到目前为止,视觉SLAM14讲已经到了终章,历时一个半月,时间有限,有些地方挖掘的不够深入,只能在后续的学习中更进一步。接下来,会着手ORB-SLAM2的开源框架,同步学习C++。
视觉SLAM学习打卡【11】-尾述
- 一、回环检测
- 1.实现方法
- 2.词袋模型步骤
- (1)生成字典Word
- (2)生成词袋Bag-of-Words(BoW)
- (3)相似度计算
- 二、建图
- 1.单目稠密重建
- (1)极线搜索与块匹配
- (2)高斯分布的逆深度滤波器
- (3)像素梯度的问题
- 2.RGB-D稠密建图
- 3.八叉树地图
- 4.实时三维重建
- 三、SLAM的开源方案
- 1. MonoSLAM
- 2. PTAM(Parallel Tracking and Mapping)
- 3. ORB-SLAM(Oriented FAST and Rotated BRIEF SLAM)
- 4. LSD-SLAM(Large Scale Direct monocular SLAM)
- 5. SVO(Semi-direct monocular Visual Odometry)
- 6. RTAB-MAP(Real-Time Appearance-Based Mapping)
- 7.视觉+惯性导航SLAM
- 8.语义SLAM
- 四、特征点法能构建稠密地图吗?
一、回环检测
1.实现方法
- 对任意两幅图像都做一些特征匹配(检测数量太大)
- 随机抽取历史数据并进行回环检测(可能漏掉回环,检测效率不高)
- 基于视觉里程计的几何关系(存在累计误差)
- 基于外观(主流方法)——词袋模型
2.词袋模型步骤
调用DBoW3::Vocabulary对象的构造函数后,输出结果:
vocabulary info:Vocabulary:k=10,L=5,Weighting=tf-idf,Scoring=L1-norm,Number of words=4983
- k=10,L=5——上述生成字典采用K叉树(深度为5,每次分叉为10),每个叶子节点对应一个单词.
- Weighting=tf-idf——TF-IDF(Term Frequence-Inverse Document Frequence / 词频-逆文档频率)
√ TF:某单词在一幅图像中经常出现,它的区分度就高; T F i = n i n . TF_{i}=\frac{n_{i}}{n}. TFi=nni.(图像A中单词wi出现了ni次,一共出现的的单词次数为n)
√ IDF:某单词在字典中出现频率越低,分类图象时区分度越高。 I D F i = log n n i . \mathrm{IDF}_{i}=\log\frac{n}{n_{i}}. IDFi=lognin.(某叶子节点wi的特征数量为ni,字典中所有特征数量为n)
√ 权重Weighting等于TF与IDF的乘积 η i = T F i × I D F i . \eta_{i}=TF_{i}\times IDF_{i}. ηi=TFi×IDFi. - Scoring=L1-norm——计算不同图像的差异,进行相似度计算.
