图像分类:Pytorch实现Vision Transformer(ViT)进行图像分类
- 前言
- 相关介绍
- ViT模型的基本原理:
- ViT的特点与优势:
- ViT的缺点:
- 应用与拓展:
- 项目结构
- 具体步骤
- 准备数据集
- 读取数据集
- 设置并解析相关参数
- 定义网络模型
- 定义损失函数
- 定义优化器
- 训练
- 参考

前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入人工智能知识点专栏、Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页查看
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
相关介绍
- 论文地址:https://arxiv.org/abs/2010.11929
- 官方源代码地址:https://github.com/google-research/vision_transformer
- 有兴趣可查阅论文和官方源代码地址。
Vision Transformer(ViT)是谷歌在2020年提出的一种革命性的图像处理模型,它首次成功地将Transformer架构应用于计算机视觉领域,尤其是图像分类任务。之前,卷积神经网络(CNN)在视觉任务上一直占据主导地位,而ViT模型的成功表明Transformer架构也可以高效处理视觉信号。
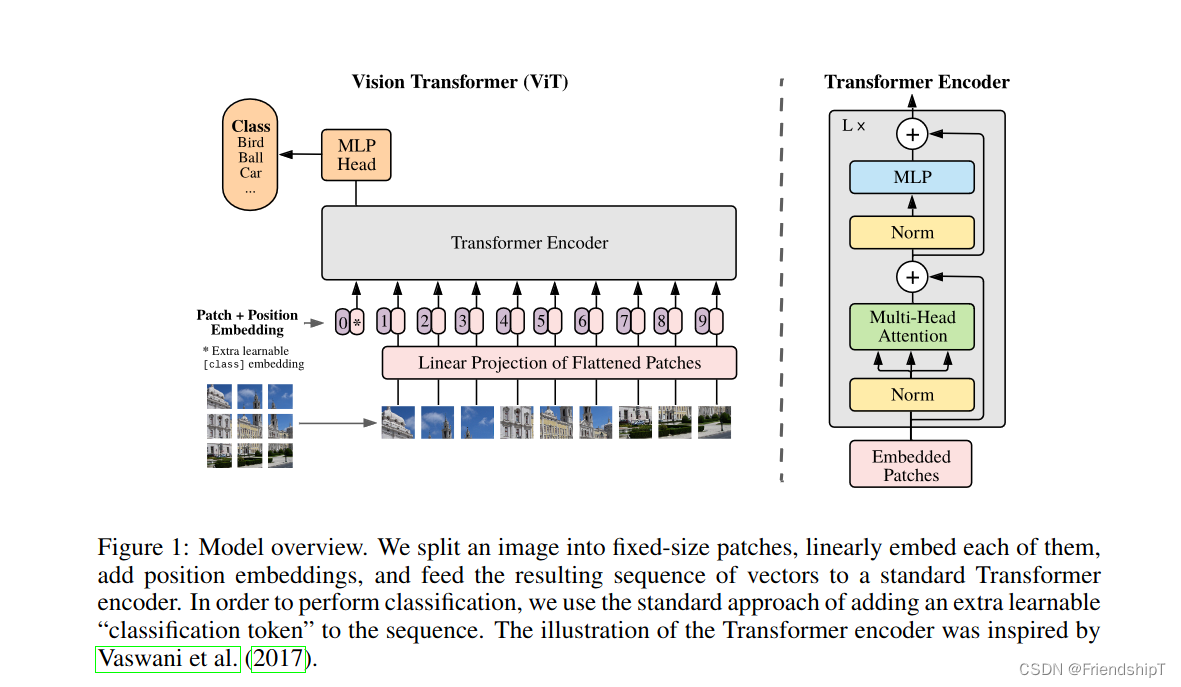
ViT模型的基本原理:
-
输入预处理:
ViT首先将输入图像分成固定大小的 patches(通常是16x16像素的小块),并将每个patch视为一个单词。接着,每个patch通过一个线性嵌入层转换成一个高维向量,类似于词嵌入在NLP中的作用。 -
位置编码:
类似于NLP中的Transformer,ViT也需要位置编码以保留图像块的空间信息,因为Transformer自身并不具备顺序信息。这通常通过向每个patch嵌入添加一个位置编码向量来实现。 -
Transformer Encoder堆叠:
获得的patch嵌入序列随后馈送到一系列的Transformer Encoder层中。每个Encoder层包含一个多头自注意力模块(Multi-Head Self-Attention)和一个前馈神经网络(FFN)。这些层允许模型捕获全局依赖关系,而不是局限于局部感受野。 -
分类头部:
与BERT等NLP模型类似,ViT模型的最后一层输出被连接到一个分类头部。对于图像分类任务,这通常是一个线性层,其输出维度对应于类别数量。 -
训练与评估:
ViT模型通常在大规模图像数据集上训练,如ImageNet,并在验证集上进行评估,结果显示即使在有限的数据集上训练,随着模型规模的增大,ViT也能取得非常优秀的性能。
ViT的特点与优势:
- 全局建模能力:由于自注意力机制,ViT可以同时考虑图像的所有部分,有利于捕捉全局上下文信息。
- 并行化处理:Transformer的自注意力机制天然支持并行计算,有助于提高训练效率。
- 可扩展性:随着模型容量的增加,ViT的表现通常能持续提升,尤其在大模型和大数据集上表现出色。
- 统一架构:ViT将视觉和语言的处理方式统一到Transformer架构下,促进了跨模态学习的发展。
ViT的缺点:
尽管Vision Transformer (ViT)在许多方面展现出了强大的潜力和优越性,但它也存在一些不足之处:
-
大量数据需求:
ViT在较小的数据集上容易过拟合,尤其是在从头开始训练时。与卷积神经网络相比,ViT通常需要更大的训练数据集才能达到最佳性能。为了解决这个问题,后续的研究提出了诸如DeiT(Data-efficient Image Transformers)等技术,利用知识蒸馏等手段来降低对大规模数据集的依赖。 -
计算资源消耗:
ViT模型的训练和推理通常需要更多的计算资源,包括内存和GPU时间。自注意力机制涉及全图谱的计算,对于长序列或者高分辨率的图像,这种计算成本可能会变得相当高昂。 -
缺乏局部特征提取:
ViT直接将图像划分为patches,虽然能够捕获全局信息,但在处理图像局部细节和纹理时可能不如卷积神经网络精细。为了解决这个问题,后来的变体如Swin Transformer引入了分层和局部窗口注意力机制。 -
迁移学习与微调:
初始阶段,ViT在下游任务上的迁移学习和微调可能不如经过长期优化的传统CNNs如ResNet方便。不过,随着预训练模型如ImageNet-21K和JFT-300M上训练的大规模ViT模型的发布,这一问题得到了一定程度的缓解。 -
复杂度和速度:
相较于轻量级的卷积神经网络,ViT在某些实时或边缘设备上的部署可能受限于其较高的计算复杂度和延迟。
尽管存在上述挑战,但随着研究的深入和硬件技术的进步,许多针对ViT的改进方案已经被提出并有效地解决了部分问题,使其在众多视觉任务中展现出越来越强的竞争力。
应用与拓展:
自从ViT提出以来,研究人员不断对其进行了各种改进和扩展,包括但不限于DeiT(Data-efficient Image Transformers)、Swin Transformer(引入了窗口注意力机制)、PVT(Pyramid Vision Transformer)等,使得Transformer架构在更多视觉任务,如目标检测、语义分割等上取得了很好的效果,并逐渐成为视觉模型设计的新范式。
项目结构
具体步骤
准备数据集
这里以CIFAR10为例。CIFAR10 数据集包含 10 类,共 60000 张彩色图片,每类图片有 6000 张。此数据集中 50000 个样例被作为训练集,剩余 10000 个样例作为测试集。类之间相互独立,不存在重叠的部分。

读取数据集
import loggingimport torchfrom torchvision import transforms, datasets
from torch.utils.data import DataLoader, RandomSampler, DistributedSampler, SequentialSamplerlogger = logging.getLogger(__name__)def get_loader(args):if args.local_rank not in [-1, 0]:torch.distributed.barrier()transform_train = transforms.Compose([transforms.RandomResizedCrop((args.img_size, args.img_size), scale=(0.05, 1.0)),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),])transform_test = transforms.Compose([transforms.Resize((args.img_size, args.img_size)),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),])if args.dataset == "cifar10":trainset = datasets.CIFAR10(root="./data",train=True,download=True,transform=transform_train)testset = datasets.CIFAR10(root="./data",train=False,download=True,transform=transform_test) if args.local_rank in [-1, 0] else Noneelse:trainset = datasets.CIFAR100(root="./data",train=True,download=True,transform=transform_train)testset = datasets.CIFAR100(root="./data",train=False,download=True,transform=transform_test) if args.local_rank in [-1, 0] else Noneif args.local_rank == 0:torch.distributed.barrier()train_sampler = RandomSampler(trainset) if args.local_rank == -1 else DistributedSampler(trainset)test_sampler = SequentialSampler(testset)train_loader = DataLoader(trainset,sampler=train_sampler,batch_size=args.train_batch_size,num_workers=0,pin_memory=True)test_loader = DataLoader(testset,sampler=test_sampler,batch_size=args.eval_batch_size,num_workers=0,pin_memory=True) if testset is not None else Nonereturn train_loader, test_loader
