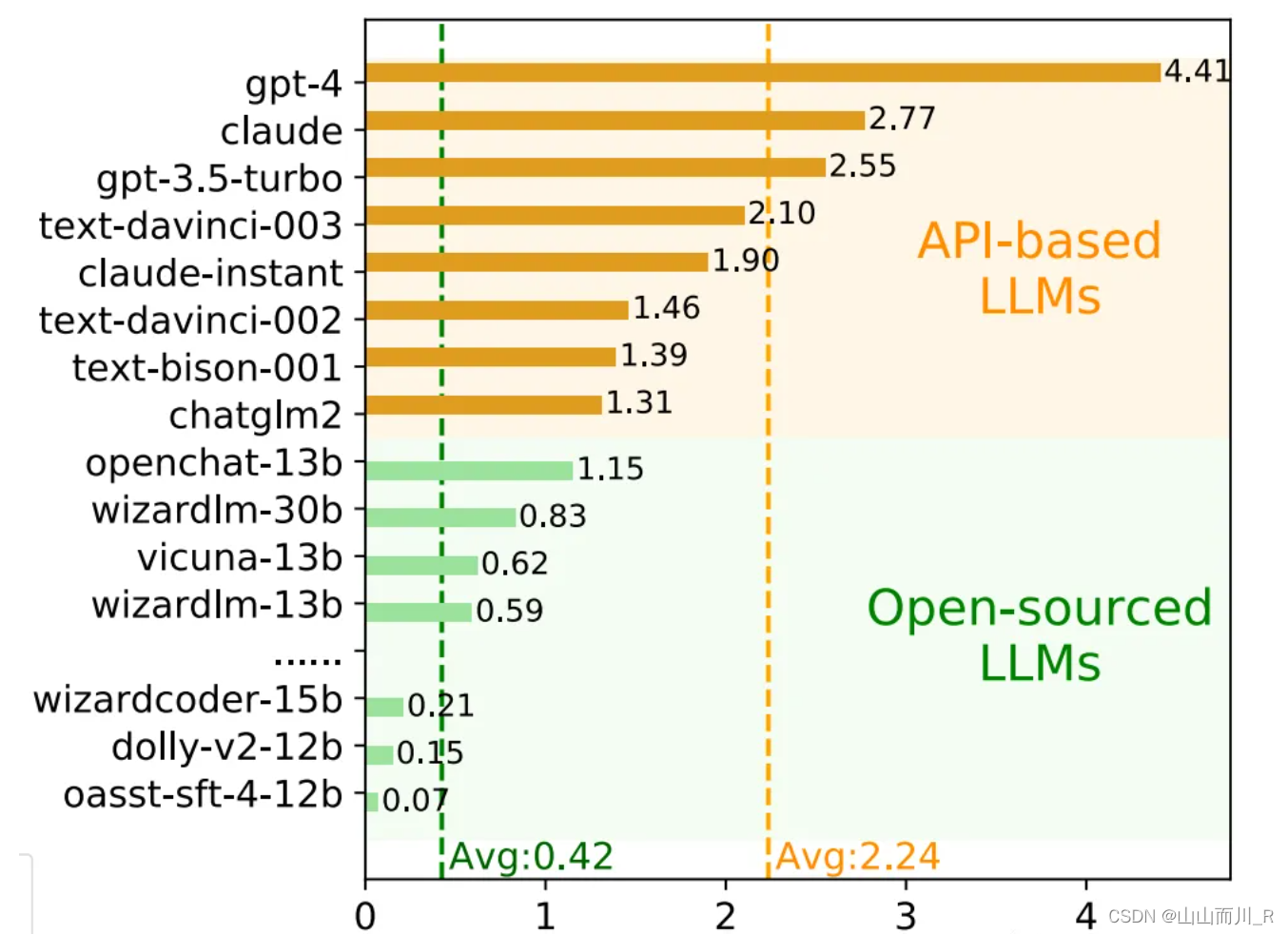
