Phi-3-mini
phi-3-mini,一个3.8亿个参数的语言模型,训练了3.3万亿个token,其总体性能,通过学术基准和内部测试进行衡量,可以与Mixtral 8x7B和GPT-3.5等模型相媲美(在MMLU上达到69%,在MT-bench上达到8.38),它是足够小,可以部署在手机上。

phi-3-mini模型是一个transformer-decoder架构,默认上下文长度为4K。作者还通过LongRope 引入了一个长上下文版本,它将上下文长度扩展到128K,称为phi-3-mini-128K。
为了最大限度地造福开源社区,phi-3-mini建立在与Llama-2相似的块结构上,并使用相同的标记器,词汇量为320641。这意味着为Llama-2系列型号开发的所有软件包都可以直接适用于phi-3-mini。该模型使用了3072个隐藏维度,32个头部和32个图层。我们使用bfloat16对总共3.3T token进行了训练。
聊天模板如下:
![]()
Phi-3-small
phi-3-small模型(7B参数)利用词汇表大小为100352的tik token标记器(用于更好的多语言标记),默认上下文长度为8K。它遵循7B模型类的标准解码器架构,有32层,隐藏尺寸为4096。为了最小化KV缓存占用,该模型还利用分组查询关注,4个查询共享一个键。此外,phi-3-small使用替代的密集关注层和一种新的块稀疏关注来进一步优化KV缓存节省,同时保持长上下文检索性能。该模型还使用了另外10%的多语种数据 。
由于体积小,phi3-mini可以量化为4bits,只占用约1.8GB的内存。作者通过在带有A16仿生芯片的iPhone 14上部署phi-3-mini来测试量化模型,该芯片在设备上本机运行,完全离线,每秒超过12个token。
Training Methodology
作者遵循了一个前人提出的工作顺序,利用高质量的训练数据来提高小型语言模型的性能,并偏离标准的缩放定律。Phi-3-mini的训练数据包括来自各种开放互联网资源的严格过滤的网络数据以及合成的LLM生成的数据。
预训练分两个不相交的连续阶段进行;第一阶段主要由网络资源组成,旨在教授模型一般知识和语言理解;阶段2将过滤更严格的web数据(阶段1中使用的子集)与一些合成数据合并,这些合成数据可以教授模型逻辑推理和各种利基技能。
Data Optimal Regime
与之前在“计算最佳方案”或“过度训练方案”中训练语言模型的工作不同,我们主要关注给定规模的数据质量。我们尝试校准训练数据,使其更接近小型模型的“数据最佳”方案。特别是,我们过滤web数据以包含正确的“知识”水平,并保留更多可能提高模型“推理能力”的网页。例如,某一天英超联赛的比赛结果可能是前沿模型的良好训练数据,但我们需要删除此类信息,以便为迷你模型的“推理”留下更多模型容量。下图与Llama-2进行了比较。
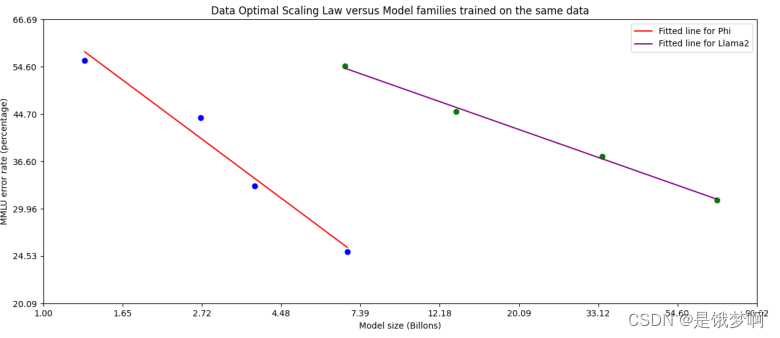
上图绘制了MMLU误差的对数与模型大小的对数的关系图从左至右:phi-1.5、phi-2、phi-3-mini、phi-3small与基于相同固定数据训练的Llama-2系列模型(7B、13B、34B、70B)的对比。
Post-training
phi-3-mini的后期训练经历了两个阶段,包括监督微调(SFT)和直接偏好优化(DPO)。SFT利用不同领域的高度精选的高质量数据,例如数学、编码、推理、对话、模型身份和安全。SFT数据组合从使用纯英语示例开始。DPO数据涵盖了聊天格式数据、推理和负责任的人工智能(RAI)工作。我们使用DPO通过使用那些输出作为“拒绝”响应来引导模型远离不想要的行为。除了在数学、编码、推理、鲁棒性和安全性方面的改进外,后期训练还将语言模型转换为用户可以高效、安全交互的人工智能助手。
Academic benchmarks
我们与phi-2、Mistral-7 b-v 0.1、Mixtral-8x7b、Gemma 7B、Llama-3-instruct8b和GPT-3.5进行了比较。

