本次课程由书生·浦语社区贡献者【北辰】老师讲解【茴香豆:搭建你的 RAG 智能助理】课程。分别是:
- RAG 基础介绍
- 茴香豆产品简介
- 使用茴香豆搭建RAG知识库实战
课程视频:https://www.bilibili.com/video/BV1QA4m1F7t4/
课程文档:https://github.com/InternLM/Tutorial/blob/camp2/huixiangdou/readme.md
这节课布置如下作业:
基础作业:
1. 在茴香豆 Web 版中创建自己领域的知识问答助手
- 参考视频零编程玩转大模型,学习茴香豆部署群聊助手
- 完成不少于 400 字的笔记 + 线上茴香豆助手对话截图(不少于5轮)
- (可选)参考 代码 在自己的服务器部署茴香豆 Web 版
2.在 InternLM Studio 上部署茴香豆技术助手
- 根据教程文档搭建
茴香豆技术助手,针对问题"茴香豆怎么部署到微信群?"进行提问 - 完成不少于 400 字的笔记 + 截图
进阶作
A【应用方向】 结合自己擅长的领域知识(游戏、法律、电子等)、专业背景,搭建个人工作助手或者垂直领域问答助手,参考茴香豆官方文档,部署到下列任一平台。
- 飞书、微信
- 可以使用 茴香豆 Web 版 或 InternLM Studio 云端服务器部署
- 涵盖部署全过程的作业报告和个人助手问答截
B【算法方向】尝试修改 good_questions.json、调试 prompt 或应用其他 NLP 技术,如其他 chunk 方法,提高个人工作助手的表现。
- 完成不少于 400 字的笔记 ,记录自己的尝试和调试思路,涵盖全过程和改进效果截图
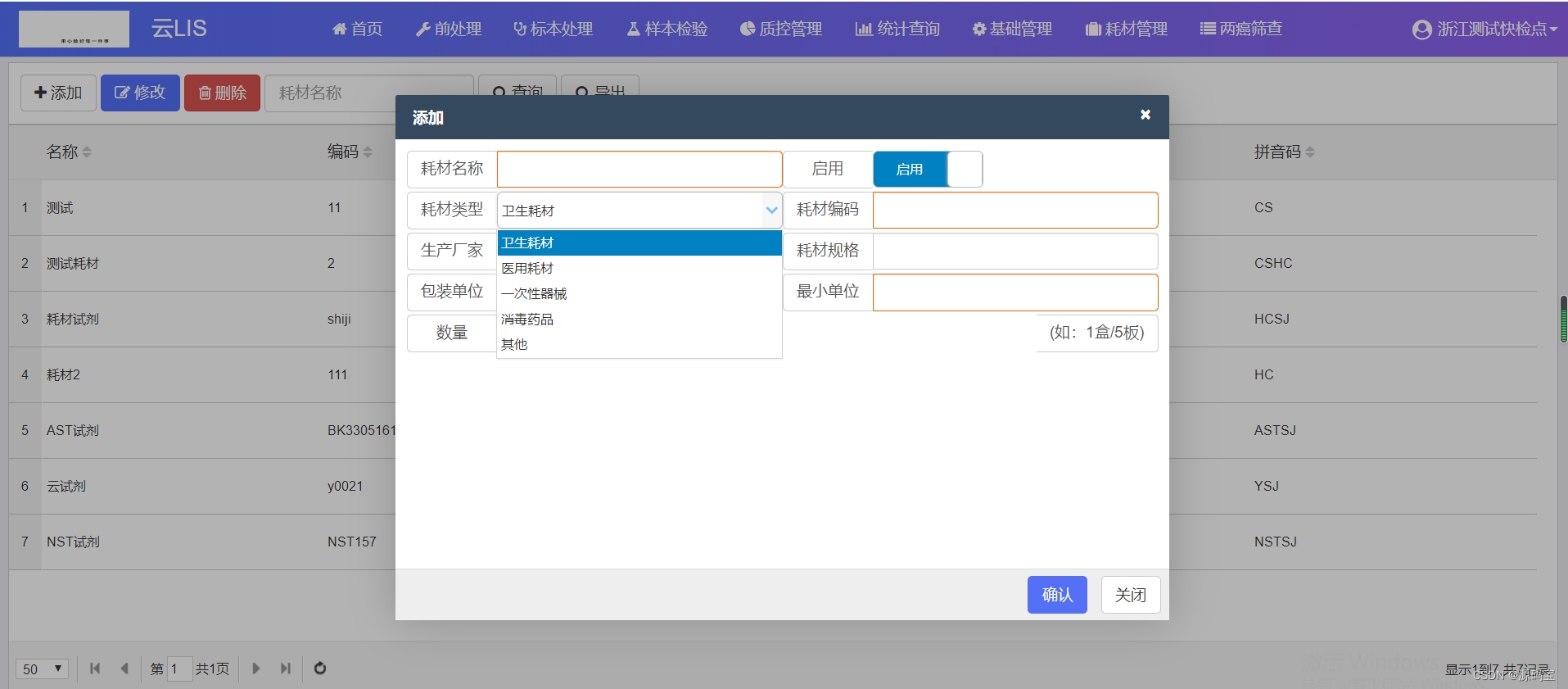
1. 在茴香豆 Web 版中创建自己领域的知识问答助手
1.1 给知识库名称取名为:大语言模型从理论到实践
1.2 从本地上传大规模语言模型 从理论到实践.pdf
