平台
依赖
linux
docker
docker-compose 或者 docker compose
镜像
docker.elastic.co/beats/filebeat:8.12.2
docker.elastic.co/beats/kibana:8.12.2
docker.elastic.co/beats/elasticsearch:8.12.2
正文
背景
对于有自建机房的公司来说,如果公司的运维技术能力不是很强,那么通过docker部署内部服务自然成了首选(其实K8S搭建的服务依然会遇到这个问题,部署方式于此基本相同,主要是filebeat的元数据处理器从add_docker_metadata修改为add_kubernetes_metadata)。
同时,很多服务需要保证一定的可用性,也就需要多实例加滚动更新,在这种情况下自然需要在不同机器上部署实例。
当生产服务出现问题时,想查看日志就必须要登录对应的服务器去挨个查看,运气不好要看完所有实例才能找到,十分痛苦。
所以希望有个统一的日志平台收集分散在各个服务器上的日志,做集中查询,自然地ELK三剑客(众所周知,3剑客有4个,还有filebeat)就成了我们的首选。
技术原理
通过docker启动的服务,其日志会保存在 /var/lib/docker/containers目录下,并以容器ID生成子目录,保存容器的配置、日志等

查看完整的容器ID

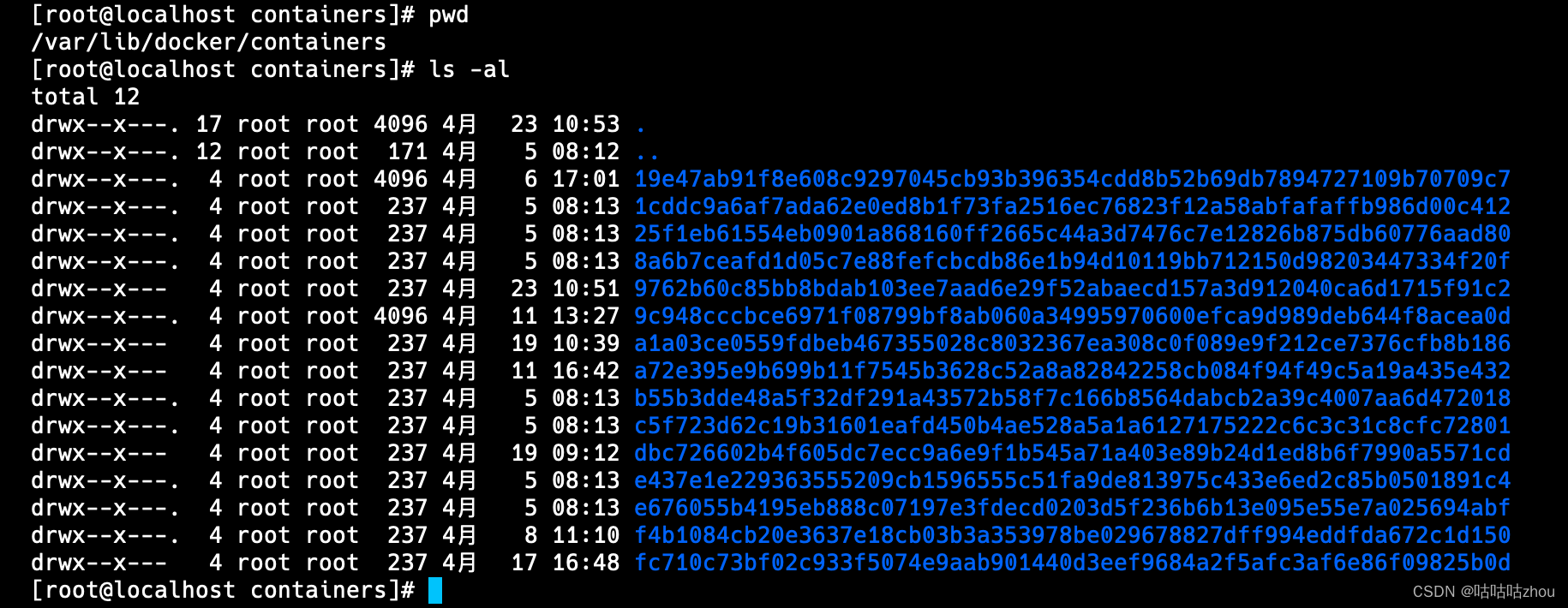
平时通过docker logs -f {容器ID}读取的就是保存在上述目录下的日志文件,因为docker以json格式保存日志,所以日志文件为 容器ID-json.log
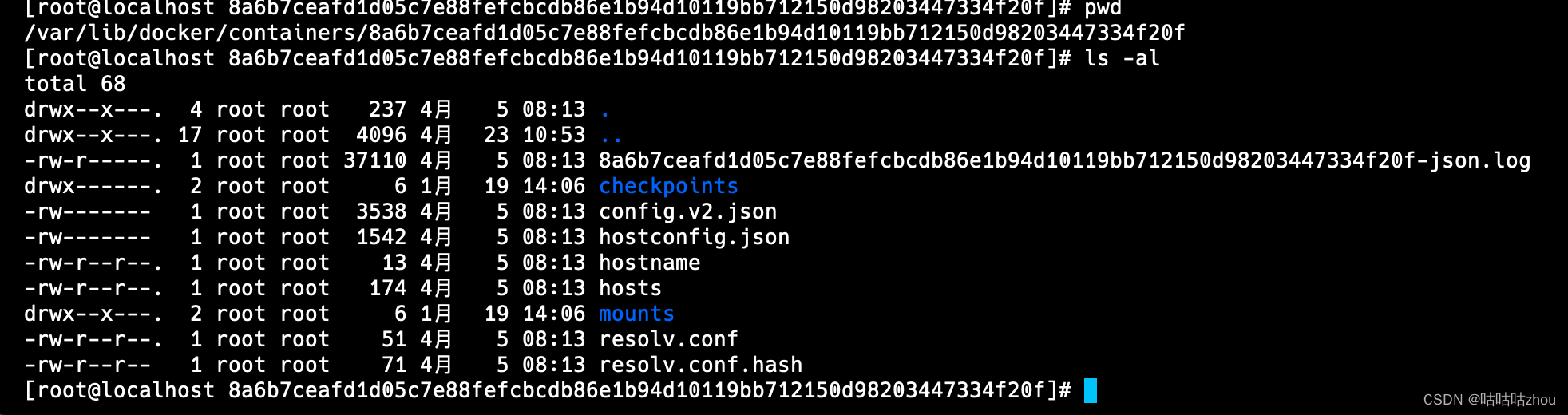
至此,我们有了 服务 -> 容器实例 -> 服务日志 这样的映射关系。
