- 前文:模型预测控制MPC(1)—— 基础概念
- 参考:模型预测控制(2022春)
- 本文从偏控制的角度介绍无约束线性MPC方法, x , u , J x,u,J x,u,J 分别代表状态、动作和代价函数
文章目录
- 1. 问题定义
- 1.1 多步预测公式
- 1.2 代价函数
- 2. 求解优化问题
- 3. 系统稳定性
- 3.1 有限预测时域
- 3.2 无限预测时域
- 4. 无约束线性 MPC 和 LQR
1. 问题定义
- 考虑一个离散线性时不变多输入输出系统(离散指时间离散,线性指系统动态可由线性方程描述,时不变指系统动态不随时间变化),环境转移如下
x ( k + 1 ) = A x ( k ) + B u ( k ) , x ∈ R n , u ∈ R p x(k+1) = \pmb{A}x(k) + \pmb{B}u(k), \quad x\in \mathbb{R}^n, u\in \mathbb{R}^p x(k+1)=Ax(k)+Bu(k),x∈Rn,u∈Rp 由于是时不变系统,要求 A , B \pmb{A,B} A,B 是稳定的(stabilizable)常数矩阵,现在假设不存在对状态或动作的约束 - 定义 x ( i ∣ k ) , u ( i ∣ k ) x(i|k), u(i|k) x(i∣k),u(i∣k) 表示从时刻 k k k 开始后第 i i i 步的预测状态和动作。特别地,有 x ( 0 ∣ k ) = x ( k ) , u ( 0 ∣ k ) = u ( k ) x(0|k)=x(k), u(0|k)=u(k) x(0∣k)=x(k),u(0∣k)=u(k)
1.1 多步预测公式
- 在系统已知的情况下,可以如下进行多步预测
x ( 1 ∣ k ) = A x ( 0 ∣ k ) + B u ( 0 ∣ k ) x ( 2 ∣ k ) = A x ( 1 ∣ k ) + B u ( 1 ∣ k ) = A [ A x ( 0 ∣ k ) + B u ( 0 ∣ k ) ] + B ( 1 ∣ k ) = A 2 x ( 0 ∣ k ) + A B u ( 0 ∣ k ) + B u ( 1 ∣ k ) ⋮ ⋮ ⋮ x ( i ∣ k ) = A x ( i − 1 ∣ k ) + B u ( i − 1 ∣ k ) = ⋯ = A i x ( 0 ∣ k ) + A i − 1 B u ( 0 ∣ k ) + A i − 2 B u ( 1 ∣ k ) + ⋯ + B u ( i − 1 ∣ k ) \begin{aligned} x(1 \mid k) & =A x(0 \mid k)+B u(0 \mid k) \\ x(2 \mid k) & =A x(1 \mid k)+B u(1 \mid k)=A[A x(0 \mid k)+B u(0 \mid k)]+B(1 \mid k) \\ & =A^{2} x(0 \mid k)+A B u(0 \mid k)+B u(1 \mid k) \\ & \quad \vdots \quad \vdots \quad \vdots \\ x(i \mid k) & =A x(i-1 \mid k)+B u(i-1 \mid k)=\cdots \\ & =A^{i} x(0 \mid k)+A^{i-1} B u(0 \mid k)+A^{i-2} B u(1 \mid k)+\cdots+B u(i-1 \mid k) \end{aligned} x(1∣k)x(2∣k)x(i∣k)=Ax(0∣k)+Bu(0∣k)=Ax(1∣k)+Bu(1∣k)=A[Ax(0∣k)+Bu(0∣k)]+B(1∣k)=A2x(0∣k)+ABu(0∣k)+Bu(1∣k)⋮⋮⋮=Ax(i−1∣k)+Bu(i−1∣k)=⋯=Aix(0∣k)+Ai−1Bu(0∣k)+Ai−2Bu(1∣k)+⋯+Bu(i−1∣k) 设预测时间步数为 N N N,多步预测结果可以写成更紧凑的矩阵形式
