🎈🎈作者主页: 喔的嘛呀🎈🎈
🎈🎈所属专栏:python爬虫学习🎈🎈
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨
目录
一、什么是Selenium
二、为什么使用selenium?
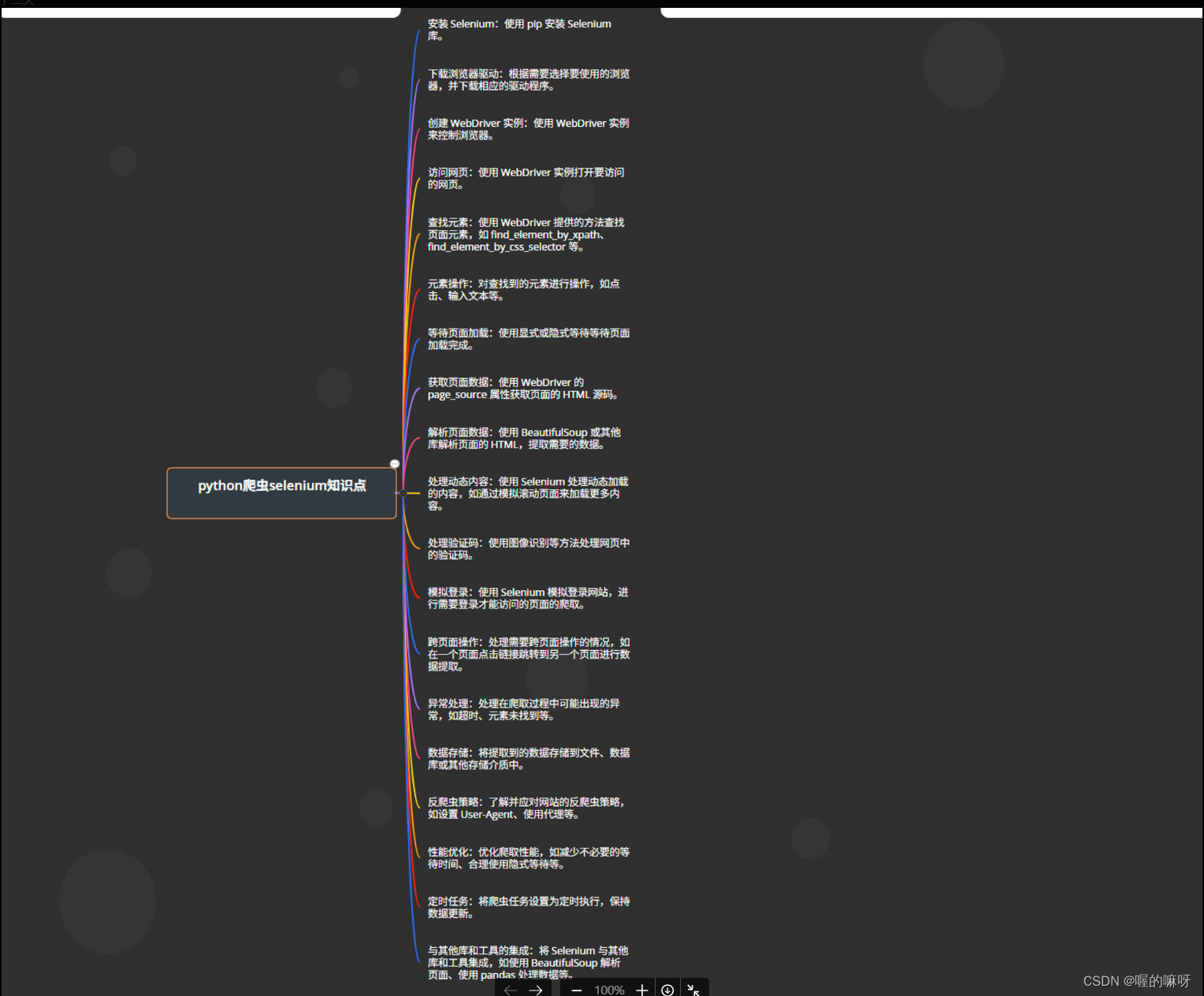
三、python爬虫selenium知识点
1、安装 Selenium:使用 pip 安装 Selenium 库。
2、下载浏览器驱动
3、创建 WebDriver 实例
4、访问网页:使用 WebDriver 实例打开要访问的网页。
6、元素操作
7、等待页面加载:
8、获取页面数据
9、解析页面数据
使用 Selenium,我们可以模拟用户在浏览器中的操作,比如点击按钮、填写表单、下拉滚动条等,从而可以访问那些通过传统的 HTTP 请求无法获取到的数据,比如使用 JavaScript 动态加载的内容。
在本次学习中,我们将学习如何安装 Selenium 库,下载浏览器驱动程序(如 ChromeDriver、GeckoDriver 等),创建 WebDriver 实例来控制浏览器,访问网页并获取页面数据,查找页面元素并进行操作,等待页面加载完成,最后使用 BeautifulSoup 或其他库解析页面数据,提取我们需要的信息。
通过学习 Selenium,你将能够扩展你的网页爬取技能,处理更加复杂的网页结构和交互逻辑,让你的爬虫更加强大和智能。
总共有十九个知识点,今天我们先看前九个,明天后十个。
一、什么是Selenium
hello,兄弟姐妹们!在 Python 爬虫学习的第二十二天,我们将深入学习如何使用 Selenium 这一强大的工具进行网页数据提取。Selenium 是一个自动化测试工具,但也可以用于网页爬取,特别是需要模拟用户操作的情况下非常有用。
Selenium 是一个用于自动化 web 应用程序测试的工具,它可以模拟用户在浏览器中的操作,比如点击按钮、填写表单、提交数据等。Selenium 测试可以直接在浏览器中运行,就像真正的用户在操作一样,这样可以更真实地模拟用户的行为。
Selenium 支持通过各种 WebDriver 驱动真实浏览器完成测试,包括 FirefoxDriver、InternetExplorerDriver、OperaDriver、ChromeDriver 等。这些驱动程序可以启动相应的浏览器,并且可以通过编程方式控制浏览器的行为,从而实现自动化测试。
此外,Selenium 也支持无界面浏览器操作,比如使用 Headless Chrome 或者 PhantomJS,这样可以在不显示实际浏览器界面的情况下进行测试,节省资源并加快测试速度。
二、为什么使用selenium?
- 处理动态网页:有些网站使用 JavaScript 动态生成内容,传统的爬虫库如 urllib、requests 无法获取到动态生成的内容,而 Selenium 可以模拟浏览器行为,获取到完整的页面内容。
- 模拟用户操作:有些网站对于频繁请求会进行反爬虫处理,使用 Selenium 可以模拟人类用户的操作行为,如点击、滚动等,降低被识别为爬虫的概率。
- 解决验证码:有些网站会使用验证码来防止爬虫,Selenium 可以通过图像识别等方式自动识别验证码,实现自动化爬取。
- 跨平台支持:Selenium 支持多种浏览器和操作系统,可以在不同环境下运行,更加灵活。
- 强大的定制能力:Selenium 提供了丰富的 API,可以实现各种复杂的操作和定制需求,满足不同爬虫场景的需求。
- 动态加载内容:有些网页内容是通过 AJAX 或其他异步加载方式获取的,Selenium 可以等待页面完全加载后再进行内容提取,确保获取到完整的页面数据。
总的来说,使用 Selenium 可以帮助爬虫程序处理更复杂的网页,提高爬取效率和成功率,适用于对动态网页内容感兴趣的爬虫任务。
三、python爬虫selenium知识点