(1)生成字典Word
- 随机选取k个中心点(特征点)
- 对每一个特征点,计算它与每一个中心点的距离(描述子算汉明距离),取最小的作为它的类(单词“Word”)
- 重新计算每个类的中心点
- 如果每个类的中心点变化很小,则算法收敛,退出(所有的类/ Word 构成字典);否则返回第二步
(2)生成词袋Bag-of-Words(BoW)
某幅图像A中,单词 wi 和其对应权重 η i \eta_i ηi 组成的向量 v 对组成它的BoW. A = { ( w 1 , η 1 ) , ( w 2 , η 2 ) , … , ( w N , η N ) } = d e f v A A=\{(w_{1},\eta_{1}),(w_{2},\eta_{2}),\ldots,(w_{N},\eta_{N})\}\stackrel{\mathrm{def}}{=}v_{A} A={(w1,η1),(w2,η2),…,(wN,ηN)}=defvA
(3)相似度计算
A、B两幅图像的相似度评分公式可以为(L1范数形式): s ( v A − v B ) = 2 ∑ i = 1 N ( ∣ v A i ∣ + ∣ v B i ∣ − ∣ v A i − v B i ∣ ) s(\boldsymbol{v}_A-\boldsymbol{v}_B)=2\sum_{i=1}^N(|\boldsymbol{v}_{Ai}|+|\boldsymbol{v}_{Bi}|-|\boldsymbol{v}_{Ai}-\boldsymbol{v}_{Bi}|) s(vA−vB)=2i=1∑N(∣vAi∣+∣vBi∣−∣vAi−vBi∣)(L1范数,也被称为曼哈顿范数,是向量范数的一种计算方式。L1范数等于向量元素的绝对值之和,也可以表示为从原点到向量所在点的曼哈顿距离。)
all in all,字典是单词的集合,字典+权重=词袋
二、建图
地图的用途归纳如下: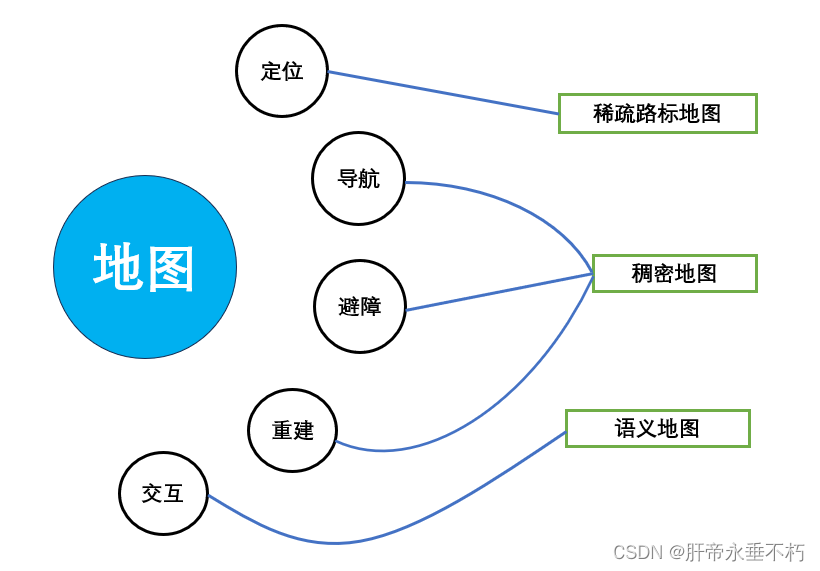
在稠密重建中,需要知道每一个像素点的距离:
- 单目相机-三角化
- 双目相机-左右目视差计算
上述两种方式称为立体视觉(Stereo Vision),其中,第一种又称为移动视角的立体视觉(Moving Stereo Vision MVS)
- RGB-D相机直接获得像素距离
1.单目稠密重建
(1)极线搜索与块匹配
在特征点方法中,我们是根据描述子通过特征匹配来确定那个点是匹配点。但是在稠密的限制下,我们不可能对每个点保存描述子,我们只能在极线上找一个与p1长的很像的点,具体来说,我们要沿着极线l2,从一头跑到另一头,在这里面找一个很像的点。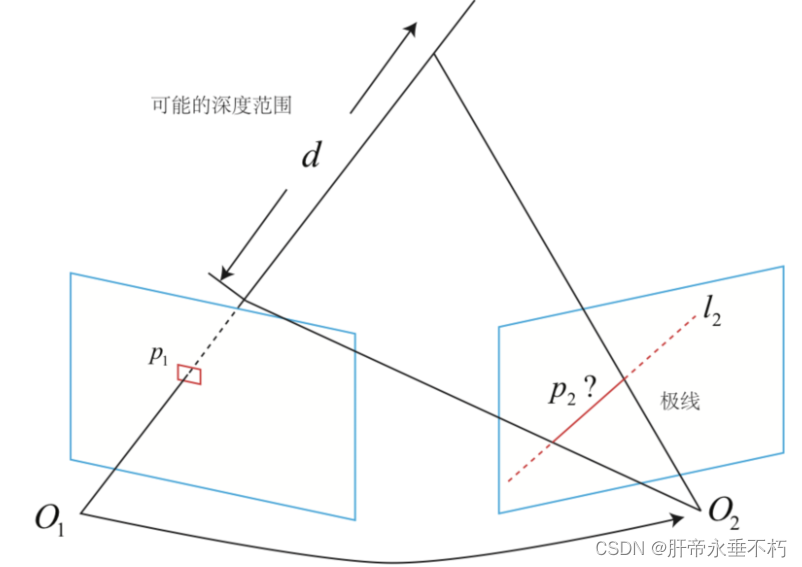
对极几何和极线搜索的区别:
- 对极几何:已知p1、p2像素坐标,根据本质矩阵E求R、t.