X ( k ) = F x ( k ) + Φ U ( k ) where X ( k ) ≜ [ x ( 1 ∣ k ) x ( 2 ∣ k ) ⋮ x ( N ∣ k ) ] U ( k ) ≜ [ u ( 0 ∣ k ) u ( 1 ∣ k ) ⋮ u ( N − 1 ∣ k ) ] F = [ A A 2 ⋮ A N ] Φ = [ B 0 A B B 0 ⋮ A N − 1 B A N − 2 B ⋯ B ] X(k) = Fx(k) + \Phi U(k)\quad \text{where} \\ \space \\ X(k) \triangleq\left[\begin{array}{c} x(1 \mid k) \\ x(2 \mid k) \\ \vdots \\ x(N \mid k) \end{array}\right] \quad U(k) \triangleq\left[\begin{array}{r} u(0 \mid k) \\ u(1 \mid k) \\ \vdots \\ u(N-1 \mid k) \end{array}\right] \\\space \\ F=\left[\begin{array}{l} A \\ A^{2} \\ \vdots \\ A^{N} \end{array}\right] \quad \Phi=\left[\begin{array}{lllll} B & 0 & & \\ A B & B & 0 & \\ \vdots & & & \\ A^{N-1} B & A^{N-2} B & \cdots & B \end{array}\right] X(k)=Fx(k)+ΦU(k)where X(k)≜ x(1∣k)x(2∣k)⋮x(N∣k) U(k)≜ u(0∣k)u(1∣k)⋮u(N−1∣k) F= AA2⋮AN Φ= BAB⋮AN−1B0BAN−2B0⋯B 其中 X X X 和 U U U 分别为状态序列和动作序列, F , Φ F,\Phi F,Φ 是由环境模型确定的常数矩阵
1.2 代价函数
-
首先把控制系统的示意图绘制如下

在每个时刻 k k k,由控制器产生动作 u ( k ) u(k) u(k) 输入被控系统,观测到系统转移至状态 x ( k ) x(k) x(k),在下一时刻计算其与参考值(目标) c ( k ) c(k) c(k) 的误差 e ( 1 ∣ k ) e(1|k) e(1∣k) 作为反馈。控制目标通常有两个
- 最优追踪效果:最小化控制过程的总误差,即最小化 mse 损失 ∑ i = 1 N e 2 ( i ∣ k ) \sum_{i=1}^N e^2(i|k) ∑i=1Ne2(i∣k), c ≡ 0 c\equiv 0 c≡0 时为 ∑ i = 1 N x 2 ( i ∣ k ) \sum_{i=1}^N x^2(i|k) ∑i=1Nx2(i∣k)
- 最小控制能耗:最小化控制过程的总输入,即最小化 mse 损失 ∑ i = 1 N u 2 ( i − 1 ∣ k ) \sum_{i=1}^N u^2(i-1|k) ∑i=1Nu2(i−1∣k)
-
通常使用两个可调节的参数 q , r q,r q,r 权衡两个目标损失,从而构造代价函数。单输入输出系统下形如
J ( k ) = ∑ i = 1 N q x 2 ( i ∣ k ) + r u 2 ( i − 1 ∣ k ) J(k) = \sum_{i=1}^N qx^2(i|k) + ru^2(i-1|k) J(k)=i=1∑Nqx2(i∣k)+ru2(i−1∣k) 多输入输出系统下形如(这里使用某种二范数作为 mse 损失的广义形式),是两个二次型之和