1、安装 Selenium:使用 pip 安装 Selenium 库。
安装 Selenium 库,可以使用 Python 的包管理工具 pip。如果你还没有安装 pip,可以参考官方文档进行安装:Installation - pip documentation v24.0)(pycharm中自带的有)
安装 Selenium 的步骤如下:
(1)打开命令行或终端。(pycharm中的terminal中输入命令)
运行以下命令安装 Selenium:
pip install selenium
等待安装完成。安装完成后,你就可以在 Python 中使用 Selenium 了。
如果需要安装特定版本的 Selenium,可以使用类似以下的命令:
pip install selenium==3.141.0
这将安装 Selenium 的 3.141.0 版本。你也可以根据需要安装其他版本。
2、下载浏览器驱动
使用 Selenium 需要下载相应的浏览器驱动,以便 Selenium 能够控制浏览器。不同的浏览器需要使用对应的驱动程序,例如 Chrome 需要 chromedriver,Firefox 需要 geckodriver。
以下是下载浏览器驱动的一般步骤:
(1)确定浏览器版本:首先确定你需要使用的浏览器版本,例如 Chrome 的版本是多少。
(2)下载对应版本的驱动程序:访问对应浏览器驱动的官方网站下载页面,下载对应浏览器版本的驱动程序。以下是一些常见浏览器的驱动下载页面:
- Chrome: ChromeDriver
- Firefox: GeckoDriver
- Edge: EdgeDriver
(3)将驱动程序添加到系统 PATH:下载完成后,将驱动程序所在目录添加到系统的 PATH 环境变量中,这样 Selenium 就能找到驱动程序。
(4)使用正确的驱动程序:在创建 WebDriver 实例时,指定正确的驱动程序。例如,使用 Chrome 驱动程序创建 Chrome 浏览器的 WebDriver 实例:
from selenium import webdriver# 指定 Chrome 驱动程序路径
driver = webdriver.Chrome(executable_path='/path/to/chromedriver')# 打开网页
driver.get('<https://www.example.com>')# 关闭浏览器
driver.quit()通过以上步骤,你就可以下载并配置好浏览器驱动,以便使用 Selenium 控制浏览器进行网页操作。
3、创建 WebDriver 实例
要创建 WebDriver 实例来控制浏览器,需要先导入 webdriver 模块,然后根据要使用的浏览器类型创建相应的 WebDriver 实例。以下是使用 Selenium 创建 WebDriver 实例的示例代码:
from selenium import webdriver# 创建一个 Chrome 浏览器实例
driver = webdriver.Chrome()# 创建其他浏览器实例的方法可以根据需要选择相应的驱动程序和参数在上面的示例中,我们通过调用 webdriver.Chrome()、webdriver.Firefox() 等方法来创建不同浏览器类型的 WebDriver 实例。然后,我们可以使用这些实例来控制相应的浏览器进行网页操作。
4、访问网页:使用 WebDriver 实例打开要访问的网页。
要使用 WebDriver 实例打开要访问的网页,可以使用 WebDriver 实例的 get() 方法,并传入要访问的网页的 URL。以下是一个示例代码,演示如何使用 Selenium 打开网页:
from selenium import webdriver# 创建一个 Chrome 浏览器实例
driver = webdriver.Chrome()# 打开网页
driver.get('<https://www.example.com>')# 关闭浏览器