- 极线搜索:已知R、t和p1像素坐标,求p2像素坐标
单个像素的灰度区分度太低,又没有描述子去描述特征,我们采用块匹配的方法,也就是取p1周围一个w×w的小块,在极线上也取很多的等大小的小块进行比较:
- SAD(Sum of Absolute Difference / 两小块差的绝对值之和)。 S ( A , B ) S A D = ∑ ∣ A ( i , j ) − B ( i , j ) ∣ . S(\boldsymbol{A},\boldsymbol{B})_{SAD}=\sum|\boldsymbol{A}(i,j)-\boldsymbol{B}(i,j)|. S(A,B)SAD=∑∣A(i,j)−B(i,j)∣.(接近0说明两小块相似)
- SSD(Sum of Squared Distance / 平方和)。 S ( A , B ) S S D = ∑ i , j ( A ( i , j ) − B ( i , j ) ) 2 . S(\boldsymbol{A},\boldsymbol{B})_{SSD}=\sum_{i,j}\left(\boldsymbol{A}(i,j)-\boldsymbol{B}(i,j)\right)^2. S(A,B)SSD=i,j∑(A(i,j)−B(i,j))2.(接近0说明两小块相似)
- NCC(Normalized Cross Correlation / 归一化互相关)。 S ( A , B ) N C C = ∑ i , j A ( i , j ) B ( i , j ) ∑ i , j A ( i , j ) 2 ∑ i , j B ( i , j ) 2 . S(\boldsymbol{A},\boldsymbol{B})_{NCC}=\frac{\sum_{i,j}\boldsymbol{A}(i,j)\boldsymbol{B}(i,j)}{\sqrt{\sum_{i,j}\boldsymbol{A}(i,j)^2\sum_{i,j}\boldsymbol{B}(i,j)^2}}. S(A,B)NCC=∑i,jA(i,j)2∑i,jB(i,j)2∑i,jA(i,j)B(i,j).(接近1说明两小块相似)
上述3种方法可以进行去均值操作:形成去均值的SSD,去均值的NCC,去均值的SAD
(2)高斯分布的逆深度滤波器
在搜索距离较长的时候,通常会得到一个非凸函数,存在许多峰值,但是真实的对应点只有一个。也就是说对应位置是一个概率表示的位置,所以估计的深度也应该是一个概率值,所以问题就转换到了对不同图像进行极线搜索的时候,估计的深度分布会发生怎样一个变化,这就是深度滤波器。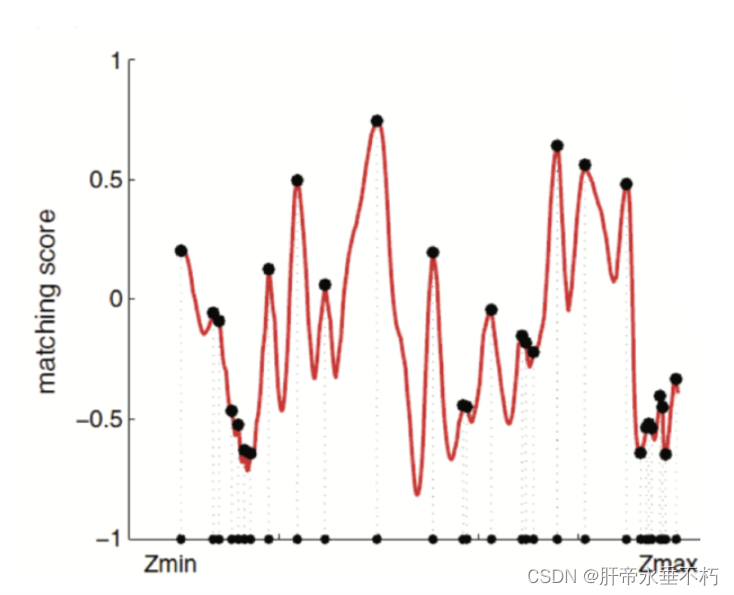
