基于随机森林和Xgboost对肥胖风险的多类别预测
作者:i阿极
作者简介:数据分析领域优质创作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
大家好,我i阿极。喜欢本专栏的小伙伴,请多多支持
| 专栏案例:机器学习案例 |
|---|
| 机器学习(一):线性回归之最小二乘法 |
| 机器学习(二):线性回归之梯度下降法 |
| 机器学习(三):基于线性回归对波士顿房价预测 |
| 机器学习(四):基于KNN算法对鸢尾花类别进行分类预测 |
| 机器学习(五):基于KNN模型对高炉发电量进行回归预测分析 |
| 机器学习(六):基于高斯贝叶斯对面部皮肤进行预测分析 |
| 机器学习(七):基于多项式贝叶斯对蘑菇毒性分类预测分析 |
| 机器学习(八):基于PCA对人脸识别数据降维并建立KNN模型检验 |
| 机器学习(十四):基于逻辑回归对超市销售活动预测分析 |
| 机器学习(十五):基于神经网络对用户评论情感分析预测 |
| 机器学习(十六):线性回归分析女性身高与体重之间的关系 |
| 机器学习(十七):基于支持向量机(SVM)进行人脸识别预测 |
| 机器学习(十八):基于逻辑回归对优惠券使用情况预测分析 |
| 机器学习(十九):基于逻辑回归对某银行客户违约预测分析 |
| 机器学习(二十):LightGBM算法原理(附案例实战) |
| 机器学习(二十一):基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习(二十二):基于逻辑回归(Logistic Regression)对股票客户流失预测分析 |
文章目录
- 基于随机森林和Xgboost对肥胖风险的多类别预测
- 1、前言
- 2、数据说明
- 3、导入所需要的模块
- 4、导入数据
- 5、查看数据维度
- 6、查看数据基本信息
- 7、描述性统计分析
- 8、探索性数据可视化分析
- 9、特征编码
- 10、划分训练集和测试集
- 11、模型建立
- 11.1 随机森林分类模型
- 11.2 Xgboost分类模型
- 12、模型检验
- 总结
1、前言
肥胖风险的多类预测不仅关乎个体的健康福祉,更是对全社会健康管理体系的挑战与机遇。在现代社会,随着工作节奏的加快和生活方式的多样化,肥胖已经成为威胁人类健康的重要因素之一。肥胖不仅与高血压、糖尿病、心血管疾病等多种慢性疾病密切相关,还可能导致心理健康问题,如焦虑、抑郁等。
因此,开展肥胖风险的多类预测研究,对于早期识别高风险人群、制定个性化的干预措施、减少肥胖及相关疾病的发生具有重要意义。传统的肥胖风险评估方法往往依赖于单一的指标,如体重指数(BMI),但这种方法忽略了人体成分的复杂性和多样性,难以全面准确地评估肥胖风险。
近年来,随着人工智能和大数据技术的飞速发展,多类预测方法被广泛应用于肥胖风险预测领域。这些方法能够综合考虑个体的遗传、环境、行为等多个因素,通过机器学习算法建立预测模型,实现对肥胖风险的精准预测。这些模型不仅具有高度的准确性和可靠性,还能够为临床医生和公共卫生专家提供科学的决策支持,帮助他们制定更有效的肥胖预防和管理策略。
未来,随着技术的不断进步和数据的不断积累,肥胖风险的多类预测研究将不断深入。我们期待通过这一领域的探索,为全球肥胖防控事业贡献更多的智慧和力量。
2、数据说明
本次比赛的数据集(训练和测试)是从在肥胖或心血管疾病风险数据集上训练的深度学习模型生成的。特征分布与原始分布接近,但不完全相同。作为本次比赛的一部分,您可以随意使用原始数据集,既可以探索差异,也可以查看在训练中加入原始数据集是否能提高模型性能。
注意:该数据集特别适用于可视化、聚类和通用 EDA。
train.csv - 训练数据集; 是分类目标NObeyesdad
test.csv - 测试数据集;您的目标是预测每行的类NObeyesdad
3、导入所需要的模块
import pandas as pd
import numpy as np
import requests
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder,PowerTransformer
import math
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
4、导入数据
train = pd.read_csv(r"D:\playground-series-s4e2\train.csv")
test = pd.read_csv(r"D:\playground-series-s4e2\test.csv")
train.head()
