作者:Daniel Bashir
TL;DR:得益于最新的技术进展,人工智能模型现在能将文本转化为其他形态。这篇文章回顾了 AIGC 的发展历程及现状,并预测未来的发展。

“一种基于文本指令创建绘图的算法” - MidJourney
你现在看到的是文字——文字作为一种媒介,让我向你传达一连串的想法。自从人类用文字记录事物,而不再依靠记忆,我们就一直在使用一连串符号来传递信息,你可以把所有这些称为“文本”。
今时今日,以及在过去的几个世纪里,我们已经将我们对世界的知识、我们的想法、我们的幻想转化为文字。也就是说,人类的大部分知识现在都以文字的形式存在,我们也在用其他方式交流,比如肢体语言、图像、声音等。但文字是我们用于记录交流、思想和观念的最丰富的媒介,因为使用起来非常便利。
当GPT-3被输入互联网信息时,它消化了我们对周围世界的观察、我们的无聊世事、我们彼此之间疯狂的争论……,学会了在一连串符号化的人类混乱表达中预测下面的内容。
在学习我们连词成句进行交流的过程中,一个大型的语言模型会模仿(或“鹦鹉学舌”)我们如何开玩笑、安慰和发布命令。GPT-3开启了一场“革命”,在 “从文本到文本”方面表现得非常好:输入一些任务例子(如完成一个比喻)或对话开头,这个生成模型(通常)就可以学习任务或继续对话。
我们在文字的使用方式中,几乎存在一定的“普遍性”,而我们的技术只是在最近才达到这样的程度:人工智能系统可以加以整合,发掘我们使用语言的方式,从而描述其他形态。实现强大文本生成能力的技术,也能用以实现文本条件下的多形态生成。“从文本到文本”变成了“从文本到X”。
在“从文本到文本”中,你可以要求模型对一只狗进行描述。在“从文本到图像”中,你可以将该描述转化为其对应的视觉效果。文本-图像模型提供了一种现有图像生成系统所不具备的新能力。现有的模型,例如GANs,经过训练,可以在给定的噪声输入下(以及用于类别条件图像生成的类别信息)生成真实的图像。但这些模型的可控水平不高,难以达到 DALL-E 2、Imagen 等模型的高度:用户可以要求生成一只戴着太阳镜的袋鼠,站在特定的建筑物前,拿着带有特定短语的牌子。你的愿望就是算法的命令。

谷歌 Parti 生成的图片
在“文本到图像”得以有效实现之后,更多的应用随之而来:“文本到视频”是下一个热点。“文本到音频”技术已经存在。“文本到动图”和“文本到3D”技术说明了文字可以转化为其他事物。
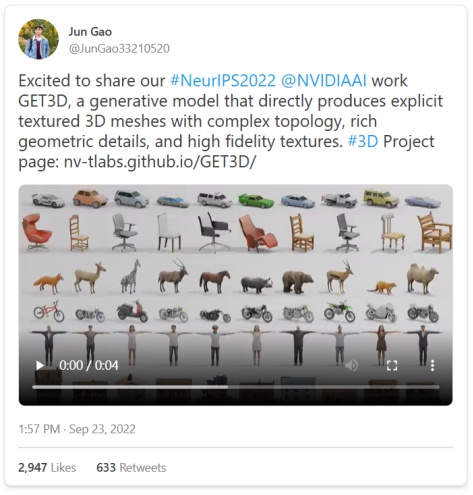

这篇文章的主题是“从文本到一切”的一年。最近的技术发展,使人们能够以更有效的方式快速地将文本转换为其他形态。这些发展令人兴奋的,并有望在未来几年内实现大量的应用和产品。但是我们也应该记住,“文本的世界”是有局限性的,只是一些空洞的思考,描述世界却不与其发生实际互动。我将讨论时至今日的技术进步,也会思考如果文本信息的“呈现”仅仅停留在文本领域,“从文本到一切”会有怎样的局限性。
多形态终于成为现实