J ( k ) = ∑ i = 1 N ∥ x ( i ∣ k ) ∥ Q 2 + ∥ u ( i − 1 ∣ k ) ∥ R 2 = X T ( k ) Q X ( k ) + U ( k ) T R U ( k ) where Q = [ Q Q ⋱ Q ] R = [ R R ⋱ R ] \begin{array}{l} J(k)=\sum_{i=1}^{N}\|x(i \mid k)\|_{Q}^{2}+\|u(i-1 \mid k)\|_{R}^{2}=X^{T}(k) \mathscr{Q} X(k)+U(k)^{T} \mathscr{R} U(k) \quad \text{where} \\\space\\ \mathscr{Q}=\left[\begin{array}{llll} Q & & & \\ & Q & & \\ & & \ddots & \\ & & & Q \end{array}\right] \quad \mathscr{R}=\left[\begin{array}{llll} R & & & \\ & R & & \\ & & \ddots & \\ & & & R \end{array}\right] \end{array} J(k)=∑i=1N∥x(i∣k)∥Q2+∥u(i−1∣k)∥R2=XT(k)QX(k)+U(k)TRU(k)where Q= QQ⋱Q R= RR⋱R -
由 1.1 节有 X ( k ) = F x ( k ) + Φ U ( k ) X(k)=F x(k)+\Phi U(k) X(k)=Fx(k)+ΦU(k),代入有
J ( k ) = ( F x ( k ) + Φ U ( k ) ) T Q ( F x ( k ) + Φ U ( k ) ) + U T ( k ) R U ( k ) = x T ( k ) F T Q F x ( k ) + 2 x T ( k ) F T Q Φ U ( k ) + U T ( k ) ( Φ T Q Φ + R ) U ( k ) \begin{aligned} J(k) & =(F x(k)+\Phi U(k))^{T} \mathscr{Q}(F x(k)+\Phi U(k))+U^{T}(k) \mathscr{R} U(k) \\ & =x^{T}(k) F^{T} \mathscr{Q} F x(k)+2 x^{T}(k) F^{T} \mathscr{Q} \Phi U(k)+U^{T}(k)\left(\Phi^{T} \mathscr{Q} \Phi+\mathscr{R}\right) U(k) \end{aligned} J(k)=(Fx(k)+ΦU(k))TQ(Fx(k)+ΦU(k))+UT(k)RU(k)=xT(k)FTQFx(k)+2xT(k)FTQΦU(k)+UT(k)(ΦTQΦ+R)U(k)
2. 求解优化问题
-
我们在 1.1 节给出了环境模型已知情况下多步预测结果的数学表达式,然后基于它在 1.2 节给出了每一时刻 k k k 要求解的优化问题表达式,本节考虑如何求解这个优化问题
-
首先回顾代价函数表达式
J ( k ) = x T ( k ) F T Q F x ( k ) + 2 x T ( k ) F T Q Φ U ( k ) + U T ( k ) ( Φ T Q Φ + R ) U ( k ) J(k) =x^{T}(k) F^{T} \mathscr{Q} F x(k)+2 x^{T}(k) F^{T} \mathscr{Q} \Phi U(k)+U^{T}(k)\left(\Phi^{T} \mathscr{Q} \Phi+\mathscr{R}\right) U(k) J(k)=xT(k)FTQFx(k)+2xT(k)FTQΦU(k)+UT(k)(ΦTQΦ+R)U(k) 注意式子中 x x x 是测量得到的反馈, F , Q , R F, \mathscr{Q}, \mathscr{R} F,Q,R 都是常数矩阵,我们只能通过优化动作序列 U U U 来优化 J J J。令 J J J 关于 U U U 的梯度为 0,求解最优动作序列 U ∗ U^* U∗
