文章目录
- 一、 三级缓存的概述
- 二、 三级缓存的实现原理
- 2.1 创建Bean流程图
- 2.2 getBean()
- 2.3 doGetBean()
- 2.4 createBean()
- 2.5 doCreateBean()
- 2.4 getSingleton()
- 三、 三级缓存的使用场景与注意事项
- 3.1 在实际开发中如何使用三级缓存
- 3.2 三级缓存可能出现的问题及解决方法
一、 三级缓存的概述
概念:
三级缓存是指用于管理 Bean 对象创建过程中不同阶段的缓存机制。
- 一级缓存(singletonObjects):存储已经完全初始化的单例 Bean 对象。
- 二级缓存(earlySingletonObjects):存储已经实例化但尚未完全初始化的单例 Bean 对象。
- 三级缓存(singletonFactories):存储 Bean 对象的创建工厂,用于在创建过程中检测循环依赖。
意义:
- 提高性能: 通过缓存已经创建的 Bean 对象,Spring 可以在后续的请求中直接返回缓存的对象,避免重复创建,从而提高了系统的性能和响应速度。
- 解决循环依赖: 三级缓存中的三级缓存(singletonFactories)用于解决循环依赖问题。当 A Bean 依赖于 B Bean,而 B Bean 又依赖于 A Bean 时,Spring 可以在创建 A Bean 的过程中将其提前放入三级缓存,以解决循环依赖的问题。
- 实现懒加载: 二级缓存(earlySingletonObjects)可以实现 Bean 的懒加载,即在 Bean 第一次被请求时才进行初始化,而不是在容器启动时就立即创建所有的 Bean 对象。
- 保证单例: 通过一级缓存(singletonObjects)中存储的已初始化的单例 Bean 对象,Spring 可以保证在应用程序中只存在一个实例,实现了单例模式的效果。
二、 三级缓存的实现原理
由于创建Bean的代码量非常多,本文仅展示与三级缓存有关的代码。
读者想要对三级缓存了解更加深刻,可以自行创建循环依赖的Bean,根据调试来解读代码。
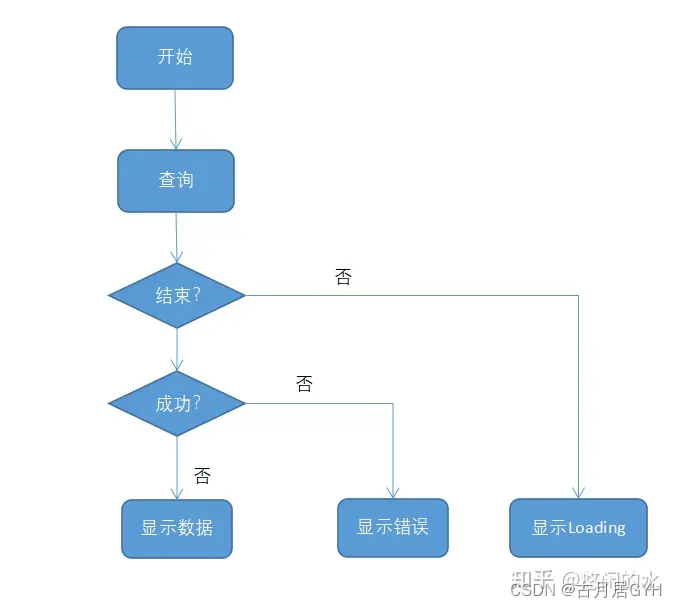
2.1 创建Bean流程图
这里仅仅展示创建Bean的大致流程图,想深入了解的读者可以自行解读源码。

2.2 getBean()

2.3 doGetBean()


2.4 createBean()

2.5 doCreateBean()


2.4 getSingleton()