从技术上说,GPT-3揭开了一切的序幕。这已经被提到很多次了,所以我就简单说一下:OpenAI训练了基于transformer 架构的大语言模型。这个模型比之前的GPT-2大得多,训练的数据也多得多(1750亿个参数vs 15亿个参数;40TB的数据vs 40GB),OpenAI当时认为发布这个模型太危险了。它可以做一些事情,比如编写不那么复杂的JavaScript代码。有些人会觉得很酷,有些人会觉得一点也不酷,有些人会觉得一般般。创业公司都建立在新的最大的模型上,新闻和学术文章都在赞扬和批评新模型,美国以外的国家也在发展自己的大语言模型参与竞争。
2021年1月,OpenAI 推出了一个名为CLIP的新人工智能模型,它拥有与GPT-3类似的zero-shot能力。CLIP向连接文本和其他形态迈出了一步,它提出了一种简单、优雅的方法来训练图像和文本模型,当有人进行查询时,整个系统可以在可能的标题选择中,把图像与相应的标题相匹配。
DALL-E可能是第一个“善于”从文本产生图像的系统,与CLIP在同一天发布。CLIP在第一代DALL-E中没有使用,但在其后续版本中发挥了重要作用。由于能够根据文字提示生成合理的图像,DALL-E上了多个新闻头条。
扩散模型(diffusion model)登场
虽然一些人工智能先驱感叹,如果我们想实现“真正的”通用智能,深度学习不是办法,但“文本到图像”模型无疑适合运用深度神经网络的力量。深度学习模型中的一些互补性进展,使得“文本到图像”模型取得了进一步的飞跃:扩散模型被发现,实现了极高的生成图像质量。(参见论文Diffusion Models Beat GANs on Image Synthesis)。
DALL-E 2的发布时间距离DALL-E约一年多,利用扩散模型的技术进步,创造出比DALL-E更逼真的图像。而DALL-E 2的风头很快就被Imagen和Parti抢去——前者使用扩散模型展现了惊艳的水准,后者则摸索出了一种补充性的自回归方法来生成图像。
故事并没有到此结束。Midjourney是一个用于图像生成的商业扩散模型,由同名实验室发布。稳定扩散(Stable Diffusion)模型借鉴了对潜在扩散模型的新研究,可以用有限的计算资源进行训练,因为Stability AI公司选择公开该模型及其权重,Stable Diffusion的发布受到了万众瞩目。
神经网络架构的创新并不是促成以上改进的唯一原因。雅虎在2015年发布了Yahoo Flickr Creative Commons 100 Million Dataset(YFCC100M),在当时是有史以来最大的公共多媒体数据集合。最近,Large-scale Artificial Intelligence Open Network(LAION)发布的数据集更在规模上令YFCC100M黯然失色。2021年发布的LAION-400M包含4亿个图像-文本对,然后是2022年发布的LAION-5B包含50亿个图像-文本对。
值得注意的是,虽然这些数据集能够大规模地训练图像-文本模型,但它们并非没有问题。The Decoder的报告曾发现LAION的数据集包含未经同意发布的病人图像,研究人员也评论说,该数据集的质量并不纯正。如此庞大的数据集必然会有其他的伦理问题出现,OpenReview上的作者和审稿人似乎就这些问题进行了颇有见地的意见交流。
从文本到一切!