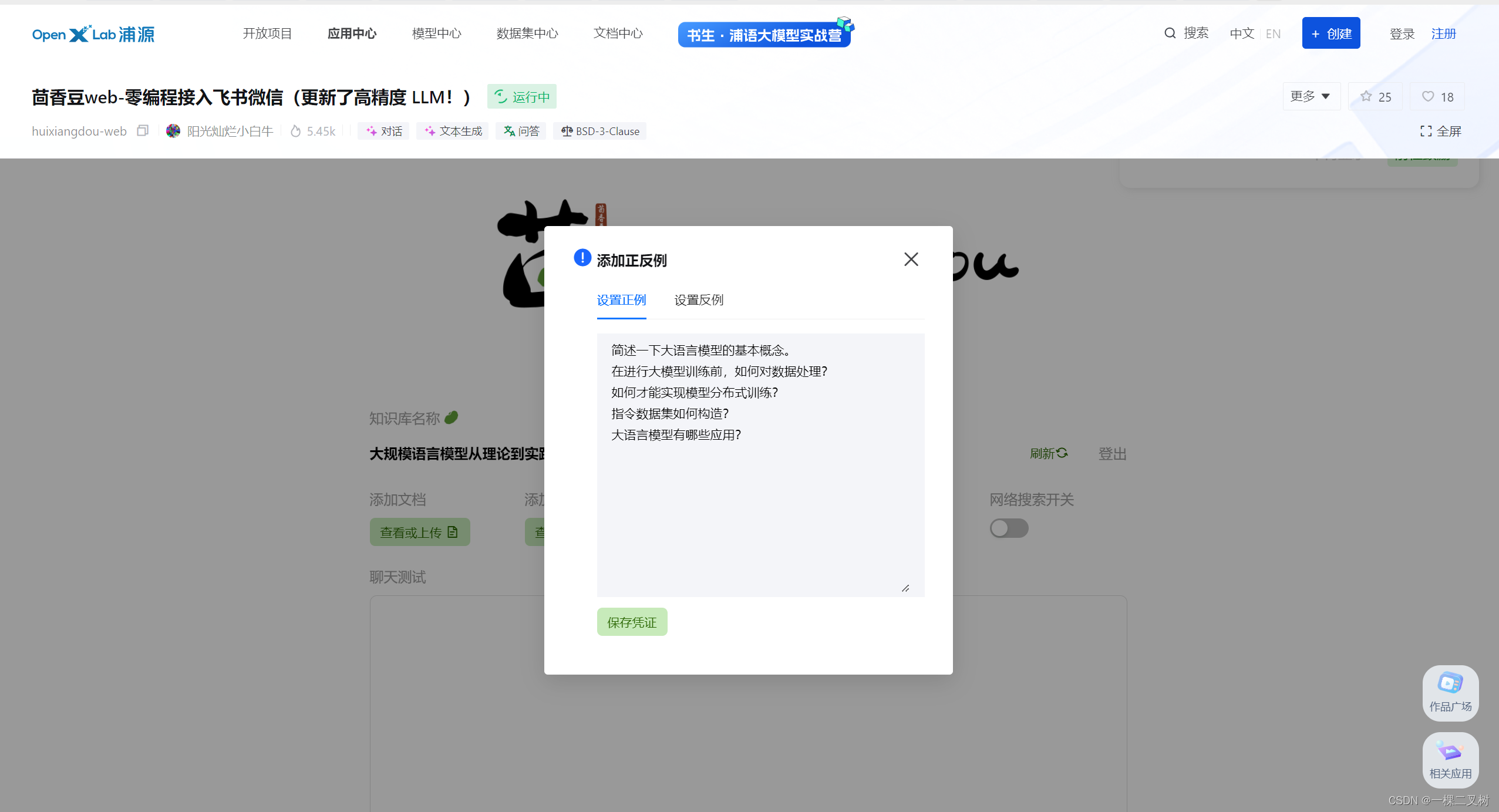
1.3 设置正反例
1.4 茴香豆助手对话
2. 在 InternLM Studio 上部署茴香豆技术助手
2.1 配置基础环境
2.2 下载相关模型
2.2 下载安装茴香豆所需要的环境包
2.3 下载茴香豆代码仓库
2.4 修改配置文件
2.5 创建知识库
2.6 运行茴香豆知识助手
给知识库名称取名为:大语言模型从理论到实践
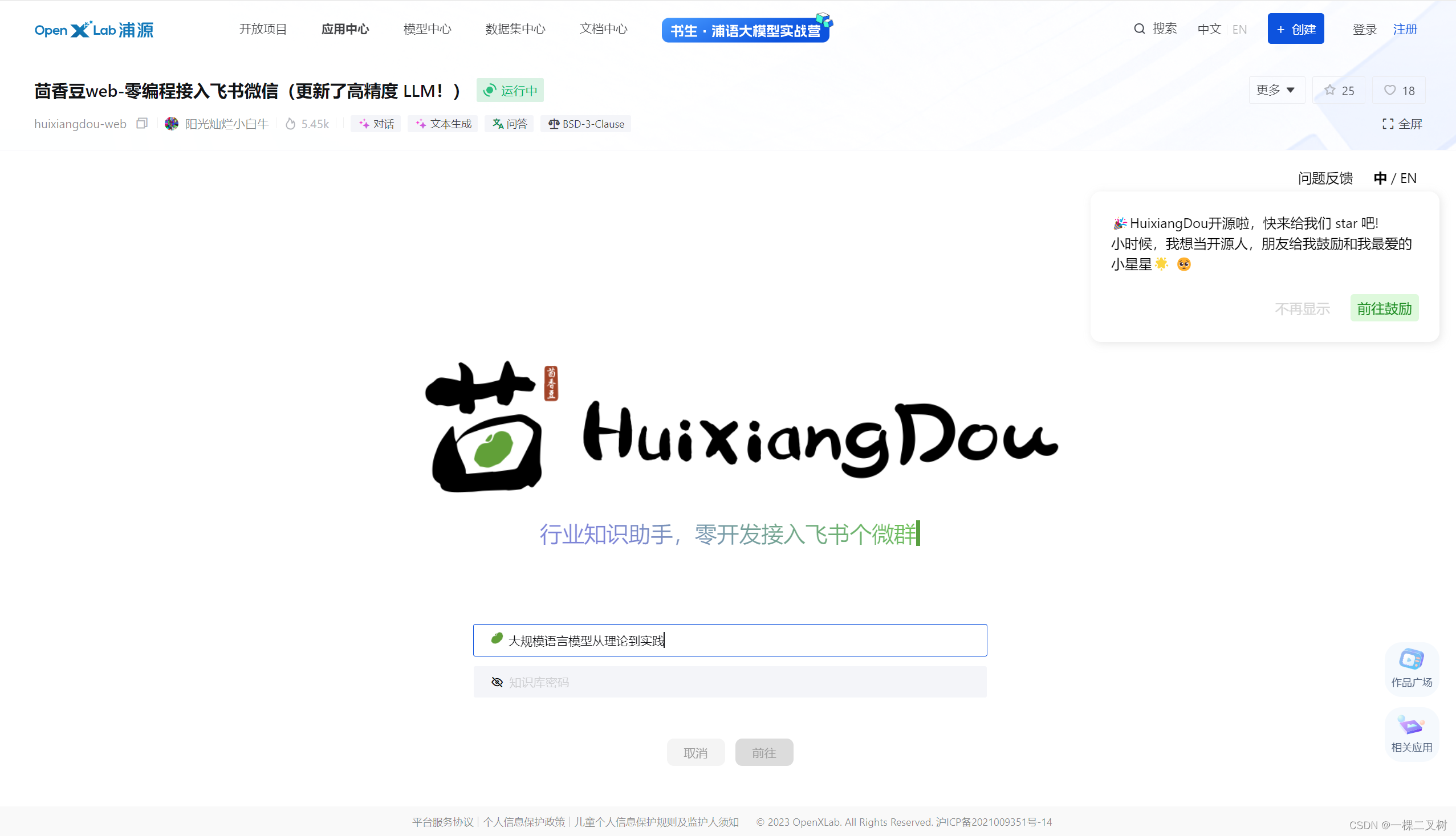 1.2 从本地上传大规模语言模型 从理论到实践.pdf
1.2 从本地上传大规模语言模型 从理论到实践.pdf
 1.3 设置正反例
1.3 设置正反例
 1.4 茴香豆助手对话
1.4 茴香豆助手对话
第一轮:简述一下大语言模型的基本概念。

第二轮: 今天天气真好,我们去公园散步吧?顺便去超市买点东西,你有什么需要的吗?
第三轮:在进行大模型训练前,如何对数据处理?