∇ U ∣ U = U ∗ = ∂ J ∂ U ∣ U = U ∗ = 0 2 x ( k ) T F T Q Φ + 2 U ( k ) T ( Φ T Q Φ + R ) ∣ U ( k ) = U ∗ = 0 U ∗ ( k ) = − ( Φ T Q Φ + R ) − 1 Φ T Q F x ( k ) \begin{aligned} &\left.\nabla_{U}\right|_{U=U^{*}}=\left.\frac{\partial J}{\partial U}\right|_{U=U^{*}}=0 \\ \space \\ &2 x(k)^{T} F^{T} \mathscr{Q} \Phi+\left.2 U(k)^{T}\left(\Phi^{T} \mathscr{Q} \Phi+\mathscr{R}\right)\right|_{U(k)=U^{*}}=0 \\ \space \\ &U^{*}(k)=-\left(\Phi^{T} \mathscr{Q} \Phi+\mathscr{R}\right)^{-1} \Phi^{T} \mathscr{Q} F x(k) \end{aligned} ∇U∣U=U∗=∂U∂J U=U∗=02x(k)TFTQΦ+2U(k)T(ΦTQΦ+R) U(k)=U∗=0U∗(k)=−(ΦTQΦ+R)−1ΦTQFx(k)
注意这里要求 ( Φ T Q Φ + R ) \left(\Phi^{T} \mathscr{Q} \Phi+\mathscr{R}\right) (ΦTQΦ+R) 可逆,有两种情况- R \mathscr{R} R 正定, Q \mathscr{Q} Q 半正定
此时 Φ T Q Φ \Phi^{T} \mathscr{Q} \Phi ΦTQΦ 半正定,它和正定矩阵之和一定正定,正定矩阵可逆
- R \mathscr{R} R 正定或半正定, Q \mathscr{Q} Q 正定且 Φ \Phi Φ 是满秩的
此时 Φ T Q Φ \Phi^{T} \mathscr{Q} \Phi ΦTQΦ 正定,它和正定或半正定矩阵之和一定正定,正定矩阵可逆。 Φ \Phi Φ 的形式第1节已经给出,当 A , B A,B A,B 完全可控时它满秩
最后,利用一个方块单位阵把最优动作序列 U ∗ ( k ) U^{*}(k) U∗(k) 中的第一个动作 u ∗ ( k ) u^*(k) u∗(k) 取出来,就得到 k k k 时刻需要执行的最优动作
u ∗ ( k ) = − [ I p × p 0 ⋯ 0 ] ( Φ T Q Φ + R ) − 1 Φ T Q F x ( k ) = − K m p c x ( k ) u^{*}(k)=-\left[\begin{array}{llll} I_{p \times p} & 0 & \cdots & 0 \end{array}\right]\left(\Phi^{T} \mathscr{Q} \Phi+\mathscr{R}\right)^{-1} \Phi^{T} \mathscr{Q} F x(k)=-K_{m p c} x(k) u∗(k)=−[Ip×p0⋯0](ΦTQΦ+R)−1ΦTQFx(k)=−Kmpcx(k)下面给出一个计算最优动作的示例。注意到无约束线性MPC不需要每步在线解优化问题,直接代入以上解析式计算即可

- R \mathscr{R} R 正定, Q \mathscr{Q} Q 半正定
-
我们直接算出了 U ∗ ( k ) = arg min U J ( k ) U^*(k) = \argmin_{U} J(k) U∗(k)=argminUJ(k) 的解析解。观察 u ∗ ( k ) u^{*}(k) u∗(k) 的表达式,其中 Φ , x , F , Q , R \Phi, x, F, \mathscr{Q}, \mathscr{R} Φ,x,F,Q,R 都是常值矩阵,因此 K m p c K_{m p c} Kmpc 也是常值矩阵,故 u ∗ ( k ) u^{*}(k) u∗(k) 就是当前状态 x ( k ) x(k) x(k) 的一个线性反馈,我们可以利用这一点验证系统的稳定性
