1 集群规划
共三台虚拟机同处overlay网段,每台虚拟机部署一套kafka和zookeeper,kafka_manager安装其中一台虚拟机上即可。
| Hostname | IP addr | Port | Listener |
|---|---|---|---|
| zk1 | docker-swarm分配 | 2183:2181 | |
| zk2 | docker-swarm分配 | 2184:2181 | |
| zk3 | docker-swarm分配 | 2185:2181 | |
| k1 | docker-swarm分配 | 内部9093:9093,外部9193:9193 | kafka1 |
| k2 | docker-swarm分配 | 内部9094:9094,外部9194:9194 | kafka2 |
| k3 | docker-swarm分配 | 内部9095:9095,外部9195:9195 | kafka3 |
| kafka_manager | 8094:9000 |
2 虚拟机安装docker(之前安装过省略该步)
3 关闭SELINUX服务
找到/etc/sysconfig/selinux文件,把其中的SELINUX设置为disabled,保存文件之后重启CentOS系统。
4 更新yum程序
yum update -y
5 安装docker
yum remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-engine
6 安装需要的软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
7 设置稳定的存储库
yum-config-manager --add-repo [https://download.docker.com/linux/centos/docker-ce.repo](https://download.docker.com/linux/centos/docker-ce.repo)
8 安装最新版的 Docker Engine 和 containerd
yum install docker-ce docker-ce-cli containerd.io
9 创建docker swarm集群(之前初始化过省略该步)
10 初始化swarm集群(管理主机上)
docker swarm init --advertise-addr <本虚拟机ip>
11 加入虚拟网段(每台从主机上)
管理主机调用初始化swarm集群的命令后会生成一段命令(如下图),将该段命令复制到每台从主机上执行。

12 查看网段信息
docker network ls
13 查看swarm集群节点信息(管理主机上)
docker node ls
14 创建虚拟共享网段(管理主机上)
docker network create -d overlay --attachable swarm_kafka
15 部署kafka集群
16 部署主机1
17 创建zookeeper1容器
docker run -d --restart always --hostname zk1 --name zk1 -p 2183:2181 -v "/root/zookeeper1/data:/data" -v "/root/zookeeper1/datalog:/datalog" -v "/root/zookeeper1/logs:/logs" -e ZOO_MY_ID=1 -e ZOO_SERVERS="server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181" --network swarm_kafka zookeeper:latest
18 创建kafka1容器