部分结果如下图所示:

5、查看数据维度
train.shape
test.shape
结果如下所示:
(20758, 18)
(13840, 17)
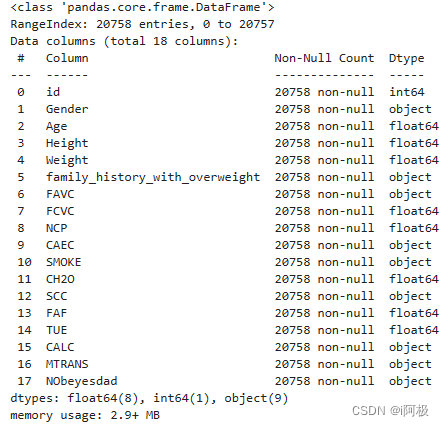
6、查看数据基本信息
train.info()
结果如下所示:
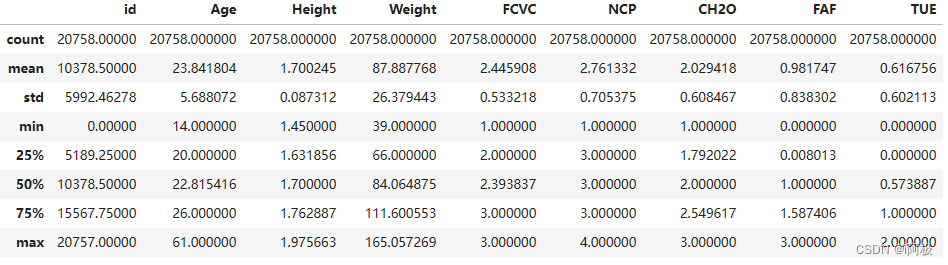
7、描述性统计分析
train.describe()
结果如下所示:
8、探索性数据可视化分析
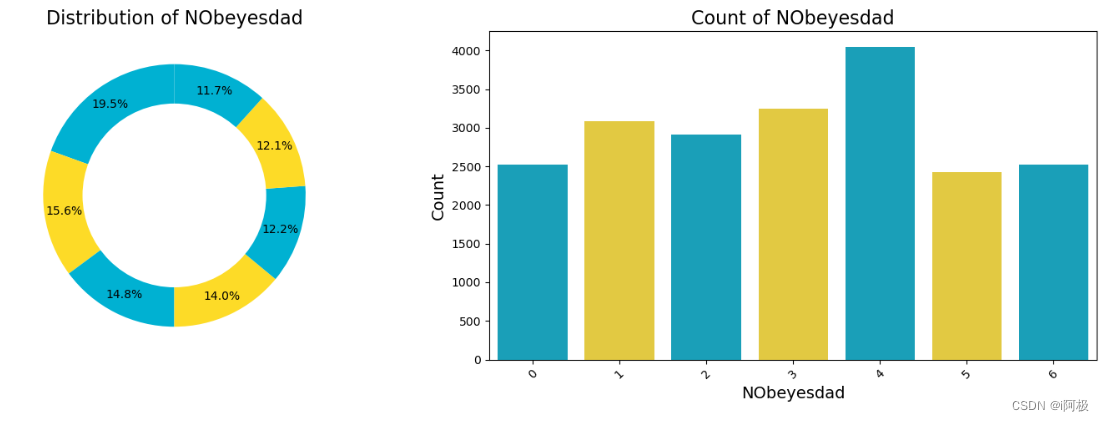
首先,定义了一个名为single_plot_distribution的函数,用于绘制给定数据框(dataframe)中某一列(column_name)的数据分布。函数首先计算该列的唯一值的出现次数(value_counts)。然后,它创建了一个包含两个子图的图形,一个用于显示环形图(pie chart),另一个用于显示条形图(bar chart)
#绘制单个饼图和条形图的函数
def single_plot_distribution(column_name, dataframe):# 获取指定列的值计数value_counts = dataframe[column_name].value_counts()# 用两个子画面设置图形fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5), gridspec_kw={'width_ratios': [1, 1]}) # 环形图palette = ["#00B1D2FF", "#FDDB27FF"]color_palette = sns.color_palette(palette)pie_colors = palette[0:3]ax1.pie(value_counts, autopct='%0.001f%%', startangle=90, pctdistance=0.85, colors=pie_colors, labels=None)centre_circle = plt.Circle((0,0),0.70,fc='white')ax1.add_artist(centre_circle)ax1.set_title(f'Distribution of {column_name}', fontsize=16)# 条形图bar_colors = palette[0:3]sns.barplot(x=value_counts.index, y=value_counts.values, ax=ax2, palette=bar_colors,) ax2.set_title(f'Count of {column_name}', fontsize=16)ax2.set_xlabel(column_name, fontsize=14)ax2.set_ylabel('Count', fontsize=14)# 旋转x轴标签以提高可读性ax2.tick_params(axis='x', rotation=45)# 显示绘图plt.tight_layout()plt.show()
由于源码中图过多,这里就举一个例子
single_plot_distribution('NObeyesdad',train)
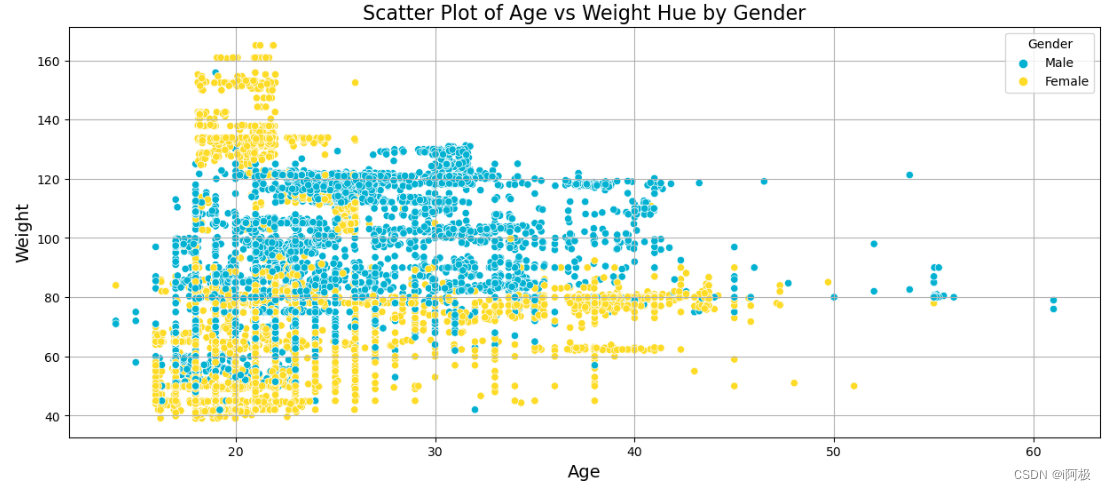
定义了一个名为advanced_scatter_plot的函数,用于绘制带有颜色区分的散点图。函数接受四个参数:x_column(x轴的数据列名)、y_column(y轴的数据列名)、target_column(用于区分不同颜色的目标列名)和dataframe(包含数据的DataFrame)。函数首先设置图形大小,然后定义颜色调色板。接着,使用seaborn库的scatterplot函数绘制散点图,其中点的颜色由target_column决定。函数还设置了图表的标题、轴标签和图例,并添加了网格线。最后,使用plt.show()显示图表。
def advanced_scatter_plot(x_column, y_column, target_column, dataframe):plt.figure(figsize=(15, 6))palette = ["#00B1D2FF", "#FDDB27FF"]color_palette = sns.color_palette(palette)sns.scatterplot(x=x_column, y=y_column, hue=target_column, data=dataframe, palette=palette[0:3])plt.title(f'Scatter Plot of {x_column} vs {y_column} Hue by {target_column}', fontsize=16)plt.xlabel(x_column, fontsize=14)plt.ylabel(y_column, fontsize=14)plt.legend(title=target_column)plt.grid(True)plt.show()
