前言
C语言包含内置类型和自定义类型。
其实C语言中有内置类型,包含:char,short,int,long,long long,float,double,long double ,这些是C语言本身支持的现成的类型。
但仅仅只有内置类型是远远不够的,在描述一个复杂对象是无法使用内置类型来描述,例如描述一个人,可以通过姓名,身高,性别,体重等来描述,这时就需要使用自定义类型!!
自定义类型包含:结构体(struct),枚举(enum),联合体(union)。
自定义类型常常与数据结构关联,所谓的数据结构,其实就是数据在内存中的存储和组织的结构,并且数据结构有很多种,
线性数据结构:顺序表,链表,栈,队列
树形的数据结构:二叉树
图……
想知道其他的内容:请关注石油人单跳所有石油人单挑所有-CSDN博客
https://blog.csdn.net/2302_80345385?spm=1011.2415.3001.5343
目录
前言
1----结构体
1-1结构体的声明
1-2结构体变量的创建和初始化
1-3结构体的特殊声明
1-4 结构体的自引用
1-5计算结构的大小
练习1——(规则1,2,3)
练习2——(规则4)
1-6内存对齐的原因
1-7修改默认对齐数
1-6结构体传参
1-7位段
1-7-1认识位段
1-7-2位段的内存分配
1-7-3位段的跨平台问题
1-7-4位段的使用的注意事项
1-7-5位段的拓展
2----联合体
2-1联合体类型的声明
2-2联合体的特点
2-2-1对比结构体和联合体的内存发布情况
2-3联合体的大小计算
2-3-1实际运用
2-4联合体的经典练习
2-4-1 方法1--联合体
2-4-2方法2--字节
3----结构体与联合体区别(重点)
3-1. 内存利用方面
3-2. 成员访问方面
3-3. 用途方面
3-4 总结
4----枚举
4-1枚举的声明
4-2枚举类型的优点
4-3枚举类型的使用
5----自定义类型的总结
6----警告的总结
7----编程提示的总结
1----结构体
1-1结构体的声明


在声明结构体时,必须列出它包含的所有成员,这个列表包括每个成员的类型和名字,
结构体的成员可能是一个或多个
花括号括起来的是变量列表(成员列表)
结构体的表示形式
假如要描述一个学生,就可以使用结构体类型~~
//结构体的声明
struct students
{char name[20];//姓名int age;//年龄float score;//成绩char id[20];//身份证号
};//注意:分号不能丢注意:分号不能丢
在声明结构体时可以使用typedef创建一种新的类型
比如:
typedef struct students
{char name[20];//姓名int age;//年龄float score;//成绩char id[20];//身份证号
}stu;//分号不能丢这个技巧和声明一个结构标签的效果相同,区别于stu现在是一个类型名但不是结构标签~~
1-2结构体变量的创建和初始化
结构体初始化有两种方式
一种是按照结构体成员的顺序初始化
一种是按指定的顺序初始化
例如:初始化学生的信息,一起看看代码吧~~
//结构体的创建和初始化
#include<stdio.h>
struct students
{char name[20];//姓名int age;//年龄float score;//成绩char id[20];//身份证号
};//分号不能丢
int main()
{//1-按结构体成员的顺序初始化//struct students s = { "张三",18,90.5f,"123456789"};//2-按指定的顺序初始化struct students s = { .name="张三",.age=18,.score=90.5f,.id="123456789" };printf("name:%s\n", s.name);printf("age:%d\n", s.age);printf("score:%f\n", s.score);printf("id:%s\n", s.id);return 0;
}1-3结构体的特殊声明
在声明结构的时候,可以不完全的声明。(缺少标签)——匿名结构体
比如下面的结构体就是一个匿名结构体:
struct
{char b;int a;float c;
}x;
但匿名结构体也存在问题
例如:
//匿名结构体只能使用一次
struct
{char b;int a;float c;
}x;
struct
{char b;int a;float c;
}*ps;
#include<stdio.h>
int main()
{ps = &x;return 0;
}输出结果:

这段代码与匿名结构体有关
上面的结构在声明的时候省略了结构体的标签。
那么
p=&x;//这是合法的吗?
分析:
编译器会把上面的两个声明当成完全不同的两个类型,所以是非法的。
匿名的结构体类型,如果没有对结构体类型重命名的话,基本上只能使用一次!!
对匿名结构体的改进
可以使用typedef重命名匿名结构体,这样就可以消除匿名结构体只能使用一次的缺陷!!
当这个结构体只使用一次是可以考虑使用匿名结构体,否则不要考虑!!
当然匿名结构体也可以重命名~~
//改善
typedef struct
{char b;int a;float c;
}stu;//匿名结构体类型也可以重新命名
#include<stdio.h>
int main()
{stu s;return 0;
}当然匿名结构体也可以进行初始化~~
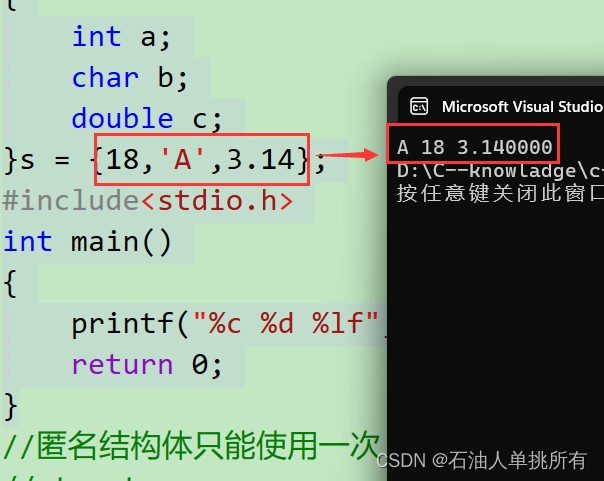
struct
{int a;char b;double c;
}s = {18,'A',3.14};//在这里创建变量,也可以初始化,没有标签名
#include<stdio.h>
int main()
{printf("%c %d %lf", s.b, s.a, s.c);return 0;
}输出结果:
1-4 结构体的自引用
在结构体中包含一个类型为该结构体本身的成员可以吗?
比如:定义一个链表的节点,其中节点的结构是:(数据域+指针域)/(数据和地址)
struct Node {int data;struct Node next;
};那么试试计算链表节点这个结构体的大小吧~~
其实这样的引用方式是错误的,因为一个结构体中再包含一个同类型的结构体变量,这样结构体变量的大小就会无穷的大,这是错误的!!
那么看看正确的自引用方式吧~~
struct Node {int data;//数据struct Node* next;//指针
};在结构体自引用的过程中,使用typedef对匿名结构体重命名,也容易产生问题,看看下面的代码可行吗?
typedef struct {int data;//数据Node* next;//指针
}Node;其实这样是不行的,因为Node是对前面的匿名结构体类型的重命名产生的,但在匿名结构体内部提前使用Node类型来创建成员变量,这是不行的!!
解决方案:定义结构体不要使用匿名结构体!!
实例代码如下:
typedef struct Node {int data;//数据struct Node* next;//指针
}Node;关于结构体的自引用,有两种写法。完整代码如下~~
//结构体的自引用
//匿名的结构体类型是不能实现这种结构体的自引用效果的
#include<stdio.h>
typedef struct Node {int data;//数据struct Node* next;//指针
}Node;
// 写法1struct Node {int data;//数据struct Node* next;//指针
};//写法2
int main()
{struct Node Node1;Node node1;return 0;
}1-5计算结构的大小
想知道结构体的大小我们得学习结构体内存对齐~~
1-5-1对齐规则
首先我们得掌握结构体的对齐规则
1、结构体的第一个成员对齐到和结构体变量起始位置偏移量为0的地址处/(位置)
2、其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处
对齐数=编译器默认的一个对齐数与该成员变量大小的较小值
VS中默认的值是8
Linux中gcc没有默认对齐数,对齐数就是成员本身的大小
3、结构体大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍
4、如果嵌套了结构体,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍数处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍
比如:偏移量是4的倍数,地址便是4的倍数~
试着做这两道练习,检验你是否真的会计算结构体大小~~
注意:VS对齐数一般设为2的整数倍
练习1——(规则1,2,3)
//计算结构体的大小
//内存对齐
#include<stdio.h>
struct S2
{char c1;//1 8 1char c2;//1 8 1int i;//4 8 4
};
int main()
{printf("%zd\n", sizeof(struct S2));return 0;
}输出结果:
8
解析:

这也可以说明结构体(struct),多个成员,每个成员都有自己独立的空间!!
0——第一个成员存放
练习2——(规则4)
#include<stdio.h>
struct S3
{double d;//8 8 8char c;//1 8 1 所有最大对齐数中最大的是8,那么结构体的大小就是8的倍数int i;//4 8 4float e;//4 8 4
};//大小为24
struct S4
{char c1;//1 8 1struct S3 s3;//看s3里的最大对齐数-8double d;//8 8 8
};
int main()
{
printf("%zd\n", sizeof(struct S4));//返回size_t
return 0;
}输出结果:
40
解析:
S3结构体大小的计算

S4结构体大小的计算

结论:对于计算嵌套的结构体的大小,先计算“里面”的结构体的大小,得出“里面”的最大对齐数,再计算外面的结构体的大小。计算嵌套的结构体时偏移量从“里面”的最大对齐数的整数倍开始,偏移“里面”的结构体的大小~~
1-6内存对齐的原因
1、平台原因

2、性能原因

结论:结构体的内存对齐是拿空间换时间的做法~~
在设计结构体是要满足内存对齐,又要节省空间
可以让占用空间小的成员,尽量集中在一起~~
下面这段代码就可以说明这个方法~~
尽管类型成员相同,但它们所占的空间大小有所不同
struct S1
{char c1;//1int i;//4char c2;//1
};
struct S2
{char c1;//1char c2;//1int i;//4
};
int main()
{printf("%zd\n", sizeof(struct S1));//12printf("%zd\n", sizeof(struct S2));//8return 0;
}输出结果

1-7修改默认对齐数
#pragma 这个预处理指令,可以改变编译器的默认对齐数
#include<stdio.h>
#pragma pack(1)
//#pragma pack(2)
//设置默认对齐数
struct S1
{char c1;//1 1 1 1 2 1int i;//1 4 1 2 4 2char c2;//1 1 1 1 2 1//对齐数为1时,每个成员对齐到数字1上,说明没有对齐//那么连续存放就OK,最终结构体的大小只要是1的倍数就OK
};
#pragma pack()//取消设置的对齐数,还原为默认的
int main()
{printf("%zd\n", sizeof(struct S1));//3return 0;
}结构体在对齐方式不合适时,可以自己更改默认对齐数~~
1-6结构体传参
#include<stdio.h>
//struct book {
// char name[20];
// int price;
//}s = {"简爱",100};//初始化写法1
struct book {char name[20];int price;
};
struct book s={ "简爱",1000 };//初始化写法2
void Print(struct book* ps)
{printf("name->%d\n", ps->price);
}
int main()
{Print(&s);return 0;
}
//结构体传参的时候要传结构体的地址!!输出结果:
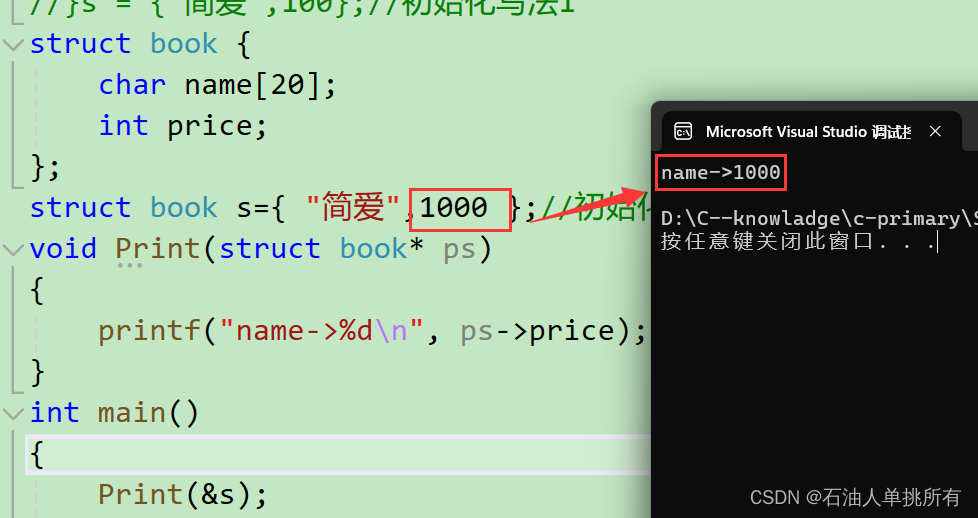
结构体传参的时候要传结构体的地址的原因:
分析:函数传参的时候,参数是需要压栈的,会有时间和空间上系统的开销。
如果传递一个结构体对象的时候,结构体过大,参数压栈的系统开销比较大,所以会导致系统的性能下降。
再强调一下结构体传参的时候要传结构体的地址!!
1-7位段
1-7-1认识位段
位段是专门用来节省内存的。
位段声明和结构是类似的,但有所差异~
1、位段的成员必须是int,unsigned int或者signed int,在C99中位段成员的类型也可以选择其他类型
2、位段的成员名后面有一个冒号和一个数字
位段的声明
struct A
{int _a ;int _b ;//4个字节占32个比特位int _c ;int _d ;int _e ;
};那么位段的大小怎么计算呢?
例如
位段——“位”:二进制位
struct A
{int _a : 2;//_a只占2个比特位int _b : 5;int _c : 10;int _d : 30;int _e : 31;
};A就是一个位段,那么A的大小是多少呢?
//位段——位:二进制位
struct A
{int _a : 2;//_a只占2个比特位int _b : 5;int _c : 10;int _d : 30;int _e : 31;
};
#include<stdio.h>
int main()
{printf("%zd\n", sizeof(struct A));//12return 0;
}输出结果
12
为什么是12呢?想知道这个得知道位段的内存分配~~
1-7-2位段的内存分配

