实验2 基于RFM分析的客户分群
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊!
喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!"
一、实验目的
1掌握RFM分析方法和k-means聚类的方法,能够进行价值识别
2掌握Python 聚类的方法
3.EM聚类(基于高斯混合模型的EM聚类)
二、知识准备
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在客户分类中,RFM模型是一个经典的分类模型,利用通用交易环节中最核心的三个维度——最近消费(Recency)、消费频率(Frequency)、消费金额(Monetary)细分客户群体,从而分析不同群体的客户价值。
三、实验准备
1.使用算法:RFM模型、聚类算法
2. 数据来源
RFM数据集为英国在线零售商在2010年12月1日至2011年12月9日间发生的所有网络交易订单信息。该公司主要销售礼品为主,并且多数客户为批发商。
数据集介绍及来源:
https://www.kaggle.com/carrie1/ecommerce-data
https://archive.ics.uci.edu/ml/datasets/online+retail#
特征说明:
InvoiceNo:订单编号,由六位数字组成,退货订单编号开头有字母C
StockCode:产品编号,由五位数字组成
Description:产品描述
Quantity:产品数量,负数表示退货
InvoiceDate:订单日期与时间
UnitPrice :单价(英镑)
CustomerID:客户编号,由5位数字组成
Country:国家2. 操作环境
"This is a transnational data set which contains all the transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based and registered non-store online retail.The company mainly sells unique all-occasion gifts. Many customers of the company are wholesalers."
3.后续学习:客户分类
Customer Segmentation | Kaggle
四、实验步骤
1、提出问题,确定目标
对。。。。。客户数据,探讨如何利用KMeans算法(EM聚类)对客户群体进行细分,以及细分后如何利用RFM模型对客户价值进行分析,并识别出高价值客户。主要希望实现以下三个目标:
1)对客户进行群体分类
2)对不同的客户群体进行特征分析,比较各细分群体的客户价值
3)对不同价值的客户制定相应的运营策略
2、数据获取

3、数据预处理
数据清洗:缺失值,异常值
变量转换、属性规约、标准化处理等
(1)删除重复值

(2)查看缺失值比例

(3)删除缺失值严重的列
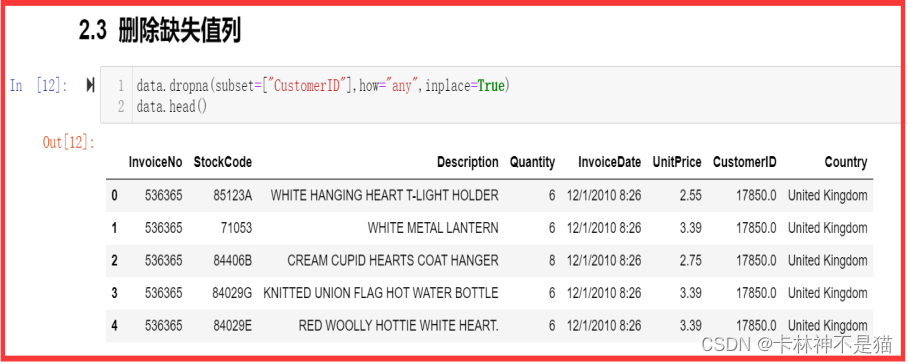
(4)删除订单异常值
根据官网https://www.kaggle.com数据介绍,InvoiceNo如果前缀是C,则表示退单号,且此时的Quantity(数量)是负数,因此需要删除这些数据!