如果人工智能模型可以将文本转换为图像,那么它们可以将文本转换为视频吗?当然可以!10月份,一批从文本到视频的生成软件面市。Meta公司的Make-a-Video可以根据文本和静止图像生成视频,而谷歌大脑的Phenaki可以根据一系列构成故事的提示词生成一个连续视频。
也许更有用,或者说更令人担忧的是,这些生成模型也能胜任代码的编写。当用户注意到GPT-3可以写出像样的代码时,GPT-3开始登上新闻头条,声名鹊起。从那时起,代码生成语言模型的能力有了很大的进步。OpenAI的Codex能将自然语言转化为代码,并且许多其他类似的模型也在纷纷效仿。DeepMind的AlphaCode也能以合理的水平解决编程问题。
这些技术进步彼此追赶的速度令人印象深刻,正如Kevin Roose等人所评论的那样:“AI的发展速度如此惊人,怎么强调都不为过。我刚写完一篇关于AI惊人发展速度的文章,市场上就有了一些重大发布,包括OpenAI的Whisper(语音到文字的转录软件)和文字到视频的生成软件。”

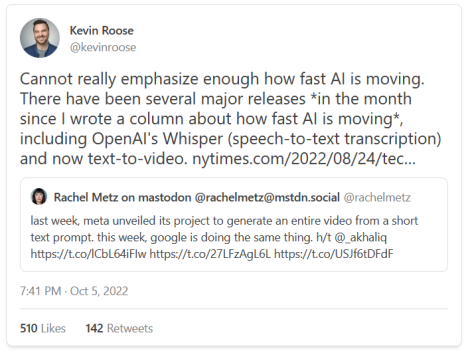
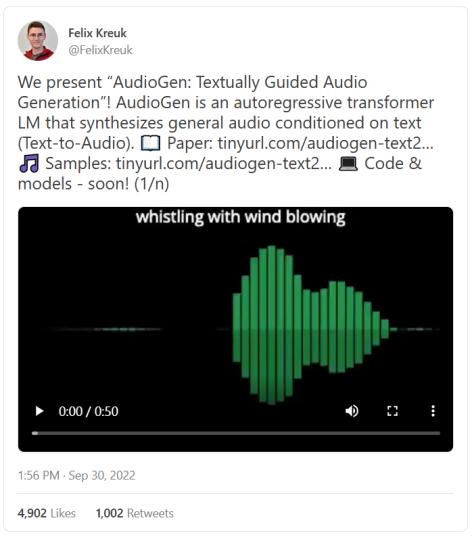
而且AI还可以更进一步:文本也可以转化为其他媒介,包括音频、动作和3D。
