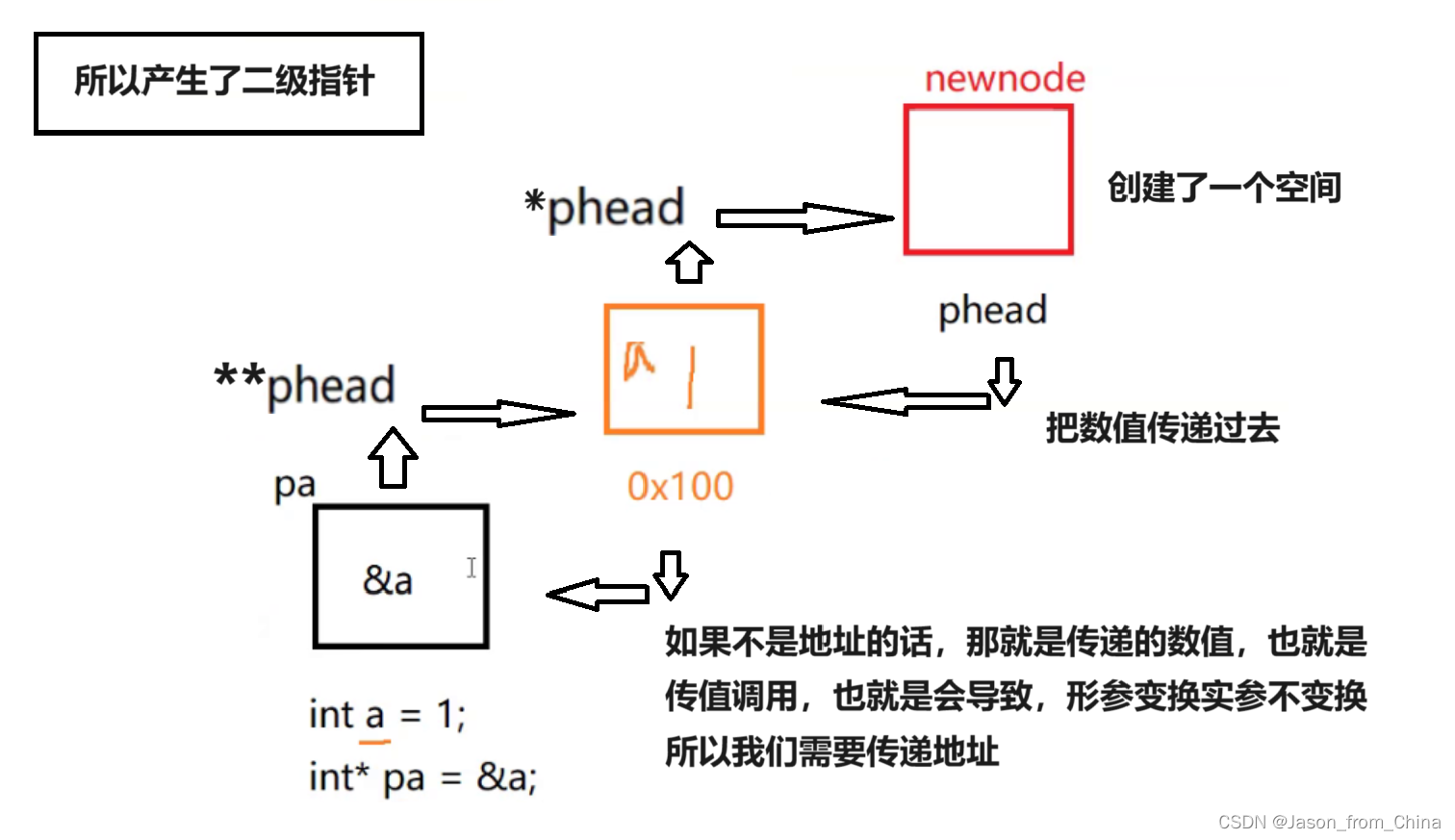
本文同步更新于博主个人博客:blog.buzzchat.top
一、Scrapy框架
1. 介绍
在当今数字化的时代,数据是一种宝贵的资源,而网络爬虫(Web Scraping)则是获取网络数据的重要工具之一。而在 Python 生态系统中,Scrapy 框架作为一种高效、灵活的网络爬虫框架,为开发者提供了强大的工具和功能,使他们能够轻松地从网站中提取所需的结构化数据。
1.1 Scrapy 框架简介
Scrapy 是一个基于 Python 的开源网络爬虫框架,旨在快速高效地爬取网站数据,并提取结构性数据。它提供了一套强大的工具和组件,使开发者能够专注于编写爬虫逻辑,而无需关注网络请求、页面解析等底层细节。Scrapy 的设计理念包括高度可配置、模块化和可扩展性,使其成为爬取大规模数据的理想选择。
1.2 本教程目的
本教程旨在帮助初学者了解如何使用 Scrapy 框架来爬取豆瓣电影 Top250 的信息。通过本教程,你将学习到如何创建一个 Scrapy 项目、编写爬虫逻辑、提取数据、保存数据以及处理网络请求等相关内容。无论是对 Scrapy 框架感兴趣的新手,还是想要学习如何从网站中获取数据的开发者,本教程都将提供有价值的知识和实用的技能。
2. 概念和工作原理
在开始使用 Scrapy 构建爬虫之前,了解其核心概念和工作原理是非常重要的。Scrapy 的设计思想是基于一系列组件的协同工作,以实现高效的网络数据爬取和处理。在本部分,我们将介绍 Scrapy 的主要组成部分以及其工作流程。
2.1 组件介绍
Scrapy 主要由以下组件组成:
-
引擎(Engine): 负责控制整个爬虫系统的流程,包括调度器、下载器和爬虫之间的通信。它负责调度并协调各个组件的工作。
-
调度器(Scheduler): 负责接收引擎发送过来的请求,并按照一定的策略将这些请求排队,然后发送给下载器。
-
下载器(Downloader): 负责下载引擎发送过来的请求对应的页面,并将下载到的页面内容返回给引擎。
-
爬虫(Spiders): 爬虫是用户编写的一组类,用于定义如何爬取特定网站(或者一组网站)的数据。每个爬虫都包含了一些用于从网页中提取数据的解析规则。
-
管道(Pipeline): 管道负责处理爬虫从网页中抽取出来的数据,并进行后续的处理,比如数据清洗、存储等操作。
-
下载中间件(Downloader Middleware): 下载中间件是介于引擎和下载器之间的组件,它可以对请求和响应进行预处理或后处理。
-
爬虫中间件(Spider Middleware): 爬虫中间件是介于引擎和爬虫之间的组件,它可以对请求和数据进行预处理或后处理。
如图所示:

2.2 工作原理
Scrapy 的工作流程如下:
- 引擎接收到用户定义的初始请求,并将其传递给调度器。
- 调度器将请求排队,并按照一定的策略选择下一个要处理的请求,然后将其发送给下载器。
- 下载器下载网页内容,并将下载到的页面内容返回给引擎。
- 引擎将下载到的页面内容发送给相应的爬虫进行解析,提取出目标数据。
- 爬虫将提取到的数据提交给管道进行后续处理,比如数据清洗、存储等操作。
- 如果有新的请求需要处理,引擎将它们发送给调度器,重复上述过程,直到没有新的请求需要处理为止。
通过以上步骤,Scrapy 能够高效地从网站中爬取数据,并对其进行处理和存储,为用户提供了强大的数据获取和处理能力。
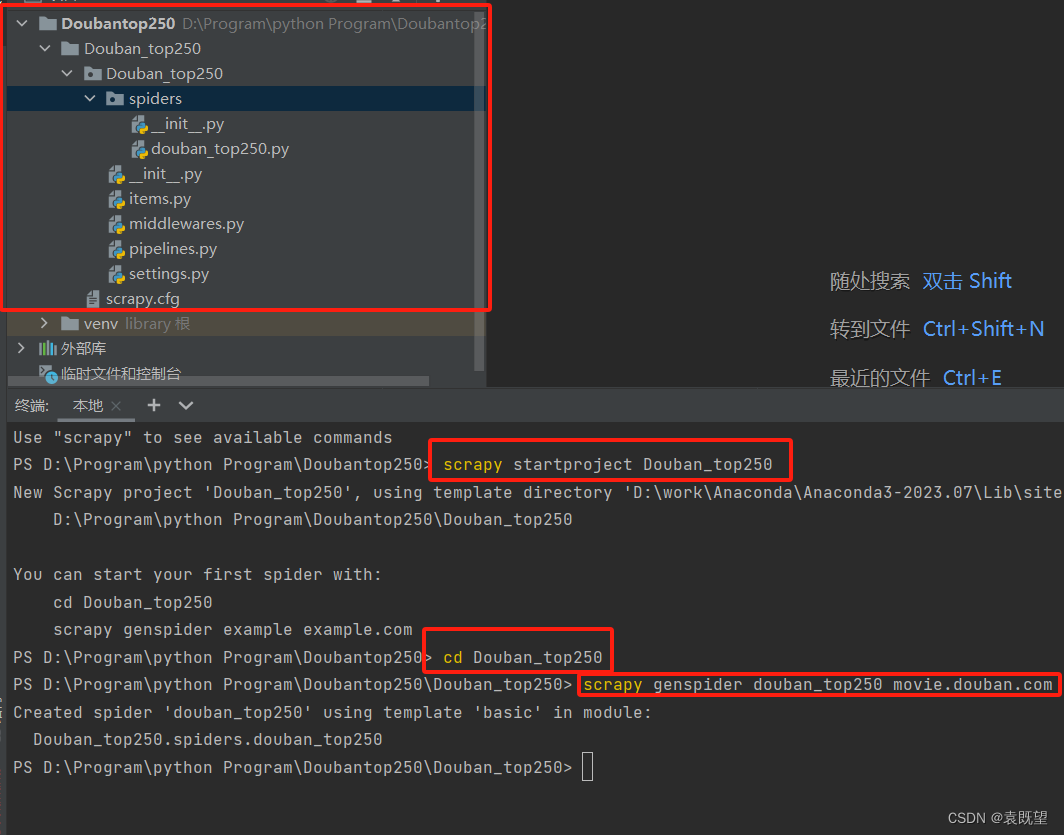
3. 创建新的 Scrapy 项目
要创建一个新的 Scrapy 项目,首先确保你已经安装了 Scrapy。然后在命令行中执行以下命令:
scrapy startproject myproject
这会在当前目录下创建一个名为 myproject 的新项目。在这个项目中,你会看到如下结构:
- myproject/
- myproject/
__init__.pyitems.py: 定义爬取的数据结构(可选)。middlewares.py: 可以在请求和响应之间进行操作的中间件(可选)。pipelines.py: 对爬取到的数据进行处理的管道(可选)。settings.py: 项目的设置文件,包含了各种配置选项。spiders/: 存放爬虫代码的目录。
__init__.py__init__.py- scrapy.cfg: Scrapy 部署配置文件。
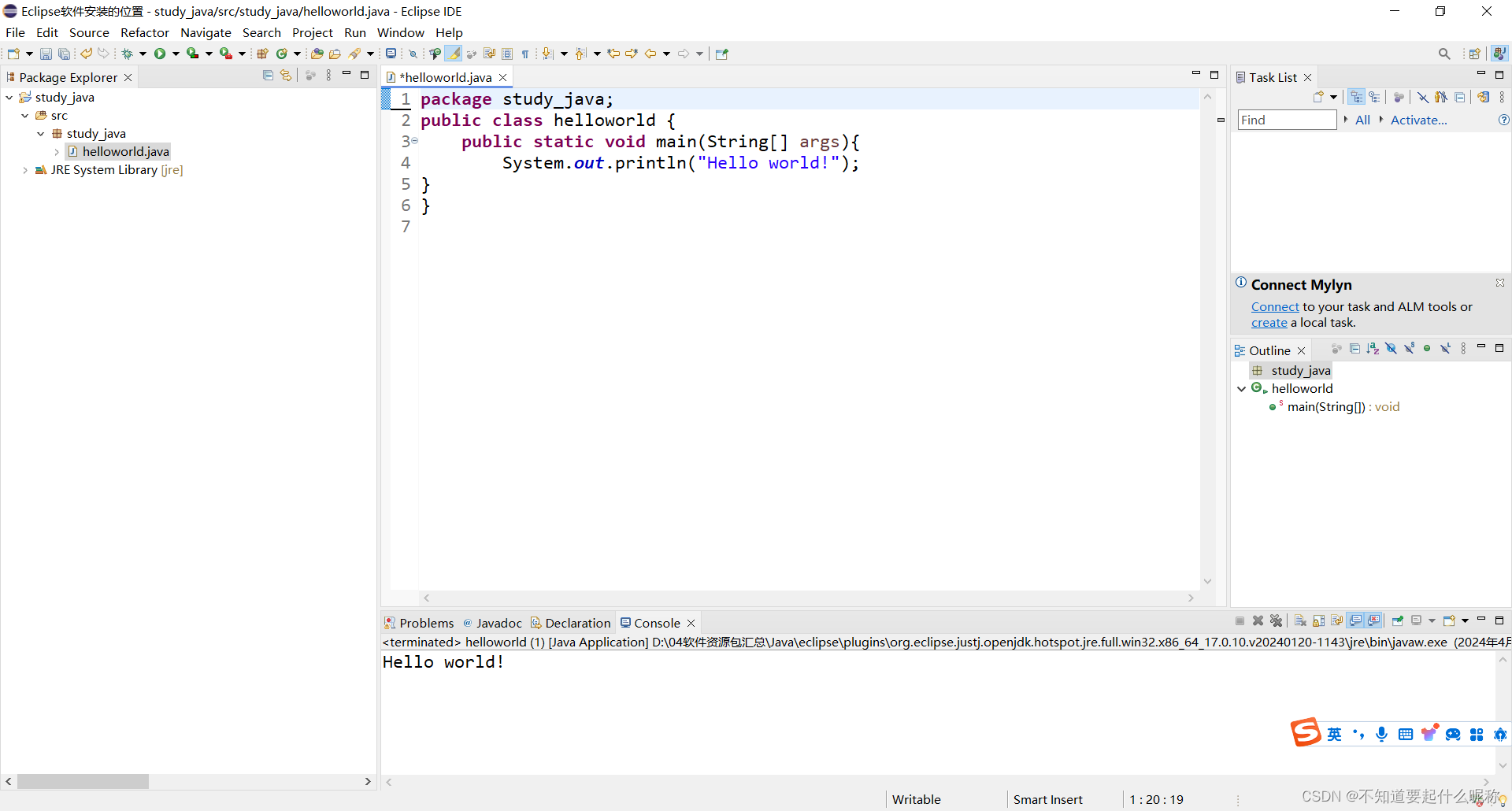
执行这些步骤后,你将拥有一个全新的Scrapy项目,可以在其中编写和运行你的爬虫代码。如果你想要创建新的爬虫,可以使用 genspider 命令来生成。例如:
cd myproject
scrapy genspider example example.com
这将在 spiders 目录中创建一个名为 example 的新爬虫,用于爬取 example.com 网站的数据。如图所示:
4. 项目文件结构及作用
scrapy.cfg: 项目的配置文件,包含了 Scrapy 项目的配置信息,比如项目的名称以及项目中使用的设置文件位置等。
myproject/: 项目的 Python 包,包含了项目的代码和其他资源文件。