设置并解析相关参数
parser = argparse.ArgumentParser()# Required parametersparser.add_argument("--name", required=True,help="Name of this run. Used for monitoring.")parser.add_argument("--dataset", choices=["cifar10", "cifar100"], default="cifar10",help="Which downstream task.")parser.add_argument("--model_type", choices=["ViT-B_16", "ViT-B_32", "ViT-L_16","ViT-L_32", "ViT-H_14", "R50-ViT-B_16"],default="ViT-B_16",help="Which variant to use.")parser.add_argument("--pretrained_dir", type=str, default="checkpoint/ViT-B_16.npz",help="Where to search for pretrained ViT models.")parser.add_argument("--output_dir", default="output", type=str,help="The output directory where checkpoints will be written.")parser.add_argument("--img_size", default=224, type=int,help="Resolution size")parser.add_argument("--train_batch_size", default=16, type=int,help="Total batch size for training.")parser.add_argument("--eval_batch_size", default=64, type=int,help="Total batch size for eval.")parser.add_argument("--eval_every", default=100, type=int,help="Run prediction on validation set every so many steps.""Will always run one evaluation at the end of training.")parser.add_argument("--learning_rate", default=3e-2, type=float,help="The initial learning rate for SGD.")parser.add_argument("--weight_decay", default=0, type=float,help="Weight deay if we apply some.")parser.add_argument("--num_steps", default=10000, type=int,help="Total number of training epochs to perform.")parser.add_argument("--decay_type", choices=["cosine", "linear"], default="cosine",help="How to decay the learning rate.")parser.add_argument("--warmup_steps", default=500, type=int,help="Step of training to perform learning rate warmup for.")parser.add_argument("--max_grad_norm", default=1.0, type=float,help="Max gradient norm.")parser.add_argument("--local_rank", type=int, default=-1,help="local_rank for distributed training on gpus")parser.add_argument('--seed', type=int, default=42,help="random seed for initialization")parser.add_argument('--gradient_accumulation_steps', type=int, default=1,help="Number of updates steps to accumulate before performing a backward/update pass.")parser.add_argument('--fp16', action='store_true',help="Whether to use 16-bit float precision instead of 32-bit")parser.add_argument('--fp16_opt_level', type=str, default='O2',help="For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3'].""See details at https://nvidia.github.io/apex/amp.html")parser.add_argument('--loss_scale', type=float, default=0,help="Loss scaling to improve fp16 numeric stability. Only used when fp16 set to True.\n""0 (default value): dynamic loss scaling.\n""Positive power of 2: static loss scaling value.\n")args = parser.parse_args()# Setup CUDA, GPU & distributed trainingif args.local_rank == -1:device = torch.device("cuda" if torch.cuda.is_available() else "cpu")args.n_gpu = torch.cuda.device_count()else: # Initializes the distributed backend which will take care of sychronizing nodes/GPUstorch.cuda.set_device(args.local_rank)device = torch.device("cuda", args.local_rank)torch.distributed.init_process_group(backend='nccl',timeout=timedelta(minutes=60))args.n_gpu = 1args.device = device# Setup logginglogging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',datefmt='%m/%d/%Y %H:%M:%S',level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN)logger.warning("Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s" %(args.local_rank, args.device, args.n_gpu, bool(args.local_rank != -1), args.fp16))# Set seedset_seed(args)