docker run -d --restart always --hostname k1 --name k1 -p 9093:9093 -p 9193:9193 -e KAFKA_BROKER_ID=1 -e KAFKA_LISTENERS="INSIDE://:9093,OUTSIDE://:9193" -e KAFKA_ADVERTISED_LISTENERS="INSIDE://<填虚拟机ip>:9093,OUTSIDE://<填虚拟机ip>:9193" -e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP="INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT" -e KAFKA_INTER_BROKER_LISTENER_NAME=INSIDE -e KAFKA_ZOOKEEPER_CONNECT="zk1:2181,zk2:2181,zk3:2181" -e ALLOW_PLAINTEXT_LISTENER='yes' -e JMX_PORT=9999 -v "/root/kafka1/wurstmeister/kafka:/wurstmeister/kafka" -v "/root/kafka1/kafka:/kafka" --network swarm_kafka --link zk1 --link zk2 --link zk3 docker.io/wurstmeister/kafka
19 部署主机2
20 创建zookeeper2容器
docker run -d --restart always --hostname zk2 --name zk2 -p 2184:2181 -v "/root/zookeeper2/data:/data" -v "/root/zookeeper2/datalog:/datalog" -v "/root/zookeeper2/logs:/logs" -e ZOO_MY_ID=2 -e ZOO_SERVERS="server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181" --network swarm_kafka zookeeper:latest
21 创建kafka2容器
docker run -d --restart always --hostname k2 --name k2 -p 9094:9094 -p 9194:9194 -e KAFKA_BROKER_ID=2 -e KAFKA_LISTENERS="INSIDE://:9094,OUTSIDE://:9194" -e KAFKA_ADVERTISED_LISTENERS="INSIDE://<填虚拟机ip>:9094,OUTSIDE://<填虚拟机ip>:9194" -e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP="INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT" -e KAFKA_INTER_BROKER_LISTENER_NAME=INSIDE -e KAFKA_ZOOKEEPER_CONNECT="zk1:2181,zk2:2181,zk3:2181" -e ALLOW_PLAINTEXT_LISTENER='yes' -e JMX_PORT=9999 -v "/root/kafka2/wurstmeister/kafka:/wurstmeister/kafka" -v "/root/kafka2/kafka:/kafka" --network swarm_kafka --link zk1 --link zk2 --link zk3 docker.io/wurstmeister/kafka
22 部署主机3
23 创建zookeeper3容器