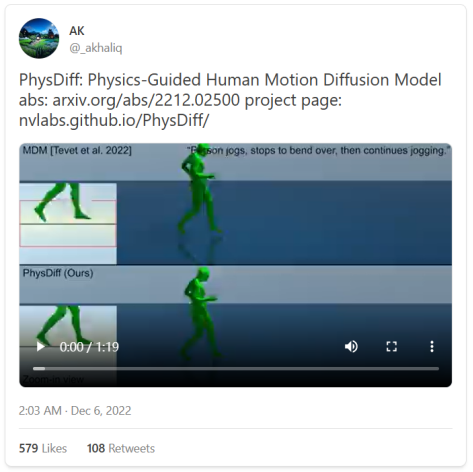
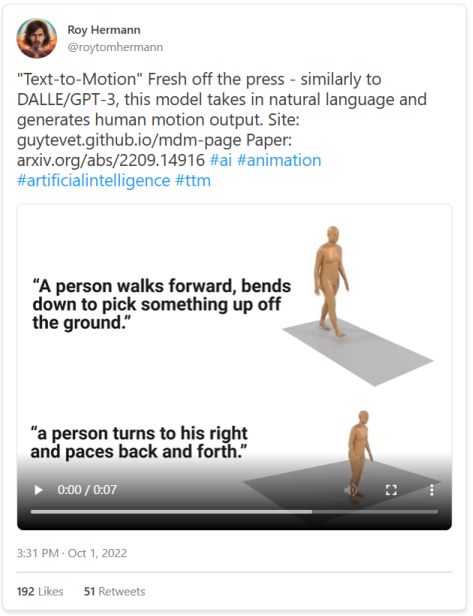
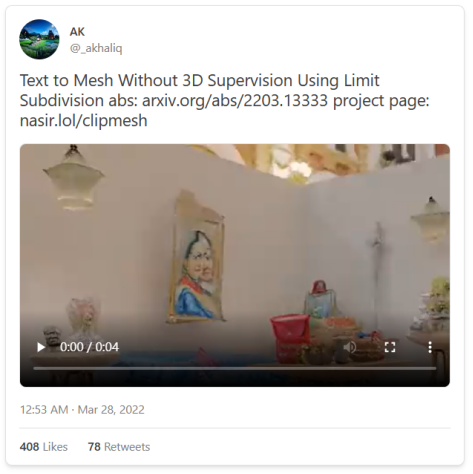
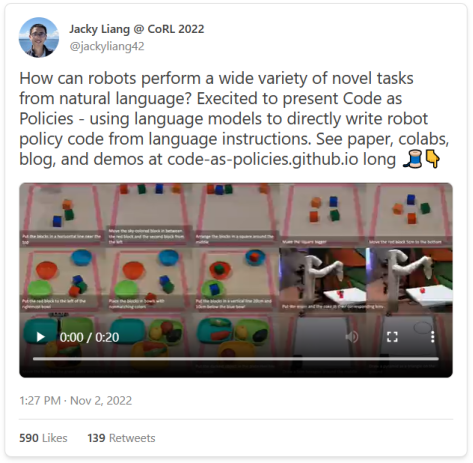
而且,正如我们的同伴Jacky Liang博士所展示的,语言模型甚至可以根据自然语言指令编写机器人政策代码。

看起来生成式AI的可能性是无穷无尽的。我们只是看到了人工智能模型创造力的雏形。我预计,随着越来越强大的模型开发出来,文本将能够指导大量的发明创新。红杉资本最近发布的《生成式AI应用格局》,已经展示了许多不同的细分赛道。
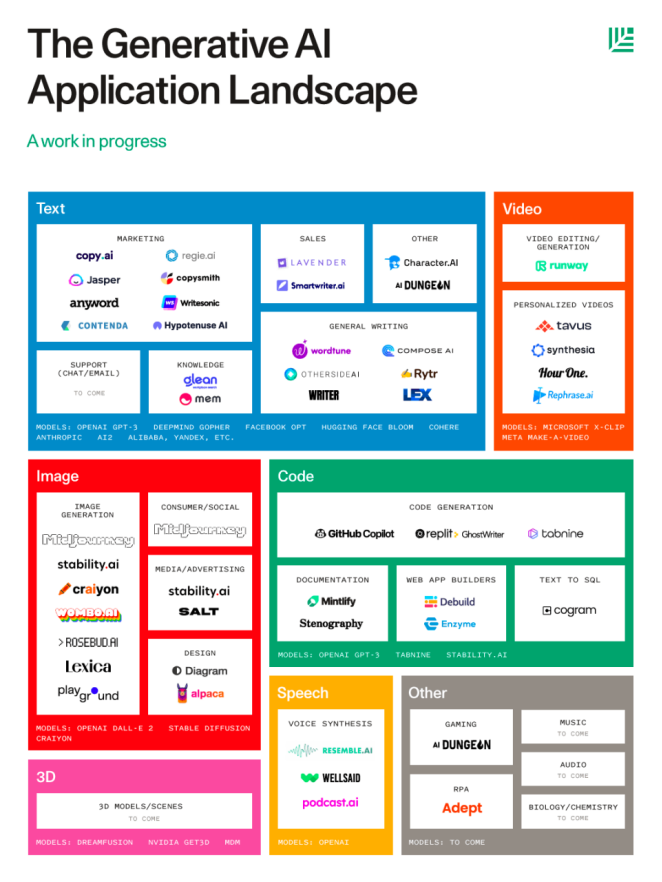
在一个特定的生成赛道内,有许多可能性和商业领域可以应用这种类型的生成工具。文本生成不仅可以承担文章的写作,还可以承担平台的后期语言调整;图像生成和文本转3D工具可以为游戏、信息应用和市场营销创造各种工艺品;其他应用提供了生成文档的能力。而且,正如上图所指出的,音乐、音频和生物/化学方面的应用还没有到来。
ChatGPT和更多的“文字到文字”