3. 系统稳定性
3.1 有限预测时域
- 把第 2 节得到的最优动 u ∗ ( k ) = − K m p c x ( k ) u^{*}(k) = -K_{m p c} x(k) u∗(k)=−Kmpcx(k) 作带回到环境模型 x ( k + 1 ) = A x ( k ) + B u ( k ) x(k+1) = \pmb{A}x(k) + \pmb{B}u(k) x(k+1)=Ax(k)+Bu(k),得到每步都执行最优动作下的环境转移为
x ( k + 1 ) = ( A − B K m p c ) x ( k ) x(k+1) = (\pmb{A} - \pmb{B}\pmb{K}_{m p c})x(k) x(k+1)=(A−BKmpc)x(k) 这是一个离散的线性闭环系统,线性系统的稳定性判别准则如下

如图所示,我们只需要检查 A − B K m p c \pmb{A} - \pmb{B}\pmb{K}_{m p c} A−BKmpc 的特征值是否在单位圆内即可前提是要求 A , B \pmb{A} ,\pmb{B} A,B 是稳定的,这样 K m p c \pmb{K}_{m p c} Kmpc 才存在
- 对于本文考虑的无约束线性 MPC 而言,使代价函数的最优的动作策略无法保证系统稳定
系统的稳定性是指系统在受到外部扰动或初始条件变化时,系统的状态不会无限制地增长或衰减,而是会在某个有限的范围内保持。换句话说,稳定的闭环系统会在一定的条件下保持一种平衡状态,而不会发散或者偏离目标(简单说就是状态 x x x 能否在扰动下收敛)
- 无约束线性 MPC 无法保证稳定性的原因,直观上可以理解为它建模的轨迹和优化的动作序列都是有限长度的,而对有限长度的轨迹预测可能无法真实地反映系统运动趋势,换句话说,随着预测时域 N N N 减少,更可能出现不稳定问题,如下例所示

3.2 无限预测时域
-
当我们优化无限长度的动作序列,即 N = ∞ N=\infin N=∞ 时,系统的稳定性是可以保证的(证明略)
-
但是,简单地令 N = ∞ N=\infin N=∞ 会出现问题,虽然依然可以按第 2 节解出
u ∗ ( k ) = − [ I p × p 0 ⋯ 0 ] ( Φ T Q Φ + R ) − 1 Φ T Q F x ( k ) = − K m p c x ( k ) u^{*}(k)=-\left[\begin{array}{llll} I_{p \times p} & 0 & \cdots & 0 \end{array}\right]\left(\Phi^{T} \mathscr{Q} \Phi+\mathscr{R}\right)^{-1} \Phi^{T} \mathscr{Q} F x(k)=-K_{m p c} x(k) u∗(k)=−[Ip×p0⋯0](ΦTQΦ+R)−1ΦTQFx(k)=−Kmpcx(k) 但此时 Φ , F , Q , R \Phi, F, \mathscr{Q}, \mathscr{R} Φ,F,Q,R 都是无限维了,这样我们就没法写程序来计算了。为了处理这个问题,我们要利用线性系统的性质:线性系统在最优代价函数关于时域的极限存在且有限,可以写作
J ( k ) = ∑ i = 1 ∞ ∥ x ( i ∣ k ) ∥ Q 2 + ∥ u ( i − 1 ∣ k ) ∥ R 2 = ∥ x ( k ) ∥ P 2 − ∥ x ( k ) ∥ Q 2 J(k)=\sum_{i=1}^{\infty}\|x(i \mid k)\|_{Q}^{2}+\|u(i-1 \mid k)\|_{R}^{2}=\|x(k)\|_{P}^{2}-\|x(k)\|_{Q}^{2} J(k)=i=1∑∞∥x(i∣k)∥Q2+∥u(i−1∣k)∥R2=∥x(k)∥P2−∥x(k)∥Q2 为了证明这里的第二个等号,需要用到离散形式的李雅普诺夫方程的一个结论:给定任意使得离散系统 x ( k + 1 ) = ( A − B K ) x ( k ) x(k+1) = (\pmb{A} - \pmb{B}\pmb{K})x(k) x(k+1)=(A−BK)x(k) 稳定的矩阵 K \pmb{K} K 和任意正定对称矩阵 Q Q Q,一定存在唯一的正定对称矩阵 P P P 使得下式成立