docker run -d --restart always --hostname zk3--name zk3 -p 2185:2181 -v "/root/zookeeper3/data:/data" -v "/root/zookeeper3/datalog:/datalog" -v "/root/zookeeper3/logs:/logs" -e ZOO_MY_ID=3 -e ZOO_SERVERS="server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181" --network swarm_kafka zookeeper:latest
24 创建kafka3容器
docker run -d --restart always --hostname k3 --name k3 -p 9095:9095 -p 9195:9195 -e KAFKA_BROKER_ID=3 -e KAFKA_LISTENERS="INSIDE://:9095,OUTSIDE://:9195" -e KAFKA_ADVERTISED_LISTENERS="INSIDE://<填虚拟机ip>:9095,OUTSIDE://<填虚拟机ip>:9195" -e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP="INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT" -e KAFKA_INTER_BROKER_LISTENER_NAME=INSIDE -e KAFKA_ZOOKEEPER_CONNECT="zk1:2181,zk2:2181,zk3:2181" -e ALLOW_PLAINTEXT_LISTENER='yes' -e JMX_PORT=9999 -v "/root/kafka3/wurstmeister/kafka:/wurstmeister/kafka" -v "/root/kafka3/kafka:/kafka" --network swarm_kafka --link zk1 --link zk2 --link zk3 docker.io/wurstmeister/kafka
25 安装kafka管理工具
docker run -d --restart always --hostname kafka-manager --name kafka-manager -p 8094:9000 -e ZK_HOSTS="zk1:2181,zk2:2181,zk3:2181" -e KAFKA_BROKERS="k1:9093,k2:9094,k3:9095" -e APPLICATION_SECRET=letmein -e KM_ARGS="-Djava.net.preferIPv4Stack=true" --network swarm_kafka --link zk1 --link zk2 --link zk3 --link k1 --link k2 --link k3 \scjtqs/kafka-manager:latest
26 配置cluster
打开kafka-manager的Windows管理界面地址:<虚拟机ip>:8094
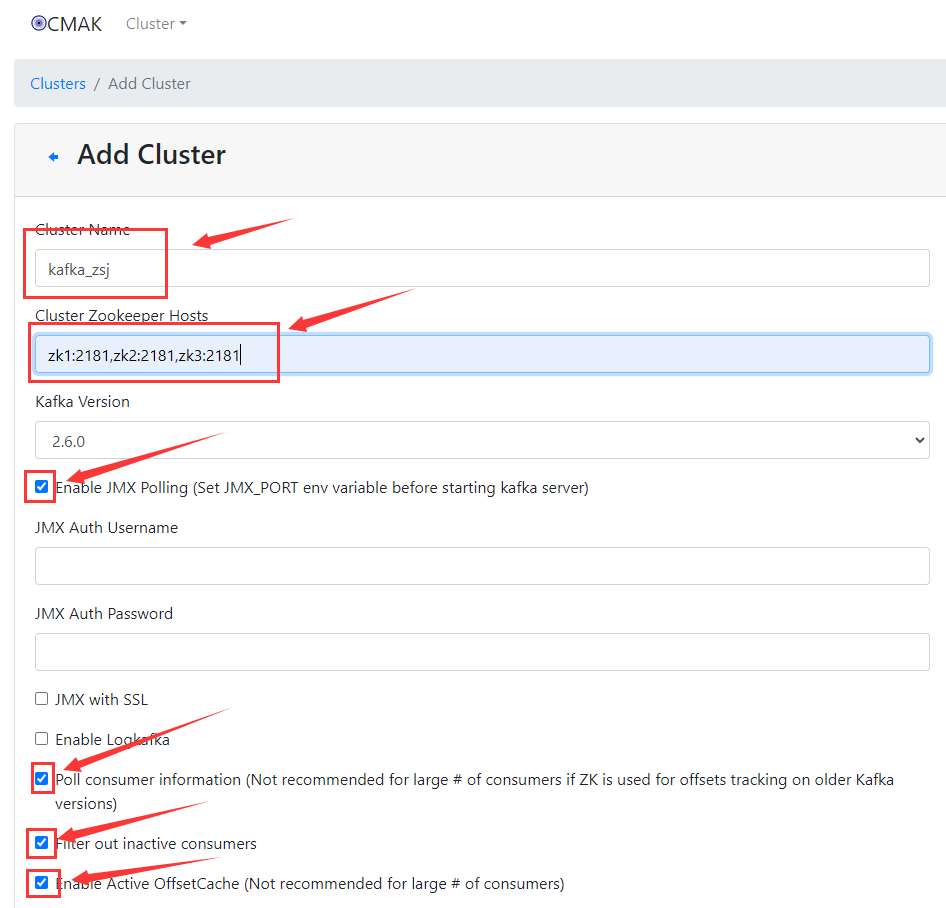
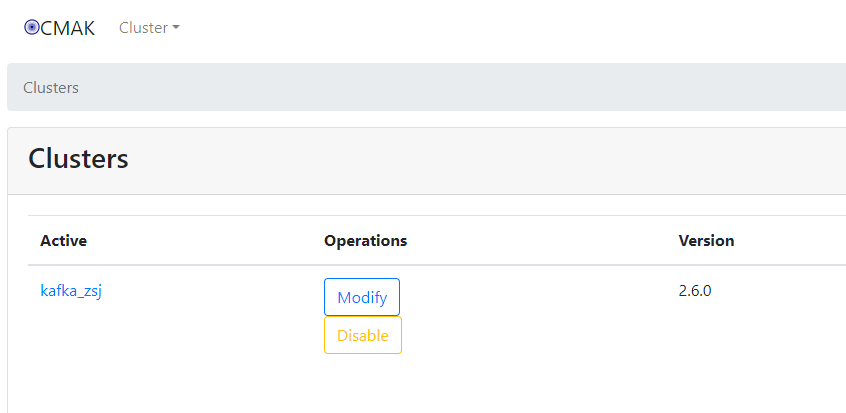
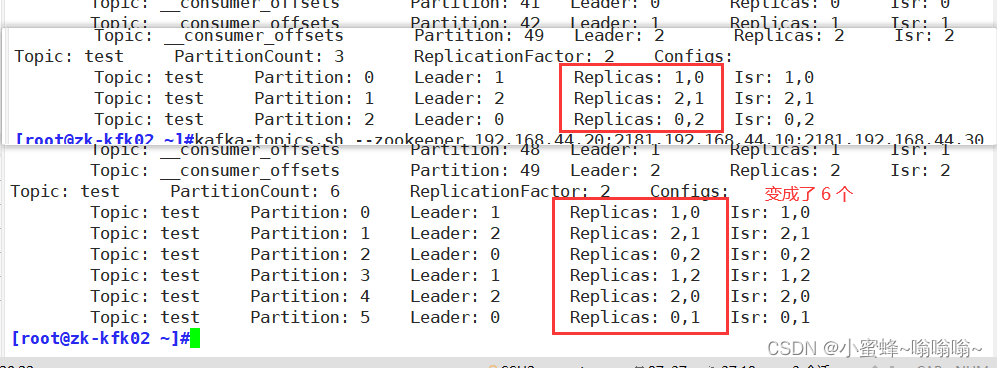
最后点击save保存,成功配置cluster图如下:
![Navicat连接SQL server出现:[IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序(0)](https://img-blog.csdnimg.cn/direct/92d4e9ec7ef8496c911afe7f831eedde.png)










![[NKCTF2024]-PWN:leak解析(中国剩余定理泄露libc地址,汇编覆盖返回地址)](https://img-blog.csdnimg.cn/direct/de3fdfbaf62b403b9833ad27d045f2d8.png)