注重可移植性的程序应该避免使用位段。由于下面这些与实现有关的依赖性,位段在不同的系
统中可能有不同的结果。
1. int 位段被当作有符号数还是无符号数
2.位段中位的最大数目。许多编译器把位段成员的长度限制在一个整型值的长度之内,所以一个能够运行于32位整数的机器上的位段声明可能在16位整数的机器上无法运行。
3.位段中的成员在内存中是从左向右分配的还是从右向左分配的。
4.当一个声明指定了两个位段,第2个位段比较大,无法容纳于第1个位段剩余的位时,编译器有可能把第2个位段放在内存的下一个字,也可能直接放在第1个位段后面,从而在两个内存位置的边界上形成重叠。
就这上面的代码,解释上这段吧~~

那么现在可以解释为什么A的大小是12字节了。
图解:

为了再次认识位段的内存分配,看看下面这段代码吧~~
struct S
{char a:3;char b:4;char c:5;char d:4;
};
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
//这个位段的空间是如何开辟的呢?解析:
例如:存数字0,1,2,3
00-0,01-1,10-2,11-2,两个二进制位就够了,但有30个比特位浪费了
此时就可以使用位段——在一定程度节省内存空间
C语言没有规定标准,剩余空间不够时,是浪费还是继续存放
这就取决于编译器
VS上数据从右往左存,剩余空间不够时,是浪费
#include<stdio.h>
struct S
{char a : 3;//010char b : 4;char c : 5;char d : 4;
};int main()
{struct S s = { 0 };s.a = 10;//1010发生截断,存的是010s.b = 12;s.c = 3;s.d = 4;return 0;
}图解
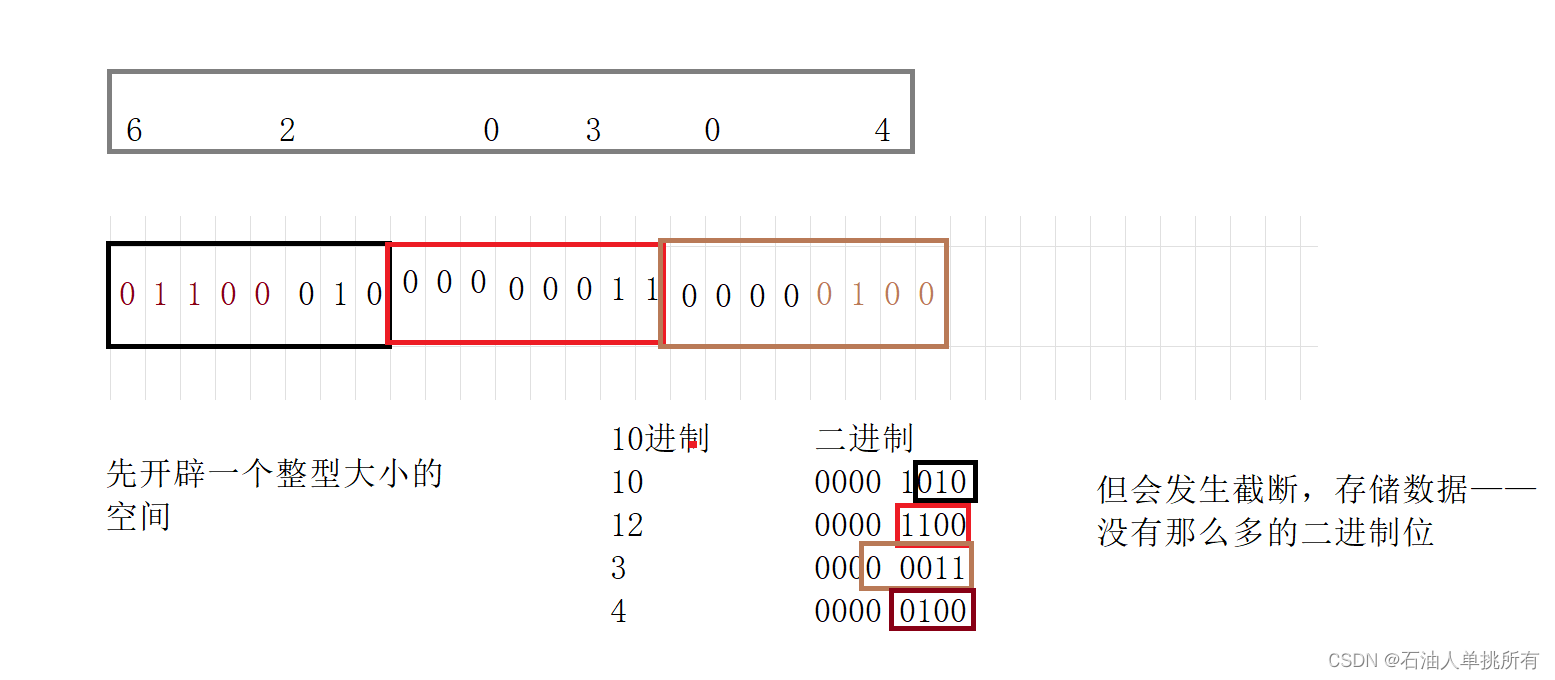
调试过程

1-7-3位段的跨平台问题
- 根据不同的平台写不同的代码。
- 32位和64位的机器上int的长度是4个字节,16位机器上int的长度是2个字节。
- int 位段被当作有符号数还是无符号数
- 位段中位的最大数目。许多编译器把位段成员的长度限制在一个整型值的长度之内,所以一个能够运行于32位整数的机器上的位段声明可能在16位整数的机器上无法运行。
- 位段中的成员在内存中是从左向右分配的还是从右向左分配的。
- 当一个声明指定了两个位段,第2个位段比较大,无法容纳于第1个位段剩余的位时,编译器有可能把第2个位段放在内存的下一个字,也可能直接放在第1个位段后面,从而在两个内存位置的边界上形成重叠。
1-7-4位段的使用的注意事项