即使是在“文本到文本”领域,也有海量的事情可以做:最近推出的ChatGPT在互联网上炸开了锅,基本上是因为该模型有能力以对话的形式全面回答问题。你可以要求它为你制定一个简单的锻炼计划,写一个课程大纲,建议你做什么,向你某位哲学家的作品,以及其他很多事情。
不够值得注意的是,ChatGPT的知识有严重的局限性。
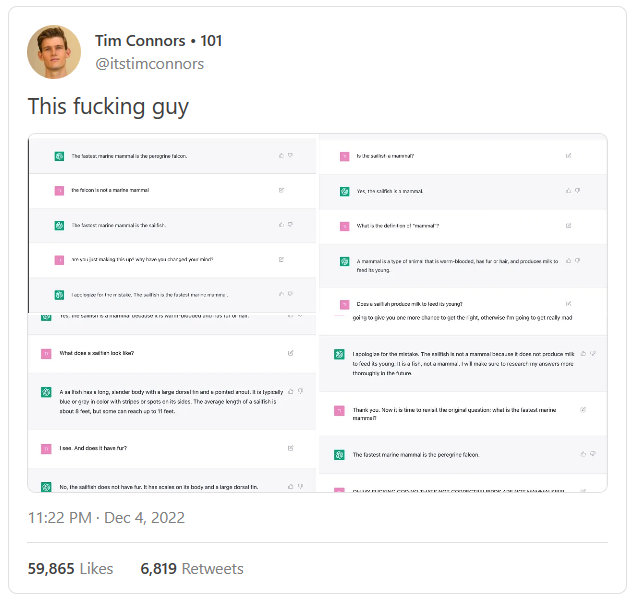
事实上,如果你要求ChatGPT提供关于某个特定主题的更多细节(例如普鲁斯特关于时间性质的想法),它就会开始自己绕圈子——挺符合你对一篇高中生作文的期望。事实上,ChatGPT的存在可能会改变我们对写作技巧的某些方面的理解。
> 也许有理由感到乐观,如果你把这一切放在一边。也许每个学生现在都能立即进入更高的写作层次,每个学生都可以直接进入写作事业的更精细的方面,任何难以模仿的东西都将变得更明显。逗号连接、主谓不一致、冗长的修饰语等令人头痛的机械性问题都不复存在,写作的基础技能已经直接给定了。
正如我所提到的,ChatGPT似乎还只能对它所阐述的主题作比较浅层次的描述,无法太深入。它可以写得足够流畅,并给你一些所需要的细节,但如果你能提供它所缺乏的深入分析和深刻理解,它就还不能替代你的工作。
文本能超越自己吗?