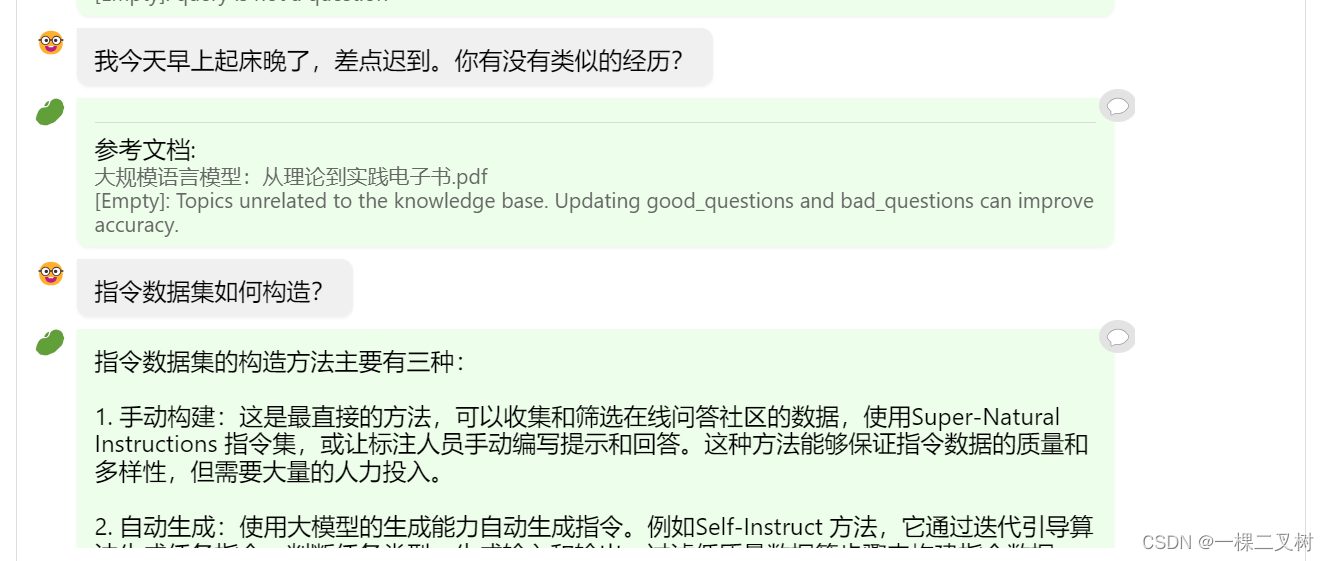
第四轮: 我今天早上起床晚了,差点迟到。你有没有类似的经历?
第五轮:指令数据集如何构造?
第六轮:如何才能实现模型分布式训练?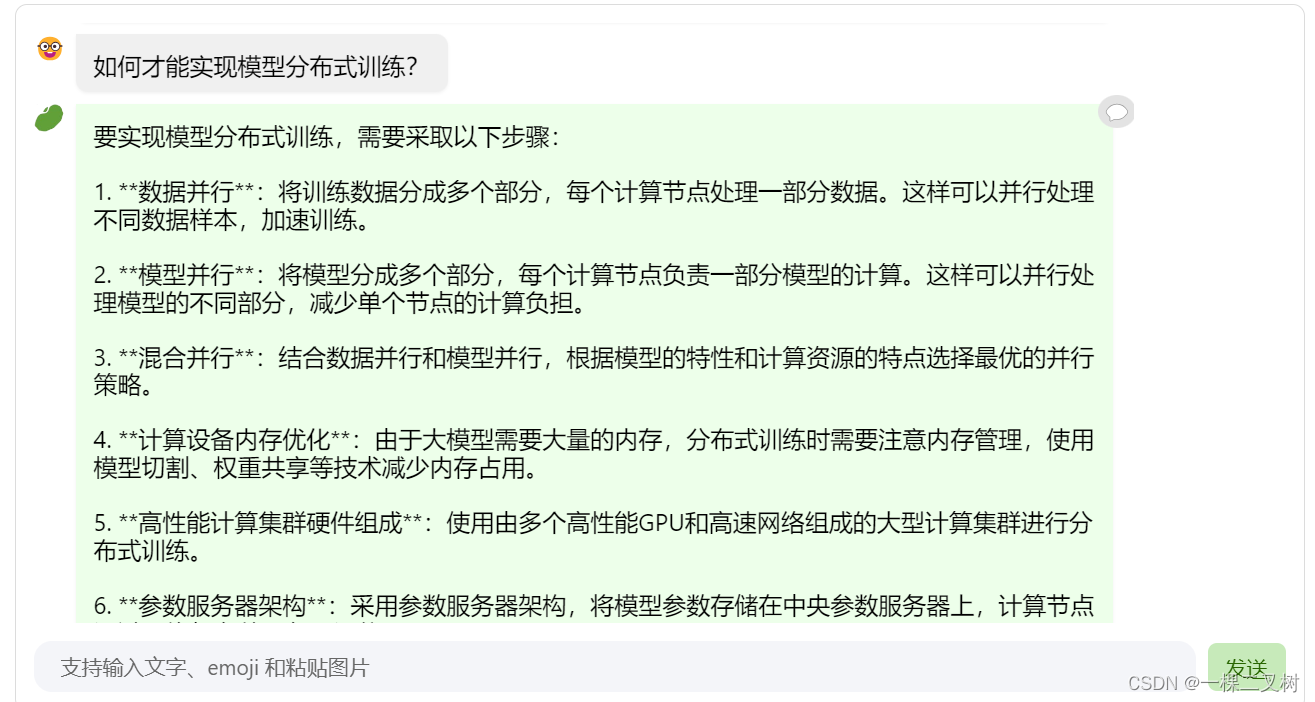
第七轮:大语言模型有哪些应用?