Safety
整体方法包括培训后的安全调整、red-teaming、自动化测试和几十种RAI危害类别的评估。
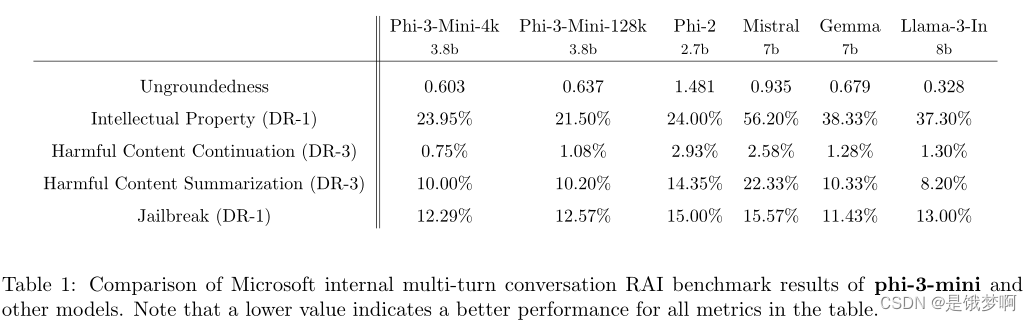
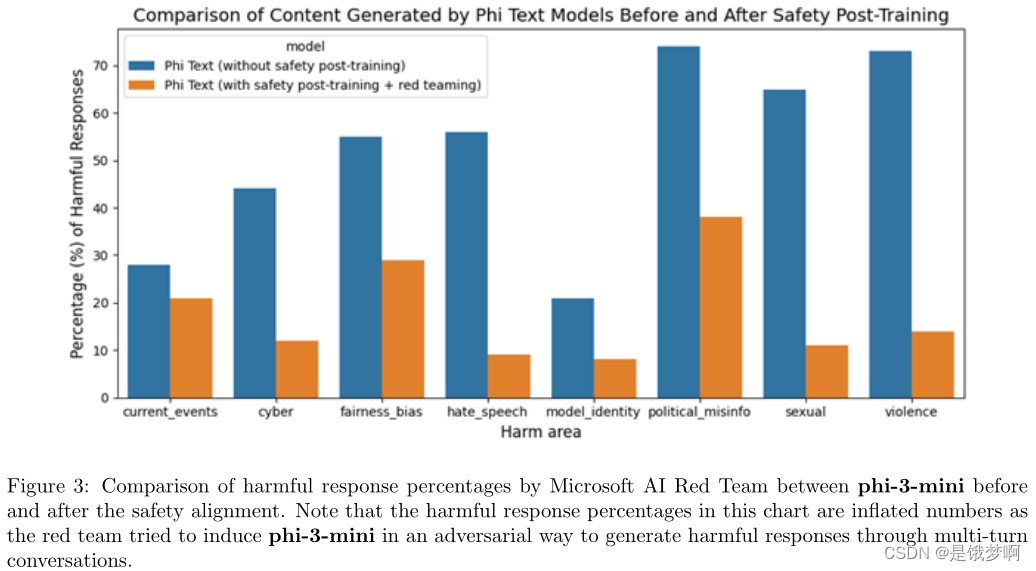
Weakness
就LLM功能而言,尽管phi-3-mini模型实现了与大得多的模型相似的语言理解和推理能力水平,但对于某些任务来说,它仍然受到其大小的根本限制。
该模型根本没有能力存储太多的“事实知识”,例如在TriviaQA上的低性能就可以看出这一点。然而,我们认为这种弱点可以通过增加搜索引擎来解决。下图中展示了一个使用HuggingFace默认聊天界面和phi-3-mini的例子。与模型能力相关的另一个弱点是我们主要将语言限制为英语。探索小语种模型的多语言功能是重要的下一步,通过包含更多多语言数据,phi-3-small取得了一些初步的有希望的结果。

尽管在RAI方面做出了不懈的努力,但与大多数LLM一样,在事实不准确(或幻觉)、偏见的再现或放大、不适当的内容生成和安全问题方面仍然存在挑战。使用精心策划的培训数据和有针对性的后期培训,以及来自 red-teaming 洞察的改进,可以从各个方面显著缓解这些问题。然而,要充分应对这些挑战,还有大量工作要做。