定义网络模型
# coding=utf-8
from __future__ import absolute_import
from __future__ import division
from __future__ import print_functionimport copy
import logging
import mathfrom os.path import join as pjoinimport torch
import torch.nn as nn
import numpy as npfrom torch.nn import CrossEntropyLoss, Dropout, Softmax, Linear, Conv2d, LayerNorm
from torch.nn.modules.utils import _pair
from scipy import ndimageimport models.configs as configsfrom .modeling_resnet import ResNetV2logger = logging.getLogger(__name__)ATTENTION_Q = "MultiHeadDotProductAttention_1/query"
ATTENTION_K = "MultiHeadDotProductAttention_1/key"
ATTENTION_V = "MultiHeadDotProductAttention_1/value"
ATTENTION_OUT = "MultiHeadDotProductAttention_1/out"
FC_0 = "MlpBlock_3/Dense_0"
FC_1 = "MlpBlock_3/Dense_1"
ATTENTION_NORM = "LayerNorm_0"
MLP_NORM = "LayerNorm_2"def np2th(weights, conv=False):"""Possibly convert HWIO to OIHW."""if conv:weights = weights.transpose([3, 2, 0, 1])return torch.from_numpy(weights)def swish(x):return x * torch.sigmoid(x)ACT2FN = {"gelu": torch.nn.functional.gelu, "relu": torch.nn.functional.relu, "swish": swish}class Attention(nn.Module):def __init__(self, config, vis):super(Attention, self).__init__()self.vis = visself.num_attention_heads = config.transformer["num_heads"]self.attention_head_size = int(config.hidden_size / self.num_attention_heads)self.all_head_size = self.num_attention_heads * self.attention_head_sizeself.query = Linear(config.hidden_size, self.all_head_size)self.key = Linear(config.hidden_size, self.all_head_size)self.value = Linear(config.hidden_size, self.all_head_size)self.out = Linear(config.hidden_size, config.hidden_size)self.attn_dropout = Dropout(config.transformer["attention_dropout_rate"])self.proj_dropout = Dropout(config.transformer["attention_dropout_rate"])self.softmax = Softmax(dim=-1)def transpose_for_scores(self, x):new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)# print(new_x_shape)x = x.view(*new_x_shape)# print(x.shape)# print(x.permute(0, 2, 1, 3).shape)return x.permute(0, 2, 1, 3)def forward(self, hidden_states):# print(hidden_states.shape)mixed_query_layer = self.query(hidden_states)#Linear(in_features=768, out_features=768, bias=True)# print(mixed_query_layer.shape)mixed_key_layer = self.key(hidden_states)# print(mixed_key_layer.shape)mixed_value_layer = self.value(hidden_states)# print(mixed_value_layer.shape)query_layer = self.transpose_for_scores(mixed_query_layer)# print(query_layer.shape)key_layer = self.transpose_for_scores(mixed_key_layer)# print(key_layer.shape)value_layer = self.transpose_for_scores(mixed_value_layer)# print(value_layer.shape)attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))# print(attention_scores.shape)attention_scores = attention_scores / math.sqrt(self.attention_head_size)# print(attention_scores.shape)attention_probs = self.softmax(attention_scores)# print(attention_probs.shape)weights = attention_probs if self.vis else Noneattention_probs = self.attn_dropout(attention_probs)# print(attention_probs.shape)context_layer = torch.matmul(attention_probs, value_layer)# print(context_layer.shape)context_layer = context_layer.permute(0, 2, 1, 3).contiguous()# print(context_layer.shape)new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)context_layer = context_layer.view(*new_context_layer_shape)# print(context_layer.shape)attention_output = self.out(context_layer)# print(attention_output.shape)attention_output = self.proj_dropout(attention_output)# print(attention_output.shape)return attention_output, weightsclass Mlp(nn.Module):def __init__(self, config):super(Mlp, self).