但是依然不太方便,需要额外自主处理服务到容器实例日志的映射。
对于这样常用场景,filebeat官方为我们提供的docker元数据处理器处理
filebeat的docker元数据处理器
我们只需要添加docker.sock这个与docker通信的套接字,filebeat就能从中获取docker启用的服务列表等元数据。
/var/run/docker.sock
When running Filebeat in a container, you need to provide access to Docker’s unix socket in order for the add_docker_metadata processor to work. You can do this by mounting the socket inside the container. For example:
之后,再借助filebeat提供的自定义处理功能,提取服务名,再把对应日志上传到各自服务名的日志即可。
至于是否需要logstash,至少以我们当前的需求来说不需要logstash在进行额外处理,已经基本满足。
由于篇幅有限,这里就不再复述如何部署es和kibana了。
部署filebeat
- 编写filebeat的部署文件
docker-compose.yml
version: "3"services:filebeat:image: 'docker.elastic.co/beats/filebeat:8.12.2'container_name: filebeatrestart: alwaysuser: "root"volumes:# docker容器日志- /var/lib/docker/containers:/var/lib/docker/containers:ro# docker 进程通信socket- /var/run/docker.sock:/var/run/docker.sock:ro# 时区 保证容器与宿主机的时区统一- /etc/localtime:/etc/localtime:ro# filebeat运行使用的配置文件 请根据实际情况调整- /code/filebeat/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro# filebeat运行时记录的元数据- /code/filebeat/data:/usr/share/filebeat/data:rw# filebeat运行时的日志- /code/filebeat/logs:/usr/share/filebeat/logs:rwcommand:- filebeatdeploy: # 资源限制resources:limits:# filebeat 是轻量级的日志收集程序,所需资源比较少cpus: '0.3'memory: 256M
- filebeat的配置文件
filebeat.yml
filebeat.inputs:- type: containerenabled: truestream: allformat: dockerpaths:# 处理空间下的日志 支持一定的通配符,k8s环境下会包含空间前缀,可以在此处过滤掉- "/var/lib/docker/containers/*/*.log"fields:multiline:# 做多行日志聚合,此处是针对java的异常堆栈信息聚合(所有非年-月-日开头的日志会被聚合到最开始匹配到的那一行展示)type: patternpattern: '^\d+.\d+.\d+|^\d+.\w{3}.