P − ( A − B K ) T P ( A − B K ) = Q + K T R K with ∣ eig ( A − B K ) ∣ < 1 P-(A-B K)^{T} P(A-B K)=Q+K^{T} R K \quad \text { with } \quad|\operatorname{eig}(A-B K)|<1 P−(A−BK)TP(A−BK)=Q+KTRK with ∣eig(A−BK)∣<1接下来利用以上结论证明无穷时域下最优代价函数 J ( k ) = ∥ x ( k ) ∥ P 2 − ∥ x ( k ) ∥ Q 2 J(k)=\|x(k)\|_{P}^{2}-\|x(k)\|_{Q}^{2} J(k)=∥x(k)∥P2−∥x(k)∥Q2
P − ( A − B K ) T P ( A − B K ) = Q + K T R K with ∣ eig ( A − B K ) ∣ < 1 P-(A-B K)^{T} P(A-B K)=Q+K^{T} R K \quad \text { with } \quad|\operatorname{eig}(A-B K)|<1 P−(A−BK)TP(A−BK)=Q+KTRK with ∣eig(A−BK)∣<1Proof:
x T [ P − ( A − B K ) T P ( A − B K ) ] x = x T [ Q + K T R K ] x x T P x − x T ( A − B K ) T P ( A − B K ) x = x T Q x + x T K T R K x x ( k ) T P x ( k ) − x T ( k + 1 ) P x ( k + 1 ) = x T ( k ) Q x ( k ) + u T ( k ) R u ( k ) ∥ x ( k ) ∥ P 2 = ∑ i = k ∞ ∥ x ( i ) ∥ Q 2 + ∥ u ( i ) ∥ R 2 = ∑ i = 1 ∞ ∥ x ( i ∣ k ) ∥ Q 2 + ∥ u ( i ∣ k ) ∥ R 2 ∥ x ( k ) ∥ P 2 − ∥ x ( k ) ∥ Q 2 = ∑ i = 1 ∞ ∥ x ( i ∣ k ) ∥ Q 2 + ∥ u ( i − 1 ∣ k ) ∥ R 2 \begin{aligned} &x^{T}\left[P-(A-B K)^{T} P(A-B K)\right] x=x^{T}\left[Q+K^{T} R K\right] x \\ &x^{T} P x-x^{T}(A-B K)^{T} P(A-B K) x=x^{T} Q x+x^{T} K^{T} R K x \\ &x(k)^{T} P x(k)-x^{T}(k+1) P x(k+1)=x^{T}(k) Q x(k)+u^{T}(k) R u(k) \\ &\|x(k)\|_{P}^{2}=\sum_{i=k}^{\infty}\|x(i)\|_{Q}^{2}+\|u(i)\|_{R}^{2} = \sum_{i=1}^{\infty}\|x(i|k)\|_{Q}^{2}+\|u(i|k)\|_{R}^{2}\\ &\|x(k)\|_{P}^{2} -\|x(k)\|_{Q}^{2} =\sum_{i=1}^{\infty}\|x(i|k)\|_{Q}^{2}+\|u(i-1|k)\|_{R}^{2} \\ \end{aligned} xT[P−(A−BK)TP(A−BK)]x=xT[Q+KTRK]xxTPx−xT(A−BK)TP(A−BK)x=xTQx+xTKTRKxx(k)TPx(k)−xT(k+1)Px(k+1)=xT(k)Qx(k)+uT(k)Ru(k)∥x(k)∥P2=i=k∑∞∥x(i)∥Q2+∥u(i)∥R2=i=1∑∞∥x(i∣k)∥Q2+∥u(i∣k)∥R2∥x(k)∥P2−∥x(k)∥Q2=i=1∑∞∥x(i∣k)∥Q2+∥u(i−1∣k)∥R2- 第 3 行等号左边用到离散系统转移 x ( k + 1 ) = ( A − B K ) x ( k ) x(k+1) = (\pmb{A} - \pmb{B}\pmb{K})x(k) x(k+1)=(A−BK)x(k)