__init__.py: 表明该目录是一个 Python 包。
items.py: 可选的文件,用于定义爬取的数据结构,通常使用 Scrapy 的 Item 类来定义数据模型。
middlewares.py: 可选的文件,包含了自定义的中间件,用于在请求和响应之间进行操作,例如添加代理、用户代理等。
pipelines.py: 可选的文件,包含了自定义的管道,用于对爬取到的数据进行处理,例如数据清洗、存储等操作。
settings.py: 项目的设置文件,包含了各种配置选项,如爬虫的延迟时间、并发请求数、用户代理等。
spiders/: 存放爬虫代码的目录,每个爬虫通常都是一个单独的 Python 文件。
__init__.py: 表明该目录是一个 Python 包。
二、实践:使用 Scrapy 爬取豆瓣电影 Top250
1.定义数据模型
在 Scrapy 中,我们使用 Item 对象来表示爬取到的数据。为了清晰地组织数据,我们需要定义一个数据模型来描述我们感兴趣的信息。在这个项目中,我们主要关注豆瓣电影 Top250 页面中的电影信息,因此我们创建一个名为 MovieItem 的数据模型来存储这些信息。
# File: your_project/items.pyimport scrapyclass MovieItem(scrapy.Item):# 定义了要爬取的关键信息字段ranking = scrapy.Field() # 排名name = scrapy.Field() # 电影名introduce = scrapy.Field() # 简介star = scrapy.Field() # 星级comments = scrapy.Field() # 评论数describe = scrapy.Field() # 描述
以上代码将这些信息定义为 Scrapy 的 Field 类型,这样可以方便后续爬取和处理。每个字段都对应了我们所感兴趣的电影信息,如排名、电影名、简介、星级、评论数和描述等。
2.编写爬虫
在这一部分,我们将创建一个 Spider 来爬取豆瓣电影 Top250 页面中的信息。我们将使用 Scrapy 提供的功能来轻松地提取页面中的数据,并将其存储到先前定义的数据模型中。
# File: your_project/spiders/douban_top250.pyimport scrapy
from ..items import MovieItemclass DoubanTop250Spider(scrapy.Spider):"""该 Spider 用于爬取豆瓣电影 Top250 页面的信息。"""name = 'douban_top250' # Spider 的名称allowed_domains = ['movie.douban.com'] # 允许爬取的域名start_urls = ['https://movie.douban.com/top250'] # 起始 URLdef parse(self, response):"""解析页面响应,提取电影信息并存储到 MovieItem 对象中:param response: 爬取到的页面响应:return: MovieItem 对象"""# 使用 XPath 选择器提取电影信息movies = response.xpath('//div[@class="item"]')for movie in movies:item = MovieItem() # 创建 MovieItem 对象来存储电影信息# 提取电影排名信息item['ranking'] = movie.xpath('div[@class="pic"]/em/text()').get()# 提取电影名称item['name'] = movie.xpath('div[@class="info"]/div[@class="hd"]/a/span[@class="title"]/text()').get()# 提取电影简介item['introduce'] = movie.xpath('div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span[@class="inq"]/text()').get()# 提取电影星级评分item['star'] = movie.xpath('div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').get()# 提取电影评论数item['comments'] = movie.xpath('div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[last()]/text()').get()# 提取电影描述信息item['describe'] = movie.xpath('div[@class="info"]/div[@class="bd"]/p[@class=""]/text()').get()yield item # 将 MovieItem 对象传递给 Scrapy 引擎# 继续爬取下一页数据next_page = response.xpath('//span[@class="next"]/a/@href').get()if next_page:yield scrapy.Request(response.urljoin(next_page), callback=self.parse)