\d+'negate: truematch: afterprocessors:- add_docker_metadata:host: "unix:///var/run/docker.sock"# 去掉不需要的字段- drop_fields:ignore_missing: true # 字段不存在时不报错fields: - agent.type.keyword- agent.type- agent.name- agent.id.keyword- agent.id- host.name- host.name.keyword- script:# 增加js脚本,处理服务名称 此处我是通过获取事件中的镜像名称,切割出我需要的部分作为后续的服务名添加到事件servcie字段中lang: javascripttimeout: 100source: > function process(event) { var s = event.Get('container.image.name');if (!s) {return event;}var sp = s.lastIndexOf('/');sp = sp < 0 ? 0 : sp + 1;var ep = s.indexOf(':');if (ep < 0) {event.Put('service', s.substring(sp));}event.Put('service', s.substring(sp, ep));}- drop_event:# 不采集下面服务的日志事件when: or:- contains:service: 'filebeat'- contains: service: 'grafana'- contains: service: 'logstash'
output.elasticsearch:# es服务的地址hosts: ["https://192.168.224.170:9200"]# es用户名username: elastic# es密码password: ""# 传输压缩级别compression_leveledit: 4ssl:# 不验证ssl证书verification_mode: noneindices:# service会作为上报的日志文件的名字参与进去- index: "host-log-%{[service]}-%{+yyyy.MM.dd}"when.has_fields:- service- index: "host-log-default-%{+yyyy.MM.dd}"setup.template.enabled: false
setup.ilm.enabled: false- 部署filebeat容器
在/code/filebeat这个目录下添加上面的2个yml文件,并创建/data和/logs目录之后
docker-compose -f docker-compose.yml up -d
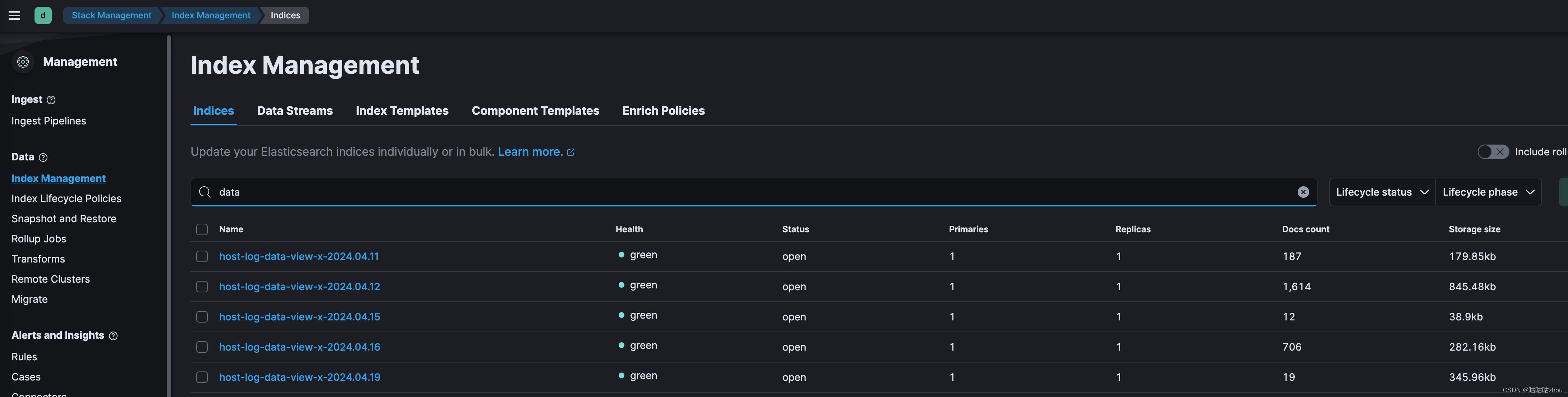
- 验证日志上传
登录kibana的web界面,查看索引管理信息,就能看到日志已经按照服务进行了切割
- 配置数据视图
由于我已经创建过该数据视图,所以提示错误了
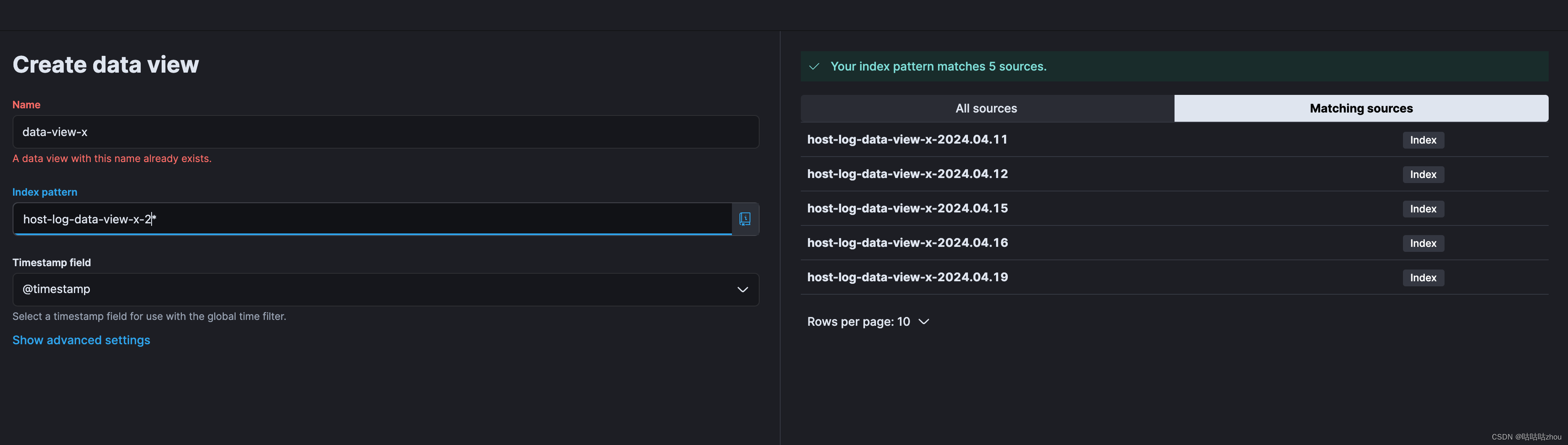
- 使用kibana查询日志
进入discover,我们就能选择已经创建的数据视图,切换完成后,搜索的日志就全是该服务下的日志信息了。
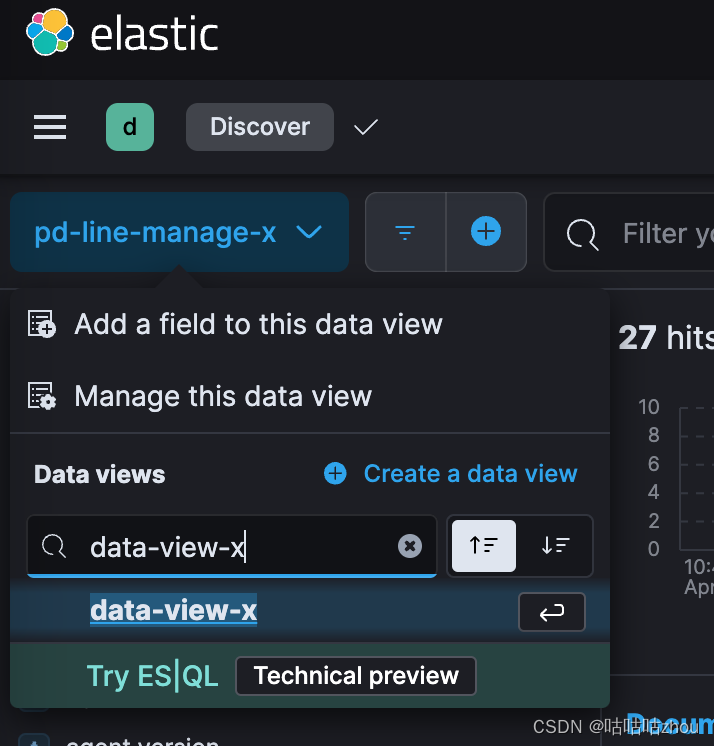
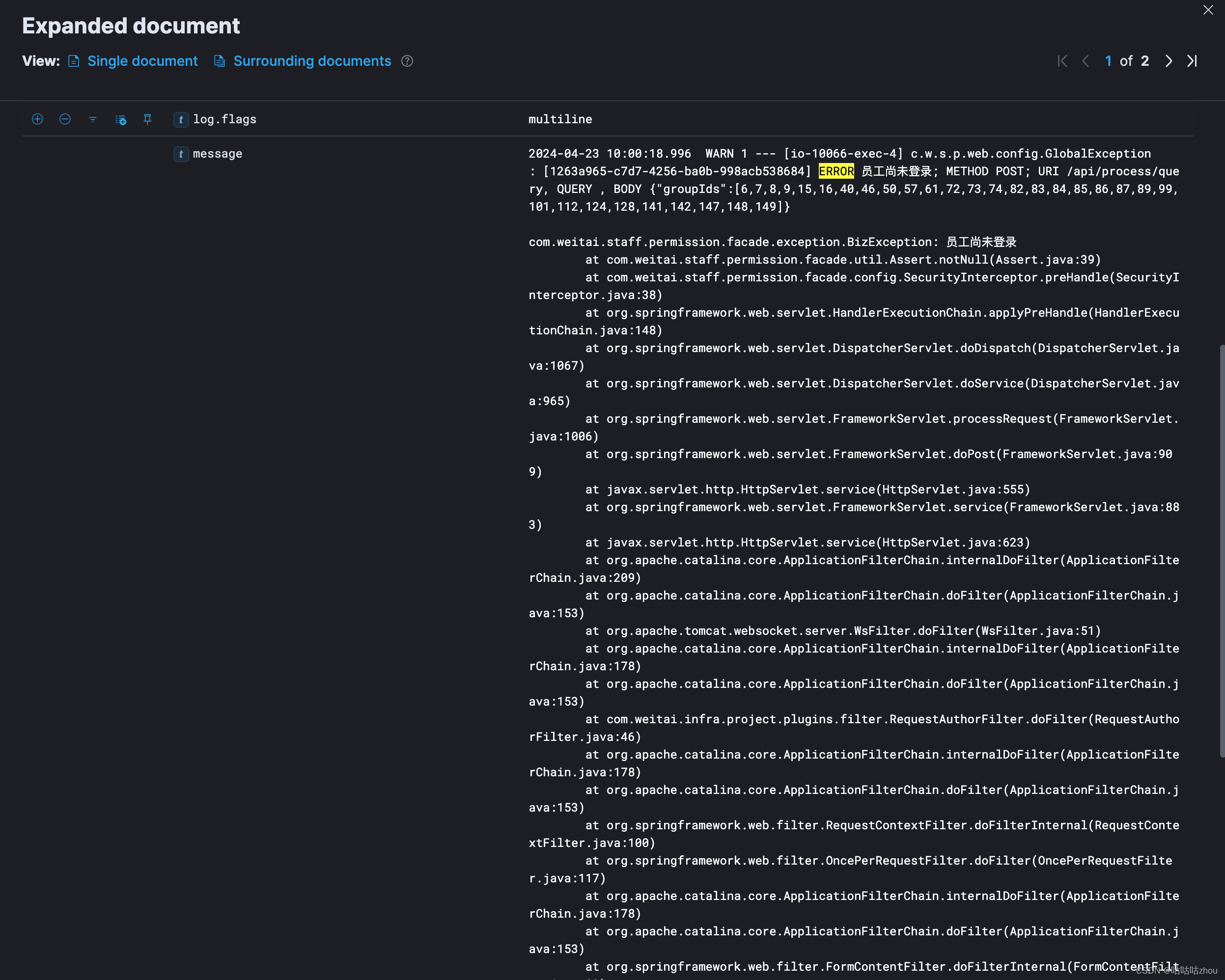
比较抱歉,上述演示的服务没有日志,我换了一个展示,途中所展示的字段偏少,是因为很多无用字段被我剔除了。
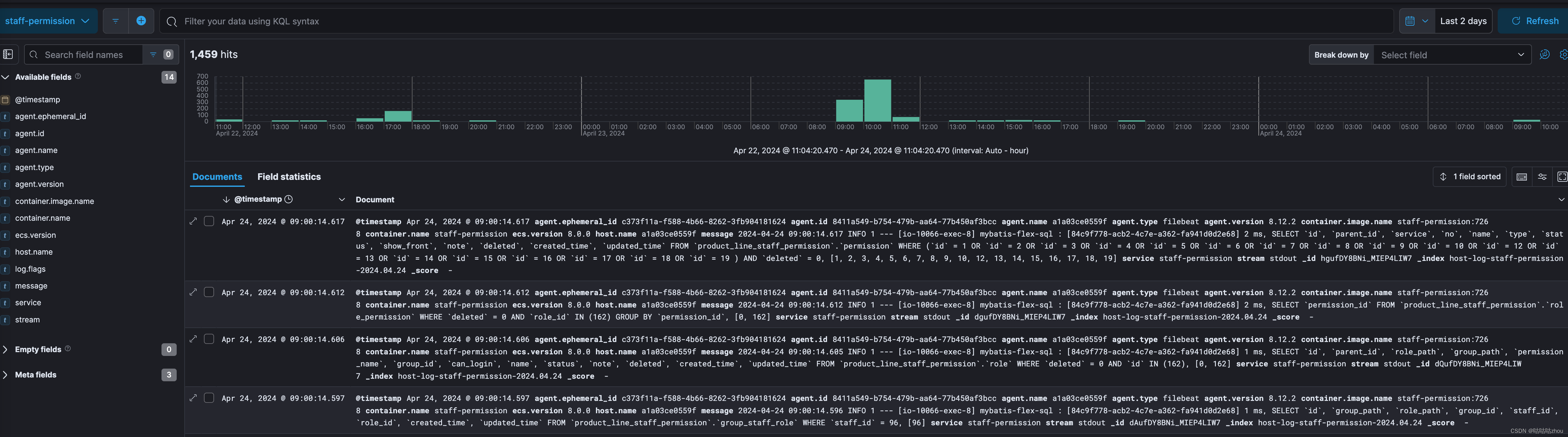