(5)属性规约


(6)变量转换
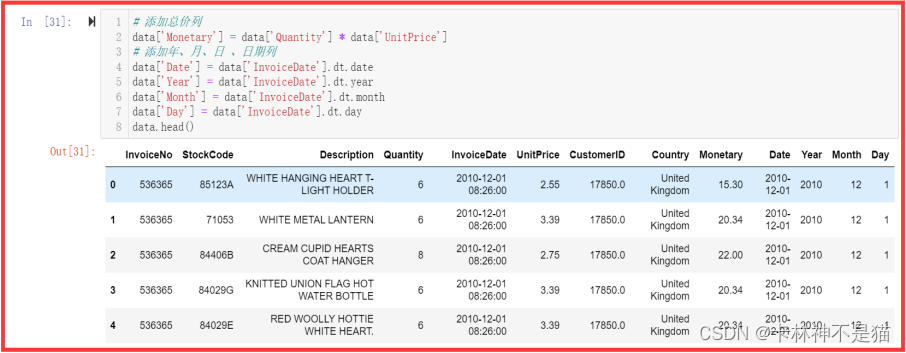
(7)RFM——计算逻辑
R:最近一次购买时间R(Recency)
F:购买频率F(Frequency)
M:购买金额M(Money)



4、数据探索性分析(可视化显示)
(1)RFM-数量-季度,三维分析


(2)RFM组别数量关系



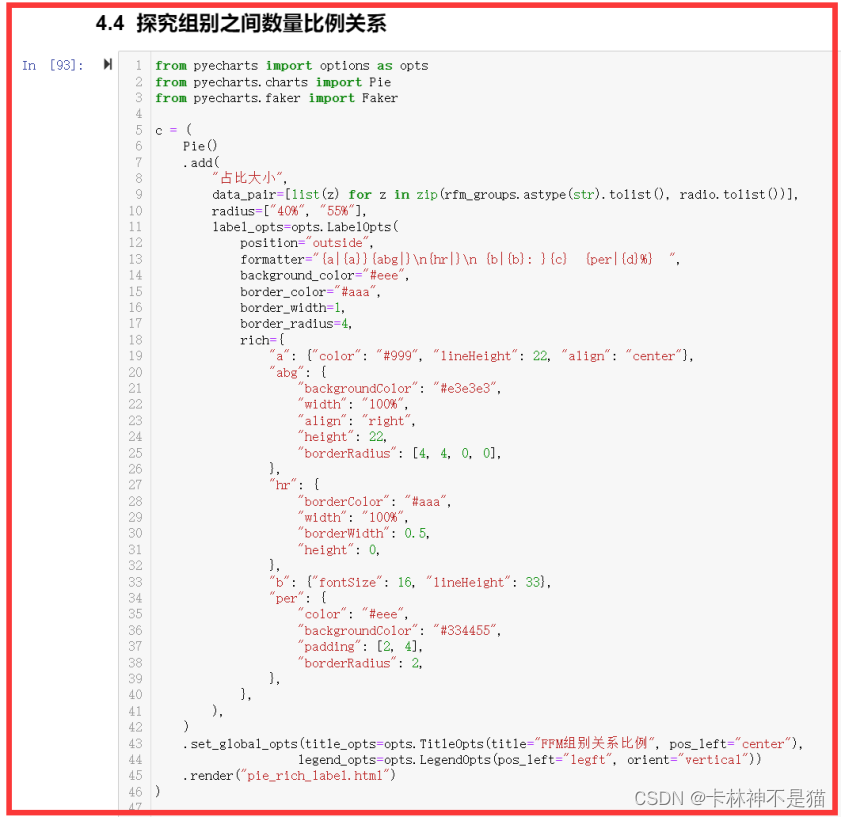
(3)RFM组别比例关系

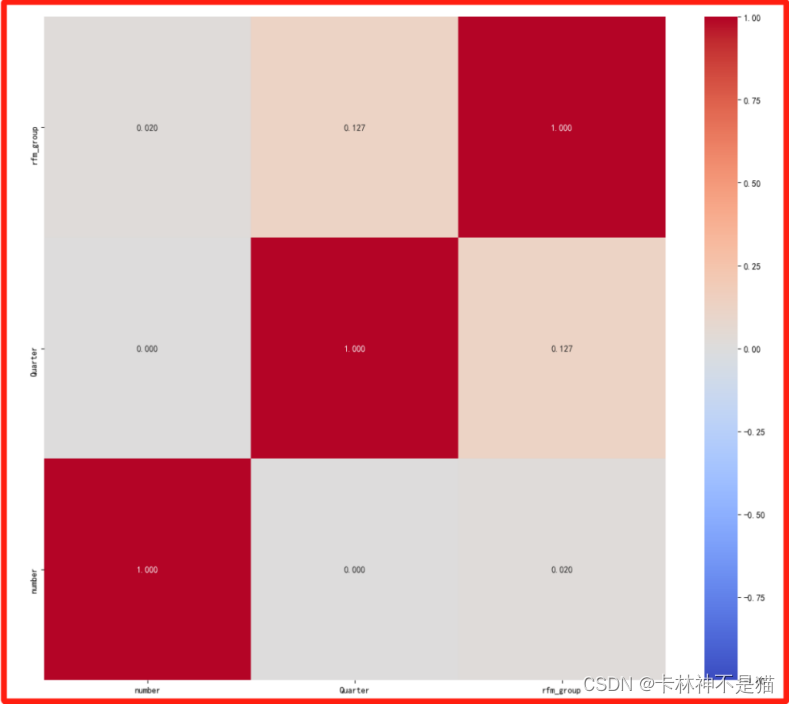
(4)RFM字段相关性系数

5、建立模型和评价模型(聚成几类,效果好),聚类可视化
(1)数据提取

(2)数据标准化
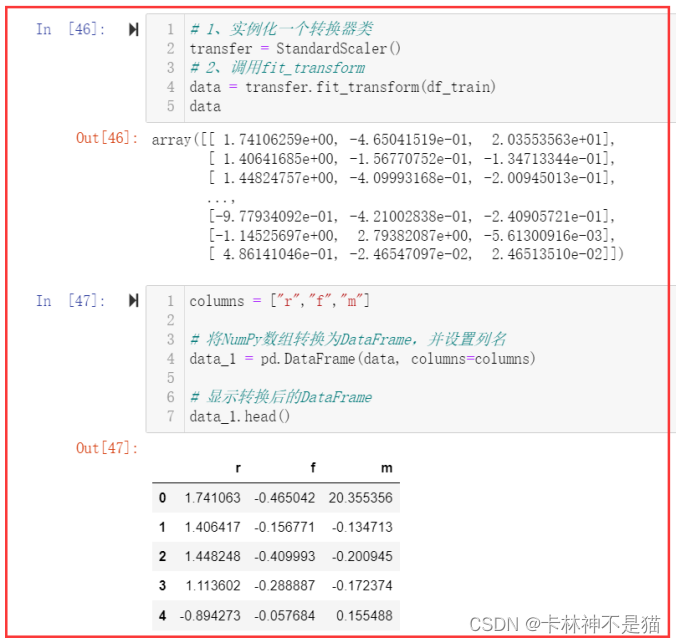
(3)肘部法确定k值

(4)建立模型和评估模型

(5)聚类可视化
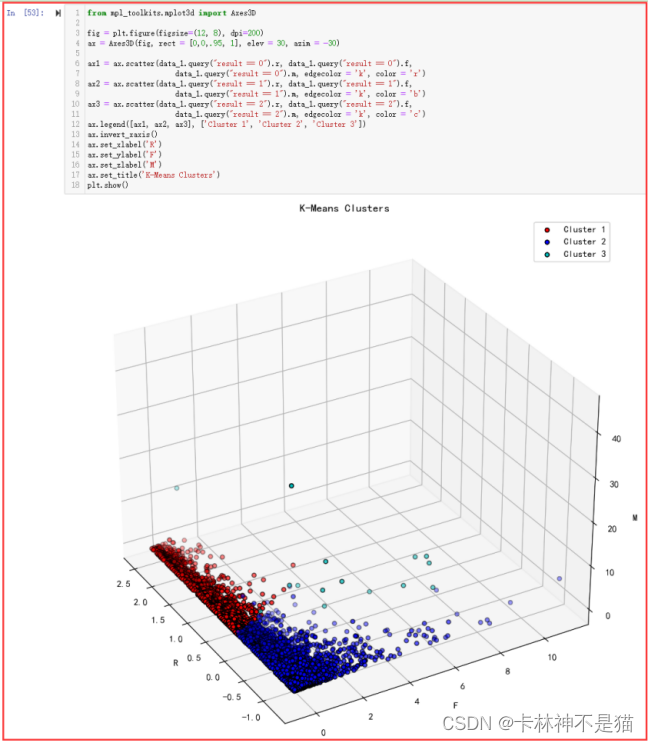
6、模型应用
会员升级?===============> 我觉得需要关注会员群体的比例!
积分兑换?===============> 普通群体也可以给少量积分兑换机制!
交叉销售?===============> 推荐的产品,可从rfm中r占比大的群体!
7、拓展思考(不用做)
本实验只针对客户价值进行分析,但客户流失并没有提出具体的分析,对客户流失有兴趣的,自己查阅资料学习
五、实验问题和体会
1、实验总结
在本次实验过程中,由于本人想要探究RFM-季度-数量之间的关系,而数据集是2010年12月1日到2011年12月9日的数据,导致在划分季度的时候,2011年12月的数据是4季度,2011年12月的数据也是4季度。导致在计算R(Frequency)的时候,即季度最大时间-当前日期时间出现时间差=365天(1年)>90天(1季度)。