 总结:茴香豆对于用户问题理解非常彻底,对于正例问题,它可以从长文本中快速定位答案所在的段落,然后结合问题加上索引出的知识,进行知识问答。对于反例问题,它会拒绝回答。
总结:茴香豆对于用户问题理解非常彻底,对于正例问题,它可以从长文本中快速定位答案所在的段落,然后结合问题加上索引出的知识,进行知识问答。对于反例问题,它会拒绝回答。
2. 在 InternLM Studio 上部署茴香豆技术助手
2.1 配置基础环境
使用 Cuda11.7-conda 镜像,在资源配置中,使用 30% A100 * 1
从官方环境复制运行 InternLM 的基础环境,命名为 InternLM2_Huixiangdou
studio-conda -o internlm-base -t InternLM2_Huixiangdou

 激活
激活 InternLM2_Huixiangdou python 虚拟环境
conda activate InternLM2_Huixiangdou
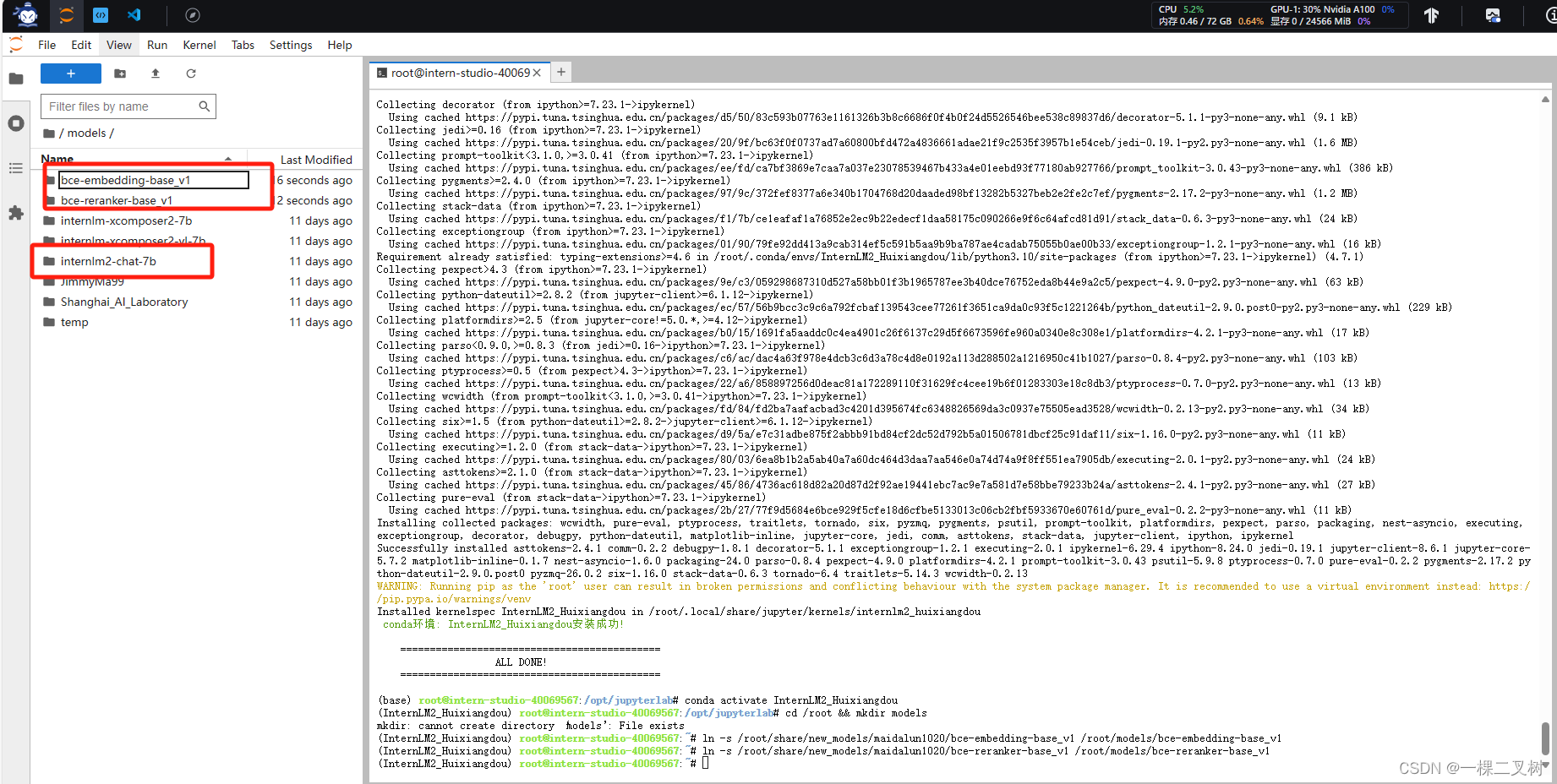
 2.2 下载相关模型
2.2 下载相关模型
# 创建模型文件夹
cd /root && mkdir models# 复制BCE模型
ln -s /root/share/new_models/maidalun1020/bce-embedding-base_v1 /root/models/bce-embedding-base_v1
ln -s /root/share/new_models/maidalun1020/bce-reranker-base_v1 /root/models/bce-reranker-base_v1# 复制大模型参数(下面的模型,根据作业进度和任务进行**选择一个**就行)
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b /root/models/internlm2-chat-7b
 2.2 下载安装茴香豆所需要的环境包
2.2 下载安装茴香豆所需要的环境包
pip install protobuf==4.25.3 accelerate==0.28.0 aiohttp==3.9.3 auto-gptq==0.7.1 bcembedding==0.1.3 beautifulsoup4==4.8.2 einops==0.7.0 faiss-gpu==1.7.2 langchain==0.1.14 loguru==0.7.2 lxml_html_clean==0.1.0 