Mysql的中一些语句的用法:
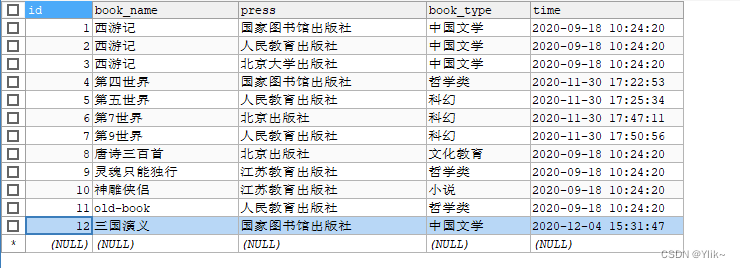
有表:
CREATE TABLE `book` (`id` int(20) NOT NULL,`book_name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '书名',`press` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '出版社',`book_type` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '书籍类型',`time` datetime NULL DEFAULT NULL COMMENT '时间',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;-- ----------------------------
-- Records of book
-- ----------------------------
INSERT INTO `book` VALUES (1, '西游记', '国家图书馆出版社', '中国文学', '2020-09-18 10:24:20');
INSERT INTO `book` VALUES (2, '西游记', '人民教育出版社', '中国文学', '2020-09-18 10:24:20');
INSERT INTO `book` VALUES (3, '西游记', '北京大学出版社', '中国文学', '2020-09-18 10:24:20');
INSERT INTO `book` VALUES (4, '第四世界', '国家图书馆出版社', '哲学类', '2020-11-30 17:22:53');
INSERT INTO `book` VALUES (5, '第五世界', '人民教育出版社', '科幻', '2020-11-30 17:25:34');
INSERT INTO `book` VALUES (7, '第7世界', '北京出版社', '科幻', '2020-11-30 17:47:11');
INSERT INTO `book` VALUES (9, '第9世界', '人民教育出版社', '科幻', '2020-11-30 17:50:56');
INSERT INTO `book` VALUES (10, '唐诗三百首', '北京出版社', '文化教育', '2020-09-18 10:24:20');
INSERT INTO `book` VALUES (11, '灵魂只能独行', '江苏教育出版社', '哲学类', '2020-09-18 10:24:20');
INSERT INTO `book` VALUES (12, '神雕侠侣', '江苏教育出版社', '小说', '2020-09-18 10:24:20');
INSERT INTO `book` VALUES (13, 'old-book', '人民教育出版社', '哲学类', '2020-09-18 10:24:20');
INSERT INTO `book` VALUES (14, '三国演义', '国家图书馆出版社', '中国文学', '2020-12-04 15:31:47');SET FOREIGN_KEY_CHECKS = 1;
一、有关LIMIT的用法:
- limit使用一个参数:表示返回前3行数据
select * from book limit 3;

- limit使用两个参数:第一个参数表示从第几行开始查,第二个参数表示取第几个条数据
LIMIT的下标是从0开始的:
limit 1 offset 1;--跳过一条数据,获取第一条数据
limit 1,1;--从第一行开始查,查一条数据
SELECT * FROM book LIMIT 1 OFFSET 1;

二、有关count的用法:
- count(*),count(1):相当于统计表的行数,不会忽略列值为null的记录。
select count(*) from book;
select count(1) from book;

- count(column_name):返回指定列的列数,会忽略列值为NULL的记录(不包括空字符串和0)
select count(boook_name) from table_name ;

- count(distinct column_name):会对这列的数据去重后再统计数目
select count(distinct column_name) from table_name ;

