文章目录
- FIFO/LFU/LRU 算法简介
- FIFO(First In First Out)
- LFU(Least Frequently Used)
- LRU(Least Recently Used)
- LRU实现
- 实现原理
- LRU代码说明
- LRU完整代码
- 单机并发缓存
- Http服务器
- 一致性哈希
- 分布式节点
- 防止缓存击穿
- 使用 Protobuf 通信
- 项目Get流程
- 参考资料
FIFO/LFU/LRU 算法简介
GeeCache 的缓存全部存储在内存中,内存是有限的,因此不可能无限制地添加数据。假定我们设置缓存能够使用的内存大小为 N,那么在某一个时间点,添加了某一条缓存记录之后,占用内存超过了 N,这个时候就需要从缓存中移除一条或多条数据了。那移除谁呢?我们肯定希望尽可能移除“没用”的数据,那如何判定数据“有用”还是“没用”呢?
FIFO(First In First Out)
先进先出,也就是淘汰缓存中最老(最早添加)的记录。FIFO 认为,最早添加的记录,其不再被使用的可能性比刚添加的可能性大。这种算法的实现也非常简单,创建一个队列,新增记录添加到队尾,每次内存不够时,淘汰队首。但是很多场景下,部分记录虽然是最早添加但也最常被访问,而不得不因为呆的时间太长而被淘汰。这类数据会被频繁地添加进缓存,又被淘汰出去,导致缓存命中率降低。
LFU(Least Frequently Used)
最少使用,也就是淘汰缓存中访问频率最低的记录。LFU 认为,如果数据过去被访问多次,那么将来被访问的频率也更高。LFU 的实现需要维护一个按照访问次数排序的队列,每次访问,访问次数加1,队列重新排序,淘汰时选择访问次数最少的即可。LFU 算法的命中率是比较高的,但缺点也非常明显,维护每个记录的访问次数,对内存的消耗是很高的;另外,如果数据的访问模式发生变化,LFU 需要较长的时间去适应,也就是说 LFU 算法受历史数据的影响比较大。例如某个数据历史上访问次数奇高,但在某个时间点之后几乎不再被访问,但因为历史访问次数过高,而迟迟不能被淘汰。
LRU(Least Recently Used)
最近最少使用,相对于仅考虑时间因素的 FIFO 和仅考虑访问频率的 LFU,LRU 算法可以认为是相对平衡的一种淘汰算法。LRU 认为,如果数据最近被访问过,那么将来被访问的概率也会更高。LRU 算法的实现非常简单,维护一个队列,如果某条记录被访问了,则移动到队尾,那么队首则是最近最少访问的数据,淘汰该条记录即可。
LRU实现
实现LRU建议先看看146. LRU 缓存再来看这里的实现就不难了。
LRU应当支持以下两个操作,一个要求:
- 获取数据 get(key)
- 如果key存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
- 写入数据 put(key, value)
- 如果key不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
- 时间复杂度要求
- 在 O(1) 时间复杂度内完成get、put操作
实现原理
LRU结构图

1、首先要想缓存数据,通过 hash map ,效率高,操作方便;定义当前缓存的数量和最大容量
2、因为需要保证最久未使用的数据在缓存满的时候将其删除,所以就需要一个数据结构能辅助完成这个逻辑。
所以说使用链表这种结构可以方便删除结点,新增结点,但由于最久未使用的结点在尾结点,通过单链表不方便操作,所以双链表会更加方便操作尾结点。
所以这里利用双链表数据结构list
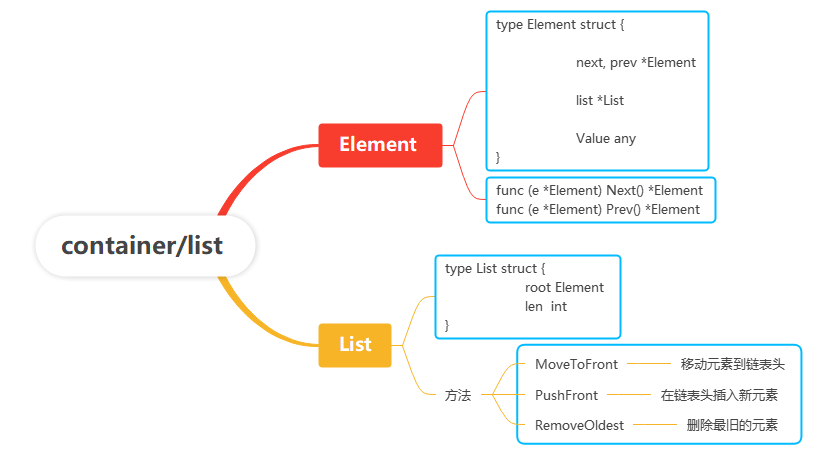
对链表的操作
- 新数据插入到链表头部
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部
- 当链表满的时候,将链表尾部的数据丢弃
LRU Cache具备的操作:
- put(key,value):如果key在hashmap中存在,则先重置对应的value值,然后获取对应的节点cur,将cur节点从链表删除,并移动到链表的头部;若果key在hashmap不存在,则新建一个节点,并将节点放到链表的头部。当Cache存满的时候,将链表最后一个节点删除即可。
- get(key):如果key在hashmap中存在,则把对应的节点放到链表头部,并返回对应的value值;如果不存在,则返回-1。
LRU代码说明
type Cache struct {maxBytes int64nbytes int64ll *list.Listcache map[string]*list.Element// optional and executed when an entry is purged.OnEvicted func(key string, value Value)
}
LRU完整代码
package lruimport "container/list"// Cache is a LRU cache. It is not safe for concurrent access.
