第1关:Bagging
任务描述
本关任务:补充 python 代码,完成 BaggingClassifier 类中的 fit 和 predict 函数。请不要修改 Begin-End 段之外的代码。
相关知识
为了完成本关任务,你需要掌握:
- 什么是 Bagging;
- Bagging 算法如何训练与预测。
什么是Bagging
Bagging 是 Bootstrap Aggregating 的英文缩写,刚接触的童鞋不要误认为 Bagging 是一种算法, Bagging 和 Boosting 都是集成学习中的学习框架,代表着不同的思想。与 Boosting 这种串行集成学习算法不同, Bagging 是并行式集成学习方法。大名鼎鼎的随机森林算法就是在 Bagging 的基础上修改的算法。
** Bagging 方法的核心思想就是三个臭皮匠顶个诸葛亮**。如果使用 Bagging 解决分类问题,就是将多个分类器的结果整合起来进行投票,选取票数最高的结果作为最终结果。如果使用 Bagging 解决回归问题,就将多个回归器的结果加起来然后求平均,将平均值作为最终结果。
那么 Bagging 方法如此有效呢,举个例子。狼人杀我相信大家都玩过,在天黑之前,村民们都要根据当天所发生的事和别人的发现来投票决定谁可能是狼人。
如果我们将每个村民看成是一个分类器,那么每个村民的任务就是二分类,假设hi(x)表示第 i 个村民认为 x 是不是狼人( -1 代表不是狼人,1 代表是狼人),f(x)表示 x 真正的身份(是不是狼人),ϵ表示为村民判断错误的错误率。则有P(hi(x)=f(x))=ϵ。
根据狼人杀的规则,村民们需要投票决定天黑前谁是狼人,也就是说如果有超过半数的村民投票时猜对了,那么这一轮就猜对了。那么假设现在有T个村民,H(x)表示投票后最终的结果,则有H(x)=sign(∑i=1Thi(x))。
现在假设每个村民都是有主见的人,对于谁是狼人都有自己的想法,那么他们的错误率也是相互独立的。那么根据 Hoeffding不等式 可知,H(x)的错误率为:
P(H(x)=f(x))=k=0∑T/2CTk(1−ϵ)kϵT−k≤exp(−21T(1−2ϵ)2)
根据上式可知,如果 5 个村民,每个村民的错误率为 0.33,那么投票的错误率为 0.749;如果 20 个村民,每个村民的错误率为 0.33,那么投票的错误率为 0.315;如果 50 个村民,每个村民的错误率为 0.33,那么投票的错误率为 0.056;如果 100 个村民,每个村民的错误率为 0.33,那么投票的错误率为 0.003。从结果可以看出,村民的数量越大,那么投票后犯错的错误率就越小。这也是 Bagging 性能强的原因之一。
Bagging方法如何训练与预测
训练
Bagging 在训练时的特点就是随机有放回采样和并行。
-
随机有放回采样:假设训练数据集有 m 条样本数据,每次从这 m 条数据中随机取一条数据放入采样集,然后将其返回,让下一次采样有机会仍然能被采样。然后重复 m 次,就能得到拥有 m 条数据的采样集,该采样集作为 Bagging 的众多分类器中的一个作为训练数据集。假设有 T 个分类器(随便什么分类器),那么就重复 T 此随机有放回采样,构建出 T 个采样集分别作为 T 个分类器的训练数据集。
-
并行:假设有 10 个分类器,在 Boosting 中,1 号分类器训练完成之后才能开始 2 号分类器的训练,而在 Bagging 中,分类器可以同时进行训练,当所有分类器训练完成之后,整个 Bagging 的训练过程就结束了。
Bagging 训练过程如下图所示:

预测
Bagging 在预测时非常简单,就是投票!比如现在有 5 个分类器,有 3 个分类器认为当前样本属于 A 类,1 个分类器认为属于 B 类,1 个分类器认为属于 C 类,那么 Bagging 的结果会是 A 类(因为 A 类的票数最高)。
Bagging 预测过程如下图所示:

编程要求
在 begin-end 中完成 BaggingClassifier 类中的 fit 和 predict 函数。分类器可使用 sklearn 提供的 DecisionTreeClassifier。要求模型保存在 self.models 中。
fit 函数用于 Bagging 的训练过程,其中:
- feature :训练集数据,类型为 ndarray;
- label :训练集标签,类型为 ndarray。
predict 函数,实现预测功能,并将标签返回,其中:
- feature :测试集数据,类型为 ndarray 。(PS:feature中有多条数据)
测试说明
只需完成 fit 与 predict 函数即可,程序内部会调用您所完成的 fit 函数构建模型并调用 predict 函数来对数据进行预测。预测的准确率高于 0.9 视为过关。
import numpy as np
from collections import Counter
from sklearn.tree import DecisionTreeClassifier
class BaggingClassifier():def __init__(self, n_model=10):'''初始化函数'''#分类器的数量,默认为10self.n_model = n_model#用于保存模型的列表,训练好分类器后将对象append进去即可self.models = []def fit(self, feature, label):'''训练模型:param feature: 训练数据集所有特征组成的ndarray:param label:训练数据集中所有标签组成的ndarray:return: None'''#************* Begin ************#for i in range(self.n_model):m = len(feature)index = np.random.choice(m, m)sample_data = feature[index]sample_lable = label[index]model = DecisionTreeClassifier()model = model.fit(sample_data, sample_lable)self.models.append(model)#************* End **************#def predict(self, feature):''':param feature:训练数据集所有特征组成的ndarray:return:预测结果,如np.array([0, 1, 2, 2, 1, 0])'''#************* Begin ************#result = []vote = []for model in self.models:r = model.predict(feature)vote.append(r)vote = np.array(vote)for i in range(len(feature)):v = sorted(Counter(vote[:, i]).items(), key=lambda x: x[1], reverse=True)result.append(v[0][0])return np.array(result)#************* End **************#
第2关:随机森林算法流程
任务描述
本关任务:补充 python 代码,完成 RandomForestClassifier 类中的 fit 和 predict 函数。请不要修改 Begin-End 段之外的代码。
相关知识
为了完成本关任务,你需要掌握随机森林的训练与预测流程
随机森林的训练流程
随机森林是 Bagging 的一种扩展变体,随机森林的训练过程相对与 Bagging 的训练过程的改变有:
- 基学习器: Bagging 的基学习器可以是任意学习器,而随机森林则是以决策树作为基学习器。
- 随机属性选择:假设原始训练数据集有 10 个特征,从这 10 个特征中随机选取 k 个特征构成训练数据子集,然后将这个子集作为训练集扔给决策树去训练。其中 k 的取值一般为 log2(特征数量) 。
这样的改动通常会使得随机森林具有更加强的泛化性,因为每一棵决策树的训练数据集是随机的,而且训练数据集中的特征也是随机抽取的。如果每一棵决策树模型的差异比较大,那么就很容易能够解决决策树容易过拟合的问题。
随机森林训练过程伪代码如下:
#假设数据集为D,标签集为A,需要构造的决策树为treedef fit(D, A):models = []for i in range(决策树的数量):有放回的随机采样数据,得到数据集sample_D和标签sample_A从采样到的数据中随机抽取K个特征构成训练集sub_D构建决策树treetree.fit(sub_D, sample_A)models.append(tree)return models
随机森林的预测流程
随机森林的预测流程与 Bagging 的预测流程基本一致,如果是回归,就将结果基学习器的预测结果全部加起来算平均;如果是分类,就投票,票数最多的结果作为最终结果。但需要注意的是,在预测时所用到的特征必须与训练模型时所用到的特征保持一致。例如,第 3 棵决策树在训练时用到了训练集的第 2,5,8 这 3 个特征。那么在预测时也要用第 2,5,8 这 3 个特征所组成的测试集传给第 3 棵决策树进行预测。
编程要求
在 begin-end 中完成 RandomForestClassifier 类中的 fit 和 predict 函数。分类器可使用 sklearn 提供的 DecisionTreeClassifier ,要求模型保存在 self.models 中。
fit 函数用于随机森林的训练过程,其中:
- feature :训练集数据,类型为 ndarray;
- label :训练集标签,类型为 ndarray。
predict 函数,实现预测功能,并将标签返回,其中:
- feature :测试集数据,类型为 ndarray 。(PS:feature中有多条数据)
测试说明
只需完成 fit 与 predict 函数即可,程序内部会调用您所完成的 fit 函数构建模型并调用 predict 函数来对数据进行预测。预测的准确率高于 0.9 视为过关。
import numpy as np
from collections import Counter
from sklearn.tree import DecisionTreeClassifier
class RandomForestClassifier():def __init__(self, n_model=10):'''初始化函数'''#分类器的数量,默认为10self.n_model = n_model#用于保存模型的列表,训练好分类器后将对象append进去即可self.models = []#用于保存决策树训练时随机选取的列的索引self.col_indexs = []def fit(self, feature, label):'''训练模型:param feature: 训练数据集所有特征组成的ndarray:param label:训练数据集中所有标签组成的ndarray:return: None'''#************* Begin ************#for i in range(self.n_model):m = len(feature)index = np.random.choice(m, m)col_index = np.random.permutation(len(feature[0]))[:int(np.log2(len(feature[0])))]sample_data = feature[index]sample_data = sample_data[:, col_index]sample_lable = label[index]model = DecisionTreeClassifier()model = model.fit(sample_data, sample_lable)self.models.append(model)self.col_indexs.append(col_index)#************* End **************#def predict(self, feature):''':param feature:训练数据集所有特征组成的ndarray:return:预测结果,如np.array([0, 1, 2, 2, 1, 0])'''#************* Begin ************#result = []vote = []for i, model in enumerate(self.models):f = feature[:, self.col_indexs[i]]r = model.predict(f)vote.append(r)vote = np.array(vote)for i in range(len(feature)):v = sorted(Counter(vote[:, i]).items(), key=lambda x: x[1], reverse=True)result.append(v[0][0])return np.array(result)#************* End **************#
第3关:手写数字识别
任务描述
本关任务:使用 sklearn 中的 RandomForestClassifier 类完成手写数字识别任务。请不要修改Begin-End段之外的代码。
相关知识
为了完成本关任务,你需要掌握如何使用 sklearn 提供的 RandomForestClassifier 类。
数据简介
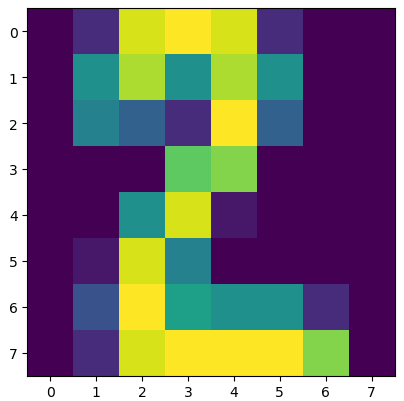
本关使用的是手写数字数据集,该数据集有 1797 个样本,每个样本包括 8*8 像素(实际上是一条样本有 64 个特征,每个像素看成是一个特征,每个特征都是 float 类型的数值)的图像和一个 [0, 9] 整数的标签。比如下图的标签是 2 :
RandomForestClassifier
RandomForestClassifier 的构造函数中有两个常用的参数可以设置:
-
n_estimators :森林中决策树的数量;
-
criterion :构建决策树时,划分节点时用到的指标。有 gini (基尼系数), entropy (信息增益)。若不设置,默认为 gini;
-
max_depth :决策树的最大深度,如果发现模型已经出现过拟合,可以尝试将该参数调小。若不设置,默认为 None;
-
max_features :随机选取特征时选取特征的数量,一般传入 auto 或者 log2,默认为 auto , auto 表示 max_features=sqrt(训练集中特征的数量) ;log2 表示 max_features=log2(训练集中特征的数量)。
RandomForestClassifier 类中的 fit 函数实现了随机森林分类器训练模型的功能,predict 函数实现了模型预测的功能。
其中 fit 函数的参数如下:
- X :大小为 [样本数量,特征数量] 的 ndarry,存放训练样本;
- Y :值为整型,大小为 [样本数量] 的 ndarray,存放训练样本的分类标签。
而 predict 函数有一个向量输入:
- X :大小为 [样本数量,特征数量] 的 ndarry,存放预测样本。
RandomForestClassifier 的使用代码如下:
from sklearn.ensemble import RandomForestClassifierclf = RandomForestClassifier(n_estimators=50)clf.fit(X_train, Y_train)result = clf.predict(X_test)
编程要求
在右侧区域的 begin-end 之间填写digit_predict(train_image, train_label, test_image)函数完成手写数字分类任务,其中:
-
train_image :包含多条训练样本的样本集,类型为 ndarray , shape 为 [-1, 8, 8] ,在喂给分类器之前请记得将其变形;
-
train_label :包含多条训练样本标签的标签集,类型为 ndarray;
-
test_image :包含多条测试样本的测试集,类型为 ndarray;
-
return : test_image 对应的预测标签,类型为 ndarray。
测试说明
只需完成 digit_predict 函数即可,程序内部会检测您的代码,预测正确率高于 0.98 视为过关。
from sklearn.ensemble import RandomForestClassifier
import numpy as npdef digit_predict(train_image, train_label, test_image):'''实现功能:训练模型并输出预测结果:param train_image: 包含多条训练样本的样本集,类型为ndarray,shape为[-1, 8, 8]:param train_label: 包含多条训练样本标签的标签集,类型为ndarray:param test_image: 包含多条测试样本的测试集,类型为ndarry:return: test_image对应的预测标签,类型为ndarray'''#************* Begin ************#X = np.reshape(train_image, newshape=(-1, 64))clf = RandomForestClassifier(n_estimators=500, max_depth=10)clf.fit(X, y=train_label)return clf.predict(test_image)#************* End **************#