在上述代码中,我们使用了 XPath 选择器来定位 HTML 页面中的元素,并提取我们感兴趣的信息。XPath 是一种用于在 XML 文档中导航和选择节点的语言。通过编写 XPath 表达式,我们可以精确定位到页面中的特定元素,从而提取我们需要的数据。
至于 XPath 选择器的代码,是通过观察豆瓣电影 Top250 页面的 HTML 结构而来的,我们根据页面的标签和类名来编写 XPath 表达式,从而定位到我们需要的电影信息。如图所示:
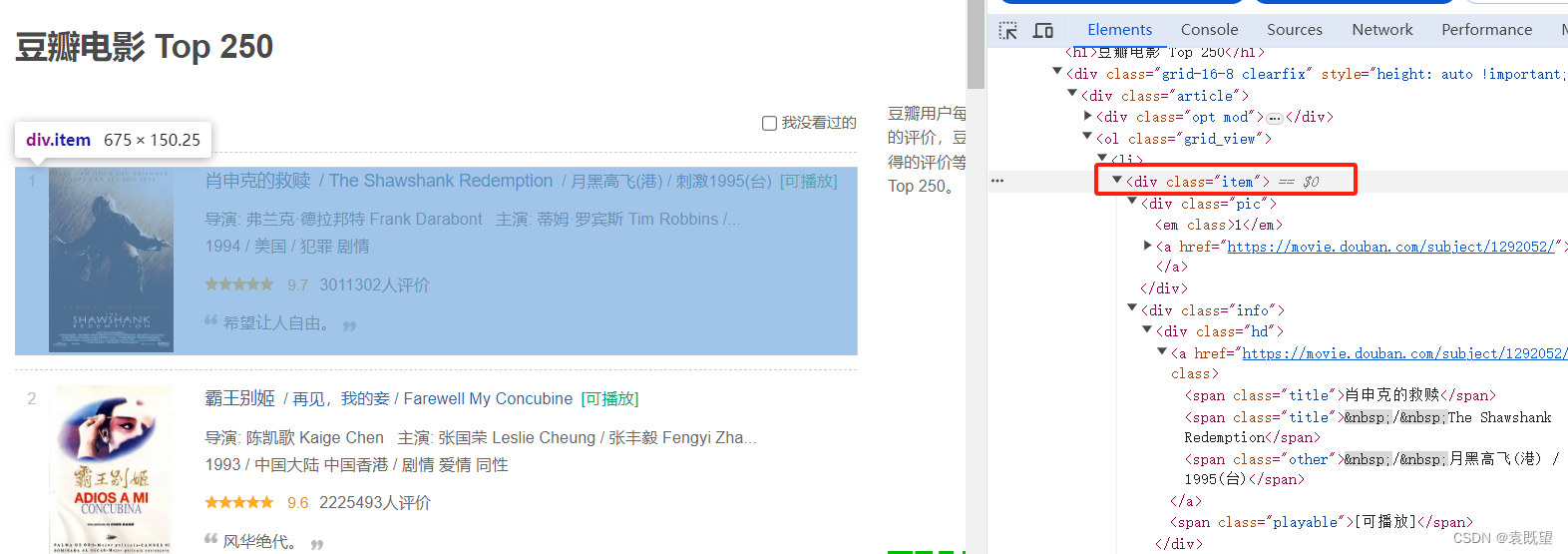
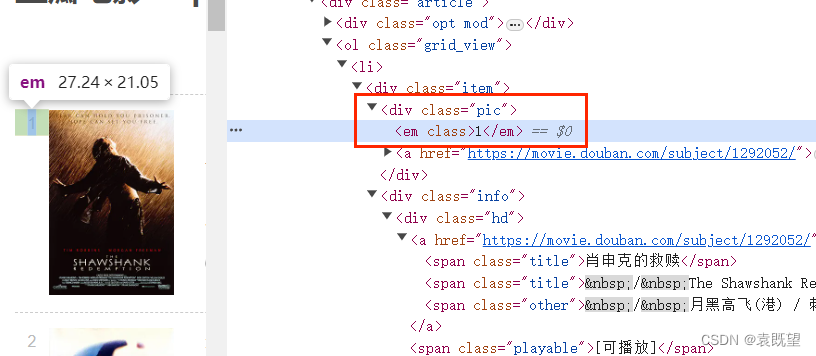
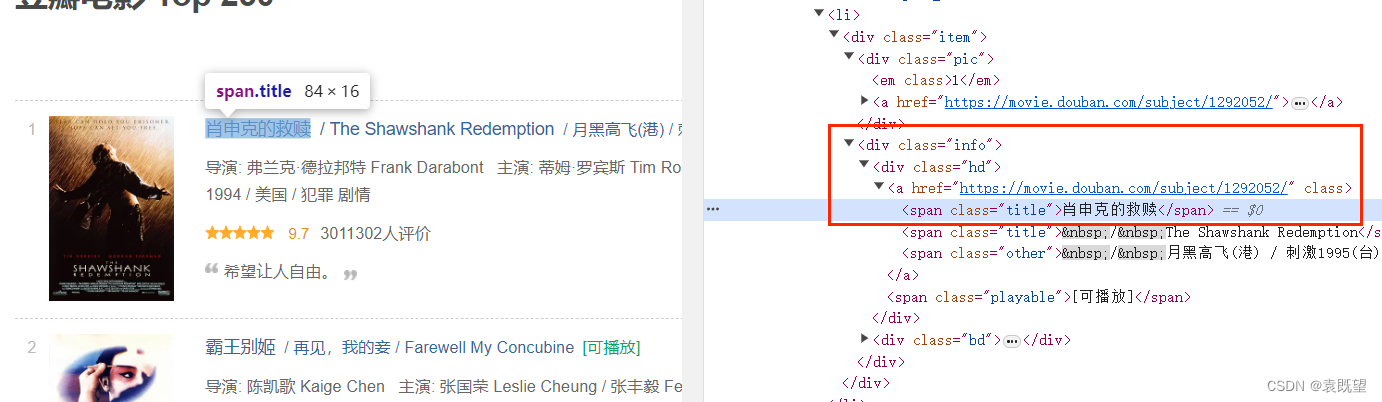
电影的所有信息都存在于<div class="item">中,其中排名(rank)的位置为<div class="pic">下的<em>标签中,电影标题的位置位于<div class="info">下的<div class="hd">下的<span class="title">标签中,以此类推即可写出其余元素的xpath代码
换页的xpath代码如图所示:
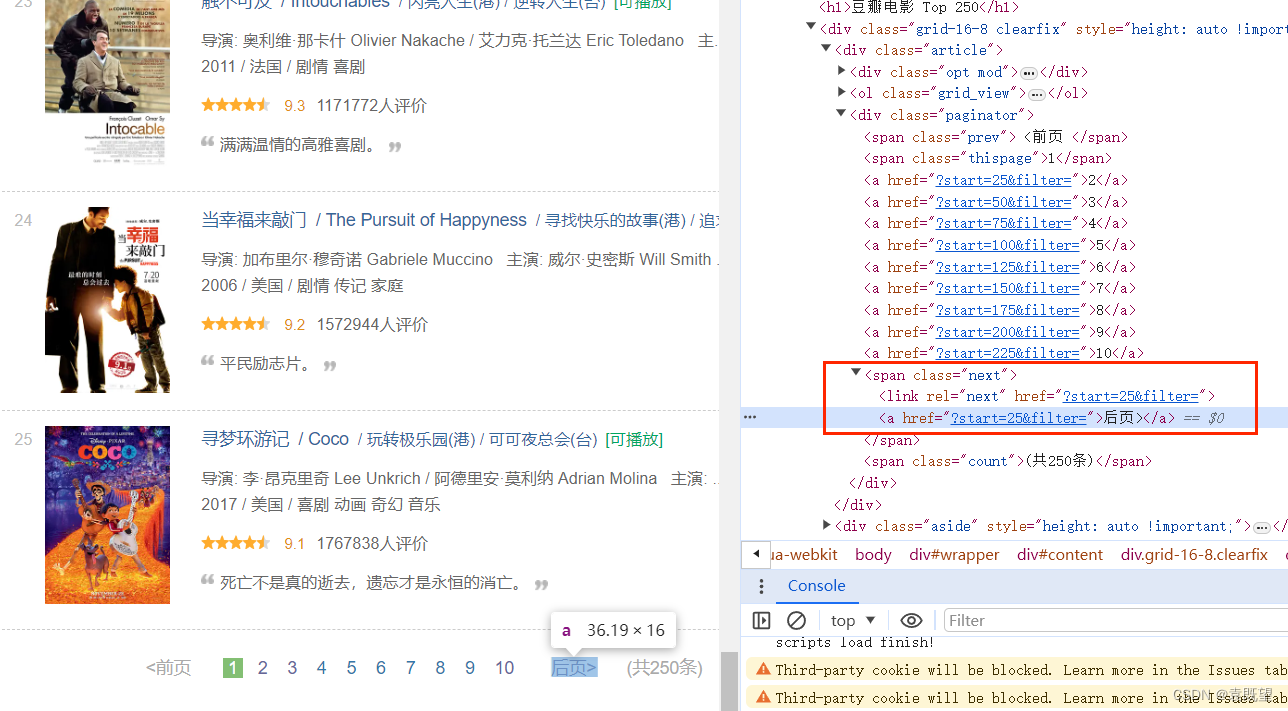
因网站源码可能重构导致xpath代码改变,实际应用时应根据实际情况修改代码
Xpath代码解释如下:
//div[@class="item"]: 这个 XPath 表达式选取了页面中所有class属性为 "item" 的div元素,这些元素包含了每部电影的信息。
div[@class="pic"]/em/text(): 这个 XPath 表达式选取了电影排名信息,其中div[@class="pic"]选择了每部电影的海报div元素,em选择了其中的em元素,然后使用text()方法提取其中的文本内容。
div[@class="info"]/div[@class="hd"]/a/span[@class="title"]/text(): 这个 XPath 表达式选取了电影名称信息,首先选择了包含电影信息的div元素,然后进一步选择了class属性为 "hd" 的div元素,接着选择了其中的a元素,然后选择了span元素,最后使用text()方法提取了电影名称的文本内容。
div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span[@class="inq"]/text(): 这个 XPath 表达式选取了电影简介信息,依次选择了包含电影信息的div元素、class属性为 "bd" 的div元素、p元素、class属性为 "quote" 的p元素、span元素,并提取了其中的文本内容。
div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text(): 这个 XPath 表达式选取了电影星级评分信息,选择了包含电影信息的div元素、class属性为 "bd" 的div元素、class属性为 "star" 的div元素、span元素、class属性为 "rating_num" 的span元素,并提取了其中的文本内容。
div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[last()]/text(): 这个 XPath 表达式选取了电影评论数信息,选择了包含电影信息的div元素、class属性为 "bd" 的div元素、class属性为 "star" 的div元素、最后一个span元素,并提取了其中的文本内容。
div[@class="info"]/div[@class="bd"]/p[@class=""]/text(): 这个 XPath 表达式选取了电影描述信息,选择了包含电影信息的div元素、class属性为 "bd" 的div元素、p元素、其中没有设置class属性的p元素,并提取了其中的文本内容。
此外,parse 方法是 Scrapy 中用于解析页面响应的方法。当 Scrapy 发起请求并获取到页面响应后,会自动调用 parse 方法来处理响应,并在其中编写代码来提取数据。parse 方法中的 response 参数包含了爬取到的页面响应,我们可以使用它来提取页面中的信息。
3.中间件设置
有时为了应对网站的反爬虫机制,我们需要对 Scrapy 的下载中间件进行一些设置,以伪装请求并防止被识别为爬虫。在这个项目中,我们可以通过设置随机的 User-Agent 和使用 IP 代理来模拟不同的用户和 IP 地址发送请求。
首先,我们需要在中间件中添加随机 User-Agent 的设置。我们可以在 middlewares.py 文件中创建一个类,名为 RandomUserAgentMiddleware,用于为每个请求随机选择一个 User-Agent,并将其添加到请求头中。