这时候我反复检验之前实验记录,发现原来数据中的数据出现了跨年(即不同年的数据12月),因此导致即使同一个季度,时间差可以超过90天。因此本人采取数据规约的方式,抽取时间2011年01月01日到2011年12月01日的数据最为本次实验数据源。但是,这个决定也会导致一个问题,就是12月份的数据不全面,还差21天数据。
本着尝试的心态,本人进行了一系列实验流程,进行数据标准化和k-means聚类后,最终发现实验准确率62.3%,而如果加上PCA降维,准确率会降低5%左右,因此本实验没有加上PCA降维,不知道会不会不妥?
在探索性可视化实验过程中,我发现了原来RFM分组和季度没有明显关系(相关性系数显示:不足0.2),而其中RFM占比很大部分是222组合,最低的是331组合。
2、结论建议
经过上面的分析,得到了要分析的重点客户群体。可根据用户的量级分为两类:
第1类是用户群体占比超过10%的群体;
第2类是占比在个位数的群体。
这两类人由于量级不同,因此需要分别有针对性的策略场景;
第3类人群,虽然从用户量级上小,但是单个人的价值度非常高。
>>>第1类人群:
占比超过10%的群体。由于这类人群基数大,必须采取批量操作和运营的方式落地运营策略,一般需要通过系统或产品实现,而不能主要依赖于人工。
222(占比17.1%):中等价值客户,企业可以通过提供个性化的优惠、加强客户关系维护等方式,进一步提升他们的满意度和忠诚度,进而增加他们的消费频次和金额,提升客户价值。
>>>第2类人群:
占比为1%~10%的群体。这部分人群数量适中,在落地时无论是产品还是人工都可接入。
112(占比8.6%):可挽回的一般性群体。这类群体购买新近度低,说明距离上次购买时间较长,很可能用户已经处于沉默或预流失、流失阶段;购物频率低,说明对网站的忠诚度一般;订单金额处于中等层级,说明其还可能具有可提升的空间。因此,对这部分群体的策略首先是通过多种方式(例如邮件、短信等)触达客户并挽回,然后通过针对流失客户的专享优惠(例如流失用户专享优惠券)措施促进其消费。在此过程中,可通过增加接触频次和刺激力度的方式,增加用户的回访、复购以及订单价值回报。