三、 三级缓存的使用场景与注意事项
3.1 在实际开发中如何使用三级缓存
在实际开发中,我们通常不需要直接操作 Spring 的三级缓存,因为 Spring 框架会自动管理这些缓存。只需要通过合适的配置和编码实践来确保 bean 的正确创建和管理即可。
在实际开发中使用 Spring 的三级缓存简单Demo:
假设有一个简单的服务接口 UserService 和其实现类 UserServiceImpl,将使用 Spring 来管理它们的依赖注入和单例管理。
public interface UserService {void addUser(String username);
}public class UserServiceImpl implements UserService {private List<String> users = new ArrayList<>();@Overridepublic void addUser(String username) {users.add(username);}
}
现在配置 Spring 容器并将 UserServiceImpl 注入到容器中:
/*
* 定义了一个配置类 AppConfig,在其中通过 @Bean 注解定义了一个名为 userService 的 Bean,并指定了它的实现类为 UserServiceImpl
*/
@Configuration
@ComponentScan(basePackages = "com.example")
public class AppConfig {@Beanpublic UserService userService() {return new UserServiceImpl();}
}public class Main {public static void main(String[] args) {AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);// Spring 默认情况下会使用单例模式管理 Bean,所以每次获取 UserService Bean 都会得到同一个实例// 从 Spring 应用上下文中获取一个名为 userService 的 Bean,其类型为 UserService。在 AppConfig 中定义了 userService Bean,并且它的实现类为 UserServiceImpl,所以这里实际上是获取了一个 UserServiceImpl 类型的对象UserService userService1 = context.getBean(UserService.class);userService1.addUser("Alice");// 再次从 Spring 应用上下文中获取一个 UserService 类型的 Bean,实际上是获取了之前已经创建过的同一个 UserServiceImpl 类型的对象UserService userService2 = context.getBean(UserService.class);userService2.addUser("Bob");// 可给对象做一些其它额外的操作// 关闭了 Spring 应用上下文,释放资源context.close();}
}
分析 Spring 是如何使用三级缓存的:
- BeanDefinition 缓存: 在 Spring 容器启动时,Spring 会解析所有的 bean 定义(BeanDefinition),并将其缓存起来。这个缓存存储了 bean 的元数据信息,如类名、依赖关系等。当我们通过
@Bean或者其他方式声明一个 bean 时,Spring 首先会检查 BeanDefinition 缓存中是否存在该 bean 的定义,如果存在,则直接使用该定义,否则会根据配置信息创建一个新的 BeanDefinition。 - 单例对象实例缓存: 当我们通过 Spring 容器获取一个单例 bean 时,Spring 首先会检查单例对象实例缓存中是否已经存在该 bean 的实例。如果存在,则直接返回缓存中的实例,否则会根据 BeanDefinition 中的信息创建一个新的 bean 实例,并放入缓存中。
- 早期的单例对象实例缓存: 在 bean 的创建过程中,Spring 可能需要解决循环依赖等问题。为了解决这些问题,Spring 使用了早期的单例对象实例缓存。当 bean 的创建过程中遇到循环依赖时,Spring 会将正在创建的 bean 提前暴露给其他需要它的 bean,从而解决循环依赖的问题。
3.2 三级缓存可能出现的问题及解决方法
在 Spring 中,虽然没有官方定义的 “三级缓存” 概念,但可以类比于 MyBatis 中的缓存机制。
从 Spring 的缓存相关模块(如 Spring Cache)的角度来看,也存在一些可能的问题以及解决方法。
- 缓存数据不一致性问题:
- 问题:当使用 Spring Cache 缓存方法的返回结果时,如果在缓存数据过期前发生了数据变更(如数据库更新),则缓存中的数据与实际数据不一致。
- 解决方法:
- 手动清除缓存:在数据变更操作后,手动清除相应的缓存,保持缓存与数据库数据的一致性。
- 使用缓存刷新策略:在 Spring Cache 中,可以通过配置缓存刷新策略,定期或在特定触发条件下刷新缓存,使缓存中的数据保持最新。
- 缓存击穿问题:
- 问题:当某个缓存项过期时,同时有大量并发请求访问该缓存项,可能导致大量请求直接访问底层数据源(如数据库),增加系统负载。
- 解决方法:
- 设置合适的缓存过期时间:根据业务场景和系统负载情况,设置合适的缓存过期时间,避免大量缓存同时失效。
- 使用互斥锁机制:在缓存项失效时,使用互斥锁机制保证只有一个线程能够重新加载缓存项,其他线程等待该线程加载完数据后再从缓存中获取。
- 缓存雪崩问题:
- 问题:当大量缓存项同时失效时,可能导致大量请求直接访问底层数据源,从而造成系统压力过大。
- 解决方法:
- 使用分布式缓存:如果系统是分布式的,考虑使用分布式缓存技术,将缓存分布在多个节点上,避免单点故障。
- 设置随机过期时间:在设置缓存过期时间时,可以稍微随机一些,避免大量缓存同时失效。
- 使用熔断机制:当系统压力过大时,可以使用熔断机制暂时关闭对底层数据源的访问,避免系统崩溃。
今是生活,今是动力,今是行为,今是创作