一、ETL的主要作用
ETL(Extract, Transform, Load)是数据仓库中的关键环节,其主要作用是将数据从源系统中抽取出来,经过转换和清洗后加载到数据仓库中。具体而言:
Extract(抽取):从不同的数据源(如数据库、文件、API等)中提取数据。
Transform(转换):对抽取的数据进行清洗、加工、计算等操作,使其适合存储在数据仓库中。
Load(加载):将经过转换的数据加载到数据仓库中的目标表中。
二、ETL与MQ集成
消息队列(MQ)是一种用于异步通信的中间件,它可以在不同的应用程序之间传递消息。
将ETL流程与消息队列(MQ)进行集成,可以进一步提升数据处理的效率和灵活性。在这一集成架构中,MQ扮演了数据传输过程中的缓冲区和调度器的角色:
-
高效解耦:通过MQ,ETL系统的抽取阶段可以从源系统中实时或定期地发布数据变更事件,而不是直接读取源系统的数据库,从而降低了源系统压力,实现了系统间的松耦合。
-
异步处理:ETL任务可以通过订阅MQ中的消息,实现数据的异步处理。当数据产生时立即发送至MQ,然后由专门的消费者服务按需拉取并执行转换操作,这样即使在大数据量或者复杂转换场景下,也能保证整个系统的响应速度和稳定性。
-
流量控制和数据缓冲:MQ提供了流量控制机制,允许ETL系统根据自身处理能力来消费消息,避免数据洪峰导致系统崩溃。同时,MQ还能作为临时的数据存储,对于突发的大规模数据抽取,可以先暂存于MQ中,待ETL系统有足够能力处理时再逐步加载,有效缓解了数据处理的压力。
-
错误处理和重试机制:在ETL过程中,若出现异常或错误,MQ可以自动重新排队消息,使得ETL系统能够重试失败的任务,确保数据的完整性和一致性。
因此,将ETL与MQ集成,不仅增强了数据处理的可靠性和可扩展性,也优化了整体的数据流转效率,为构建高效稳定的数据仓库体系提供有力支持,而ETCLoud这个ETL工具就支持与多种MQ对接,下面我们就用这款工具实操演示下如何在ETL中集成使用MQ。
三、案例演示
在ETLCloud中,与MQ集成的具体实现方式包括以下几种:
1.使用消息队列作为数据源
ETL作业可以从MQ中直接获取数据,而不是从数据库或文件中抽取数据。这样可以减少对源系统的压力,提高性能。这里我们创建一个RabbitMQ数据源。
ETLCLoud新建数据源
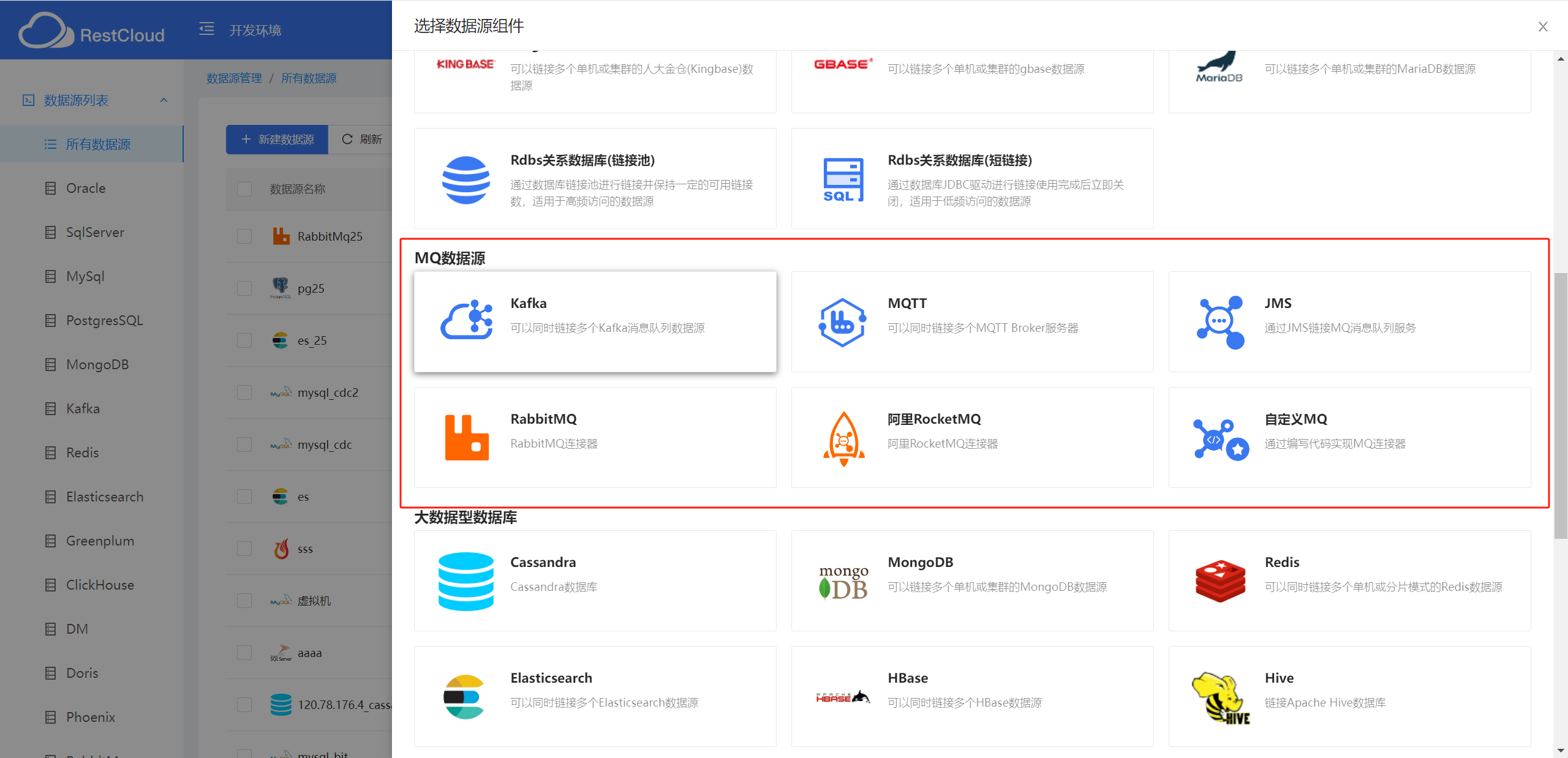
RabbitMQ数据源配置