因此不能对位段成员使用&操作符,这样就不能使用scanf函数给位段成员输入值,那么解决方案是:先输入放在一个变量中,然后赋值给位段成员~
//位段的使用
//使用位段的结构体类型中的成员类型应该相同
struct A
{int _a : 2;//_a只占2个比特位int _b : 5;int _c : 10;int _d : 30;int _e : 31;
};
#include<stdio.h>
int main()
{struct A sa = { 0 };int b = 0;scanf("%d", & b);sa._b = b;printf("%zd", sizeof(struct A));return 0;
}1-7-5位段的拓展



2----联合体
2-1联合体类型的声明
像结构体一样,联合体也是由一个或多个成员构成,这些成员可以是不同的类型。
但编译器只为最大的成员分配足够的内存空间。联合体的特点是所有成员共用同一块内存空间。
因此联合体也叫共用体。
给联合体其中一个成员赋值,其他成员的值也跟着变化。
联合体的运用场景:改变c时i也被改变,先改变低地址处。
一般:union与struct不会同时使用~
//联合体类型的声明
#include<stdio.h>
union un {char a;int b;
};
int main()
{union un u = { 0 };//联合体变量的定义//计算联合体变量的大小printf("%zd\n", sizeof(u));return 0;
}输出结果:

为什么输出结果是4呢?
那要看联合体类型的特点呢~~
2-2联合体的特点
联合体的成员是共用同一块内存空间的,这样一个联合变量的大小,至少是最大成员的大小。(因为联合至少得有能力保存最大的成员)
看看这两段代码,相信你会对此有深入的理解。
第一段代码
#include <stdio.h>
//联合体的声明
union Un
{char c;int i;
};
int main()
{//创建联合体变量union Un un = {0};// 它们的地址大小一样?printf("%p\n", &(un.i));printf("%p\n", &(un.c));printf("%p\n", &un);return 0;
}输出结果:
00000045EBFFF764
00000045EBFFF764
00000045EBFFF764
再看看第二段代码
#include <stdio.h>
union Un//联合体的声明
{char c;int i;
};
int main()
{union Un un = { 0 };//联合体变量的创建un.i = 0x11223344;un.c = 0x55;printf("%x\n", un.i);return 0;
}输出结果:
11223355
从输出结果可以看出,第一段代码输出的地址都一样,而从第二段代码输出结果可以分析,将i的第四个字节的内容修改为55了。
因此可以画出联合体(un)的内存发布图

2-2-1对比结构体和联合体的内存发布情况
我们再对比一下相同成员的结构体和联合体的内存发布情况。
结构体
struct S
{char c;int i;
};内存分布情况:

联合体:
union un
{char c;int i;
};内存发布情况:

结论:共用体(union)多个成员,所以成员共用同一块内存空间!!
2-3联合体的大小计算
1、联合体的大小至少是最大成员的大小
2、当最大成员的大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍
试着计算下面两个联合体的大小吧~~
// 计算联合体的大小
#include<stdio.h>
union Un1
{char c[5];//1 8 1int i;//4 8 4
};
union Un2
{short c[7];//2 8 2int i;//4 8 4
};
int main()
{union Un1 u1 = { 0 };union Un2 u2 = { 0 };printf("%zd\n", sizeof(u1));printf("%zd\n", sizeof(u2));return 0;
}
输出结果:
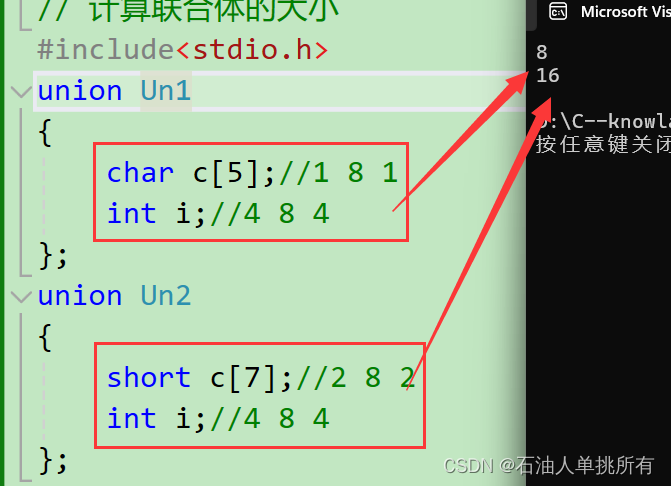
解析
联合体Un1的内存发布
联合体Un2的内存发布