openai==1.16.1 openpyxl==3.1.2 pandas==2.2.1 pydantic==2.6.4 pymupdf==1.24.1 python-docx==1.1.0 pytoml==0.1.21 readability-lxml==0.8.1 redis==5.0.3 requests==2.31.0 scikit-learn==1.4.1.post1 sentence_transformers==2.2.2 textract==1.6.5 tiktoken==0.6.0 transformers==4.39.3 transformers_stream_generator==0.0.5 unstructured==0.11.2 2.3 下载茴香豆代码仓库
2.3 下载茴香豆代码仓库
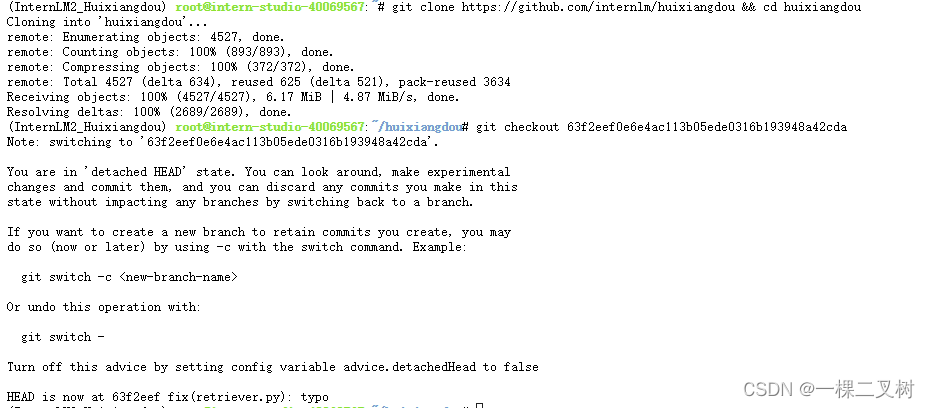
cd /root
# 克隆代码仓库
git clone https://github.com/internlm/huixiangdou && cd huixiangdou
git checkout 63f2eef0e6e4ac113b05ede0316b193948a42cda
 2.4 修改配置文件
2.4 修改配置文件
sed -i '6s#.*#embedding_model_path = "/root/models/bce-embedding-base_v1"#' /root/huixiangdou/config.ini
sed -i '7s#.*#reranker_model_path = "/root/models/bce-reranker-base_v1"#' /root/huixiangdou/config.ini
sed -i '29s#.*#local_llm_path = "/root/models/internlm2-chat-7b"#' /root/huixiangdou/config.ini

2.5 创建知识库
下载 Huixiangdou 语料
cd /root/huixiangdou && mkdir repodirgit clone https://github.com/internlm/huixiangdou --depth=1 repodir/huixiangdou
 增加茴香豆相关的问题到接受问题示例
增加茴香豆相关的问题到接受问题示例
cd /root/huixiangdou