# File: your_project/middlewares.pyimport random
class user_agent(object):def process_request(self, request, spider):# user agent 列表USER_AGENT_LIST = ['MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23','Opera/9.20 (Macintosh; Intel Mac OS X; U; en)','Opera/9.0 (Macintosh; PPC Mac OS X; U; en)','iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)','Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)','iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0','Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)','Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)']agent = random.choice(USER_AGENT_LIST) # 从上面列表中随机抽取一个代理request.headers['User-Agent'] = agent # 设置请求头的用户代理在上述代码中,我们创建了一个名为 RandomUserAgentMiddleware 的类,它的 process_request 方法用于处理每个请求,为每个请求随机选择一个 User-Agent,并将其添加到请求头中。其中 USER_AGENT_LIST 是在 settings.py 中定义的用户代理列表。
我们还可以添加一个 IP 代理的设置,以应对可能的 IP 封锁或限制。这里不再详细列举代码,你可以在 middlewares.py 中创建一个类来实现该功能,并在 settings.py 中设置相应的 IP 代理列表。
最后,我们需要在 settings.py 文件中启用这些中间件,并设置它们的优先级:
# File: your_project/settings.pyDOWNLOADER_MIDDLEWARES = {'myproject.middlewares.user_agent': 543,
}
在上述代码中,我们将 RandomUserAgentMiddleware 设置为 DOWNLOADER_MIDDLEWARES 字典的值,并指定了优先级为 543。你也可以根据实际情况添加 IP 代理中间件,并设置相应的优先级。
这样,当我们运行 Scrapy 项目时,每个请求就会随机选择一个 User-Agent,并根据需要使用 IP 代理发送请求,以应对网站的反爬虫机制。
4.数据存储
当我们选择将数据存储到 CSV 文件中时,我们需要在 Scrapy 项目中编写一个专门的 Pipeline,负责将爬取到的数据写入 CSV 文件中。下面是一个示例:
# File: your_project/pipelines.pyimport csvclass CSVPipeline:"""Pipeline 类,用于将爬取到的数据存储到 CSV 文件中"""def __init__(self, csv_file_path):"""初始化方法,设置 CSV 文件路径"""self.csv_file_path = csv_file_path@classmethoddef from_crawler(cls, crawler):"""类方法,从 Scrapy 配置中获取 CSV 文件路径"""return cls(csv_file_path=crawler.settings.get('CSV_FILE_PATH'))def open_spider(self, spider):"""在 Spider 开始爬取时调用,打开 CSV 文件并写入表头"""self.csv_file = open(self.csv_file_path, 'w', newline='', encoding='utf-8')# 创建 CSV 写入器,并写入表头,这里的表头根据 MovieItem 的字段来确定self.csv_writer = csv.DictWriter(self.csv_file, fieldnames=['ranking', 'name', 'introduce', 'star', 'comments', 'describe'])self.csv_writer.writeheader()def close_spider(self, spider):"""在 Spider 结束爬取时调用,关闭 CSV 文件"""self.csv_file.close()def process_item(self, item, spider):"""处理每个 Item 对象,将其写入 CSV 文件中"""# 使用 CSV 写入器将 Item 写入 CSV 文件self.csv_writer.writerow(item)return item
在上述代码中,我们定义了一个名为 CSVPipeline 的 Pipeline 类,它负责将爬取到的数据存储到 CSV 文件中。在该 Pipeline 中,我们实现了四个方法:
__init__方法:用于初始化 CSV 文件路径。from_crawler类方法:用于从 Scrapy 的配置中获取 CSV 文件路径。open_spider方法:在 Spider 开始爬取时调用,用于打开 CSV 文件并写入表头。close_spider方法:在 Spider 结束爬取时调用,用于关闭 CSV 文件。process_item方法:处理每个 Item 对象,将其写入 CSV 文件中。
接下来,我们需要在 Scrapy 项目的 settings.py 文件中设置 CSV 文件的路径:
# File: your_project/settings.pyCSV_FILE_PATH = 'douban_movies.csv'
最后,我们需要在 settings.py 中启用该 Pipeline:
# File: your_project/settings.pyITEM_PIPELINES = {'your_project.pipelines.CSVPipeline': 300,
}
这样,当我们运行 Scrapy 项目时,爬取到的电影信息就会被存储到名为 douban_movies.csv 的 CSV 文件中了
5.启动Scrapy项目
在实际应用中,启动Scrapy项目有多种方式,以下是其中一些:
5.1 使用命令行工具
Scrapy提供了命令行工具,可以让你直接在终端中启动项目。使用 scrapy crawl 命令,你可以指定要运行的Spider以及输出的文件格式和路径。例如:
scrapy crawl douban_top250这里没有指定 -o douban_movies.csv 输出文件路径,因为数据存储已经在Pipeline中设置。
5.2 编写Python脚本
你也可以编写一个简单的Python脚本来启动Scrapy项目。在脚本中,导入你的Spider类,并调用Scrapy的 crawl() 函数来运行Spider。以下是一个示例:
from scrapy import cmdlinecmdline.execute("scrapy crawl douban_top250".split())
与命令行工具一样,在这个示例中我们也没有指定输出文件路径。
5.3 使用Scrapy的CrawlerProcess
使用Scrapy的 CrawlerProcess 类来编写自定义的启动脚本。这种方式更加灵活,可以更好地控制Scrapy的运行方式。以下是一个示例:
from scrapy.crawler import CrawlerProcess
from myproject.spiders import MySpider# 创建一个 CrawlerProcess 实例
process = CrawlerProcess()# 向进程中添加要运行的 Spider,这里使用了自定义的 MySpider
process.crawl(MySpider)# 开始运行爬虫,直到所有爬虫完成
process.start()
这段代码将会启动指定的Spider,并且会按照它们在 process.crawl() 中被添加的顺序依次运行。你可以根据需要添加更多的Spider。
5.4 使用Scrapyd
Scrapyd是一个用于部署和管理Scrapy项目的工具,你可以将Scrapy项目部署到Scrapyd服务器上,并通过HTTP API来控制项目的启动和停止。
通过以上几种启动方法,你可以根据项目需求和个人偏好来选择最合适的方式。Scrapy提供了灵活而强大的工具来满足你的爬虫需求。
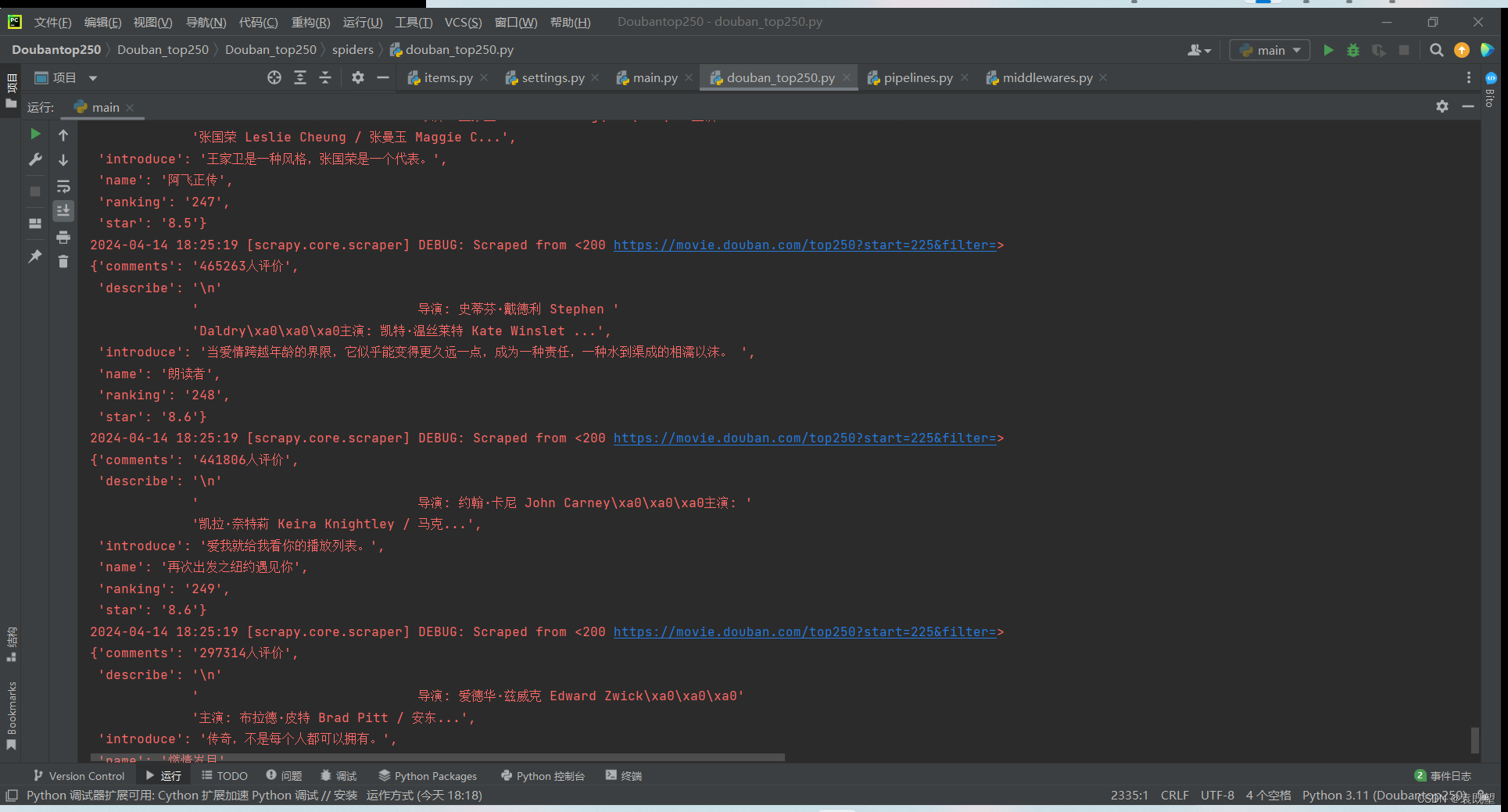
如图所示,均已准确爬取
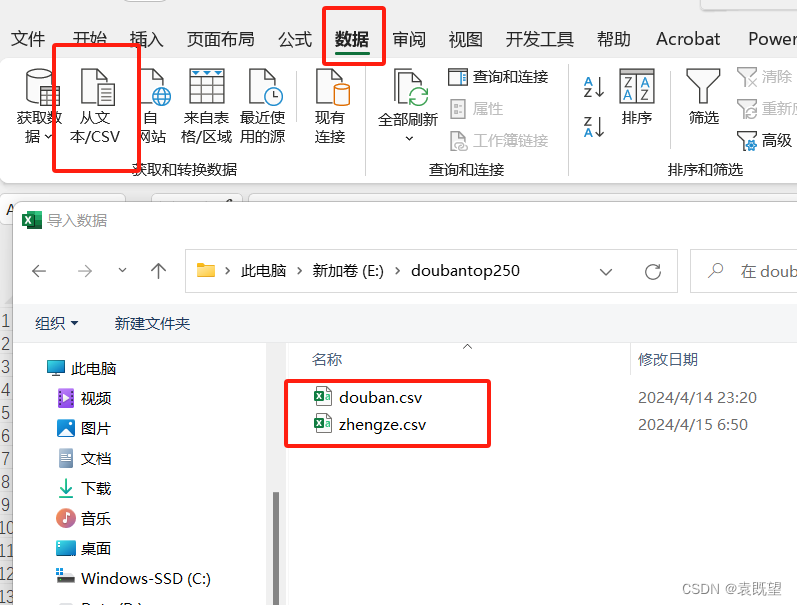
这里给大家说明一个常见问题的解决方案,当你直接用excel打开csv代码乱码时,可通过以下方法解决,如图所示选择数据—>从文本/csv文件导入,选择文件即可
三、使用正则表达式从电影介绍详情中提取指定信息
目标:爬取电影详情页面中介绍详情内容中括号包裹的内容
在这个项目中,我们仍然可以套用第二部分的大致代码结构,但需要针对新的需求进行一些调整。主要区分点包括:
-
爬取的内容不同,需要重写
items类:
由于我们要从电影详情页面提取的信息不同于之前的需求,我们需要重新定义items.py文件中的数据模型。这意味着我们需要修改数据模型中的字段,以便适应新的数据结构。例如,我们可能需要添加一个字段来存储电影简介中的括号内容。 -
根据网页具体情况重写
spider文件:
鉴于我们现在要爬取的是豆瓣电影详情页面,而不是之前的 Top250 页面,我们需要对spider.py文件进行重写。这意味着我们需要更新爬取页面的 URL,修改解析函数以匹配电影详情页面的 HTML 结构,并调整数据提取逻辑以确保我们可以准确地提取电影简介中的括号内容。
除了这些主要区分点之外,我们的项目结构和工作流程将保持大致相同。我们仍然会使用 Scrapy 框架来构建我们的爬虫,利用其强大的功能来快速而高效地提取所需信息。
在下一步中,我们将详细讨论如何重写 items.py 和 spider.py 文件,以满足新的需求。