异常日志聚合展示的效果
在k8s下部署filebeat的调整
- 日志采集路径可以不做调整,但使用
/var/log/containers会更加清楚方便。

以pd-line-manage-x-6956486dc9-ptb9f_dev_pd-line-manage-x-929ae622ee5d893c8aa87dba621a3bb25508f2a7e0ca09791133ee804c2ad179.log举例,日志会按照{POD的ID}_{命名空间}_{Deployment名}-{容器ID}这样的规则软连接到docker容器下的日志存放目录。
注:这是k8s使用的是docker容器,如果使用其他CRI就不一定是这样了。

2. filebeat的部署方式建议采用Daemonsets
这样filebeat的实例会自动在每个机器上部署。
- filbeat配置文件调整
paths:# 处理空间下的日志 支持一定的通配符,k8s环境下会包含空间前缀,可以在此处过滤掉- "/var/lib/docker/containers/*/*.log"
processors:- add_docker_metadata:host: "unix:///var/run/docker.sock"
修改为
paths:# 只处理dev空间下的日志- "/var/log/containers/*_dev_*.log"
processors:- add_kubernetes_metadata:host: ${NODE_NAME}# 只收集dev空间的日志namespace: dev# 提取k8s集群中的一些环境变量信息in_cluster: truematchers:- logs_path:logs_path: "/var/log/containers/"
这样大体就实现了在k8s部署filebeat,整体与收集docker日志类似。