- 第 3 行等号右边用到 u ( k ) = − K x ( k ) u(k)=-Kx(k) u(k)=−Kx(k)
- 由于 x x x 和 u u u 都定义为列向量, x ( k ) T P x ( k ) = x 2 ( k ) P , u T ( k ) R u ( k ) = u 2 ( k ) R x(k)^{T} P x(k)=x^2(k)P, \space u^{T}(k) R u(k)=u^2(k)R x(k)TPx(k)=x2(k)P, uT(k)Ru(k)=u2(k)R
- 第 4 行就是把第 3 行左右都从 k k k 时刻到 ∞ \infin ∞ 求和,左边是 x 2 ( k ) P − x 2 ( k + 1 ) P + x 2 ( k + 1 ) P − x 2 ( k + 2 ) P . . . x^2(k)P-x^2(k+1)P+x^2(k+1)P-x^2(k+2)P... x2(k)P−x2(k+1)P+x2(k+1)P−x2(k+2)P...,这样后面全都加减相消了,只留下第一项 x 2 ( k ) P = ∥ x ( k ) ∥ P 2 x^2(k)P = \|x(k)\|_{P}^{2} x2(k)P=∥x(k)∥P2
-
证明以上结论后,我们可以通过以下步骤,求解无限预测时域下的最优动作了:要求 A , B \pmb{A},\pmb{B} A,B 稳定,给定对称正定的 Q Q Q
- 找到任意线性反馈 u = − K x u=-Kx u=−Kx 使得离散系统稳定(即 ∣ eig ( a − B K ) ∣ < 1 |\text{eig}(a-BK)|<1 ∣eig(a−BK)∣<1)
- 根据 Q , R , K Q, R, K Q,R,K 求解李雅普诺夫方程 P − ( A − B K ) T P ( A − B K ) = Q + K T R K P-(A-B K)^{T} P(A-B K)=Q+K^{T} R K P−(A−BK)TP(A−BK)=Q+KTRK,解得正定对称矩阵 P P P
- 无限时域下的代价函数值可以如下转换,用有限时域内的代价函数值表示
J ( k ) = ∑ i = 1 ∞ ∥ x ( i ∣ k ) ∥ Q 2 + ∥ u ( i − 1 ∣ k ) ∥ R 2 = ∑ i = N ∞ ∥ x ( i ∣ k ) ∥ Q 2 + ∥ u ( i − 1 ∣ k ) ∥ R 2 + ∑ i = 1 N − 1 ∥ x ( i ∣ k ) ∥ Q 2 + ∥ u ( i − 1 ∣ k ) ∥ R 2 = ∥ x ( N ∣ k ) ∥ P 2 − ∥ x ( N ∣ k ) ∥ Q 2 + ∑ i = 1 N − 1 ∥ x ( i ∣ k ) ∥ Q 2 + ∥ u ( i − 1 ∣ k ) ∥ R 2 = X T ( k ) Q X ( k ) + U ( k ) T R U ( k ) \begin{aligned} J(k) & =\sum_{i=1}^{\infty}\|x(i \mid k)\|_{Q}^{2}+\|u(i-1 \mid k)\|_{R}^{2} \\ & =\sum_{i=N}^{\infty}\|x(i \mid k)\|_{Q}^{2}+\|u(i-1 \mid k)\|_{R}^{2} + \sum_{i=1}^{N-1}\|x(i \mid k)\|_{Q}^{2}+\|u(i-1 \mid k)\|_{R}^{2} \\ & =\|x(N \mid