mv resource/good_questions.json resource/good_questions_bk.jsonecho '["mmpose中怎么调用mmyolo接口","mmpose实现姿态估计后怎么实现行为识别","mmpose执行提取关键点命令不是分为两步吗,一步是目标检测,另一步是关键点提取,我现在目标检测这部分的代码是demo/topdown_demo_with_mmdet.py demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth 现在我想把这个mmdet的checkpoints换位yolo的,那么应该怎么操作","在mmdetection中,如何同时加载两个数据集,两个dataloader","如何将mmdetection2.28.2的retinanet配置文件改为单尺度的呢?","1.MMPose_Tutorial.ipynb、inferencer_demo.py、image_demo.py、bottomup_demo.py、body3d_pose_lifter_demo.py这几个文件和topdown_demo_with_mmdet.py的区别是什么,\n2.我如果要使用mmdet是不是就只能使用topdown_demo_with_mmdet.py文件,","mmpose 测试 map 一直是 0 怎么办?","如何使用mmpose检测人体关键点?","我使用的数据集是labelme标注的,我想知道mmpose的数据集都是什么样式的,全都是单目标的数据集标注,还是里边也有多目标然后进行标注","如何生成openmmpose的c++推理脚本","mmpose","mmpose的目标检测阶段调用的模型,一定要是demo文件夹下的文件吗,有没有其他路径下的文件","mmpose可以实现行为识别吗,如果要实现的话应该怎么做","我在mmyolo的v0.6.0 (15/8/2023)更新日志里看到了他新增了支持基于 MMPose 的 YOLOX-Pose,我现在是不是只需要在mmpose/project/yolox-Pose内做出一些设置就可以,换掉demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py 改用mmyolo来进行目标检测了","mac m1从源码安装的mmpose是x86_64的","想请教一下mmpose有没有提供可以读取外接摄像头,做3d姿态并达到实时的项目呀?","huixiangdou 是什么?","使用科研仪器需要注意什么?","huixiangdou 是什么?","茴香豆 是什么?","茴香豆 能部署到微信吗?","茴香豆 怎么应用到飞书","茴香豆 