前言
近日,深圳元象科技正式发布了其首个基于混合专家(Mixture of Experts,MoE)架构的大型语言模型 - XVERSE-MoE-A4.2B。这款模型总参数量高达258亿,但在推理过程中仅需激活4.2亿参数,却展现出了媲美130亿参数大模型的性能表现,可谓是当前MoE架构领域的一大突破。
作为元象公司继XVERSE-65B和XVERSE-13B系列之后的又一重磅开源产品,XVERSE-MoE-A4.2B无疑将为国内外的中小企业、科研机构以及开发者带来全新的发展机遇。
-
Huggingface模型下载:https://huggingface.co/xverse/XVERSE-MoE-A4.2B
-
AI快站模型免费加速下载:https://aifasthub.com/models/xverse

突破传统MoE局限,性能出色
XVERSE-MoE-A4.2B之所以备受瞩目,主要源于其在MoE架构设计上的一系列创新:
-
首先是在模型结构上的突破。与传统MoE模型(如Mixtral 8x7B)每个专家大小等同于标准前馈网络(FFN)不同,XVERSE-MoE-A4.2B采用了更细粒度的专家设计,每个专家仅为标准FFN的1/4大小。这不仅提升了模型的灵活性,也大幅提高了性能表现。
-
同时,XVERSE-MoE-A4.2B还将专家分为了共享专家(Shared Expert)和非共享专家(Non-shared Expert)两类。共享专家在计算过程中始终处于激活状态,而非共享专家则根据具体任务需求进行选择性激活。这种设计有利于将通用知识压缩到共享专家参数中,从而减少各专家之间的知识冗余。
-
此外,在训练方面,XVERSE团队还引入了负载均衡损失(Balancing Loss)和路由器z-loss等技术,进一步优化了MoE架构的训练效率和稳定性。
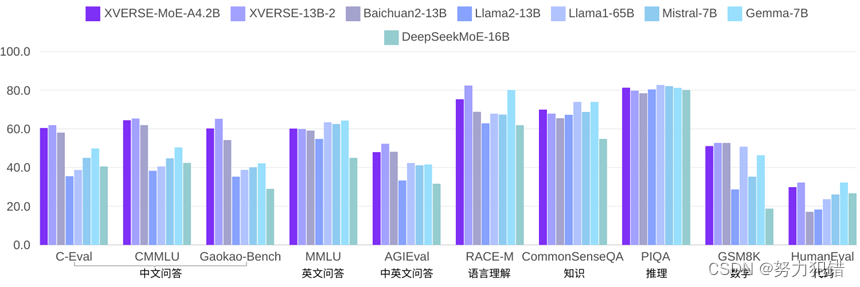
模型性能
得益于这些创新,XVERSE-MoE-A4.2B不仅在参数量上大幅压缩,每次推理只需激活4.2亿参数,但性能却能媲美130亿参数级别的大模型,如Llama2-13B。
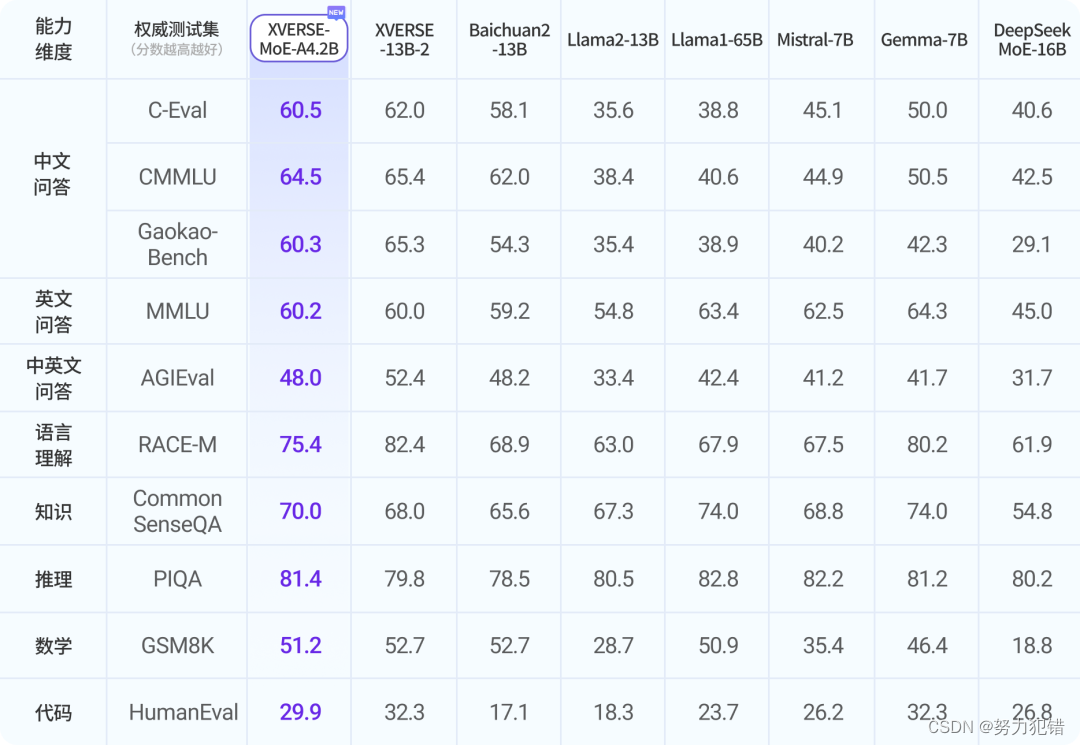
这一成绩的背后,离不开元象团队在数据和算法方面的深入优化:
-
首先是在训练数据方面。XVERSE-MoE-A4.2B是基于一个高达2.7万亿token的大规模、多语种数据集进行训练的,覆盖了中英俄等40余种语言。通过精细设置数据采样比例,不仅确保了中英两种语言的卓越表现,也兼顾了其他语种的效果。
-
其次在算法优化方面,XVERSE团队针对MoE架构独有的专家路由和权重计算逻辑,自主研发了一套高效的融合算子,大幅提升了模型的计算效率。同时,他们还创新性地设计了计算、通信和显存卸载的重叠处理方式,解决了MoE模型高显存占用和大通信量的挑战,进一步提高了整体的吞吐量。
总结
综上所述,XVERSE-MoE-A4.2B模型的发布不仅展示了元象科技在混合专家模型技术领域的领先地位,也为AI领域带来了新的应用可能性,特别是在资源受限的情况下,提供了一种新的、有效的解决方案。随着技术的不断成熟和优化,期待这种新型架构能在未来发挥更大的作用。
模型下载
Huggingface模型下载
https://huggingface.co/xverse/XVERSE-MoE-A4.2B
AI快站模型免费加速下载
https://aifasthub.com/models/xverse





![适用于 Windows 的 10 个顶级 PDF 编辑器 [免费和付费]](https://img-blog.csdnimg.cn/img_convert/63160b0208f693f03a94219ece10a78d.webp?x-oss-process=image/format,png)