联合体是可以节省内存的!!
2-3-1实际运用
比如有一个礼物兑换单,礼物兑换单中三个商品:书,杯子,衬衫。
每一种商品都有库存量,价格,商品类型和商品类型相关的其他信息
书:书名,作者,页数
杯子:设计
衬衫:设计,颜色,尺寸
如果将这些信息简单的一 一罗列在一个结构体中,用起来很方便,但这样使得结构体的大小偏大,比较浪费内存,因为对于兑换单中的商品来说,只有部分属性信息是常用的,比如商品为书,就不需要design,colour,size……
所以可以把公共属性单独写出来,剩余属于各种商品本身的属性使用联合体联合起来,这样在一定程度上节省了内存~~
struct gift_list
{//公共属性int stock_number;//库存量double price;//价格int type;//商品类型//每个商品具有的自己的属性union {struct {char book_name[20];//书名char author[20];//作者int page;//页数}book;struct {char design[20];//设计}cup;struct {char design[20];//设计char colour[10];//颜色char size[10];//尺寸}shirt;};
};2-4联合体的经典练习
写一个小程序判断,你的机器是大端模式还是小端模式
在写程序之前,先来回顾一下大端和小端模式
大端:数据的低位字节内容保存在内存的高地址处,而数据的高位字节内容保存在内存的低地址处
小端:数据的低位字节内容保存在内存的低地址处,而数据的高位字节内容保存在内存的高地址处
例如:0x11223344,在小端模式下,存储的顺序是44332211在10进制中,例如数字123,1是高位,3是低位,在计算机中从左往右,是从低地址到高地址处的
2-4-1 方法1--联合体
练习判断一个机器是大端还是小端
根据联合体的内存发布特点可以轻松解决
写法1
#include<stdio.h>
int check_sys()
{union {int a;char b;}sa;sa.a = 1;return sa.b;
}
int main()
{if (check_sys()){printf("小端\n");}else{printf("大端\n");}return 0;
}2-4-2方法2--字节
练习判断一个机器是大端还是小端
判断一个字节存储的是1还是0
//写法2
#include<stdio.h>
int check_sys()
{int i = 1;return (*(char*)(&i));
}
int main()
{if (check_sys()){printf("小端\n");}else{printf("大端\n");}return 0;
}本电脑的输出结果:
小端
3----结构体与联合体区别(重点)
C语言中结构体(struct)与联合体(union)是两种不同的数据结构,它们的主要区别在于内存利用、成员访问和用途。具体分析如下:
3-1. 内存利用方面
结构体中每个成员占用独立的内存空间,而联合体的所有成员共享同一块内存空间。这意味着一个结构体变量的总长度等于所有成员的长度之和,而一个联合体变量的总长度至少能容纳最大的成员变量,并且要满足是所有成员变量类型大小的整数倍。
3-2. 成员访问方面
在结构体中,可以同时访问每个成员,因为它们各自拥有独立的存储空间;而在联合体中,只能同时访问其中一个成员,因为所有成员共用相同的存储空间。
3-3. 用途方面
结构体通常用于将不同类型的数据组合成一个整体,以自定义数据类型的形式来使用;而联合体则用于让几个不同类型的变量共占一段内存,这些变量会相互覆盖,通常用于节省内存或者处理不同类型数据的交替存储。
3-4 总结
总结来说,结构体适合用于需要同时存储和访问多个不同类型数据的情况,而联合体则适用于只需要存储一组数据中的某一个,或者需要共享内存空间以节省内存的场合。了解这两者的区别对于编写高效、可维护的代码非常重要。通过合理选择使用结构体或联合体,可以优化程序的内存使用,提高执行效率。
4----枚举
4-1枚举的声明
枚举字面意思就是一 一列举,把可能的值一 一列举。
比如:性别:男、女,可以一 一列举
三原色:红、绿、蓝,也可以一 一列举~
这些数据的表示就可以使用枚举!!
比如三原色使用枚举类型表示:
//枚举类型的声明
enum Colour {RED ,GREEN ,BLUE ,
};上面定义的enum Colour是枚举类型,{ }中的内容是枚举类型的可能取值,也叫枚举常量。
这些可能取值都是有值的,默认从0开始,一次递增1。当然在声明枚举类型的时候也可以赋值。
比如:
enum Colour{RED = 2,GREEN = 4,BLUE = 6,
};4-2枚举类型的优点
之前我们学习了#define定义常量,那么枚举类型与之有什么不同呢?