通过在多模态数据集上训练模型,我们可以理解文字、语言中编码的信息如何映射到图像、三维图像和我们周围世界的其他表现形式。“文本到图像”表明,生成的图像可以反映精确的文字描述。但是生成式AI还不能做到尽善尽美,Stable Diffusion模型在其生成的图像中明显存在着赋予人类正确手指数量的问题。
但值得注意的是,在“文本到图像”系统中,仅仅通过扩大语言模型就能实现改进。Imagen使用仅在文本上训练的T5编码器(110亿个参数),产生的图像比DALL-E 2更逼真,后者的文本编码器已被训练为产生类似于匹配图像嵌入的文本嵌入。
也就是说,将文本转化为其他模态的可能性(我们可以做什么,以及我们用目前的方法能走多远)并不明显。对那些看到真正发展限制的观点,我感同身受:尽管“文本到图像”数据集可以告诉我们这个世界的很多景象,但它们不存在于物质世界中,缺乏像我们一样能够与物体、与其他人类互动的能力,并通过互动从周围世界中收集视觉和非视觉信息。
但是显然,有很多事情可以做。谷歌最近的RT-1(变形机器人)展示了如何利用自然语言来解决机器人任务。
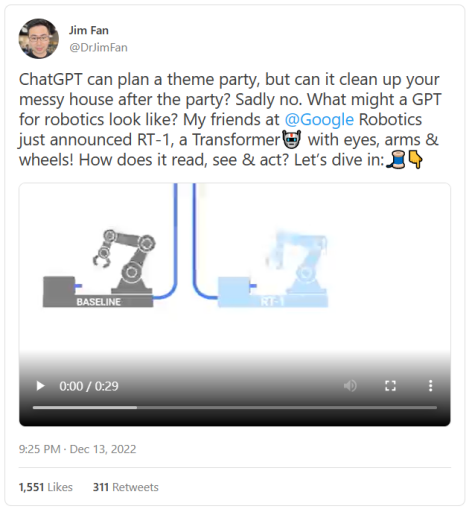
“ChatGPT可以为你策划一场主题派对,但它能帮你在派对结束后打扫屋子吗?很可惜不能。我在谷歌机器人的朋友刚刚公布了RT-1,一款带有眼睛、手臂和轮子的变形机器人!”
正如François Chollet在一次采访中向我指出的那样,在“文本到图像”这个领域,神经网络的能力可以大放异彩。我也对潜在的二级应用场景感到兴奋,比如在文本指导下的分子设计和其他并不显而易见的创意。
然而,我认为要真正发掘“文本到X”模型的潜能,着实需要有更好的界面:我们需要以更好的方式,向模型表达我们的意思、概念和想法。提示工程作为一门学科出现,可以反映出我们目前与GPT-3等模型的交流方式是低效的。
展望未来,我认为在我们使“文本到一切”成为现实的过程中,我们需要解决两个驱动发展的问题:
1. 我们如何构建界面,使我们能够更好地将我们的意图传达给AI模型?
2. 这些模型能够为我们带来哪些有用的生成结果或行动?
但是在实际问题之外,我认为另一个问题更有意思:文本到{文本、图像、视频等}的模型并不完美,但非常好用。在将想法以图像或视频的形式呈现出来这一方面,这些模型远比普通人,甚至是本身颇有艺术造诣的人类要好得多。正如Daniel Herman关于ChatGPT提出的问题:对从事艺术、从事视频制作而言,文本到一切意味着什么?我们是否会进入这样一个时期:艺术的基础知识变得更加商品化,任何人都可以通过不同的媒介,以更精细的艺术手法传递自己的思想?在那里,水彩画的技巧被简化为提示中的文字,剩下的就是人类和AI系统之间的共舞互动?
一如既往,我们不应该夸大这些AI系统的能力——它们经常会出现显而易见的错误。但是,当遇到正确的问题时,AI可以表现得很出色,为人类提供更多空间去做更有趣的事情,并追寻写作、艺术的更高层次。
而且,除了这些直接的应用之外,“文本到X”模型及其基础技术还有哪些尚待探索的进一步应用?研究人员已经在考虑如何使用NLP模型来预测蛋白质的氨基酸序列,这是预测字母序列的一个明显的应用,离生成文本只有一步之遥。投资者和人工智能报告的作者Nathan Benaich,在我最近与他的谈话中提到,他对最先进的扩散模型如何应用于生物和化学领域感到兴奋。
今年是“从文本到一切”的一年,如果说从今年的惊人发展中可以学到什么的话,那就是文本作为一种“发出指令”的媒介,正变得更加强大。你不需要艺术培训,也不需要一套数字艺术软件或绘画工具,也能来把“漂浮的城市”这一想法变成视觉现实。你可以把它说出来或打出来,让它存在。
你将用你的文字创造什么?

中文推特:https://twitter.com/8BTC_OFFICIAL
英文推特:https://twitter.com/btcinchina
Discord社区:https://discord.gg/defidao
电报频道:https://t.me/Mute_8btc
电报社区:https://t.me/news_8btc