假设深度值d服从高斯分布,通过信息融合(两个高斯分布的乘积依然是高斯分布),更新原来d的分布。
逆深度:是近年来SLAM研究中出现的一种广泛使用的参数化技巧。假设深度的倒数(逆深度)为高斯分布是有效的,有更好的数值稳定性。
(3)像素梯度的问题
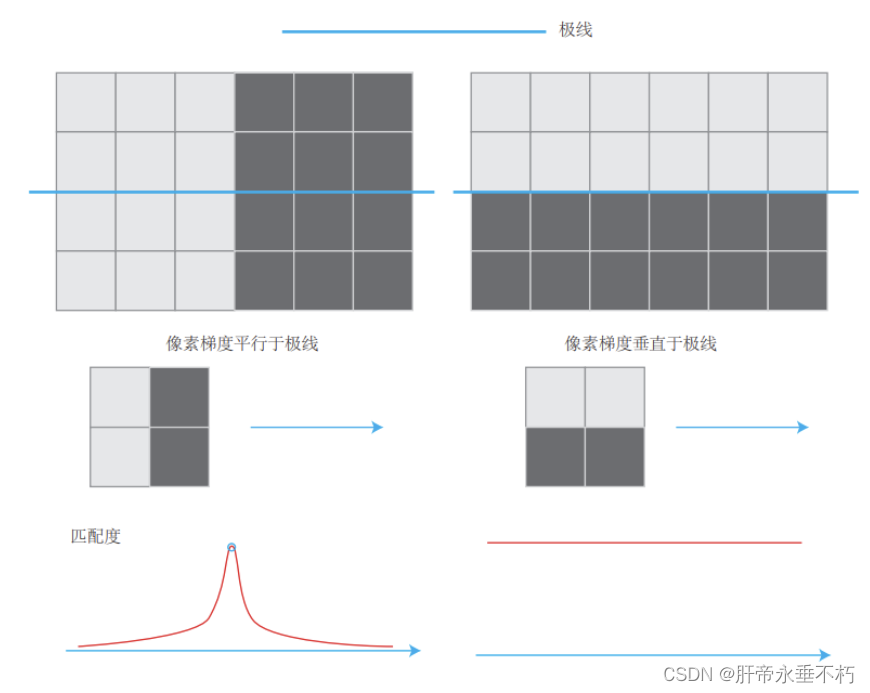
- 立体视觉对物体纹理的依赖性:对于梯度不明显的像素,由于在块匹配时没有区分性,将难以有效的估计其深度。
- 像素梯度和极线的关系:当像素梯度与极线夹角较小时,极线匹配的不确定性小;而当夹角较大时,匹配的不确定性变大。
2.RGB-D稠密建图
利用深度相机进行稠密建图是相对简单的,最简单的方法就是根据估算的相机位姿,将深度相机数据转换为点云,拼接之后就得到了一个由离散点组成的点云地图(Point Cloud Map)。在此基础上改进:
- 三角网格(Mesh)
- 面片(Surfel)
- 通过体素(Voxel)建立占据网格地图(Occupancy Map).有许多小的立方体单元(体素)组成,每个体素都包含了其位置信息和属性信息。
3.八叉树地图
在导航中比较常用,本身具有较好的压缩性能的八叉树地图,比较节省存储空间。
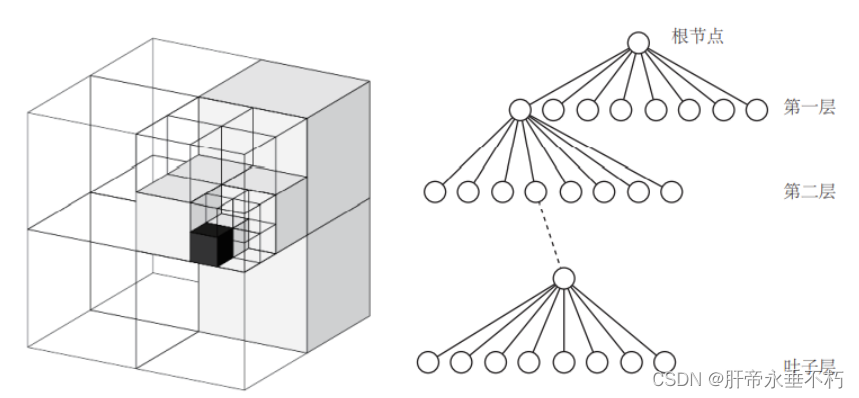
- 对空间进行划分,每次划分是对空间的三个方向各划一刀,于是会产生八个块,对应到树结构上就是一层产生八个儿子节点,也就是八叉树。整个大方块可以看成是根节点,而最小的块可以看作是“叶子节点”。于是,在八叉树中,当我们由下一层节点往上走一层时,地图的体积就能扩大八倍。体积与深度成指数关系,所以当我们用更大的深度时,建模的体积会增长的非常快。
- 八叉树可以节省存储,主要是在于当某个方块的所有子节点都被占据或都不被占据时,就没必要展开这个节点。
4.实时三维重建
与SLAM非常相似但又有稍许不同的研究方向:实时三维重建。一种以”建图“为主体,定位居于次要地位的做法。
三、SLAM的开源方案
1. MonoSLAM
- 第一个实时单目视觉SLAM系统
- 后端:EKF
- 前端:特征点法
2. PTAM(Parallel Tracking and Mapping)
- 实现了定位&建图过程的并行化
- 第一个使用非线性优化BA
3. ORB-SLAM(Oriented FAST and Rotated BRIEF SLAM)