333(占比8%):绝对忠诚的高价值群体。虽然用户绝对数量只有355,但由于其各方面表现非常突出,因此可以倾斜更多的资源,例如设计VIP服务、专享服务、绿色通道等。另外,针对这部分人群的高价值附加服务的推荐也是提升其价值的重点策略。
211(占比7.8%):可发展的低价值群体。这类群体相对于212群体在订单金额上表现略差,因此在211群体策略的基础上,可以增加与订单相关的刺激措施,例如组合商品优惠券发送、积分购买商品等。
322(占比7.5%)、323(占比2.8%)和332(占比2.3%):有潜力的普通群体。这类群体最近刚完成购买,需要提升的是购买频次及购买金额。因此可通过交叉销售、个性化推荐、向上销售、组合优惠券、打包商品销售等策略,提升其单次购买的订单金额及促进其重复购买。
212(占比4.1%):可发展的一般性群体。购买新近度和订单金额一般,且购买频率低。考虑到其最大的群体基础,以及在新近度和订单金额上都可以,因此可采取常规性的礼品兑换和赠送、购物社区活动、签到、免运费等手段维持并提升其消费状态。
233(占比6.6%)、223(占比3.6%)和133(占比1.2%):一般性的高价值群体。这类群体的主要着手点是提升新近购买度,即促进其实现最近一次的购买,可通过DM、电话、客户拜访、线下访谈、微信、电子邮件等方式直接建立用户挽回通道,以挽回这部分高价值用户。
312(占比1.6%):有潜力的一般性群体。这类群体购买新近度高,说明最近一次购买发生在很短时间之前,群体对于公司尚有比较熟悉的接触渠道和认知状态;购物频率低,说明对网站的忠诚度一般;订单金额处于中等层级,说明其还具有可提升的空间。因此,可以借助其最近购买的商品,为其定制一些与上次购买相关的商品,通过向上销售等策略提升购买频次和订单金额。
311(占比2.7%):有潜力的低价值群体。这部分用户与211群体类似,但在购物新近度上更好,因此对其可采取相同的策略。除此以外,在这类群体的最近接触渠道上可以增加营销或广告资源投入,通过这些渠道再次将客户引入网站完成消费。