能部署到微信群吗?","茴香豆 怎么应用到飞书群","huixiangdou 能部署到微信吗?","huixiangdou 怎么应用到飞书","huixiangdou 能部署到微信群吗?","huixiangdou 怎么应用到飞书群","huixiangdou","茴香豆","茴香豆 有哪些应用场景","huixiangdou 有什么用","huixiangdou 的优势有哪些?","茴香豆 已经应用的场景","huixiangdou 已经应用的场景","huixiangdou 怎么安装","茴香豆 怎么安装","茴香豆 最新版本是什么","茴香豆 支持哪些大模型","茴香豆 支持哪些通讯软件","config.ini 文件怎么配置","remote_llm_model 可以填哪些模型?"
]' > /root/huixiangdou/resource/good_questions.json
 再创建一个测试用的问询列表,用来测试拒答流程是否起效:
再创建一个测试用的问询列表,用来测试拒答流程是否起效:
cd /root/huixiangdouecho '[
"huixiangdou 是什么?",
"你好,介绍下自己"
]' > ./test_queries.json
 创建 RAG 检索过程中使用的向量数据库
创建 RAG 检索过程中使用的向量数据库
# 创建向量数据库存储目录
cd /root/huixiangdou && mkdir workdir # 分别向量化知识语料、接受问题和拒绝问题中后保存到 workdir
python3 -m huixiangdou.service.feature_store --sample ./test_queries.json
 2.6 运行茴香豆知识助手
2.6 运行茴香豆知识助手
填入问题,运行茴香豆
# 填入问题
sed -i '74s/.*/ queries = ["huixiangdou 是什么?", "茴香豆怎么部署到微信群", "今天天气怎么样?"]/' /root/huixiangdou/huixiangdou/main.py# 运行茴香豆
cd /root/huixiangdou/
python3 -m huixiangdou.main --standalone

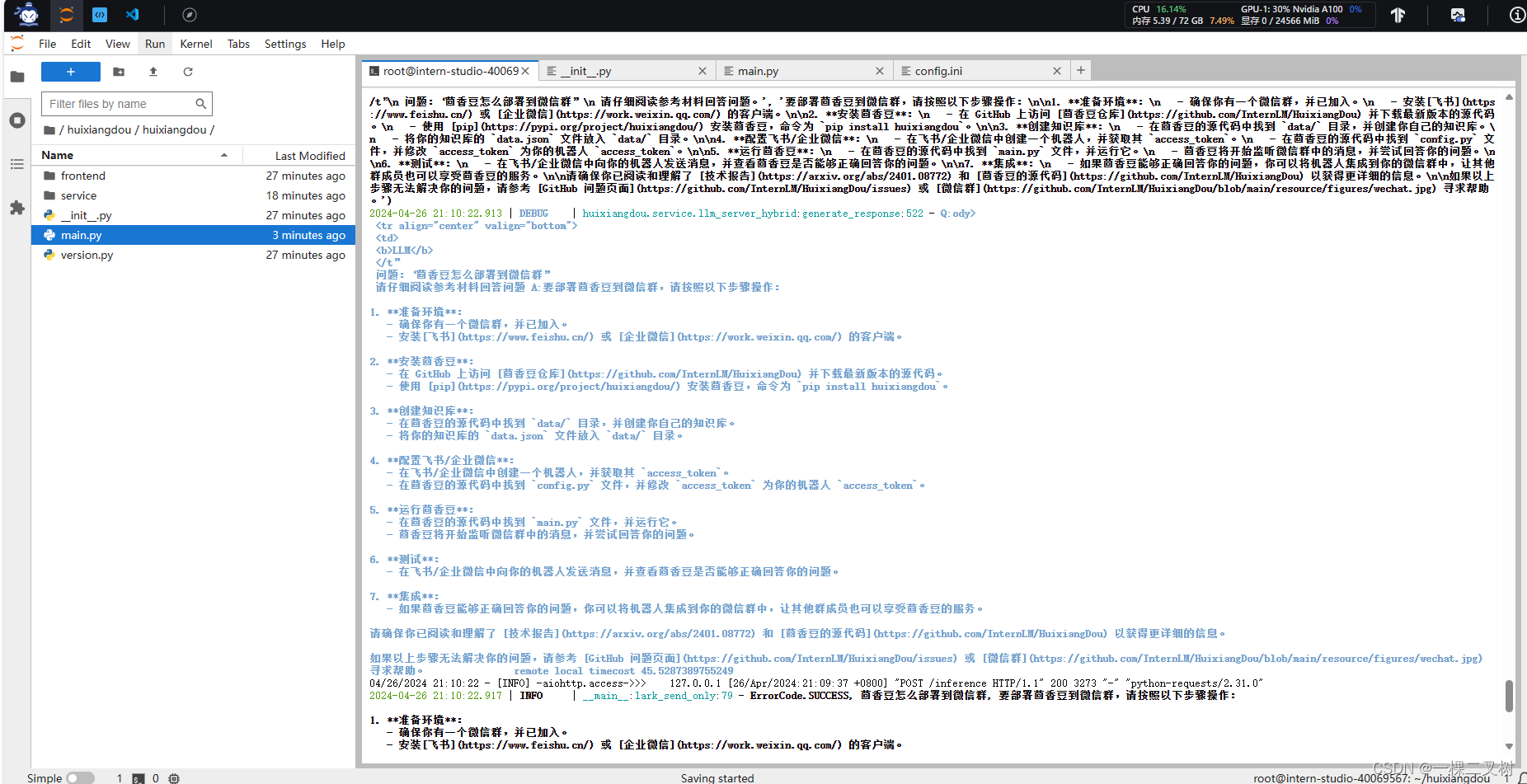
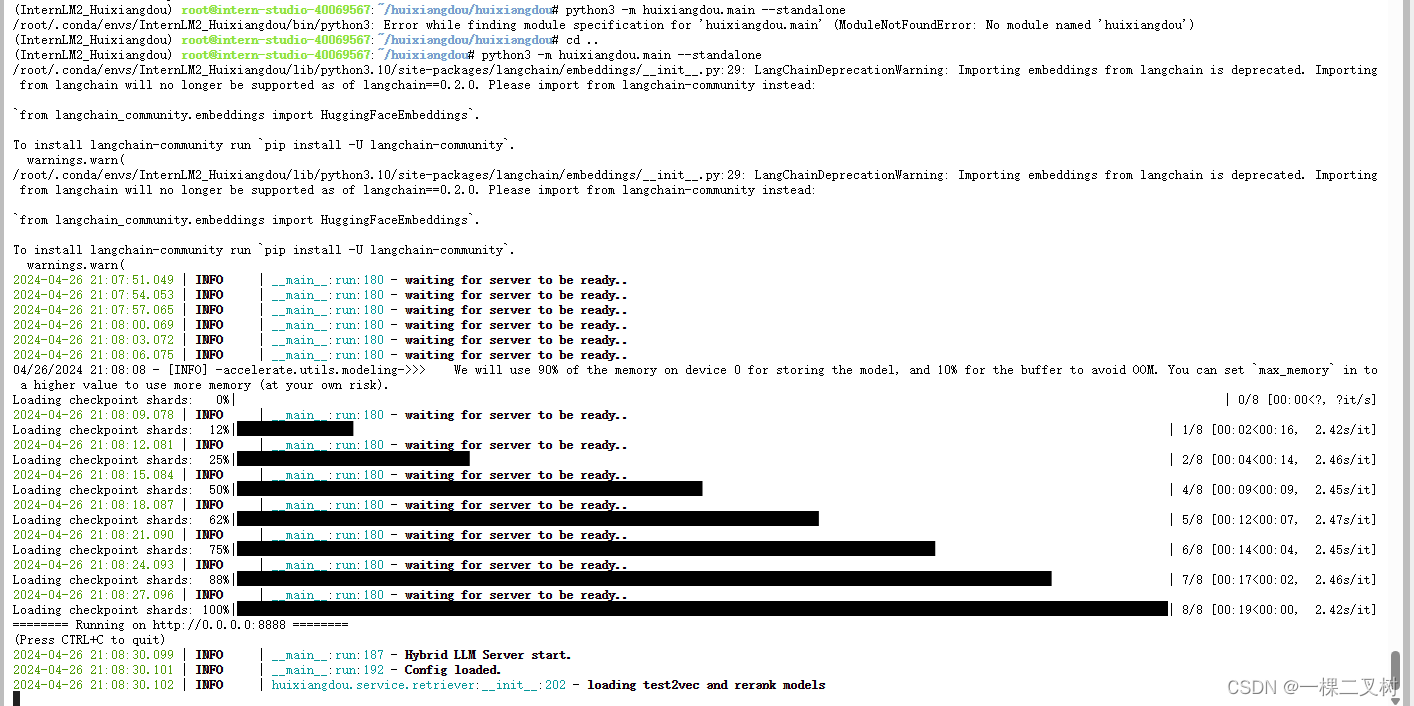 茴香豆技术助理对“茴香豆怎么部署到微信群”回答的结果
茴香豆技术助理对“茴香豆怎么部署到微信群”回答的结果