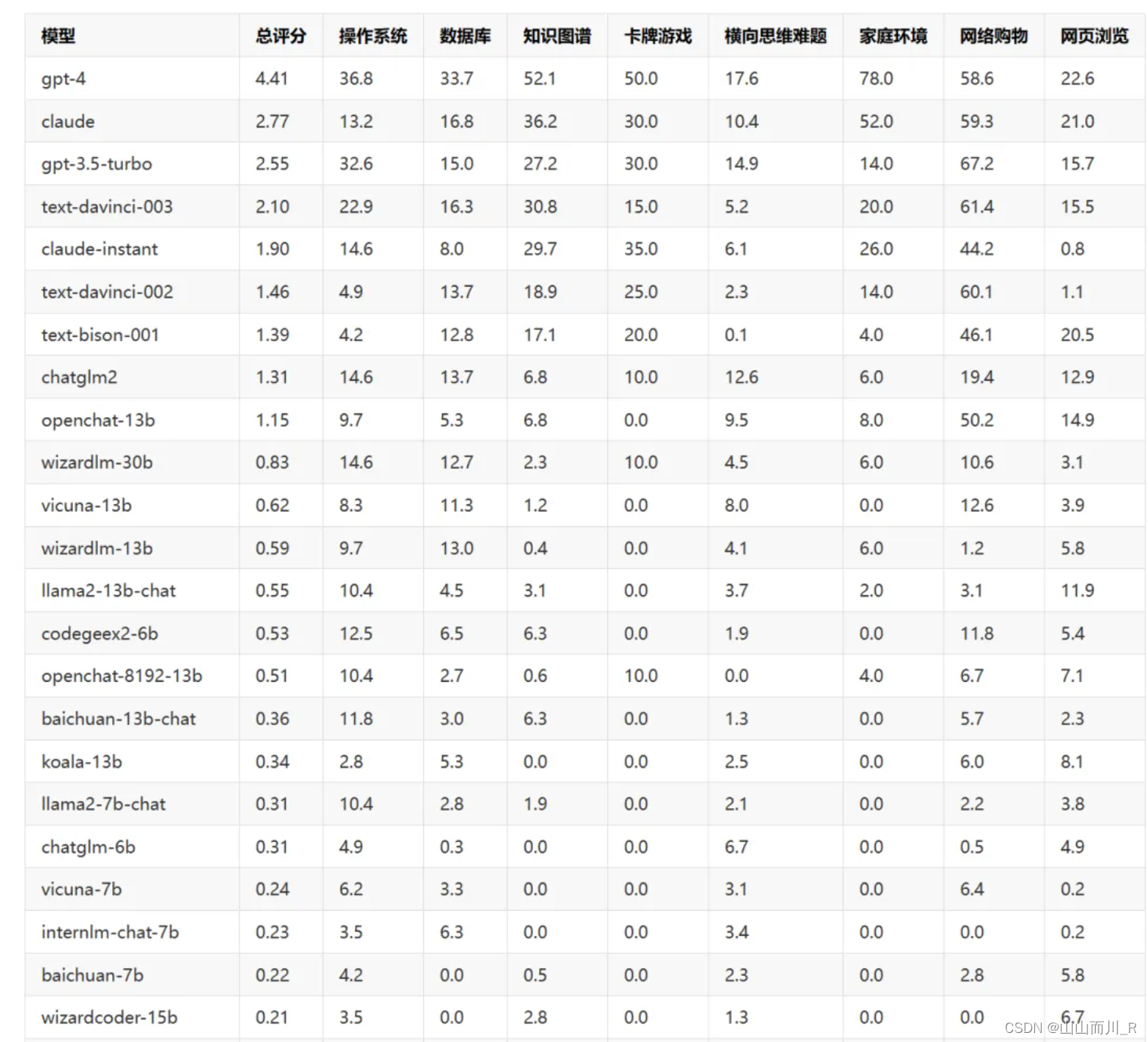
AI Agent能力评测工具AgentBench评测结果
LoRA模型是什么?