111(占比6.4%):这是一类在各个维度上都比较差的客户群体。一般情况下,会在其他各个群体策略和管理都落地后才考虑他们。主要策略是先通过多种策略挽回客户,然后为客户推送与其类似的其他群体,或者当前热销的商品或折扣非常大的商品。在刺激消费时,可根据其消费水平、品类等情况,有针对性地设置商品暴露条件,先在优惠券及优惠商品的综合刺激下使其实现消费,再考虑消费频率以及订单金额的提升。
>>>第3类群体:
占比非常少,但却是非常重要的群体。
213(占比0.8%):可发展的高价值群体。这类人群发展的重点是提升购物频率,因此可指定不同的活动或事件来触达用户,促进其回访和购买,例如不同的节日活动、每周新品推送、高价值客户专享商品等。
313(占比0.5%):有潜力的高价值群体。这类群体的消费新近度高且订单金额高,但购买频率低,因此只要提升其购买频次,用户群体的贡献价值就会倍增。提升购买频率上,除了在其最近一次的接触渠道上增加曝光外,与最近一次渠道相关的其他关联访问渠道也要考虑增加营销资源。另外,213中的策略也要组合应用其中。
113(占比0.3%):可挽回的高价值群体。这类群体与112群体类似,但订单金额贡献更高,因此除了应用112中的策略外,可增加部分人工的参与来挽回这些高价值客户,例如线下访谈、客户电话沟通等。
231(占比0.3%):较活高频低价值群体。企业应通过提供定制化的优惠和服务、加强互动沟通、了解客户需求并提供精准推荐等手段,来刺激他们的购买欲望并提升他们的消费价值。
131(占比0.2%):近期不活跃高频低价值群体,需要思考吸引该群体的商品种类,重新启动激活消费策略。
331(占比0.2):近期活跃高频低价值群体,企业应加强与他们的互动和沟通,提供个性化的优惠和推荐,深入分析他们的消费需求和习惯,并提供优质的客户服务,以维持和提升他们的消费价值和忠诚度。
数据源在下载区啦!