三、order by 的用法:
- ORDER BY 关键字可以使查询返回的「结果集」按照指定的列进行排序,可以按照某「一列」排序或者同时按照「多列」进行排序,排序的顺序可以是「升序ASC」或者「降序DESC」。
select * from book order by id;--升序排
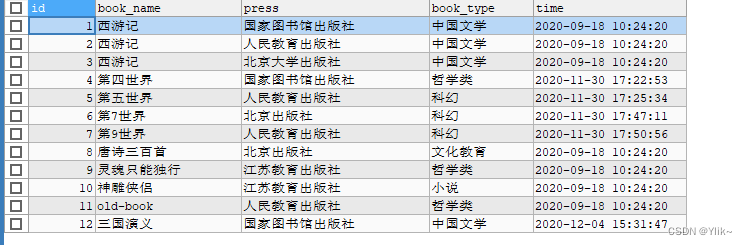
select * from book order by id desc;--降序排
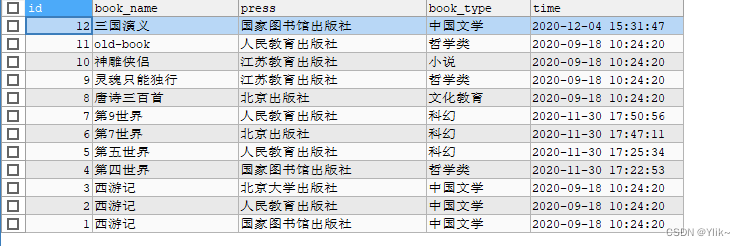
- 当ORDER BY 后有两列时,先根据第一列进行排序,当第一列相同时,再根据第二列排序:
SELECT * FROM book ORDER BY book_name,press
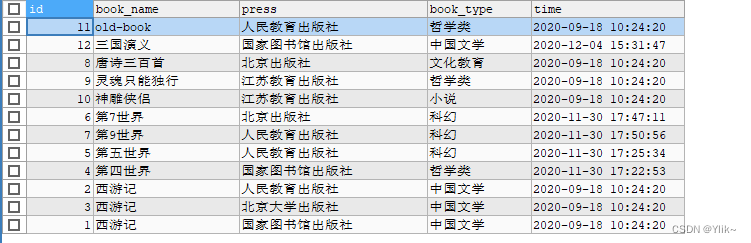
四、group by的用法:
- group by 关键字可以根据一个或多个字段对查询结果进行分组
- group by 一般都会结合Mysql聚合函数来使用
- 在 Group By 中指定的列可以是表达式或函数,但在 Select 子句中必须使用别名来引用这些列。
- 如果需要指定条件来过滤分组后的结果集,需要结合 having 关键字;原因:where不能与聚合函数联合使用 并且 where 是在 group by 之前执行的
- Group By 是一种 SQL 查询语句,常用于根据一个或多个列对查询结果进行分组。在 Group By 子句中指定的列将成为分组依据,而在 Select 子句中指定的列必须是聚合函数(例如 SUM、AVG、COUNT 等)或分组列。
SELECT COUNT(1) num,book_type FROM book GROUP BY book_type
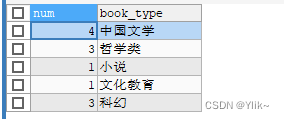
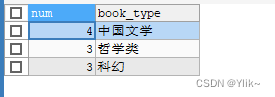
- 结合group by 结合 having使用:
- Having 子句中的条件是基于聚合函数计算的结果进行过滤的。
- 如果在 Select 子句中没有使用聚合函数,则必须在 Group By 子句中包含该列。
- 如果条件中只涉及到一个聚合函数,可以使用 WHERE 子句代替 Having 子句。
SELECT COUNT(1) num,book_type FROM book GROUP BY book_type HAVING num >1
- 经常结合group by 使用的聚合函数
AVG(col)--返回指定列的平均值
COUNT(col)--返回指定列中非NULL值的个数
MIN(col)--返回指定列的最小值
MAX(col)--返回指定列的最大值
SUM(col)--返回指定列的所有值之和
GROUP_CONCAT(col) --返回由属于一组的列值连接组合而成的结果
五、表之间的联结(inner join、left join、right join…)
-
Inner join…on…:即内连接,同时将两表作为参考对象,根据ON后给出的两表的条件将两表连接起来。结果则是两表同时满足ON后的条件的部分才会列出。
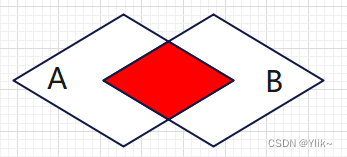
-
Left join…on…:即左连接,是以左表为基础,根据ON后给出的两表的条件将两表连接起来。结果会将左表所有的查询信息列出,而右表只列出ON后条件与左表满足的部分。左连接全称为左外连接,是外连接的一种。
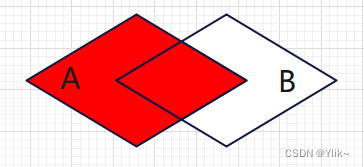
-
Right join…on….:即右连接,是以右表为基础,根据ON后给出的两表的条件将两表连接起来。结果会将右表所有的查询信息列出,而左表只列出ON后条件与右表满足的部分。右连接全称为右外连接,是外连接的一种。
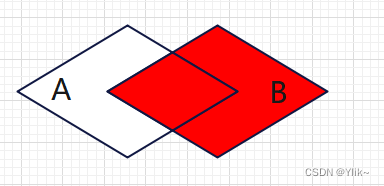
-
union 和 union all:
- 使用UNION必须有两条或者两条以上的SELECT语句组成,语句之间用UNION关键字分割
- 使用UNION关联的每个子查询必须包含相同的检索列、表达式或这聚集函数(次序可以不一样)
- 列数据类型必须兼容;类型不必完全相同,但必须是DBMS可以隐含转换的类型(不同的数值类型或者不同的日期类型)
- UNION几乎总是完成与多个WHERE条件相同的工作,UNION ALL是UNION的一种形式,它完成WHERE子句完成不了的工作,因为他将返回每个条件的匹配行(包括重复行)
- 使用组合查询,当需要对结果进行排序是,只能指定一条Order By语句,这条语句只能放在最后一天SELECT语句的后面
- UNION会对结果进行去重 UNION ALL 将子查询的结果全部合并
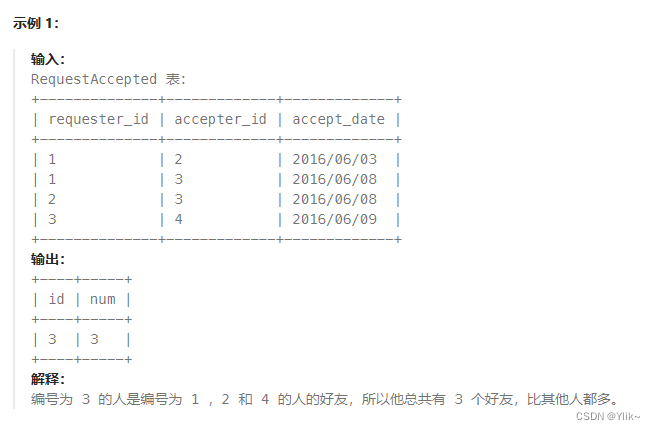
--好友申请:谁有最多的朋友
select ids id,count(1) num from
(select requester_id as ids from RequestAccepted
union all
select accepter_id from RequestAccepted
) a1
group by ids
order by num desc
limit 1
六、Mysql常用函数
不同数据库的函数往往各不相同,因此不可移植。本节主要以 MySQL 的函数为例。
1. 文本处理
| 函数 | 说明 |
|---|---|
| LEFT()、RIGHT() | 左边或者右边的字符 |
| LOWER()、UPPER() | 转换为小写或者大写 |
| LTRIM()、RTRIM() | 去除左边或者右边的空格 |
| LENGTH() | 长度,以字节为单位 |
| SOUNDEX() | 转换为语音值 |
其中, SOUNDEX() 可以将一个字符串转换为描述其语音表示的字母数字模式。
SELECT *
FROM mytable
WHERE SOUNDEX(col1) = SOUNDEX('apple')
2. 日期和时间处理
- 日期格式:YYYY-MM-DD
- 时间格式:HH:MM:SS
| 函 数 | 说 明 |
|---|---|
| AddDate() | 增加一个日期(天、周等) |
| AddTime() | 增加一个时间(时、分等) |
| CurDate() | 返回当前日期 |
| CurTime() | 返回当前时间 |
| Date() | 返回日期时间的日期部分 |
| DateDiff() | 计算两个日期之差 |
| Date_Add() | 高度灵活的日期运算函数 |
| Date_Format() | 返回一个格式化的日期或时间串 |
| Day() | 返回一个日期的天数部分 |
| DayOfWeek() | 对于一个日期,返回对应的星期几 |
| Hour() | 返回一个时间的小时部分 |
| Minute() | 返回一个时间的分钟部分 |
| Month() | 返回一个日期的月份部分 |
| Now() | 返回当前日期和时间 |
| Second() | 返回一个时间的秒部分 |
| Time() | 返回一个日期时间的时间部分 |
| Year() | 返回一个日期的年份部分 |
3. 数值处理
| 函数 | 说明 |
|---|---|
| SIN() | 正弦 |
| COS() | 余弦 |
| TAN() | 正切 |
| ABS() | 绝对值 |
| SQRT() | 平方根 |
| MOD() | 余数 |
| EXP() | 指数 |
| PI() | 圆周率 |
| RAND() | 随机数 |
4. 汇总
| 函 数 | 说 明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
| AVG() | 会忽略 NULL 行。 |
使用 DISTINCT 可以让汇总函数值汇总不同的值。
SELECT AVG(DISTINCT col1) AS avg_col
FROM mytable