以 t1 表和索引为例子,下面两张图说明了存储层如何存储数据。
create table t1 (id1 int, id2 int, name varchar(10), salary int, primary key(id1, id2))
with column group (each column);create index idx (name) storing(salary)
with column group(each column);

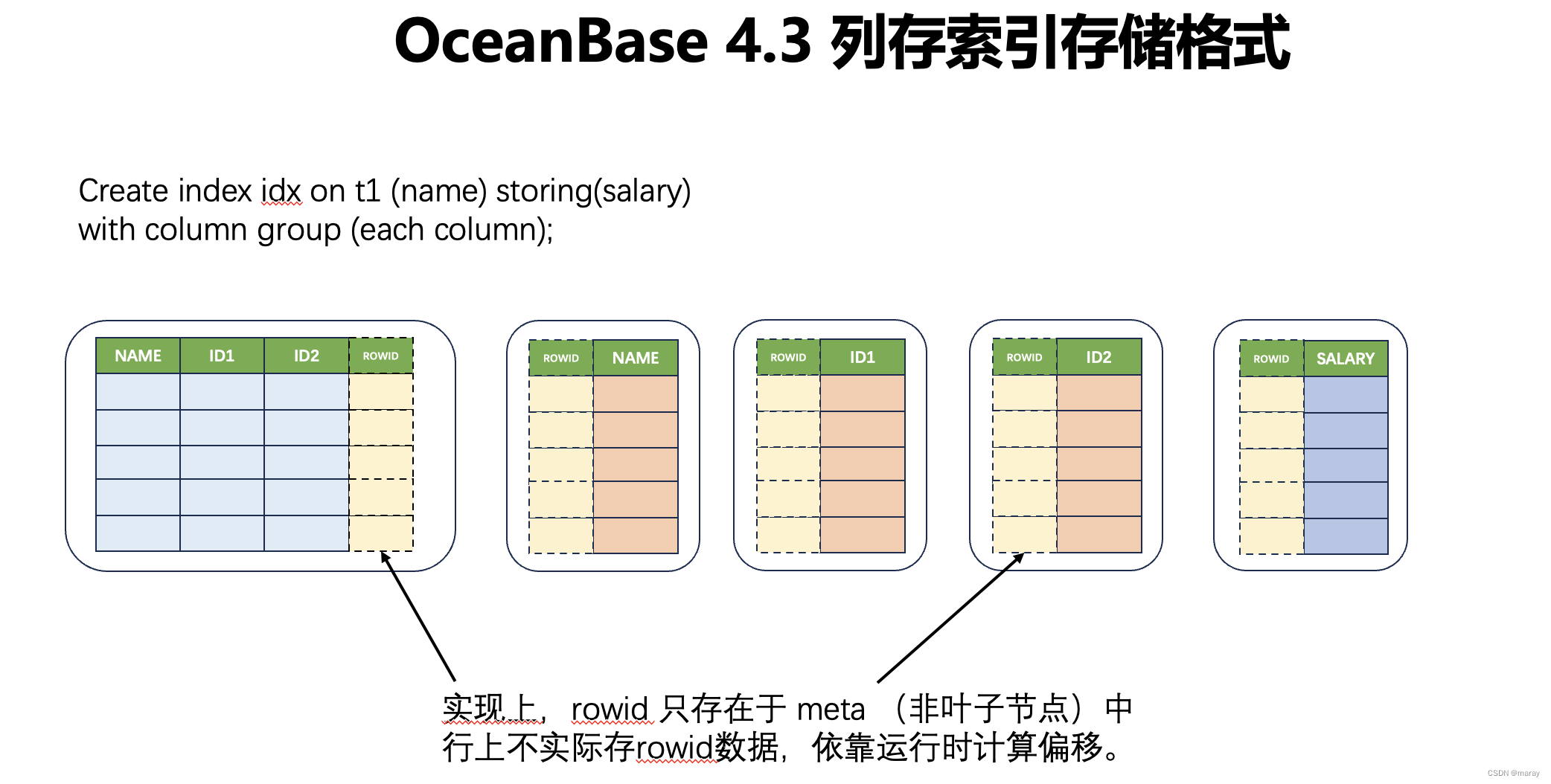
- 对于主表,主键部分总是会另存一份作为一个 column group。
- 对于索引表,索引列+主键列也会作为一个 column group 另存一份
- 上述两个 column group 里都会存一个叫做 rowid 的东西,rowid 用于在其它列中定位对应行
- rowid 并不是保存于每一行(上述图中仅为概念示意图),而是把 id 的范围保存在微块 meta 中。
- 列存的一次点查,先在 btree 里通过主键找到对应行,拿到 rowid,然后 rowid 去列里面定位对应的微块,然后用 rowid 计算微块内的偏移,定位到这个 column group 中的行数据。
- 在 each column 的场景中,虽然主键会组成一个 column group,但主键中的每一列,依然会作为一个独立的列再重复保存一次。这里有一定的额外存储开销。