driver.quit()在这个示例中,我们首先创建了一个 Chrome 浏览器的 WebDriver 实例。然后,使用 get() 方法打开了 Example Domain 这个网页。最后,使用 quit() 方法关闭了浏览器。你可以将 URL 替换为你要访问的网页的 URL。
5、查找元素:使用 WebDriver 提供的方法查找页面元素
使用 Selenium 中的 WebDriver 实例,可以通过各种方法查找页面元素,例如根据元素的 XPath、CSS 选择器、ID 等属性。以下是一些常用的查找元素的方法:
(1)根据 ID 查找元素:
element = driver.find_element_by_id('element_id')
(2)根据 class 名称查找元素:
element = driver.find_element_by_class_name('class_name')
(3)根据标签名查找元素:
element = driver.find_element_by_tag_name('tag_name')
(4)根据 CSS 选择器查找元素:
element = driver.find_element_by_css_selector('css_selector')
(5)根据 XPath 查找元素:
element = driver.find_element_by_xpath('xpath_expression')
(6)查找多个元素:如果要查找多个元素,可以使用 find_elements_* 方法,例如:
elements = driver.find_elements_by_xpath('xpath_expression')
这些方法可以用于查找页面上的各种元素,如文本框、按钮、链接等。找到元素后,就可以对其进行操作,比如点击、输入文本等。
6、元素操作
对查找到的元素进行操作是使用 Selenium 进行网页自动化的核心部分。一旦找到页面元素,就可以对其执行各种操作,比如点击链接、填写表单、提交数据等。以下是一些常用的元素操作示例:
(1)点击元素:
element.click()
(2)输入文本:
element.send_keys('text_to_input')
(3)清空输入框:
element.clear()
(4)提交表单:
form_element.submit()
(5)获取元素文本:
text = element.text
(6)获取元素属性:
pythonCopy code
attribute_value = element.get_attribute('attribute_name')
(7)模拟鼠标操作(需要导入 ActionChains):
from selenium.webdriver.common.action_chains import ActionChains# 鼠标移动到元素上
ActionChains(driver).move_to_element(element).perform()# 鼠标右键点击元素
ActionChains(driver).context_click(element).perform()(8)模拟键盘操作(需要导入 Keys):
from selenium.webdriver.common.keys import Keys# 模拟按下回车键
element.send_keys(Keys.ENTER)
这些操作可以让你在自动化测试或网页爬虫中与页面元素进行交互,实现各种功能。
7、等待页面加载:
等待页面加载是使用 Selenium 进行网页自动化测试和爬取的重要步骤之一。在页面加载过程中,有时会出现网络延迟或异步加载的情况,为了确保页面的所有元素都已加载完成,需要使用等待机制。
Selenium 提供了两种等待方式:显式等待和隐式等待。
