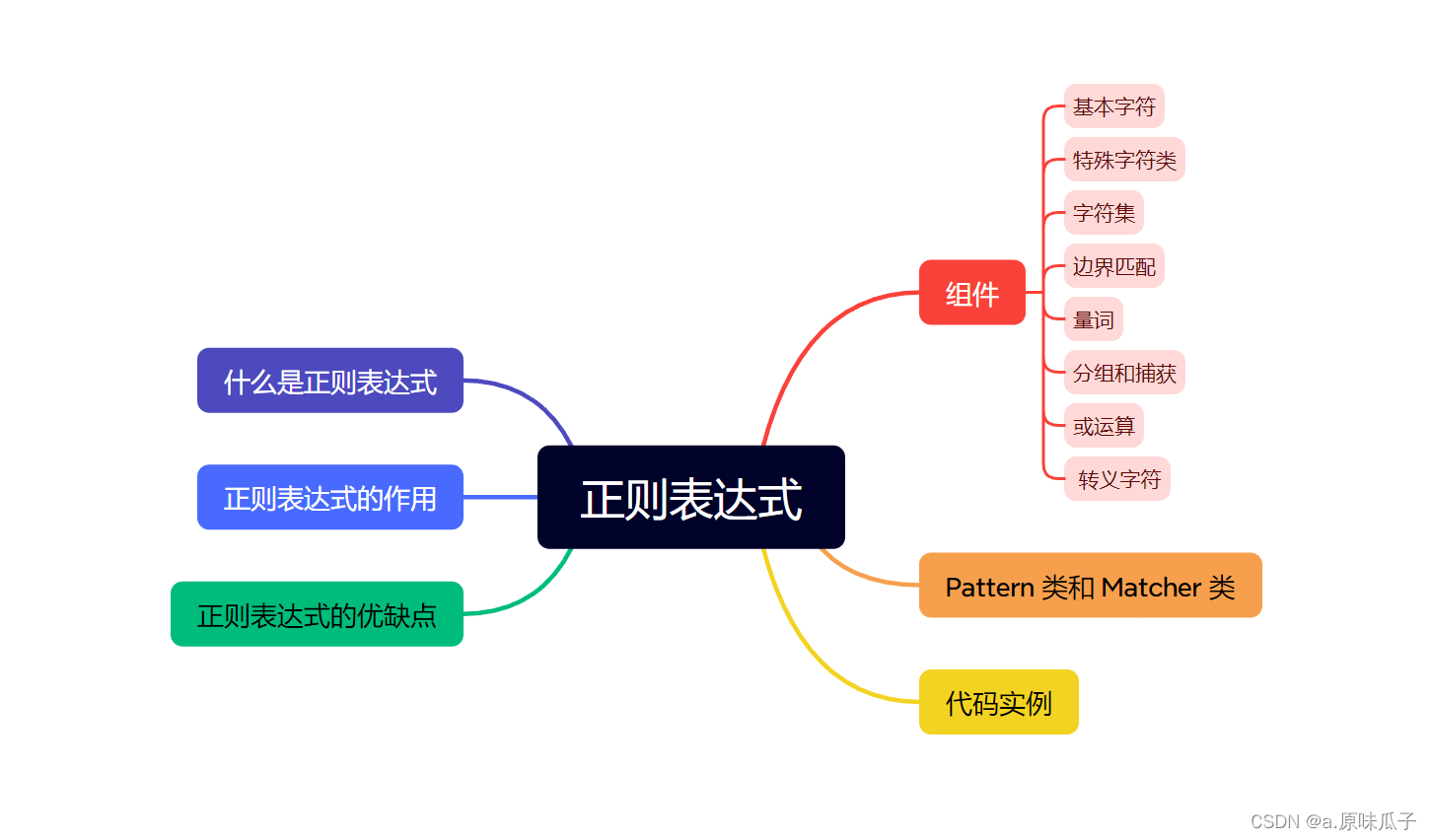
什么是正则表达式:
正则表达式是一种用来描述字符串模式的语法。在 Java 中,正则表达式通常是一个字符串,它由普通字符(例如字母、数字、标点符号等)和特殊字符(称为元字符)组成。这些特殊字符可以表示一些模式,例如匹配数字、字母、空格等。
正则表达式的作用:
正则表达式在 Java 中被广泛应用于字符串处理中,主要用于以下几个方面:
-
查找匹配的文本:可以使用正则表达式在文本中查找特定的模式或子字符串。
-
验证输入的格式:可以使用正则表达式验证输入字符串是否符合特定的格式,例如电子邮件地址、手机号码等。
-
替换匹配的文本:可以使用正则表达式替换文本中匹配的部分为指定的字符串。
-
分割字符串:可以使用正则表达式将字符串分割成多个部分,例如根据逗号、空格等字符进行分割。
正则表达式的优缺点:
优点:
-
灵活性:正则表达式提供了一种灵活的方式来描述字符串模式,可以精确地匹配各种复杂的模式,从而实现灵活的文本处理和匹配需求。
-
强大的模式匹配能力:正则表达式支持各种模式匹配操作,包括查找、替换、验证等,可以满足各种文本处理需求。
-
广泛应用:正则表达式在各种编程语言和平台上都得到广泛支持和应用,是一种通用的文本处理工具。
-
表达能力强:正则表达式可以使用各种元字符和特殊语法来表达复杂的字符串模式,具有很强的表达能力。
缺点:
-
复杂性:正则表达式的语法相对复杂,学习曲线较陡,对于初学者来说可能需要一些时间和练习才能掌握。
-
可读性差:由于正则表达式的语法较为紧凑和晦涩,编写和阅读正则表达式可能比较困难,尤其是对于复杂的正则表达式。
-
性能:对于复杂的正则表达式模式和大量的文本数据,正则表达式的性能可能不如手动编写的字符串处理代码,可能会导致性能问题。
-
维护困难:一些复杂的正则表达式可能会变得难以理解和维护,特别是当需要修改或扩展现有的正则表达式时。
组件:
1. 基本匹配
- 字面字符:直接匹配字符串中的特定字符。例如,
cat会匹配 "cat"。 - 元字符:拥有特殊意义的字符,用于构建强大的匹配模式,如
.、^、$、*、+、?、|、()、[]、{}等。
正则表达式是一种强大的文本处理工具,用于搜索、匹配和操作字符串。它们基于一套规则来识别字符串中的特定模式。正则表达式广泛应用于编程、数据分析、文本处理等领域。以下是正则表达式的一些基本概念和组件:
2. 特殊字符类
.:匹配除换行符外的任意单个字符。\d、\w、\s:分别匹配任意数字、任意字母或数字(包括下划线),以及任意空白字符(如空格、制表符)。\D、\W、\S:匹配任意非数字、非单词字符、非空白字符。
3. 字符集
[abc]:匹配任何一个列在方括号中的字符(如 'a'、'b' 或 'c')。[^abc]:匹配任何不在方括号中的字符。
4. 边界匹配
^:匹配行的开头。$:匹配行的结尾。\b:匹配单词边界,即单词和空格之间的位置。\B:匹配非单词边界的位置。
5. 量词
*:匹配前面的元素零次或多次。+:匹配前面的元素一次或多次。?:匹配前面的元素零次或一次。{n}:匹配前面的元素恰好 n 次。{n,}:匹配前面的元素至少 n 次。{n,m}:匹配前面的元素至少 n 次,但不超过 m 次。
6. 分组和捕获
(xyz):将 'xyz' 视为一个单一的单位,并捕获这部分匹配的文本。这些捕获可以用于后续的操作和引用。
7. 或运算
|:匹配两个或多个分支选择,例如cat|dog表示匹配 "cat" 或 "dog"。
8. 转义字符
\:用于转义特殊字符,使其被解释为字面值,如\.就是匹配点号本身,而不是任意字符的元字符。
Pattern 类和 Matcher 类:
Java 中的正则表达式通常使用 java.util.regex 包中的类来进行处理,主要包括 Pattern 类和 Matcher 类。Pattern 类表示编译后的正则表达式模式,而 Matcher 类用于执行匹配操作。
Pattern 类
Pattern 类用于表示编译后的正则表达式模式。它提供了一系列静态方法来编译和获取正则表达式模式。主要方法包括:
-
compile(String regex):
- 静态方法,用于将给定的正则表达式字符串编译为