- 支持单目、双目、RGB-D三种模式
- 创新使用三线程完成SLAM:实时跟踪特征点的Tracking线程;局部BA的优化线程(小图);全局位姿图的回环检测和优化线程(大图)。
4. LSD-SLAM(Large Scale Direct monocular SLAM)
- 将单目直接法运用到半稠密(只估计梯度明显的像素位置)SLAM中
5. SVO(Semi-direct monocular Visual Odometry)
- 半直接/稀疏直接法:指特征点与直接法的混合使用。SVO跟踪一些关键点(角点,没有描述子),像直接法那样,估计关键点周围的相机运动.
- 提出深度滤波器的概念,并推导了基于均匀-高斯混合分布的深度滤波器
- 追求速度和轻量化,舍弃了后端优化和回环检测部分,故称为视觉里程计.
6. RTAB-MAP(Real-Time Appearance-Based Mapping)
- RGB-D传感器上的SLAM方案,能够在CPU上实时建立稠密的地图
- 包含:基于特征的视觉里程计;基于词袋的回环检测;后端的位姿图优化;点云和三角网络地图
7.视觉+惯性导航SLAM
- 使用VIO(Visual-Inertial Odometry,即视觉惯性里程计)
- IMU和相机互补:IMU为快速运动提供了较好的解决方案(运动过快,相机产生模糊);相机在慢速运动下解决IMU漂移问题.
- VIO框架定型为2大类:松耦合(IMU和相机各干各的,最后对结果融合)和紧耦合(IMU和相机一起,共同构建运动方程,然后进行状态估计)
8.语义SLAM
- 把物体识别和视觉SLAM相结合,构建带标签的地图,把标签信息引入BA或优化端的目标函数和约束中.
- 将SLAM与深度学习、神经网络结合,处理图像.
四、特征点法能构建稠密地图吗?
在学习SLAM过程中,由于对该领域了解尚浅,产生了片面的认识:特征点法和直接法均可以重建稀疏地图,半稠密、稠密地图无描述子,仅可采用直接法。
特征点法本身并不能直接构建稠密地图。特征点法主要是通过提取和匹配图像中的特征点来进行定位与建图。它主要关注的是稀疏的特征点,这些点可能不足以构成稠密地图。稠密地图通常需要更多的像素级信息,而不仅仅是特征点。
然而,通过结合其他方法或技术,特征点法可以在一定程度上用于构建稠密地图。例如,可以利用特征点法得到的稀疏地图作为初始估计,然后通过插值或其他方法扩展为稠密地图。另外,也可以使用深度相机或其他传感器来获取更多的深度信息,结合特征点法来实现稠密地图的构建。