1.定义数据模型
对于本项目,我们打算爬取豆瓣电影页面,因此需要定义一个数据模型来存储电影信息。
首先,我们将创建一个名为 ZhengzeItem 的类,该类继承自 Scrapy 的 Item 类。这个类将包含两个字段:
title:用于存储电影的标题。parenthesis_content:用于存储电影剧情简介中带括号的内容。
在添加完数据模型后,我们需要修改数据管道以适应新的数据模型并存储到 CSV 文件中。以下是对 items.py 和 pipelines.py 文件的修改说明:
在 items.py 文件中:
import scrapyclass ZhengzeItem(scrapy.Item):"""数据模型:定义了爬取电影详情页面所需的字段Fields:title (str): 电影标题parenthesis_content (str): 电影剧情简介中带括号的内容"""# 电影标题title = scrapy.Field()# 电影剧情简介中带括号的内容parenthesis_content = scrapy.Field()
这里我们定义了一个名为 ZhengzeItem 的数据模型,包含了电影标题和剧情简介中带括号的内容两个字段,以适应我们从豆瓣电影页面爬取的数据。
在 pipelines.py 文件中:
import csvclass CSVPipeline:"""数据管道:将爬取的电影信息存储为 CSV 文件"""def __init__(self, settings):self.settings = settingsself.file = None@classmethoddef from_crawler(cls, crawler):settings = crawler.settingsreturn cls(settings)def open_spider(self, spider):self.file = open(self.settings.get('CSV_FILE_PATH'), 'w', newline='', encoding='utf-8')self.writer = csv.writer(self.file)self.writer.writerow(['Title', 'Parenthesis Content'])def close_spider(self, spider):if self.file:self.file.close()def process_item(self, item, spider):title = str(item.get('title', ''))parenthesis_content = str(item.get('parenthesis_content', ''))self.writer.writerow([title, parenthesis_content])return item
在这里,我们修改了数据管道 CSVPipeline 的代码,使用了 csv 模块来将爬取的电影信息存储到 CSV 文件中。通过这样的修改,我们可以确保爬取的数据能够被正确地存储和处理。
2.编写爬虫
当编写爬虫时,首先要考虑的是如何访问每个电影的详情页面。在这个项目中,我们需要访问豆瓣电影网站上排名前250的电影的详情页面。为了实现这一目标,我们需要先找到每个电影的链接。
步骤:
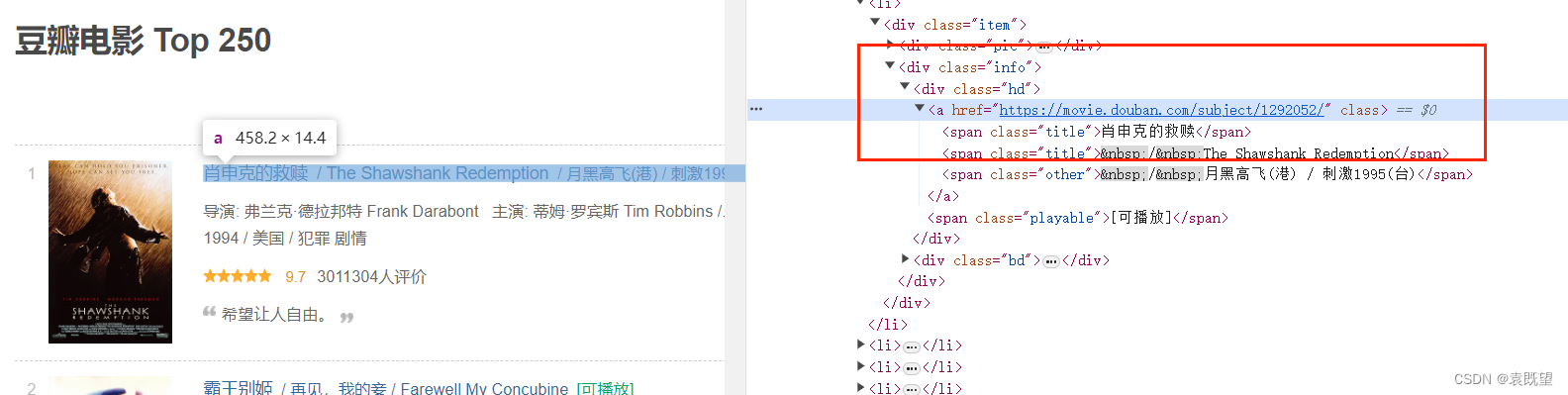
1. 通过XPath找到每个电影的详情页链接:
- 我们首先分析豆瓣电影Top250页面的HTML结构,确定每个电影链接所在的位置,并编写XPath表达式来定位这些链接。
2. 使用Scrapy发送HTTP请求访问每个电影的详情页:
- 通过Scrapy的
scrapy.Request()方法,我们可以根据之前获取到的链接,发送HTTP请求访问每个电影的详情页面。3. 提取详情页面中的内容:
- 一旦我们成功访问了每个电影的详情页,我们需要从页面中提取出电影标题和电影简介中用括号括起来的内容。为了实现这一步,我们可以使用XPath或其他解析方法来定位这些信息。
4. 使用正则表达式提取所需内容:
- 在获取到详情页的HTML源码后,我们可以使用正则表达式来进一步提取所需内容。针对电影简介中用括号括起来的内容,我们可以编写正则表达式来匹配并提取出来。
5. 保存提取到的数据到CSV文件:
- 最后一步是将提取到的数据保存到CSV文件中。我们可以使用Python的CSV模块来创建CSV文件,并将数据写入其中。确保数据格式的正确性和完整性,以便后续的分析和使用。
xpath寻找过程:
2.1 寻找每个电影的详情页链接(如图所示)
2.2 寻找详情页面中的内容(这里会遇到2个BUG)
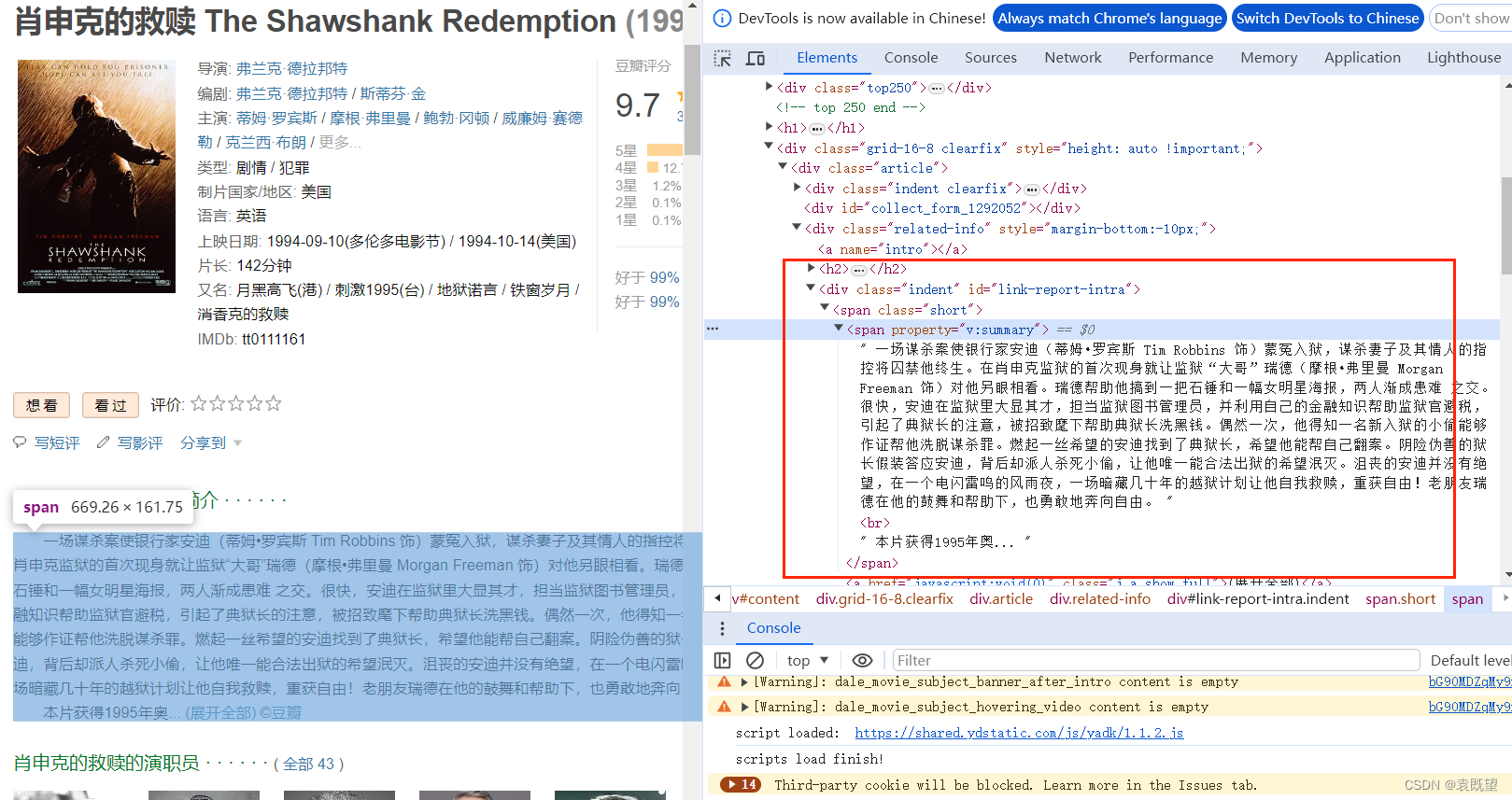
BUG1:
在后续爬取过程中发现,爬取内容缺失,如下图所示,仅爬取到了第1段内容,第二段之后未爬取到,查看源码发现<br>之后的内容未爬取到,因此修改代码中的xpath,在前面加上normalize-space()即可解决
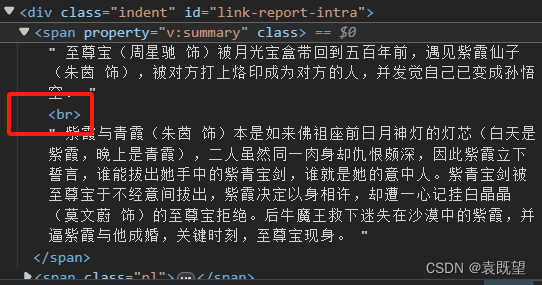