__init__()self.fc1 = Linear(config.hidden_size, config.transformer["mlp_dim"])self.fc2 = Linear(config.transformer["mlp_dim"], config.hidden_size)self.act_fn = ACT2FN["gelu"]self.dropout = Dropout(config.transformer["dropout_rate"])self._init_weights()def _init_weights(self):nn.init.xavier_uniform_(self.fc1.weight)nn.init.xavier_uniform_(self.fc2.weight)nn.init.normal_(self.fc1.bias, std=1e-6)nn.init.normal_(self.fc2.bias, std=1e-6)def forward(self, x):x = self.fc1(x)x = self.act_fn(x)x = self.dropout(x)x = self.fc2(x)x = self.dropout(x)return xclass Embeddings(nn.Module):"""Construct the embeddings from patch, position embeddings."""def __init__(self, config, img_size, in_channels=3):super(Embeddings, self).__init__()self.hybrid = Noneimg_size = _pair(img_size)if config.patches.get("grid") is not None:grid_size = config.patches["grid"]patch_size = (img_size[0] // 16 // grid_size[0], img_size[1] // 16 // grid_size[1])n_patches = (img_size[0] // 16) * (img_size[1] // 16)self.hybrid = Trueelse:patch_size = _pair(config.patches["size"])n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1])self.hybrid = Falseif self.hybrid:self.hybrid_model = ResNetV2(block_units=config.resnet.num_layers,width_factor=config.resnet.width_factor)in_channels = self.hybrid_model.width * 16self.patch_embeddings = Conv2d(in_channels=in_channels,out_channels=config.hidden_size,kernel_size=patch_size,stride=patch_size)self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches+1, config.hidden_size))self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))self.dropout = Dropout(config.transformer["dropout_rate"])def forward(self, x):# print(x.shape)B = x.shape[0]cls_tokens = self.cls_token.expand(B, -1, -1)# print(cls_tokens.shape)if self.hybrid:x = self.hybrid_model(x)x = self.patch_embeddings(x)#Conv2d: Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))# print(x.shape)x = x.flatten(2)# print(x.shape)x = x.transpose(-1, -2)# print(x.shape)x = torch.cat((cls_tokens, x), dim=1)# print(x.shape)embeddings = x + self.position_embeddings# print(embeddings.shape)embeddings = self.dropout(embeddings)# print(embeddings.shape)return embeddingsclass Block(nn.Module):def __init__(self, config, vis):super(Block, self).__init__()self.hidden_size = config.hidden_sizeself.attention_norm = LayerNorm(config.hidden_size, eps=1e-6)self.ffn_norm = LayerNorm(config.hidden_size, eps=1e-6)self.ffn = Mlp(config)self.attn = Attention(config, vis)def forward(self, x):# print(x.shape)h = xx = self.attention_norm(x)# print(x.shape)x, weights = self.attn(x)x = x + h# print(x.shape)h = xx = self.ffn_norm(x)# print(x.shape)x = self.ffn(x)# print(x.shape)x = x + h# print(x.shape)return x, weightsdef load_from(self, weights, n_block):ROOT = f"Transformer/encoderblock_{n_block}"with torch.no_grad():# linux下路径按照这个query_weight = np2th(weights[pjoin(ROOT, ATTENTION_Q, "kernel")]).view(self.hidden_size, self.hidden_size).t()key_weight = np2th(weights[pjoin(ROOT, ATTENTION_K, "kernel")]).view(self.hidden_size, self.hidden_size).t()value_weight = np2th(weights[pjoin(ROOT, ATTENTION_V, "kernel")]).view(self.hidden_size, self.hidden_size).t()out_weight = np2th(weights[pjoin(ROOT, ATTENTION_OUT, "kernel")]).view(self.hidden_size, self.hidden_size).t()query_bias = np2th(weights[pjoin(ROOT, ATTENTION_Q, "bias")]).view(-1)key_bias = np2th(weights[pjoin(ROOT, ATTENTION_K, "bias")]).view(-1)value_bias = np2th(weights[pjoin(ROOT, ATTENTION_V, "bias")]).view(-1)out_bias = np2th(weights[pjoin(ROOT, ATTENTION_OUT, "bias")]).view(-1)self.attn.query.weight.copy_(query_weight)self.attn.key.weight.copy_(key_weight)self.attn.value.weight.copy_(value_weight)self.attn.out.weight.copy_(out_weight)self.attn.query.bias.copy_(query_bias)self.attn.key.bias.copy_(key_bias)self.attn.value.bias.copy_(value_bias)self.attn.out.bias.copy_(out_bias)mlp_weight_0 = np2th(weights[pjoin(ROOT, FC_0, "kernel")]).t()mlp_weight_1 = np2th(weights[pjoin(ROOT, FC_1, "kernel")]).t()mlp_bias_0 = np2th(weights[pjoin(ROOT, FC_0, "bias")]).t()mlp_bias_1 = np2th(weights[pjoin(ROOT, FC_1, "bias")]).t()self.ffn.fc1.weight.copy_(mlp_weight_0)self.ffn.fc2.weight.copy_(mlp_weight_1)self.ffn.fc1.bias.copy_(mlp_bias_0)self.ffn.fc2.bias.copy_(mlp_bias_1)self.attention_norm.weight.copy_(np2th(weights[pjoin(ROOT, ATTENTION_NORM, "scale")]))self.attention_norm.bias.copy_(np2th(weights[pjoin(ROOT, ATTENTION_NORM, "bias")]))self.ffn_norm.weight.copy_(np2th(weights[pjoin(ROOT, MLP_NORM, "scale")]))self.ffn_norm.bias.copy_(np2th(weights[pjoin(ROOT, MLP_NORM, "bias")]))"""query_weight = np2th(weights[ROOT + "/" + ATTENTION_Q + "/" + "kernel"]).view(self.hidden_size, self.hidden_size).t()key_weight = np2th(weights[ROOT + "/" + ATTENTION_K+ "/" + "kernel"]).view(self.hidden_size, self.hidden_size).t()value_weight = np2th(weights[ROOT + "/" + ATTENTION_V+"/" + "kernel"]).view(self.hidden_size, self.hidden_size).t()out_weight = np2th(weights[ROOT + "/" + ATTENTION_OUT+"/" + "kernel"]).view(self.hidden_size, self.hidden_size).t()query_bias = np2th(weights[ROOT + "/" + ATTENTION_Q+"/" + "bias"]).view(-1)key_bias = np2th(weights[ROOT + "/" + ATTENTION_K+"/" + "bias"]).view(-1)value_bias = np2th(weights[ROOT + "/" + ATTENTION_V+"/" + "bias"]).view(-1)out_bias = np2th(weights[ROOT + "/" + ATTENTION_OUT+"/" + "bias"]).view(-1)self.attn.query.weight.copy_(query_weight)self.attn.key.weight.copy_(key_weight)self.attn.value.weight.copy_(value_weight)self.attn.out.weight.copy_(out_weight)self.attn.query.bias.copy_(query_bias)self.attn.key.bias.copy_(key_bias)self.attn.value.bias.copy_(value_bias)self.attn.out.bias.copy_(out_bias)mlp_weight_0 = np2th(weights[ROOT + "/" + FC_0+"/" + "kernel"]).t()mlp_weight_1 = np2th(weights[ROOT + "/" + FC_1+"/" + "kernel"]).t()mlp_bias_0 = np2th(weights[ROOT + "/" + FC_0+"/" +"bias"]).t()mlp_bias_1 = np2th(weights[ROOT + "/" + FC_1+"/" +"bias"]).t()self.ffn.fc1.weight.copy_(mlp_weight_0)self.ffn.fc2.weight.copy_(mlp_weight_1)self.ffn.fc1.bias.copy_(mlp_bias_0)self.ffn.fc2.bias.copy_(mlp_bias_1)self.attention_norm.weight.copy_(np2th(weights[ROOT + "/" + ATTENTION_NORM+"/" + "scale"]))self.attention_norm.bias.copy_(np2th(weights[ROOT + "/" + ATTENTION_NORM+"/" + "bias"]))self.ffn_norm.weight.copy_(np2th(weights[ROOT + "/" + MLP_NORM+"/" + "scale"]))self.ffn_norm.bias.copy_(np2th(weights[ROOT + "/" + MLP_NORM+"/" + "bias"]))""" class Encoder(nn.Module):def __init__(self, config, vis):super(Encoder, self).__init__()self.vis = visself.layer = nn.ModuleList()self.encoder_norm = LayerNorm(config.hidden_size, eps=1e-6)for _ in range(config.transformer["num_layers"]):layer = Block(config, vis)self.layer.append(copy.deepcopy(layer))def forward(self, hidden_states):# print(hidden_states.shape)attn_weights = []for layer_block in self.layer:hidden_states, weights = layer_block(hidden_states)if self.vis:attn_weights.append(weights)encoded = self.encoder_norm(hidden_states)return encoded, attn_weightsclass Transformer(nn.Module):def __init__(self, config, img_size, vis):super(Transformer, self).