4-3枚举类型的使用
enum Colour{RED = 2,GREEN = 4,BLUE = 6,
};
enum Colour clr = GREEN;//使用枚举常量给枚举变量赋值C语言中可以拿整数给枚举变量赋值,但在C++中不行!!
5----自定义类型的总结
- 1、 在结构中,不同类型的值可以存储在一起。结构中的值称为成员,它们是通过名字访问的。结构变量是一个标量,可以出现在普通标量变量可以出现的任何场合。
- 2、 结构的声明列出了结构包含的成员列表。不同的结构声明即使它们的成员列表相同也被认为是不同的类型。结构标签是一个名字,它与一个成员列表相关联。你可以使用结构标签在不同的声明中创建相同类型的结构变量,这样就不用每次在声明中重复成员列表。typedef也可以用于实现这个目标。
- 3、 结构的成员可以是标量、数组或指针。结构也可以包含本身也是结构的成员。在不同的结构中出现同样的成员名是不会引起冲突的。你使用点操作符访问结构变量的成员。如果你拥有一个指向结构的指针,你可以使用箭头操作符访问这个结构的成员。
- 4、 结构不能包含类型也是这个结构的成员,但它的成员可以是一个指向这个结构的指针。这个技巧常常用于链式数据结构中。为了声明两个结构,每个结构都包含一个指向对方的指针的成员,我们需要使用不完整的声明来定义一个结构标签名。结构变量可以用一个由花括号包围的值列表进行初始化。这些值的类型必须适合它所初始化的那些成员。
- 5、 编译器为一个结构变量的成员分配内存时要满足它们的边界对齐要求。在实现结构存储的边界对齐时,可能会浪费一部分内存空间。根据边界对齐要求降序排列结构成员可以最大限度地减少结构存储中浪费的内存空间。sizeof 返回的值包含了结构中浪费的内存空间。
- 6、 结构可以作为参数传递给函数,也可以作为返回值从函数返回。但是,向函数传递一个指向结构的指针往往效率更高。在结构指针参数的声明中可以加上const 关键字防止函数修改指针所指向的结构。
- 7、 位段是结构的一种,但它的成员长度以位为单位指定。位段声明在本质上是不可移植的,因为它涉及许多与实现有关的因素。但是,位段允许你把长度为奇数的值包装在一起以节省存储空间。源代码如果需要访问一个值内部任意的一些位,使用位段比较简便。
- 8、 一个联合的所有成员都存储于同一个内存位置。通过访问不同类型的联合成员,内存中相同的位组合可以被解释为不同的东西。联合在实现变体记录时很有用,但程序员必须负责确认实际存储的是哪个变体并选择正确的联合成员以便访问数据。联合变量也可以进行初始化,但初始值必须与联合第1个成员的类型匹配。
6----警告的总结
1.具有相同成员列表的结构声明产生不同类型的变量。
2.使用typedef 为一个自引用的结构定义名字时应该小心。
3.向函数传递结构参数是低效的。
7----编程提示的总结
1. 把结构标签声明和结构的 typedef 声明放在头文件中,当源文件需要这些声明时可以通过#include指令把它们包含进来。
2. 结构成员的最佳排列形式并不一定就是考虑边界对齐而浪费内存空间最少的那种排列形式。3.把位段成员显式地声明为signed int或unsigned int类型。
4.位段是不可移植的。
5.位段使源代码中位的操作表达得更为清楚。
制作不易,老铁们三连吧,别下次一定了!!