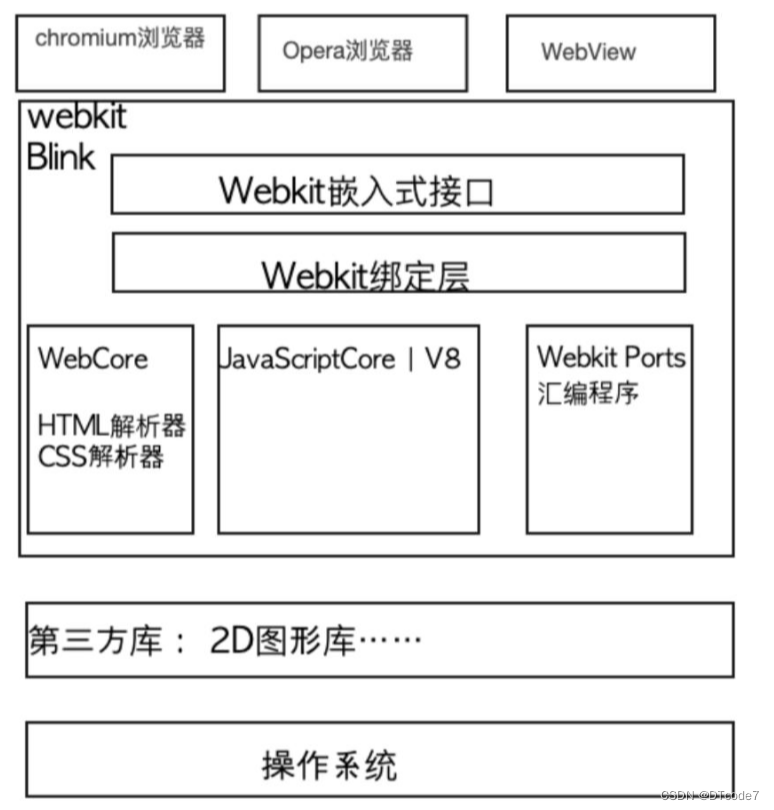
LoRA模型(Low-Rank Adaptation of Large Language Models)是一种针对大型语言模型(LLMs)的微调技术,其目的是在保持模型原有性能的基础上,以较小的计算资源和数据量实现模型的快速适应特定任务或领域。LoRA方法通过引入低秩近似(low-rank approximation)的思想,对大型预训练语言模型的部分权重进行高效且轻量级的调整,从而实现对模型的定制化改造,而不必重新训练整个模型。以下是LoRA模型的关键特性与工作原理:
工作原理与关键技术要点:
-
低秩矩阵注入:
- LoRA在大型语言模型(如GPT-3)中选定一组特定层(通常为Transformer的注意力层),在这些层中引入一对低秩矩阵(通常为稀疏的),分别对应于权重矩阵的增加项(additive update)和乘法项(multiplicative update)。
- 这些低秩矩阵通常具有较小的秩(rank),比如远小于原始权重矩阵的维度,这意味着它们包含的参数数量远少于直接微调整个模型所需。
-
微调过程:
- 在微调阶段,只训练这些低秩矩阵的参数,而保持原模型其余部分的权重不变(即冻结)。
- 通过在特定任务的数据集上训练这些少量额外参数,LoRA能够引导模型在保持原有语言理解能力的同时,针对性地学习任务相关的语言模式和知识。
-
内存效率与计算效率:
- 由于只需训练一小部分参数,LoRA显著降低了微调过程中的内存需求和计算成本。
- 在推理阶段,这些低秩矩阵可以在运行时动态地与原模型权重相加或相乘,无需改变模型结构或重新存储整个模型,进一步节省了资源。
-
应用与扩展:
- LoRA不仅适用于文本生成、文本分类、问答等传统的NLP任务,还可以与其他模型组件结合,如与stable diffusion(SD)模型一起使用,以改变或定制SD模型的生成风格或添加特定人物/IP
- LoRA方法也可以看作是一种插件式的微调策略,使得用户可以根据需求快速定制不同的大型语言模型,而无需从头训练或完全微调模型
总结,LoRA模型是一种轻量级的微调技术,它通过在大型预训练语言模型中注入低秩矩阵来适应特定任务,既保留了原模型的泛化能力,又显著降低了微调所需的计算资源和数据量,为高效利用和定制化大型语言模型提供了实用工具
另一种解释:
LoRA(Low-Rank Adaptation of Large Language Models,大型语言模型的低秩适应)是微软研究员提出的一种新颖技术,旨在解决微调大型语言模型的问题。具有数十亿参数的强大模型,如GPT-3,要对其进行微调以适应特定任务或领域的成本非常高。LoRA提议冻结预训练模型的权重,并在每个Transformer块中注入可训练层(称为秩分解矩阵)。这大大减少了可训练参数的数量和GPU内存需求,因为大部分模型权重不需要计算梯度。研究人员发现,通过专注于大型语言模型的Transformer注意力块,LoRA的微调质量与完整模型的微调相当,同时速度更快,计算需求更低。
尽管LoRA最初是为大型语言模型提出的,但这种技术也可以应用在其他地方。在Stable Diffusion微调的情况下,LoRA可以应用于与描述它们的提示相关的图像表示之间的交叉注意力层。LoRA微调的优点包括:
- 训练速度更快
- 计算需求更低
- 训练权重更小,因为原始模型被冻结,我们注入新的可训练层,可以将新层的权重保存为一个约3MB大小的文件,比UNet模型的原始大小小了近一千倍。
LoRA可以与其他技术结合使用,例如Dreambooth,使训练更快、只需少量图像即可实现目标学习,还可以调整文本编码器以获得更高的主题保真度。总之,LoRA为微调大型语言模型提供了一种快速、低成本的解决方案,使模型能够更容易地适应新的领域或数据集。