__init__()self.embeddings = Embeddings(config, img_size=img_size)self.encoder = Encoder(config, vis)def forward(self, input_ids):embedding_output = self.embeddings(input_ids)encoded, attn_weights = self.encoder(embedding_output)return encoded, attn_weightsclass VisionTransformer(nn.Module):def __init__(self, config, img_size=224, num_classes=21843, zero_head=False, vis=False):super(VisionTransformer, self).__init__()self.num_classes = num_classesself.zero_head = zero_headself.classifier = config.classifierself.transformer = Transformer(config, img_size, vis)self.head = Linear(config.hidden_size, num_classes)def forward(self, x, labels=None):x, attn_weights = self.transformer(x)# print(x.shape)logits = self.head(x[:, 0])# print(logits.shape)if labels is not None:loss_fct = CrossEntropyLoss()loss = loss_fct(logits.view(-1, self.num_classes), labels.view(-1))return losselse:return logits, attn_weightsdef load_from(self, weights):with torch.no_grad():if self.zero_head:nn.init.zeros_(self.head.weight)nn.init.zeros_(self.head.bias)else:self.head.weight.copy_(np2th(weights["head/kernel"]).t())self.head.bias.copy_(np2th(weights["head/bias"]).t())self.transformer.embeddings.patch_embeddings.weight.copy_(np2th(weights["embedding/kernel"], conv=True))self.transformer.embeddings.patch_embeddings.bias.copy_(np2th(weights["embedding/bias"]))self.transformer.embeddings.cls_token.copy_(np2th(weights["cls"]))self.transformer.encoder.encoder_norm.weight.copy_(np2th(weights["Transformer/encoder_norm/scale"]))self.transformer.encoder.encoder_norm.bias.copy_(np2th(weights["Transformer/encoder_norm/bias"]))posemb = np2th(weights["Transformer/posembed_input/pos_embedding"])posemb_new = self.transformer.embeddings.position_embeddingsif posemb.size() == posemb_new.size():self.transformer.embeddings.position_embeddings.copy_(posemb)else:logger.info("load_pretrained: resized variant: %s to %s" % (posemb.size(), posemb_new.size()))ntok_new = posemb_new.size(1)if self.classifier == "token":posemb_tok, posemb_grid = posemb[:, :1], posemb[0, 1:]ntok_new -= 1else:posemb_tok, posemb_grid = posemb[:, :0], posemb[0]gs_old = int(np.sqrt(len(posemb_grid)))gs_new = int(np.sqrt(ntok_new))# print('load_pretrained: grid-size from %s to %s' % (gs_old, gs_new))posemb_grid = posemb_grid.reshape(gs_old, gs_old, -1)zoom = (gs_new / gs_old, gs_new / gs_old, 1)posemb_grid = ndimage.zoom(posemb_grid, zoom, order=1)posemb_grid = posemb_grid.reshape(1, gs_new * gs_new, -1)posemb = np.concatenate([posemb_tok, posemb_grid], axis=1)self.transformer.embeddings.position_embeddings.copy_(np2th(posemb))for bname, block in self.transformer.encoder.named_children():for uname, unit in block.named_children():unit.load_from(weights, n_block=uname)if self.transformer.embeddings.hybrid:self.transformer.embeddings.hybrid_model.root.conv.weight.copy_(np2th(weights["conv_root/kernel"], conv=True))gn_weight = np2th(weights["gn_root/scale"]).view(-1)gn_bias = np2th(weights["gn_root/bias"]).view(-1)self.transformer.embeddings.hybrid_model.root.gn.weight.copy_(gn_weight)self.transformer.embeddings.hybrid_model.root.gn.bias.copy_(gn_bias)for bname, block in self.transformer.embeddings.hybrid_model.body.named_children():for uname, unit in block.named_children():unit.load_from(weights, n_block=bname, n_unit=uname)CONFIGS = {'ViT-B_16': configs.get_b16_config(),'ViT-B_32': configs.get_b32_config(),'ViT-L_16': configs.get_l16_config(),'ViT-L_32': configs.get_l32_config(),'ViT-H_14': configs.get_h14_config(),'R50-ViT-B_16': configs.get_r50_b16_config(),'testing': configs.get_testing(),
}
定义损失函数
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_classes), labels.view(-1))
