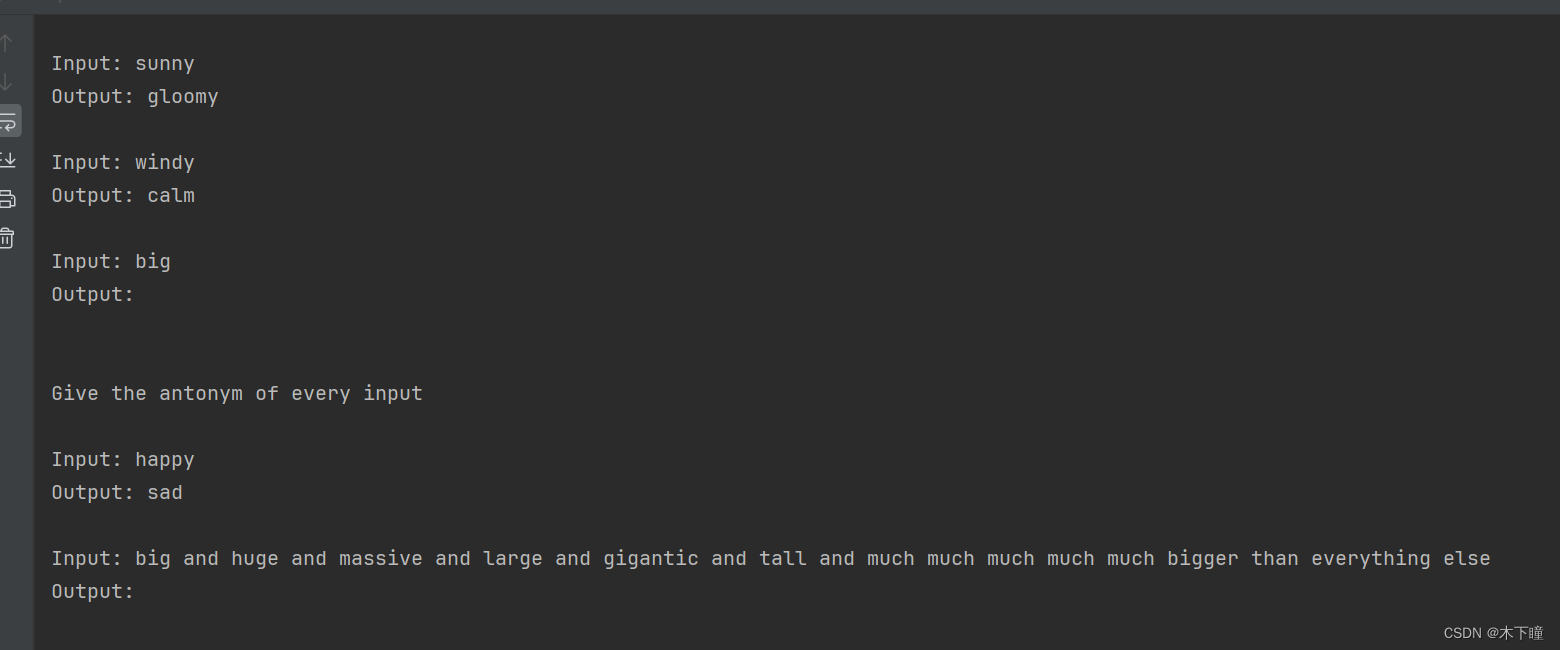
)# 当用户输入的内容比较少时,所有示例都足够被使用
print(dynamic_prompt.format(adjective="big"))# 当用户输入的内容足够长时,只有少量示例会被引用
long_string = "big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else"
print(dynamic_prompt.format(adjective=long_string))
outputparse格式化输出
使用 PydanticOutputParser 控制输出格式
from typing import Listfrom langchain_core.prompts import PromptTemplate
from langchain_community.llms.ollama import Ollama
from langchain.output_parsers import PydanticOutputParser
from langchain.pydantic_v1 import BaseModel, Fieldclass Actor(BaseModel):name: str = Field(description="name of an author")book_names: List[str] = Field(description="list of names of book they wrote")actor_query = "随机生成一位知名的作家及其代表作品"parser = PydanticOutputParser(pydantic_object=Actor)prompt = PromptTemplate(template="请回答下面的问题:\n{query}\n\n{format_instructions}\n如果输出是代码块,请不要包含首尾的```符号",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)input = prompt.format_prompt(query=actor_query)
print(input)model = Ollama(model="llama2-chinese:13b")
output = model(input.to_string())print(output)
parser.parse(output)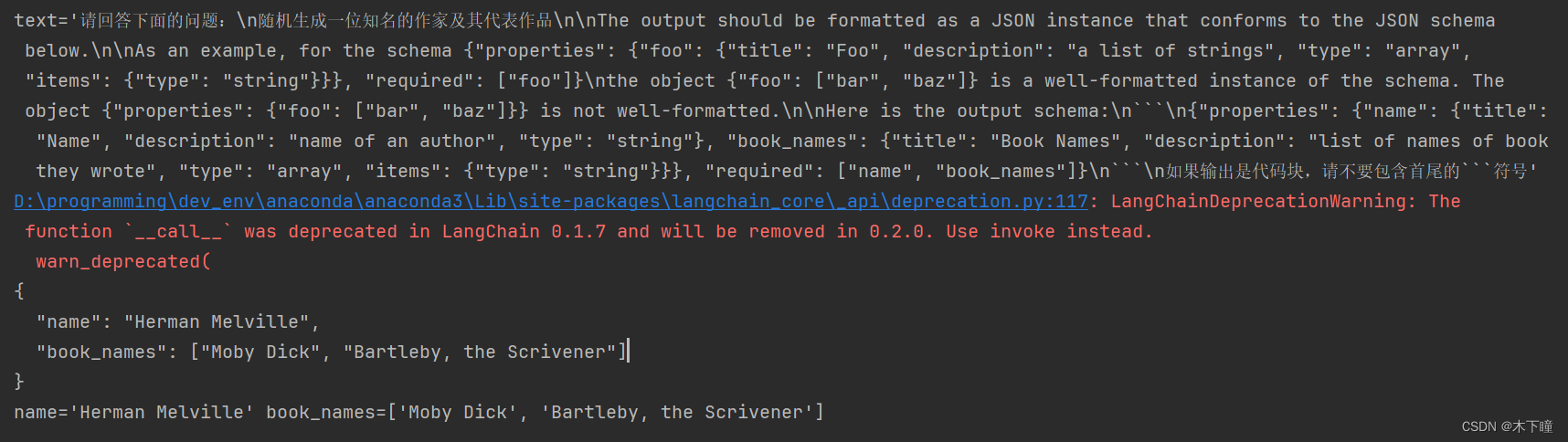
并行使用调用链
import os
from dotenv import load_dotenv
from langchain_community.llms import Tongyi
load_dotenv('key.env') # 指定加载 env 文件
key = os.getenv('DASHSCOPE_API_KEY') # 获得指定环境变量
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"] # 获得指定环境变量
model = Tongyi(temperature=1)from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParalleljoke_chain = ChatPromptTemplate.from_template("讲一句关于{topic}的笑话") | model
poem_chain = ChatPromptTemplate.from_template("写一首关于{topic}的短诗") | model# 通过 RunnableParallel(也可以叫做 RunnableMap)来并行执行两个调用链
map_chain = RunnableParallel(joke=joke_chain, poem=poem_chain)
print(map_chain.invoke({"topic": "小白兔"}))



![[论文翻译]GLU Variants Improve Transformer](https://img-blog.csdnimg.cn/img_convert/1d13469c0f3bd71da30743358699a7f2.png)