(1)显式等待:在代码中明确指定等待条件,直到条件满足或超时才继续执行后续操作。可以使用 WebDriverWait 类结合 expected_conditions 模块来实现。例如,等待页面标题包含特定文本:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 设置最长等待时间为10秒
wait = WebDriverWait(driver, 10)
# 等待直到标题包含"example"
wait.until(EC.title_contains("example"))(2)隐式等待:在创建 WebDriver 实例后,设置一个全局的等待时间,当查找元素或执行操作时,如果找不到元素或操作耗时超过设置的等待时间,将等待一段时间再继续执行。例如:
driver.implicitly_wait(10) # 设置隐式等待时间为10秒
在使用等待机制时,应根据实际情况合理设置等待时间,避免等待时间过长导致效率低下,或等待时间过短导致操作失败。
8、获取页面数据
要获取页面的 HTML 源码,可以使用 WebDriver 实例的 page_source 属性。这个属性可以让你获取当前页面的完整 HTML 内容,然后你可以使用解析库(如 BeautifulSoup)来解析和提取所需的信息。以下是一个示例代码:
pythonCopy code
from selenium import webdriver# 创建一个 Chrome 浏览器实例
driver = webdriver.Chrome()# 打开网页
driver.get('<https://www.example.com>')# 获取页面的 HTML 源码
html_source = driver.page_source# 关闭浏览器
driver.quit()# 打印页面的 HTML 源码
print(html_source)在这个示例中,我们首先创建了一个 Chrome 浏览器的 WebDriver 实例,然后使用 get() 方法打开了 Example Domain 这个网页。接着,使用 page_source 属性获取了页面的 HTML 源码,并将其打印出来。最后,使用 quit() 方法关闭了浏览器。
9、解析页面数据
解析页面数据是使用 Selenium 进行网页爬取的重要步骤之一。一旦获取到页面的 HTML 源码,就可以使用解析库(如 BeautifulSoup)来解析并提取所需的信息。以下是一个示例代码,演示如何使用 BeautifulSoup 解析页面数据:
pythonCopy code
from selenium import webdriver
from bs4 import BeautifulSoup# 创建一个 Chrome 浏览器实例
driver = webdriver.Chrome()# 打开网页
driver.get('<https://www.example.com>')# 获取页面的 HTML 源码
html_source = driver.page_source# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html_source, 'html.parser')# 查找页面中的标题元素
title_element = soup.find('title')# 输出标题文本
if title_element:print('Page Title:', title_element.text.strip())
else:print('Title element not found')# 关闭浏览器
driver.quit()在这个示例中,我们首先创建了一个 Chrome 浏览器的 WebDriver 实例,然后使用 get() 方法打开了 Example Domain 这个网页。接着,使用 page_source 属性获取了页面的 HTML 源码,并将其传递给 BeautifulSoup 解析。然后,我们使用 BeautifulSoup 的 find() 方法查找页面中的标题元素,并输出标题文本。最后,使用 quit() 方法关闭了浏览器。