因为当网页中包含 `<br>` 标签时,提取文本内容可能会出现问题,因为 `<br>` 标签表示换行,但在XPath表达式中并不会被视为分隔符。因此,文本内容可能会被 `<br>` 标签打断,导致提取的结果不完整或不正确。
为了解决这个问题,我们可以使用 XPath 中的 `normalize-space()` 函数。这个函数的作用是移除文本字符串中开头和结尾的空白字符,并将字符串中的连续空白字符替换为单个空格,从而将文本内容规范化为一个整体。
在这个例子中,我们将 `normalize-space()` 函数应用在XPath表达式的结果上,这样就可以确保提取的文本内容不会被 `<br>` 标签打断,而是被规范化为一段连续的文本。因此,无论 `<br>` 标签在哪里,我们都可以正确提取简介文本,而不会受到其影响。
解决后如图所示,全部正确爬取:
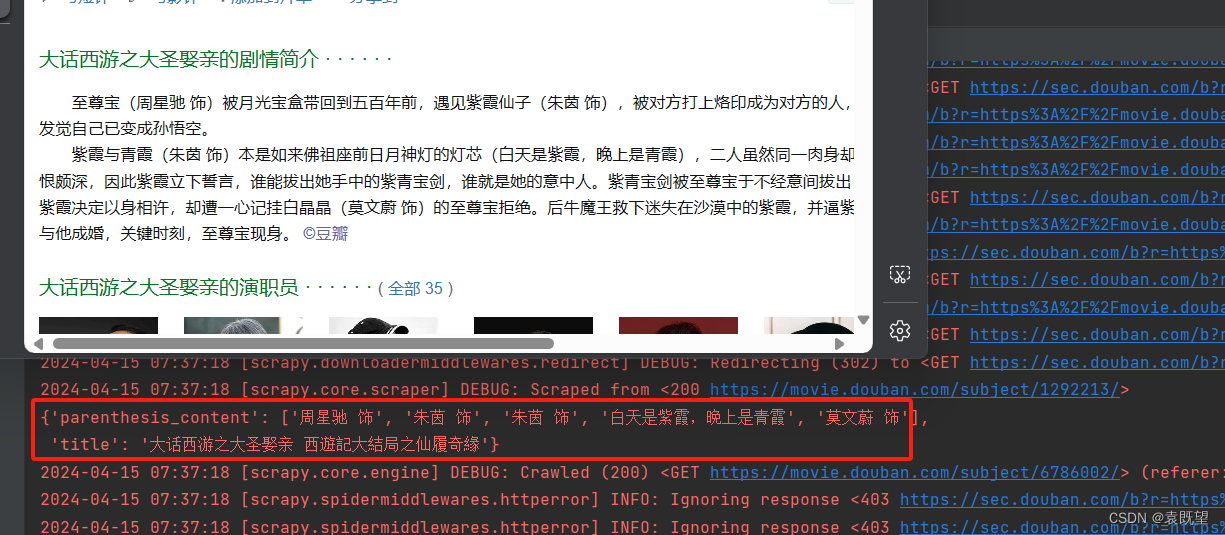
BUG2:
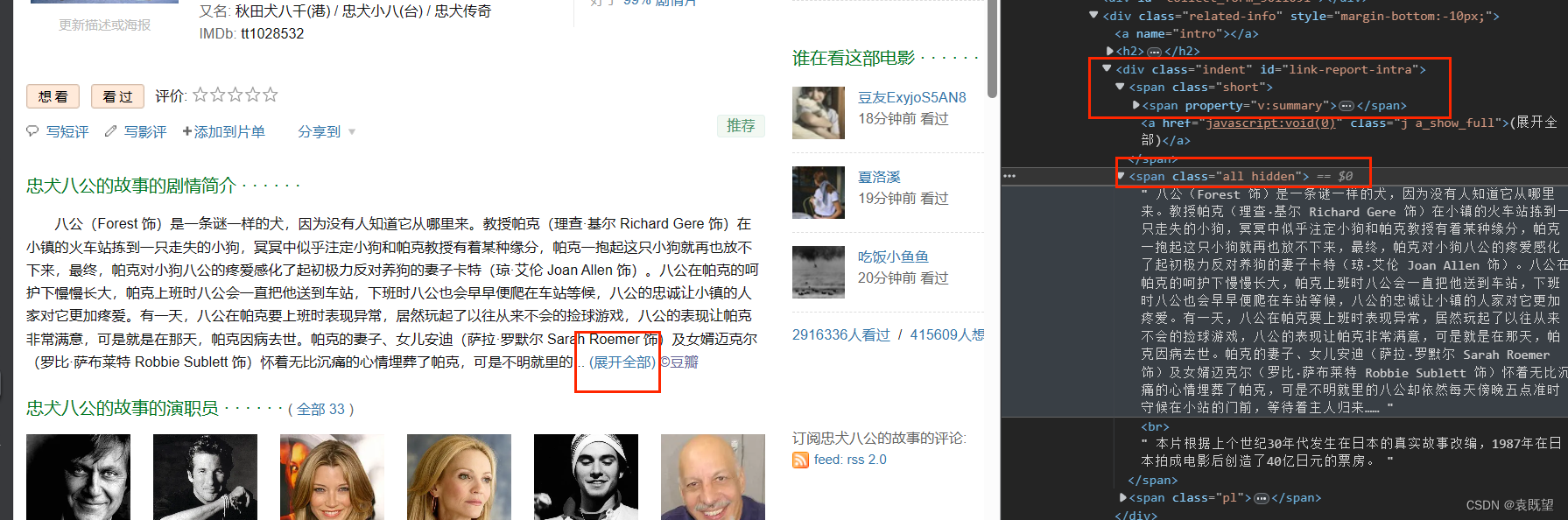
解决BUG1之后发现,仍有部分文章爬取到的内容为空,查看网站源码即可发现,存在不同的xpath解析路径,如下图所示,图1电影详情全部展示并存在于<span property="v:summary" class="">之下,图2的电影详情存在(展开全部)按钮,并且文章内容存储在<span class="all hidden">之下,而之前的代码仅包含第一种情况,因此将修改xpath代码为:
normalize-space(//div[@id="link-report-intra"]/span[@class="all hidden" or @property="v:summary即可同时匹配以上两种情况
图1:
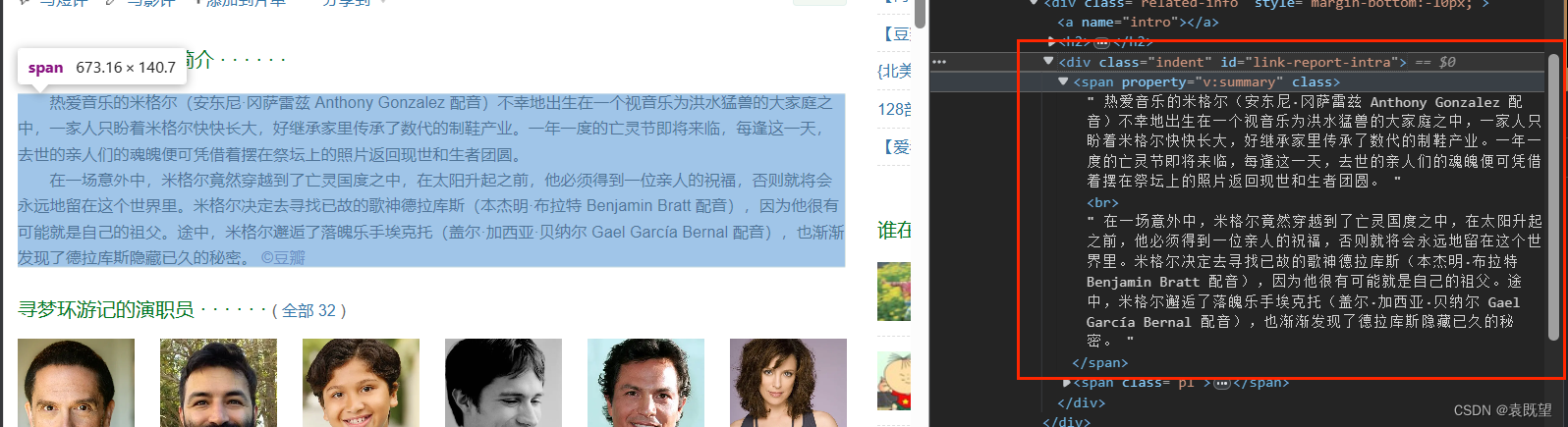
图2:
2.3 正则表达式
当提取电影简介中的括号内内容时,我们需要使用正则表达式来匹配括号中的文本。但是,并非所有电影简介都包含括号,因此我们需要处理这种情况,以避免出现错误。
代码解析:
import reif synopsis:# 定义正则表达式来匹配带括号的内容,使用多行模式(re.DOTALL)parenthesis_pattern = r'(([^)]*))' # 匹配括号内的内容parenthesis_matches = re.findall(parenthesis_pattern, synopsis, re.DOTALL)# 对每个匹配到的括号内容字符串调用 strip() 方法去除空格,并生成新的列表parenthesis_matches_stripped = [match.strip() for match in parenthesis_matches]
else:parenthesis_matches_stripped = []
解释:
if synopsis::此条件语句检查电影简介是否存在内容。如果简介非空,则执行下一步操作。parenthesis_pattern = r'(([^)]*))':这里定义了一个正则表达式模式,用于匹配括号中的内容。r前缀表示原始字符串,以避免反斜杠转义问题。模式(([^)]*))匹配括号内的任何字符,直到遇到右括号为止。re.findall(parenthesis_pattern, synopsis, re.DOTALL):使用re.findall函数在synopsis中查找所有匹配parenthesis_pattern的内容,并使用re.DOTALL标志以匹配换行符。[match.strip() for match in parenthesis_matches]:对于每个匹配到的括号内容字符串,使用strip()方法去除首尾的空格,并将结果存储在parenthesis_matches_stripped列表中。- 如果电影简介为空,则将
parenthesis_matches_stripped设置为空列表,以避免出现错误。
通过这种方式,我们可以确保在提取电影简介中的括号内内容时,代码能够正确处理各种情况,包括简介为空或简介中没有括号的情况。
2.4 实际爬虫过程中遇到的问题和解决方案
2.4.1 爬取过程中重定向到登陆页面
如图所示:出现302重定向,点击去发现是跳转到登陆页面了
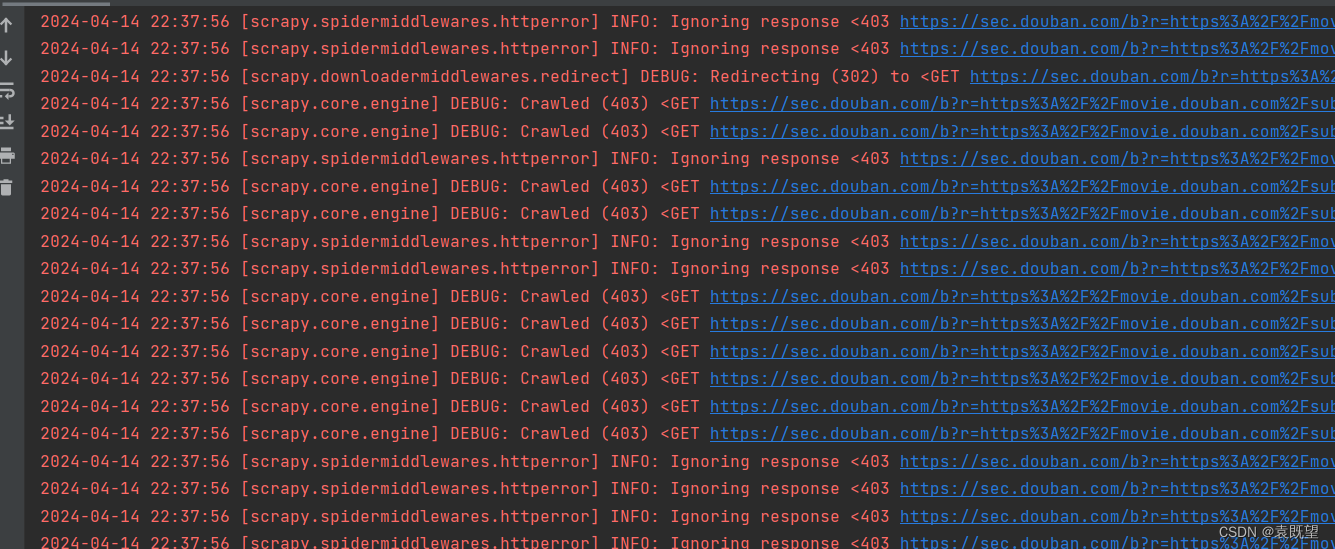
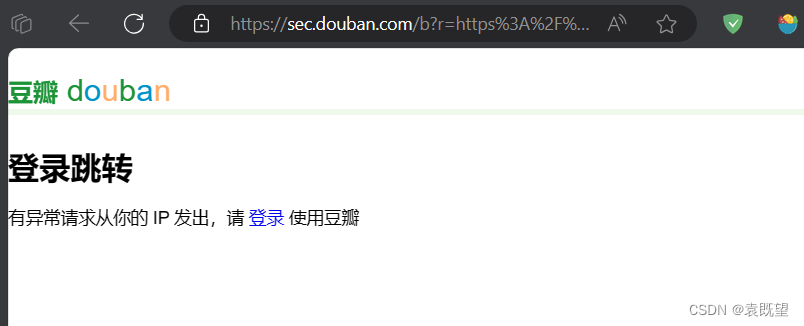
这是通常是因为网站对未登录用户进行了重定向以保护内容或者限制访问。302状态码表示临时重定向,通常用于指示需要进行授权或者登录才能访问资源。
解决这个问题的方法之一是设置请求头中的cookie,以模拟登录状态。登录网站后,浏览器会将一些身份验证信息存储在cookie中,并在之后的请求中发送给服务器。通过在爬虫中设置相同的cookie,可以让服务器认为爬虫是已登录的用户,从而避免跳转到登录页面。
如图所示,登录后在network中找到cookie,然后复制添加到爬虫文件中即可,代码放在本段最后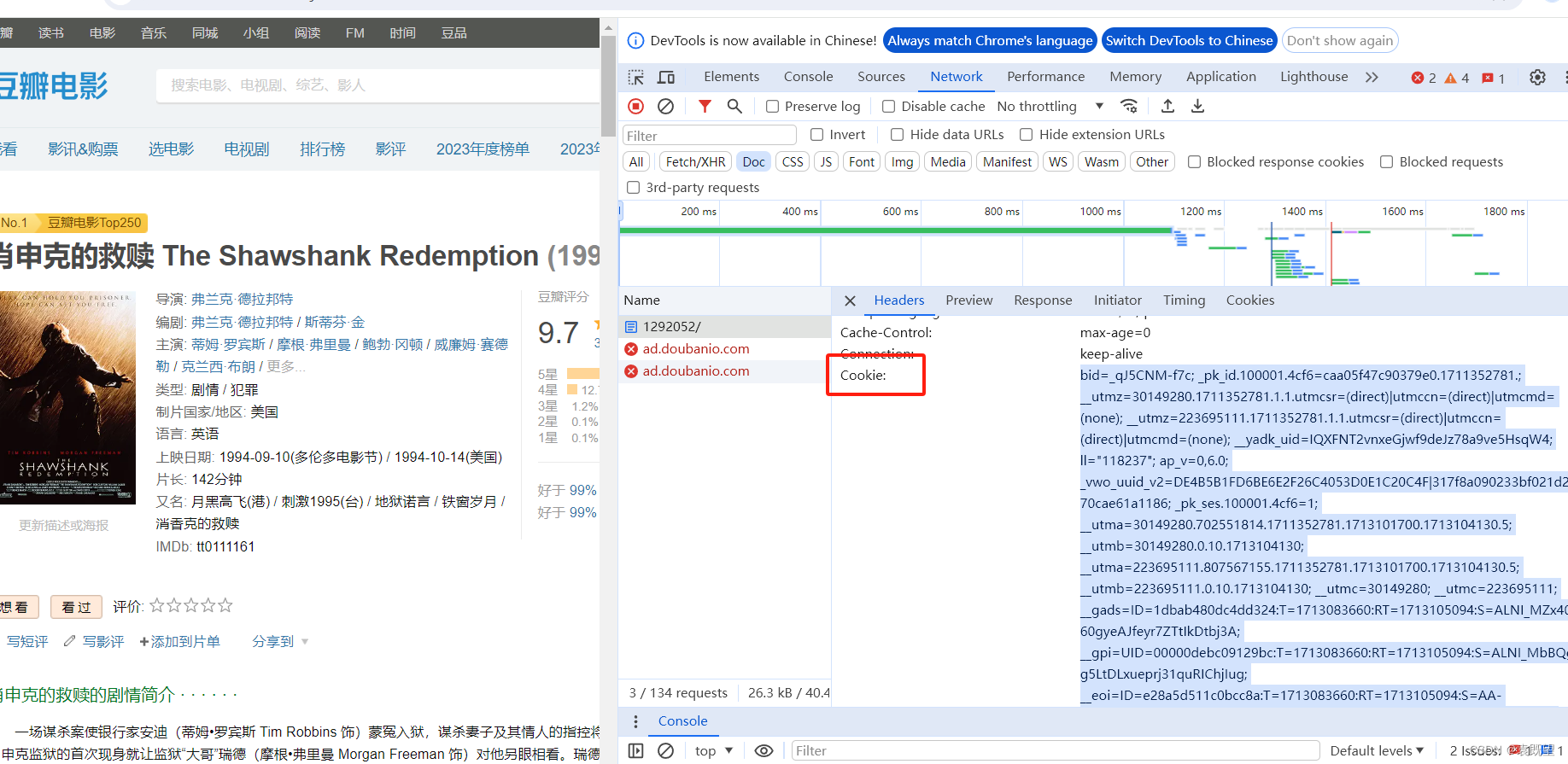
同时一定要注意!!!你的cookie是电脑端,所以UA池中不能存在安卓端的内容,如图所示就会被反爬机制查到!!!