# define loss function (criterion)if config['loss'] == 'BCEWithLogitsLoss':criterion = nn.BCEWithLogitsLoss().cuda()#WithLogits 就是先将输出结果经过sigmoid再交叉熵else:criterion = losses.__dict__[config['loss']]().cuda()cudnn.benchmark = True
定义优化器
# Prepare optimizer and scheduleroptimizer = torch.optim.SGD(model.parameters(),lr=args.learning_rate,momentum=0.9,weight_decay=args.weight_decay)#L2的系数t_total = args.num_stepsif args.decay_type == "cosine":scheduler = WarmupCosineSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)else:scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)
训练
def train(args, model):""" Train the model """if args.local_rank in [-1, 0]:os.makedirs(args.output_dir, exist_ok=True)writer = SummaryWriter(log_dir=os.path.join("logs", args.name))args.train_batch_size = args.train_batch_size // args.gradient_accumulation_steps# Prepare datasettrain_loader, test_loader = get_loader(args)# Prepare optimizer and scheduleroptimizer = torch.optim.SGD(model.parameters(),lr=args.learning_rate,momentum=0.9,weight_decay=args.weight_decay)#L2的系数t_total = args.num_stepsif args.decay_type == "cosine":scheduler = WarmupCosineSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)else:scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)"""if args.fp16:model, optimizer = amp.initialize(models=model,optimizers=optimizer,opt_level=args.fp16_opt_level)amp._amp_state.loss_scalers[0]._loss_scale = 2**20# Distributed trainingif args.local_rank != -1:model = DDP(model, message_size=250000000, gradient_predivide_factor=get_world_size())"""# Train!logger.info("***** Running training *****")logger.info(" Total optimization steps = %d", args.num_steps)logger.info(" Instantaneous batch size per GPU = %d", args.train_batch_size)logger.info(" Total train batch size (w. parallel, distributed & accumulation) = %d",args.train_batch_size * args.gradient_accumulation_steps * (torch.distributed.get_world_size() if args.local_rank != -1 else 1))logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)model.zero_grad()set_seed(args) # Added here for reproducibility (even between python 2 and 3)losses = AverageMeter()global_step, best_acc = 0, 0while True:model.train()epoch_iterator = tqdm(train_loader,desc="Training (X / X Steps) (loss=X.X)",bar_format="{l_bar}{r_bar}",dynamic_ncols=True,disable=args.local_rank not in [-1, 0])for step, batch in enumerate(epoch_iterator):batch = tuple(t.to(args.device) for t in batch)x, y = batchloss = model(x, y)if args.gradient_accumulation_steps > 1:loss = loss / args.gradient_accumulation_stepsif args.fp16:with amp.scale_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()else:loss.backward()if (step + 1) % args.gradient_accumulation_steps == 0:losses.update(loss.item()*args.gradient_accumulation_steps)if args.fp16:torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)else:torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)scheduler.step()optimizer.step()optimizer.zero_grad()global_step += 1epoch_iterator.set_description("Training (%d / %d Steps) (loss=%2.5f)" % (global_step, t_total, losses.val))if args.local_rank in [-1, 0]:writer.add_scalar("train/loss", scalar_value=losses.val, global_step=global_step)writer.add_scalar("train/lr", scalar_value=scheduler.get_lr()[0], global_step=global_step)if global_step % args.eval_every == 0 and args.local_rank in [-1, 0]:accuracy = valid(args, model, writer, test_loader, global_step)if best_acc < accuracy:save_model(args, model)best_acc = accuracymodel.train()if global_step % t_total == 0:breaklosses.reset()if global_step % t_total == 0:breakif args.local_rank in [-1, 0]:writer.close()logger.info("Best Accuracy: \t%f" % best_acc)logger.info("End Training!")