Pattern对象。 - 返回一个
Pattern对象,表示编译后的正则表达式模式。
- 静态方法,用于将给定的正则表达式字符串编译为
-
matcher(CharSequence input):
- 方法用于创建一个
Matcher对象,用于在给定的输入字符序列中执行匹配操作。 - 接受一个
CharSequence参数,可以是String或StringBuilder等字符序列。
- 方法用于创建一个
-
split(CharSequence input):
- 方法用于根据正则表达式模式将输入字符序列分割成多个部分。
- 返回一个
String[]数组,包含分割后的子字符串。
Matcher 类
Matcher 类是用于执行匹配操作的对象。它提供了一系列方法来执行查找、替换等操作。主要方法包括:
-
matches():
- 方法用于尝试将整个输入字符序列与正则表达式模式进行匹配。
- 返回一个布尔值,表示是否整个输入字符序列与模式匹配。
-
find():
- 方法用于在输入字符序列中查找下一个匹配项。
- 返回
true表示找到了匹配项,否则返回false。
-
start() 和 end():
start()方法返回当前匹配的子字符串在原始输入字符序列中的起始位置(包含)。end()方法返回当前匹配的子字符串在原始输入字符序列中的结束位置(不包含)。
-
group():
- 方法用于返回当前匹配的子字符串。
- 如果在调用
find()方法之后调用group()方法,则返回当前匹配的子字符串。 - 如果在调用
matches()方法之后调用group()方法,则返回整个输入字符序列。
代码实例:
1. 验证邮箱地址是否有效
import java.util.regex.*;public class Main {public static void main(String[] args) {String email = "example@example.com";String regex = "^[a-zA-Z0-9_+&*-]+(?:\\.[a-zA-Z0-9_+&*-]+)*@(?:[a-zA-Z0-9-]+\\.)+[a-zA-Z]{2,7}$";boolean isValid = email.matches(regex);if (isValid) {System.out.println("Valid email address");} else {System.out.println("Invalid email address");}}
}
2. 提取文本中的所有链接
import java.util.regex.*;
import java.util.*;public class Main {public static void main(String[] args) {String text = "Visit my website at https://example.com and my blog at http://blog.example.com";String regex = "https?://\\S+";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(text);List<String> links = new ArrayList<>();while (matcher.find()) {links.add(matcher.group());}System.out.println("Links found:");for (String link : links) {System.out.println(link);}}
}
3. 替换字符串中的所有数字
public class Main {public static void main(String[] args) {String text = "Today is 2024-04-16";String replacedText = text.replaceAll("\\d", "*");System.out.println(replacedText); // 输出:Today is ****-**-**}
}