2.4.2 被反爬机制查到的解决方案
如图所示,爬取过程中出现302重定向到了以下界面
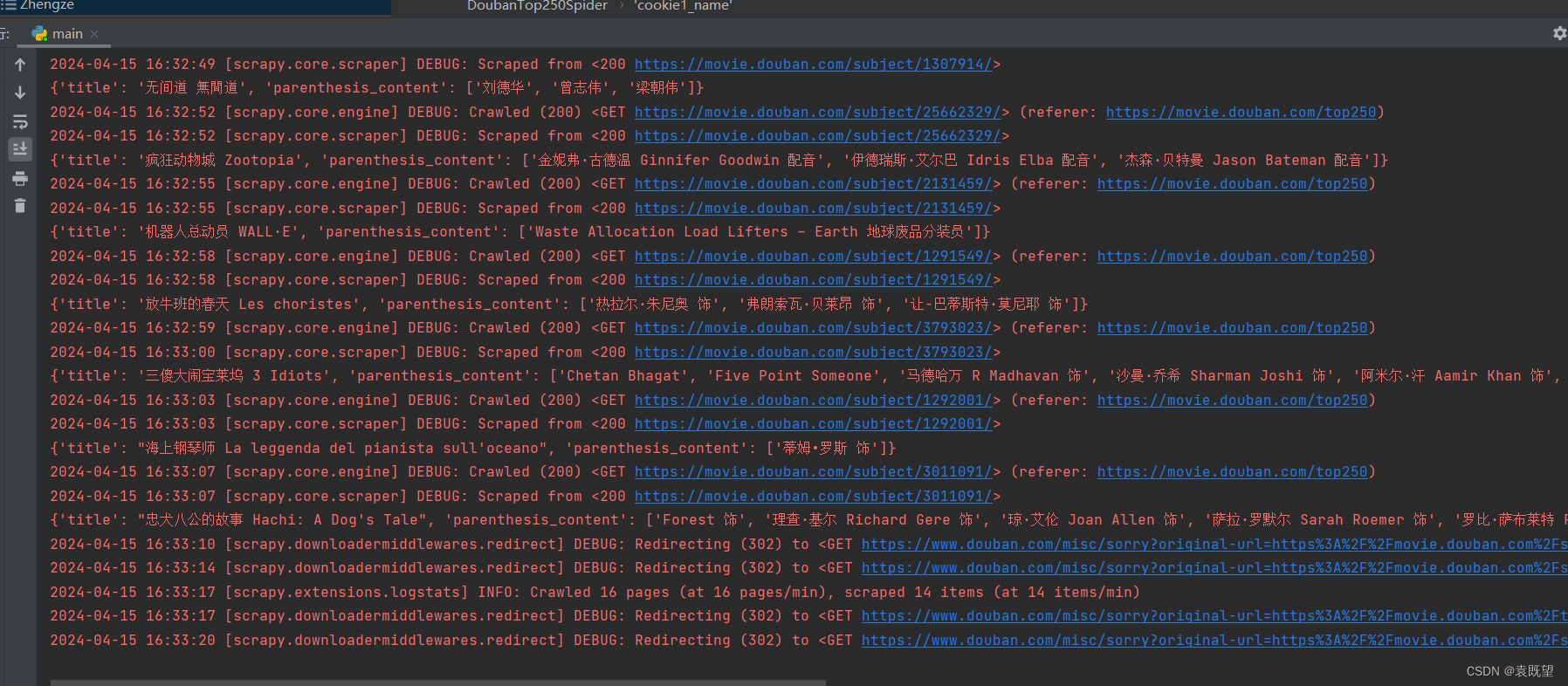
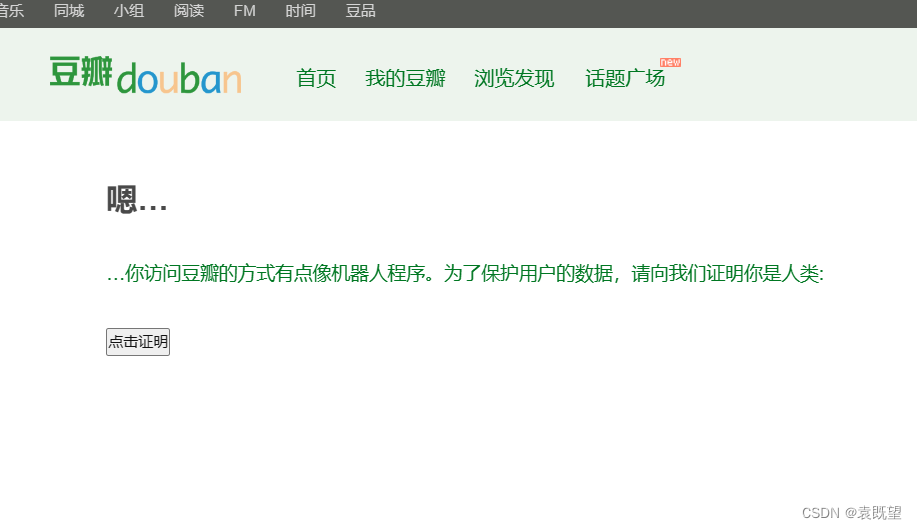
跳转到机器人检测界面可能是由于网站的反爬机制检测到了你的爬虫行为。网站的反爬机制可以检测到访问模式、频率、请求头等与正常用户不同的行为,并将其识别为爬虫或机器人。
为了规避这些反爬机制,你可以尝试以下几种方法:
设置合理的请求头信息: 模拟浏览器的行为,包括设置User-Agent、Referer等请求头,使请求看起来更像是来自正常的浏览器而不是爬虫。
降低访问频率: 适当控制爬取的速度,避免短时间内发送过多的请求,模拟正常用户的访问行为。
使用代理IP: 使用代理IP进行请求,以隐藏你的真实IP地址,减少被网站识别为爬虫的可能性。
处理验证码: 如果跳转到机器人检测界面是因为验证码的原因,可以通过自动识别验证码的方式来解决。
模拟登录: 如果网站要求登录后才能访问内容,可以尝试模拟登录并保存登录状态,以维持登录状态进行后续的请求。
动态切换请求头和IP: 定期更换请求头信息和IP地址,增加反爬机制的识别难度。
需要注意的是,绕过反爬机制可能违反网站的使用条款,造成不必要的麻烦。建议在进行爬取之前,先查看网站的使用政策,并尊重网站所有者的规定。
我这里使用了如下方法来成功绕过反爬虫检测:
设置随机User-Agent: 通过中间件
RandomUserAgentMiddleware在每次请求中随机选择一个User-Agent,以模拟不同浏览器或设备的访问行为,降低被识别为爬虫的可能性。设置随机请求延迟: 通过设置随机的下载延迟时间,即
DOWNLOAD_DELAY_MIN和DOWNLOAD_DELAY_MAX之间的随机时间,可以避免请求过于频繁,减少被网站识别为爬虫的概率。启用Cookie: 通过将
COOKIES_ENABLED设置为True,启用了Cookie,这可以在一定程度上帮助维持登录状态或者处理网站基于Cookie的认证机制。
另外,如果同一个ip下爬取次数过多可能会造成IP封禁,如果你和博主一样使用笔记本电脑的话,可以尝试切换不同手机热点的方式去改变IP
尝试切换不同手机热点是一种常见的方式来改变IP地址。使用不同的网络连接(比如不同的WiFi网络或者移动数据网络)可以改变你的出口IP地址,从而规避一些网站的IP封禁。然而,需要注意的是,一些网站可能会采取更复杂的反爬虫措施,不仅仅会封禁单个IP地址,还可能会监测用户的行为模式,比如频繁的爬取请求,从而对整个IP段进行封禁或者采取其他限制措施。
因此,尽管切换IP地址是一种常见的应对措施,但是并不一定总是有效的。在进行网络爬取时,最好遵守网站的robots.txt协议和使用适当的爬取速率来避免被封禁。
settings.py文件内容如下:
BOT_NAME = "Zhengze"
ROBOTSTXT_OBEY = FalseSPIDER_MODULES = ["Zhengze.spiders"]
NEWSPIDER_MODULE = "Zhengze.spiders"
COOKIES_ENABLED = True# 中间件配置
DOWNLOADER_MIDDLEWARES = {'Zhengze.middlewares.RandomUserAgentMiddleware': 543, # 设置随机User-Agent中间件的优先级# 'Zhengze.middlewares.ProxyMiddleware': 544, # 设置随机User-Agent中间件的优先级
}import random# 设置一个随机延迟范围,比如 1 到 3 秒之间
DOWNLOAD_DELAY_MIN = 0
DOWNLOAD_DELAY_MAX = 1# 生成随机延迟时间
delay = random.uniform(DOWNLOAD_DELAY_MIN, DOWNLOAD_DELAY_MAX)# 使用动态延迟时间
DOWNLOAD_DELAY = delay# CSV输出路径设置
CSV_FILE_PATH = 'E:/doubantop250/Zhengze.csv'# 数据处理管道设置
ITEM_PIPELINES = {'Zhengze.pipelines.CSVPipeline': 300,
}
最终爬虫文件如下:
import scrapy
import re
from ..items import ZhengzeItem
from bs4 import BeautifulSoupclass DoubanTop250Spider(scrapy.Spider):name = "Zhengze"allowed_domains = ["movie.douban.com"]start_urls = ["https://movie.douban.com/top250"]# 设置你的 cookiecustom_cookies = {'cookie1_name': 'bid=_qJ5CNM-f7c; _pk_id.100001.4cf6=caa05f47c90379e0.1711352781.; __utmz=30149280.1711352781.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmz=223695111.1711352781.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __yadk_uid=IQXFNT2vnxeGjwf9deJz78a9ve5HsqW4; ll="118237"; _vwo_uuid_v2=DE4B5B1FD6BE6E2F26C4053D0E1C20C4F|317f8a090233bf021d2e70cae61a1186; dbcl2="279763592:IvXurz8qqIA"; push_noty_num=0; push_doumail_num=0; ck=RQhm; ap_v=0,6.0; _pk_ses.100001.4cf6=1; __utma=30149280.702551814.1711352781.1713138121.1713168043.7; __utmb=30149280.0.10.1713168043; __utmc=30149280; __utma=223695111.807567155.1711352781.1713138121.1713168043.7; __utmb=223695111.0.10.1713168043; __utmc=223695111; __gads=ID=1dbab480dc4dd324:T=1713083660:RT=1713168046:S=ALNI_MZx40l60gyeAJfeyr7ZTtIkDtbj3A; __gpi=UID=00000debc09129bc:T=1713083660:RT=1713168046:S=ALNI_MbBQgg5LtDLxueprj31quRIChjIug; __eoi=ID=e28a5d511c0bcc8a:T=1713083660:RT=1713168046:S=AA-AfjZDyydCQqURUR0ZSKESl3mU'}def start_requests(self):for url in self.start_urls:# 发送请求时,添加 cookieyield scrapy.Request(url=url, cookies=self.custom_cookies, callback=self.parse,dont_filter=True)def parse(self, response):# 获取当前页面的电影信息for item in self.parse_page(response):yield item# 检查是否有下一页,并发送请求next_page = response.xpath('//span[@class="next"]/a/@href').get()if next_page:yield response.follow(next_page, callback=self.parse)def parse_page(self, response):# 获取每部电影的链接movie_links = response.xpath('//div[@class="hd"]/a/@href').extract()for movie_link in movie_links:yield scrapy.Request(movie_link, callback=self.parse_movie)import redef parse_movie(self, response):# 获取电影标题title = response.xpath('//h1/span/text()').get()synopsis = response.xpath('normalize-space(//div[@id="link-report-intra"]/span[@class="all hidden" or @property="v:summary"])').get()# 如果简介不为空,则进行括号内容的正则匹配if synopsis:# 定义正则表达式来匹配带括号的内容,使用多行模式(re.DOTALL)parenthesis_pattern = '(([^)]*))' # 匹配括号内的内容parenthesis_matches = re.findall(parenthesis_pattern, synopsis, re.DOTALL)# 对每个匹配到的括号内容字符串调用 strip() 方法去除空格,并生成新的列表parenthesis_matches_stripped = [match.strip() for match in parenthesis_matches]else:parenthesis_matches_stripped = []# 创建 Item 对象并存储提取的内容item = {'title': title,'parenthesis_content': parenthesis_matches_stripped}yield item