k)\|_{P}^{2}-\|x(N \mid k)\|_{Q}^{2} + \sum_{i=1}^{N-1}\|x(i \mid k)\|_{Q}^{2}+\|u(i-1 \mid k)\|_{R}^{2} \\ & =X^{T}(k) \mathscr{Q} X(k)+U(k)^{T} \mathscr{R} U(k) \end{aligned} J(k)=i=1∑∞∥x(i∣k)∥Q2+∥u(i−1∣k)∥R2=i=N∑∞∥x(i∣k)∥Q2+∥u(i−1∣k)∥R2+i=1∑N−1∥x(i∣k)∥Q2+∥u(i−1∣k)∥R2=∥x(N∣k)∥P2−∥x(N∣k)∥Q2+i=1∑N−1∥x(i∣k)∥Q2+∥u(i−1∣k)∥R2=XT(k)QX(k)+U(k)TRU(k) 注意第三行中减去一个 x x x 关乎 Q Q Q 的二次型,增加一个 x x x 关乎 P P P 的二次型,这可以体现在矩阵 Q \mathscr{Q} Q 中,而 R \mathscr{R} R 不变,即
Q = diag [ Q , Q , . . . . , Q , P ] R = diag [ R , R , . . . . , R , R ] \mathscr{Q} = \text{diag} [Q,Q,....,Q,P] \\ \mathscr{R} = \text{diag} [R,R,....,R,R] Q=diag[Q,Q,....,Q,P]R=diag[R,R,....,R,R] - 优化 3 中 J ( k ) J(k) J(k) 得到的控制策略一定可以保证系统稳定性,优化问题求解过程和第 2 节相同,最优策略为
u ∗ ( k ) = − [ I p × p 0 ⋯ 0 ] ( Φ T Q Φ + R ) − 1 Φ T Q F x ( k ) = − K m p c x ( k ) u^{*}(k)=-\left[\begin{array}{llll} I_{p \times p} & 0 & \cdots & 0 \end{array}\right]\left(\Phi^{T} \mathscr{Q} \Phi+\mathscr{R}\right)^{-1} \Phi^{T} \mathscr{Q} F x(k)=-K_{m p c} x(k) u∗(k)=−[Ip×p0⋯0](ΦTQΦ+R)−1ΦTQFx(k)=−Kmpcx(k)
-
下面给出一个根据以上方法计算的例子

-
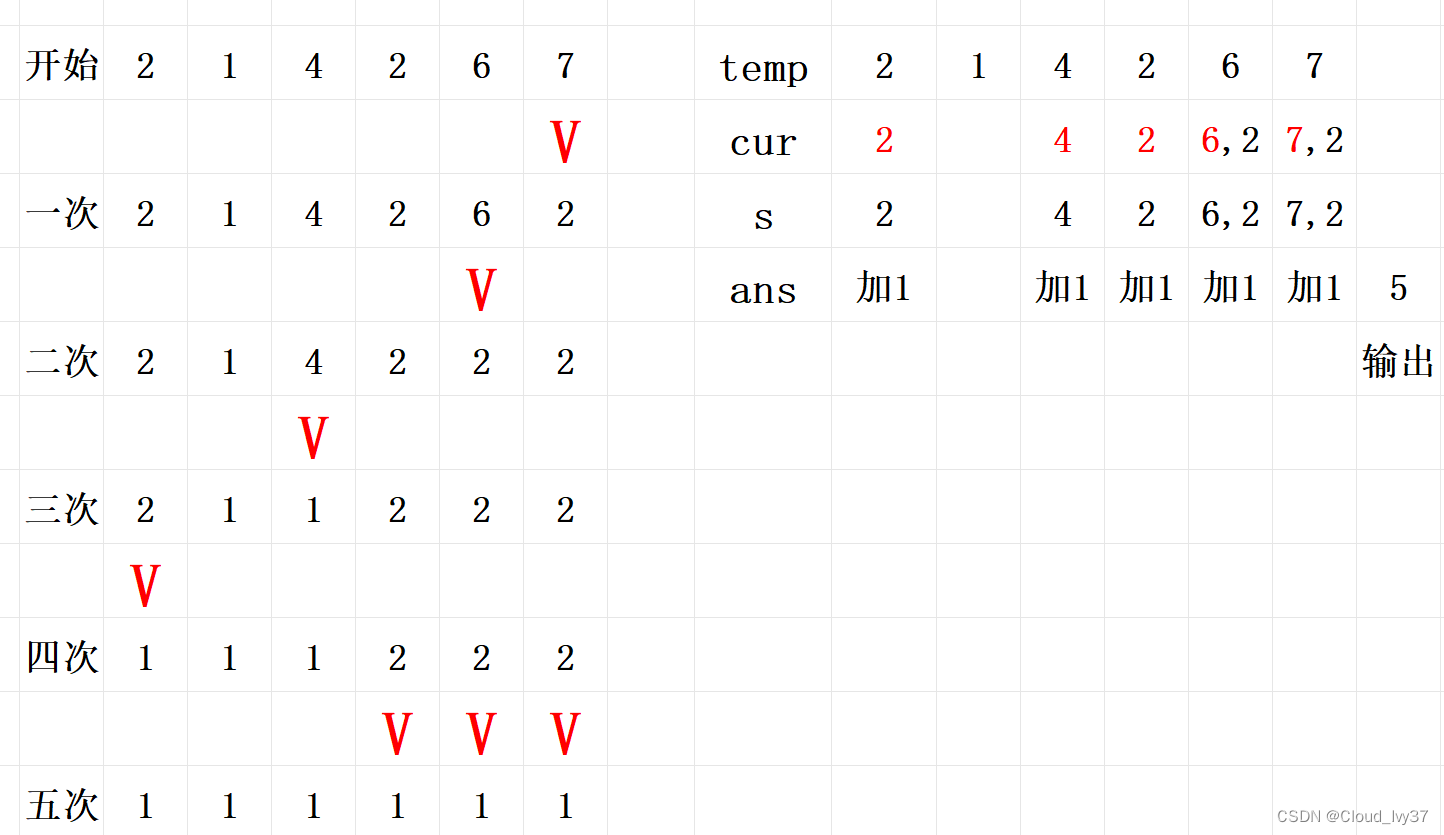
进一步地,我们可以考察以上第 3 步中对时间划分时 N N N 不同取值的影响,如下
分析以上计算过程,我们起初任取的 K K K 从序列第 N N N 个时刻起才开始发挥作用,因此 N N N 取值越大,计算结果越接近真实最优值,初始取值的影响越小
4. 无约束线性 MPC 和 LQR
- 无穷时域上,无约束线性MPC和LQR的求解结果其实是一样的
- 无约束线性 MPC 通过找到最优的动作序列 { u ( k ) , u ( k + 1 ) . . . } \{u(k), u(k+1)...\} {u(k),u(k+1)...} 来最小化代价函数,这等价于优化 u = − K m p c x u=-K_{mpc}x u=−Kmpcx
- LQR 通过求解每一步最优的控制增益 K l q r K_{lqr} Klqr,构造动作 u = − K l q r x u=-K_{lqr}x u=−Klqrx 执行来最小化代价函数,这等价于求解最优动作序列 { u ( k ) , u ( k + 1 ) . . . } \{u(k), u(k+1)...\} {u(k),u(k+1)...}
- 因此,二者的优化目标其实是一样的,二者的优化结果也是一样的。但是无约束线性 MPC 仍有意义
- 有些场景下我们只关注有限时域内的控制过程,这时 LQR 没法解
- 约束 MPC 的稳定性分析是基于无约束 MPC 稳定性分析的