$ python train.py --name cifar10-100_500 --dataset cifar10 --model_type ViT-B_16 --num_steps 100
04/16/2024 17:59:27 - INFO - models.modeling - load_pretrained: resized variant: torch.Size([1, 577, 768]) to torch.Size([1, 197, 768])
04/16/2024 17:59:30 - INFO - __main__ - classifier: token
hidden_size: 768
patches:size: !!python/tuple- 16- 16
representation_size: null
transformer:attention_dropout_rate: 0.0dropout_rate: 0.1mlp_dim: 3072num_heads: 12num_layers: 1204/16/2024 17:59:30 - INFO - __main__ - Training parameters Namespace(dataset='cifar10', decay_type='cosine', device=device(type='cuda'), eval_batch_size=64, eval_every=100, fp16=False, fp16_opt_level='O2', gradient_accumulation_steps=1, img_size=224, learning_rate=0.03, local_rank=-1, loss_scale=0, max_grad_norm=1.0, model_type='ViT-B_16', n_gpu=1, name='cifar10-100_500', num_steps=100, output_dir='output', pretrained_dir='checkpoint/ViT-B_16.npz', seed=42, train_batch_size=16, warmup_steps=500, weight_decay=0)
04/16/2024 17:59:30 - INFO - __main__ - Total Parameter: 85.8M
85.806346
Files already downloaded and verified
04/16/2024 17:59:31 - INFO - __main__ - ***** Running training *****
04/16/2024 17:59:31 - INFO - __main__ - Total optimization steps = 100
04/16/2024 17:59:31 - INFO - __main__ - Instantaneous batch size per GPU = 16
04/16/2024 17:59:31 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 16
04/16/2024 17:59:31 - INFO - __main__ - Gradient Accumulation steps = 1
Training (X / X Steps) (loss=X.X): 0%|| 0/3125 [00:00<?, ?it/s]
Training (100 / 100 Steps) (loss=1.00880): 3%|| 99/3125 [00:19<09:57, 5.06it/s]04/16/2024 17:59:50 - INFO - __main__ - ***** Running Validation *****
04/16/2024 17:59:50 - INFO - __main__ - Num steps = 157
04/16/2024 17:59:50 - INFO - __main__ - Batch size = 64
Validating... (loss=0.36825): 100%|| 157/157 [00:40<00:00, 3.84it/s]
04/16/2024 18:00:31 - INFO - __main__ - /157 [00:40<00:00, 3.93it/s]04/16/2024 18:00:31 - INFO - __main__ - Validation Results
04/16/2024 18:00:31 - INFO - __main__ - Global Steps: 100
04/16/2024 18:00:31 - INFO - __main__ - Valid Loss: 0.36111
04/16/2024 18:00:31 - INFO - __main__ - Valid Accuracy: 0.95660
04/16/2024 18:00:31 - INFO - __main__ - Saved model checkpoint to [DIR: output]
Training (100 / 100 Steps) (loss=1.00880): 3%|| 99/3125 [01:00<30:53, 1.63it/s]
04/16/2024 18:00:31 - INFO - __main__ - Best Accuracy: 0.956600
04/16/2024 18:00:31 - INFO - __main__ - End Training!
参考
[1] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. 2020
[2] ViT源代码地址. https://github.com/google-research/vision_transformer
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入人工智能知识点专栏、Python日常小操作专栏、OpenCV-Python小应用专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页查看
- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目