type Cache struct {maxBytes int64nbytes int64ll *list.Listcache map[string]*list.Element// optional and executed when an entry is purged.OnEvicted func(key string, value Value)
}type entry struct {key stringvalue Value
}// Value use Len to count how many bytes it takes
type Value interface {Len() int
}// New is the Constructor of Cache
func New(maxBytes int64, onEvicted func(string, Value)) *Cache {return &Cache{maxBytes: maxBytes,ll: list.New(),cache: make(map[string]*list.Element),OnEvicted: onEvicted,}
}// Add adds a value to the cache.
func (c *Cache) Add(key string, value Value) {if ele, ok := c.cache[key]; ok {c.ll.MoveToFront(ele)kv := ele.Value.(*entry)c.nbytes += int64(value.Len()) - int64(kv.value.Len())kv.value = value} else {ele := c.ll.PushFront(&entry{key, value})c.cache[key] = elec.nbytes += int64(len(key)) + int64(value.Len())}for c.maxBytes != 0 && c.maxBytes < c.nbytes {c.RemoveOldest()}
}// Get look ups a key's value
func (c *Cache) Get(key string) (value Value, ok bool) {if ele, ok := c.cache[key]; ok {c.ll.MoveToFront(ele)kv := ele.Value.(*entry)return kv.value, true}return
}// RemoveOldest removes the oldest item
func (c *Cache) RemoveOldest() {ele := c.ll.Back()if ele != nil {c.ll.Remove(ele)kv := ele.Value.(*entry)delete(c.cache, kv.key)c.nbytes -= int64(len(kv.key)) + int64(kv.value.Len())if c.OnEvicted != nil {c.OnEvicted(kv.key, kv.value)}}
}// Len the number of cache entries
func (c *Cache) Len() int {return c.ll.Len()
}单机并发缓存
介绍 sync.Mutex 互斥锁的使用,并实现 LRU 缓存的并发控制。
实现 GeeCache 核心数据结构 Group,缓存不存在时,调用回调函数获取源数据
Http服务器
介绍如何使用 Go 语言标准库 http 搭建 HTTP Server
并实现 main 函数启动 HTTP Server 测试 API
一致性哈希
一致性哈希(consistent hashing)的原理以及为什么要使用一致性哈希。
实现一致性哈希代码,添加相应的测试用例,代码约60行
分布式节点
这部分有点乱,可以看一下Get流程图
注册节点(Register Peers),借助一致性哈希算法选择节点。
实现 HTTP 客户端,与远程节点的服务端通信
防止缓存击穿
缓存雪崩、缓存击穿与缓存穿透的概念简介。
使用 singleflight 防止缓存击穿,实现与测试。
使用 Protobuf 通信
为什么要使用 protobuf?
使用 protobuf 进行节点间通信,编码报文,提高效率。
项目Get流程
// Overall flow char requsets local
// gee := createGroup() --------> /api Service : 9999 ------------------------------> gee.Get(key) ------> g.mainCache.Get(key)
// | ^ |
// | | |remote
// v | v
// cache Service : 800x | g.peers.PickPeer(key)
// |create hash ring & init peerGetter | |
// |registry peers write in g.peer | |p.httpGetters[p.hashRing(key)]
// v | |
// httpPool.Set(otherAddrs...) | v
// g.peers = gee.RegisterPeers(httpPool) | g.getFromPeer(peerGetter, key)
// | | |
// | | |
// v | v
// http.ListenAndServe("localhost:800x", httpPool)<------------+--------------peerGetter.Get(key)
// | |
// |requsets |
// v |
// p.ServeHttp(w, r) |
// | |
// |url.parse() |
// |--------------------------------------------参考资料
Redis 核心技术与实战
Redis 源码剖析与实战
面试用 Golang 手撸 LRU
Hash 表的时间复杂度为什么是 O(1)
画图工具asciiflow





![Flutter 从 Assets 中读取 JSON 文件:指南 [2024]](https://img-blog.csdnimg.cn/img_convert/2eefce542b5b99ee3dc574fc10336589.webp?x-oss-process=image/format,png)