2.将ETL作业的结果发送到MQ
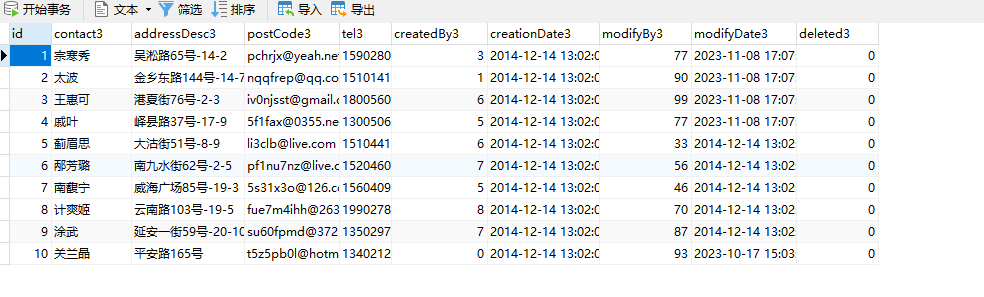
ETL作业处理完数据后,将结果发送到MQ,由其他系统进行后续处理。这里我们选择从mysql数据库中读取部分测试信息,经过字段名映射后输出到RabbitMQ中。
mysql库表信息-随机生成的测试数据:

这里可以设计流程实现(流程设计界面):

映射组件配置:

RabbitMQ输出组件配置:

运行后,查看目标端数据(流程运行日志):

MQ接收消息:

3.实时监听MQ,使用MQ作为ETL作业的触发器
可以创建MQ监听器,当MQ有新数据到达时,MQ可以作为ETL作业的触发器,启动相应的作业进行数据处理。比如这里实现简单的数据入库:
先设计ETL触发流程:
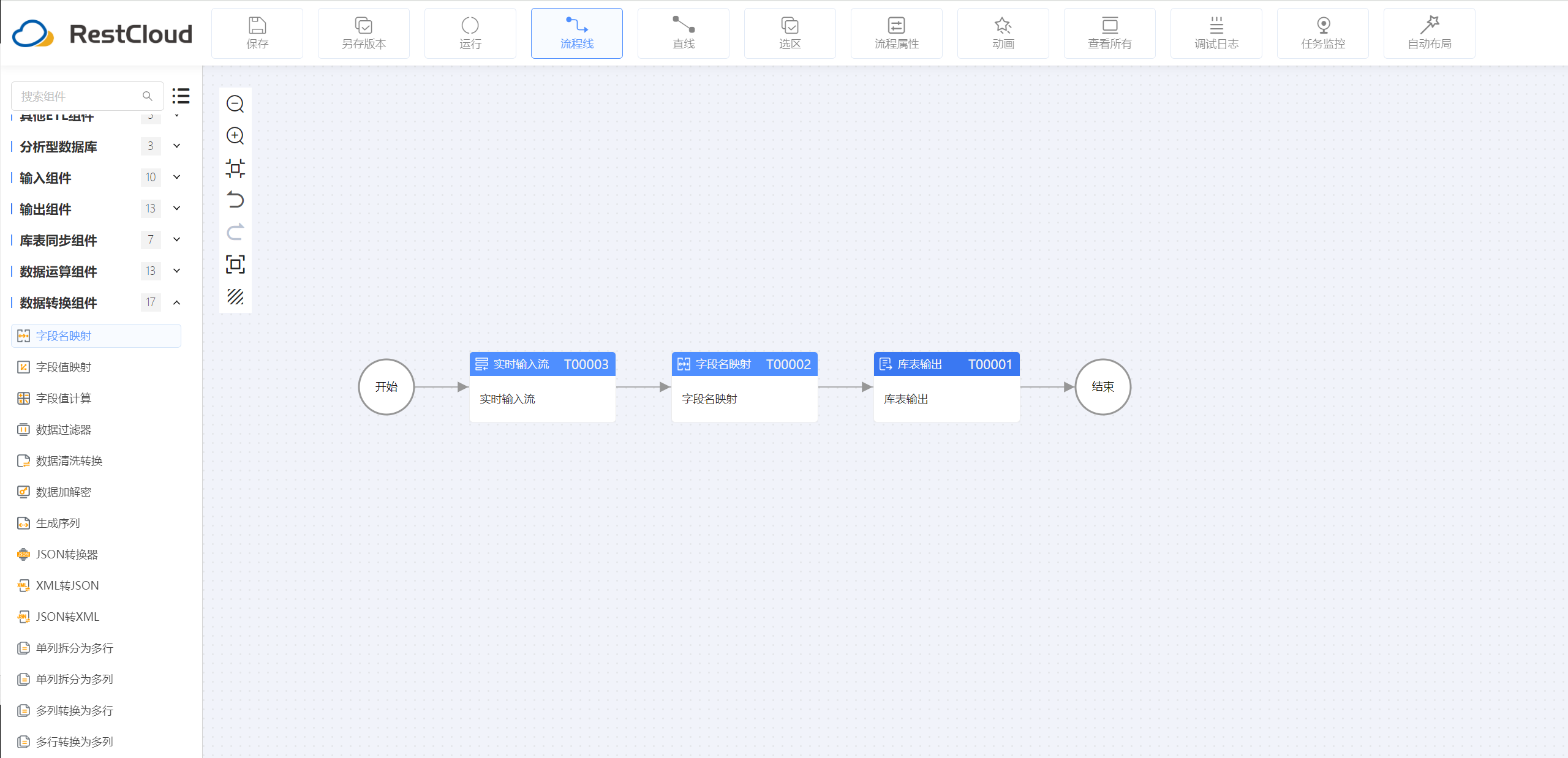
字段映射配置:

配置MQ监听器:

当向该队列发送数据时,监听器就会自动调用刚刚设计的ETL流程,从而触发数据同步流程。这里我们可以运行“将ETL作业的结果发送到MQ”这个ETL流程,将数据发送到MQ中。
监听器流程被调用日志(触发流程日志):

数据输出效果(目标库表数据):
四、总结
通过上述实例展示,我们可以看到ETLCloud与MQ的深度集成能显著提升数据集成与处理的效率及健壮性。通过监听MQ中的数据变更事件,ETL作业可以即时响应并处理这些事件,进而减少了对源系统的依赖,同时也提高了数据更新的实时性。
将ETL与MQ集成,是现代数据仓库建设中一种高效且稳健的实践方式。它能够充分利用MQ的消息传递机制,优化数据流经各个环节的效率,并增强系统的稳定性和可靠性。通过精心设计和实施此类集成方案,企业能够更好地驾驭海量数据,为数据分析、智能决策提供强有力的支持。