由于源码中图过多,这里就举一个例子
advanced_scatter_plot('Age', 'Weight', 'Gender', train)#在男女当中,显示年龄与体重的关系
9、特征编码
label_encoder = LabelEncoder()
train['NObeyesdad'] = label_encoder.fit_transform(train['NObeyesdad'])train = pd.get_dummies(train)
test = pd.get_dummies(test)
10、划分训练集和测试集
X = train.drop(['id', 'NObeyesdad'], axis=1)
y = train['NObeyesdad']X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
#将训练集和测试集划分为8:2
11、模型建立
11.1 随机森林分类模型
model_RF = RandomForestClassifier(n_estimators=100, random_state=42)
model_RF.fit(X_train, y_train)
val_preds_RF = model_RF.predict(X_val)
accuracy_RF = accuracy_score(y_val, val_preds_RF)
print(f"Validation Accuracy: {accuracy_RF}")#模型准确率
# Validation Accuracy: 0.8872832369942196
11.2 Xgboost分类模型
from xgboost import XGBClassifier # 初始化XGBoost分类器
model_XGB = XGBClassifier(n_estimators=100, random_state=42) # 使用训练数据拟合模型
model_XGB.fit(X_train, y_train)
val_preds_XGB = model_XGB.predict(X_val)
accuracy_XGB = accuracy_score(y_val, val_preds_XGB)
print(f"Validation Accuracy: {accuracy_XGB}")#模型准确率
#Validation Accuracy: 0.9019749518304432
12、模型检验
一开始有导入文件名为test的数据集,将训练好的模型进行检验。
if 'CALC_Always' in test.columns:test.drop('CALC_Always', axis=1, inplace=True)
test_preds_RF = model_RF.predict(test.drop('id', axis=1))
test_preds_XGB = model_XGB.predict(test.drop('id', axis=1))
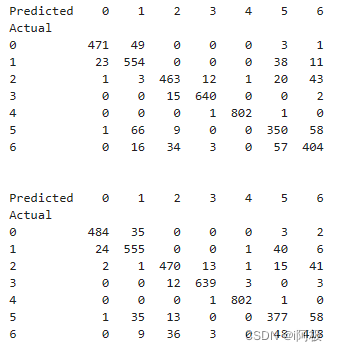
#输出热力图结果
conf_matrix_RF = pd.crosstab(y_val, val_preds_RF, rownames=['Actual'], colnames=['Predicted'])
conf_matrix_XGB = pd.crosstab(y_val, val_preds_XGB, rownames=['Actual'], colnames=['Predicted'])
print(conf_matrix_RF)
print('\n')
print(conf_matrix_XGB)
总结
此项目适合毕设和课设学习等等。由于图过多,本文就显示一个例子,如果需要数据集或源码(每个代码详解)可在博主首页的“资源”下载。
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发CSDN博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