一、数据库操作
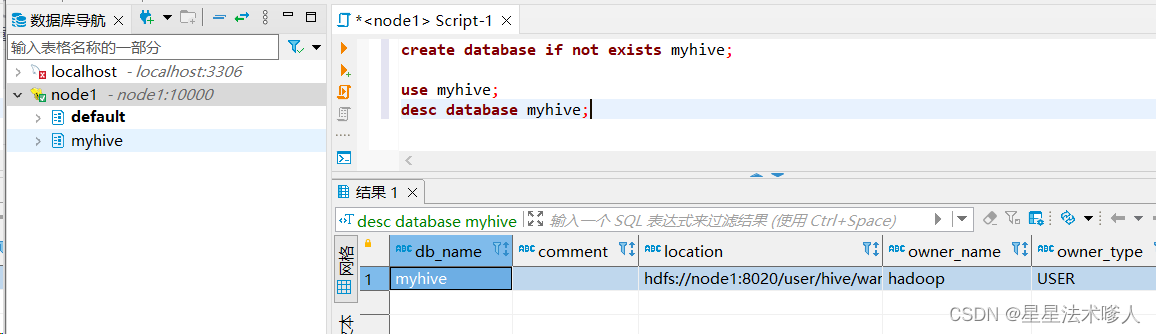
- 创建数据库
create database if not exists myhive;
- 使用数据库
use myhive;
- 查看数据库详细信息
desc database myhive;
数据库本质上就是在HDFS之上的文件夹。
默认数据库的存放路径是HDFS的:/user/hive/warehouse内
- 创建数据库并指定hdfs存储位置
create database myhive2 location '/myhive2';
使用location关键字,可以指定数据库在HDFS的存储路径
- 删除一个空数据库,如果数据库下面有数据表,那么就会报错
drop database myhive;
- 强制删除数据库,包含数据库下面的表一起删除
drop database myhive2 cascade;
二、数据表操作
2.1、数据导入(数据加载)
- 方式一:从文件向表加载数据
load data [local] inpath 'path' [overwrite] into table tablename;
----如果数据在hdfs,那么源文件会消失(本质上走的mv移动)
----如果数据在本地,需要带local,如果在hdfs就不用带了
----这个加载方式不会走MapReduce,小文件加载数据快
- 方式二:从表向其他表加载数据
insert into | overwrite table tablename select .......;
2.2、数据导出
- 方式一:通过insert overwrite 语句
insert overwrite [local] directory 'path'
[row format delimited fields terminated by ''] -----自定义列分隔符
select .....;
----带local,写入本地
----不带local,写入hdfs
方式二:
# -e 直接执行sql语句,将结果通过linux的重定向符号写入到指定文件中
bin/hive -e "sql语句"> result.txt
# -f 直接执行sql脚本,将结果通过linux的重定向符号写入到指定文件中
bin/hive -e "sql脚本文件"> result.txt
2.3、分区表
在大数据中,最常用的一种思想就是分治,我们可以把大的文件分割成一个个小的文件,这样每次操作一个小的文件就会很容易了。同样的道理,在hive当中也是支持这种思想,就是我们可以把大的数据,按照每天或者每小时进行切分成一个个的小文件,这样去操作小的文件就会容易得多。
- 创建分区表
- 单分区

- 多分区

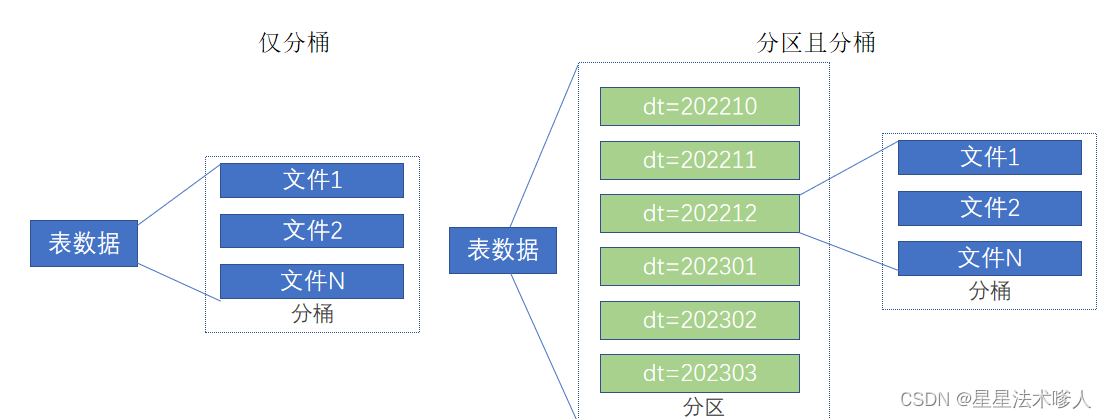
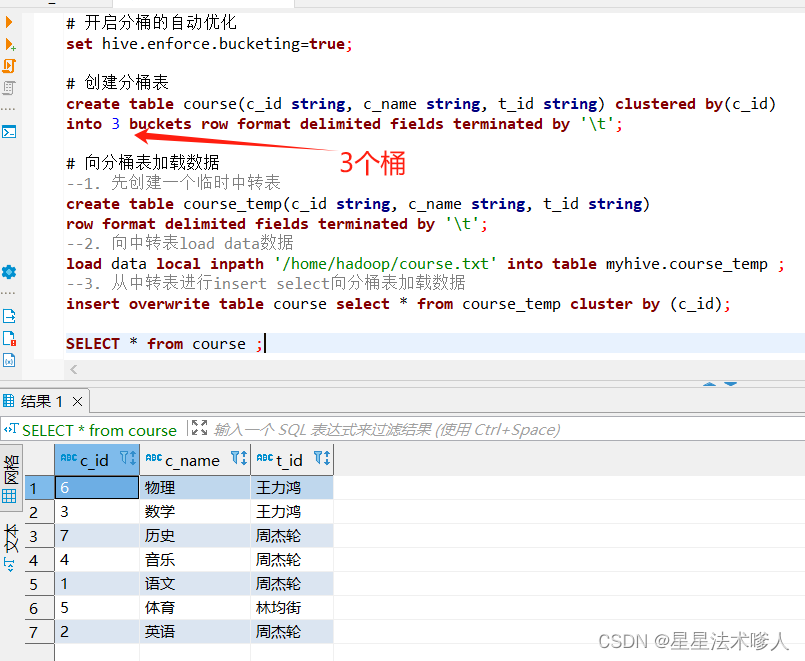
2.4、分桶表
分桶和分区一样,也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式。
但和分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储。